Recognition: unknown
Layer Embedding Deep Fusion Graph Neural Network
Pith reviewed 2026-05-08 08:16 UTC · model grok-4.3
The pith
LEDF-GNN fuses multi-layer embeddings nonlinearly and runs original plus reconstructed topologies in parallel to improve GNN performance on both homophilic and heterophilic graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LEDF-GNN introduces a Layer Embedding Deep Fusion operator that nonlinearly fuses multi-layer embeddings to capture inter-layer dependencies and reduce deep propagation degradation, paired with a Dual-Topology Parallel Strategy that runs the original and reconstructed topologies in parallel for adaptive structure-semantics co-optimization, yielding consistent gains over state-of-the-art methods in semi-supervised classification on citation and image benchmarks under both homophilic and heterophilic regimes.
What carries the argument
The Layer Embedding Deep Fusion (LEDF) operator, which performs nonlinear fusion across layer embeddings, together with the Dual-Topology Parallel Strategy (DTPS) that processes original and reconstructed graph topologies simultaneously.
If this is right
- LEDF-GNN outperforms state-of-the-art baselines in semi-supervised node classification on citation and image benchmarks.
- The model maintains performance under both homophilic and heterophilic graph conditions.
- Nonlinear layer fusion reduces the degradation that normally occurs with increased network depth.
- Dual-topology processing allows adaptive co-optimization of structure and semantics without manual rewiring.
Where Pith is reading between the lines
- The same fusion operator could be applied to other GNN architectures to extend their effective depth on long-range tasks.
- Dual-topology processing may reduce reliance on separate graph-reconstruction pre-processing steps in heterophilic settings.
- The approach opens the possibility of testing whether nonlinear inter-layer fusion lowers sensitivity to hyperparameter choices across GNN families.
Load-bearing premise
The LEDF operator and Dual-Topology Parallel Strategy will capture inter-layer dependencies and adapt to varying homophily without creating new over-smoothing or needing extensive tuning that hurts generalization.
What would settle it
Training deeper versions of LEDF-GNN on additional heterophilic datasets and measuring whether node classification accuracy drops or over-smoothing metrics rise relative to shallower baselines would falsify the central claim if the gains disappear.
Figures











read the original abstract
Graph Neural Networks (GNNs) have demonstrated impressive performance in learning representations from graph-structured data. However, their message-passing mechanism inherently relies on the assumption of label consistency among connected nodes, limiting their applicability to low-homophily settings. Moreover, since message passing operates as a hierarchical diffusion process, GNNs face challenges in capturing long-range dependencies. As network depth increases, the structural noise along heterophilic edges tends to be amplified, resulting in over-smoothing. This issue becomes especially prominent in highly heterophilic graphs, where the propagation of inconsistent semantics across the topology continually exacerbates misaggregation. To address this issue, we propose a novel framework named Layer Embedding Deep Fusion Graph Neural Network (LEDF-GNN). Specifically, we design a Layer Embedding Deep Fusion (LEDF) operator that nonlinearly fuses multi-layer embeddings to capture inter-layer dependencies and effectively alleviate deep propagation degradation. Meanwhile, to mitigate structural heterophily, LEDF-GNN employs a Dual-Topology Parallel Strategy (DTPS) that simultaneously leverages the original and reconstructed topologies, allowing for adaptive structure-semantics co-optimization under diverse homophily conditions. Extensive semi-supervised classification experiments on the citation and image benchmarks demonstrate that, under both homophilic and heterophilic settings, LEDF-GNN consistently outperforms state-of-the-art baselines, validating its effectiveness and generalization capability across diverse graph types.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Layer Embedding Deep Fusion Graph Neural Network (LEDF-GNN) to address over-smoothing and heterophily limitations in standard GNN message-passing. It introduces a Layer Embedding Deep Fusion (LEDF) operator for nonlinear fusion of multi-layer embeddings to capture inter-layer dependencies, and a Dual-Topology Parallel Strategy (DTPS) that processes original and reconstructed topologies in parallel for adaptive structure-semantics co-optimization. The central claim is that extensive semi-supervised node classification experiments on citation and image benchmarks demonstrate consistent outperformance over state-of-the-art baselines under both homophilic and heterophilic settings.
Significance. If the experimental claims hold with proper ablations and statistical validation, the work could contribute a practical approach to mitigating deep propagation degradation and heterophily-induced misaggregation in GNNs. The dual-topology and deep-fusion ideas target well-known pain points and might generalize across graph types, but the abstract provides no equations, results, or controls to evaluate whether the operators achieve the claimed benefits without new drawbacks such as increased tuning burden or residual smoothing.
major comments (2)
- [Abstract] Abstract: the claim that LEDF-GNN 'consistently outperforms state-of-the-art baselines' supplies no equations, ablation results, statistical significance, baseline details, or performance metrics; the central empirical claim therefore cannot be verified from the available text and the experimental design remains opaque.
- [Abstract] Abstract: the weakest assumption—that the LEDF operator and DTPS will nonlinearly capture inter-layer dependencies and enable adaptive co-optimization without introducing new over-smoothing or requiring extensive hyperparameter tuning—is stated without any preliminary analysis, complexity discussion, or theoretical justification, which is load-bearing for the motivation and generalization claims.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for identifying areas where the abstract could better convey the manuscript's contributions. We address the two major comments point by point below. The full paper contains the requested details on methods, experiments, and analysis; we propose targeted revisions to the abstract to improve transparency without altering its length constraints.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that LEDF-GNN 'consistently outperforms state-of-the-art baselines' supplies no equations, ablation results, statistical significance, baseline details, or performance metrics; the central empirical claim therefore cannot be verified from the available text and the experimental design remains opaque.
Authors: We agree that the abstract is a high-level summary and therefore omits specific equations, ablation tables, statistical details, and numerical metrics. These elements are fully documented in the manuscript: the LEDF equations appear in Section 3.2, DTPS in Section 3.3, baseline descriptions and experimental protocol in Section 4.1, and results (including means, standard deviations from repeated runs, and comparisons across homophilic/heterophilic settings) in Tables 1–3 and Section 4.2. We will revise the abstract to include a concise statement of the average performance gains and a note that comprehensive ablations and statistical validation are provided in the experimental section. revision: yes
-
Referee: [Abstract] Abstract: the weakest assumption—that the LEDF operator and DTPS will nonlinearly capture inter-layer dependencies and enable adaptive co-optimization without introducing new over-smoothing or requiring extensive hyperparameter tuning—is stated without any preliminary analysis, complexity discussion, or theoretical justification, which is load-bearing for the motivation and generalization claims.
Authors: The abstract condenses the motivation; the preliminary analysis of over-smoothing and heterophily appears in the Introduction, the nonlinear fusion rationale and inter-layer dependency capture are justified in Section 3.2, the adaptive co-optimization via DTPS is explained in Section 3.3, and complexity (linear in depth) plus empirical checks for residual smoothing are discussed in Sections 3.4 and 4.3. We acknowledge the abstract could better signal these supporting elements and will add a brief clause referencing the design motivations and validation that no new smoothing or excessive tuning burden is introduced. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper proposes the LEDF operator and DTPS strategy as novel architectural components to address over-smoothing and heterophily in GNNs. The derivation consists of defining these operators to nonlinearly fuse embeddings and leverage dual topologies, followed by empirical validation on citation and image benchmarks. No load-bearing step reduces a claimed prediction or result to a fitted input by construction, no self-citation chain justifies a uniqueness theorem, and no ansatz is smuggled via prior work. The central claims rest on independent experimental outperformance rather than self-referential re-derivation, making the chain self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Message-passing mechanism inherently relies on label consistency among connected nodes
- domain assumption Structural noise along heterophilic edges is amplified with network depth
invented entities (2)
-
Layer Embedding Deep Fusion (LEDF) operator
no independent evidence
-
Dual-Topology Parallel Strategy (DTPS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Make heterophilic graphs better fit gnn: A graph rewiring approach.IEEE Transactions on Knowledge and Data Engineering, 2024
Wendong Bi, Lun Du, Qiang Fu, Yanlin Wang, Shi Han, and Dongmei Zhang. Make heterophilic graphs better fit gnn: A graph rewiring approach.IEEE Transactions on Knowledge and Data Engineering, 2024. 1
2024
-
[2]
Combining labeled and un- labeled data with co-training
Avrim Blum and Tom Mitchell. Combining labeled and un- labeled data with co-training. InProceedings of the eleventh annual conference on Computational learning theory, pages 92–100, 1998. 6
1998
-
[3]
Chen Cai and Yusu Wang. A note on over-smoothing for graph neural networks.arXiv preprint arXiv:2006.13318,
-
[4]
A multi-scale approach for graph link prediction
Lei Cai and Shuiwang Ji. A multi-scale approach for graph link prediction. InProceedings of the AAAI conference on artificial intelligence, pages 3308–3315, 2020. 1
2020
-
[5]
Measuring and relieving the over-smoothing problem for graph neural networks from the topological view
Deli Chen, Yankai Lin, Wei Li, Peng Li, Jie Zhou, and Xu Sun. Measuring and relieving the over-smoothing problem for graph neural networks from the topological view. InPro- ceedings of the AAAI conference on artificial intelligence, pages 3438–3445, 2020. 1
2020
-
[6]
Simple and deep graph convolutional net- works
Ming Chen, Zhewei Wei, Zengfeng Huang, Bolin Ding, and Yaliang Li. Simple and deep graph convolutional net- works. InInternational conference on machine learning, pages 1725–1735. PMLR, 2020. 2
2020
-
[7]
Gbk-gnn: Gated bi-kernel graph neural networks for modeling both homophily and het- erophily
Lun Du, Xiaozhou Shi, Qiang Fu, Xiaojun Ma, Hengyu Liu, Shi Han, and Dongmei Zhang. Gbk-gnn: Gated bi-kernel graph neural networks for modeling both homophily and het- erophily. InProceedings of the ACM web conference 2022, pages 1550–1558, 2022. 1
2022
-
[8]
Predict then propagate: Graph neural networks meet personalized pagerank
Johannes Gasteiger, Aleksandar Bojchevski, and Stephan G¨unnemann. Predict then propagate: Graph neural networks meet personalized pagerank. InInternational Conference on Learning Representations, 2019. 1, 6
2019
-
[9]
Neural message passing for quantum chemistry
Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. Neural message passing for quantum chemistry. InInternational conference on machine learning, pages 1263–1272. Pmlr, 2017. 1
2017
-
[10]
Inductive representation learning on large graphs.Advances in neural information processing systems, 30, 2017
Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs.Advances in neural information processing systems, 30, 2017. 2
2017
-
[11]
G- mixup: Graph data augmentation for graph classification
Xiaotian Han, Zhimeng Jiang, Ninghao Liu, and Xia Hu. G- mixup: Graph data augmentation for graph classification. In International conference on machine learning, pages 8230–
-
[12]
Harnessing explanations: Llm-to-lm interpreter for enhanced text-attributed graph rep- resentation learning
Xiaoxin He, Xavier Bresson, Thomas Laurent, Adam Per- old, Yann LeCun, and Bryan Hooi. Harnessing explanations: Llm-to-lm interpreter for enhanced text-attributed graph rep- resentation learning. InICLR, 2024. 6
2024
-
[13]
On which nodes does gcn fail? enhancing gcn from the node perspective
Jincheng Huang, Jialie Shen, Xiaoshuang Shi, and Xiaofeng Zhu. On which nodes does gcn fail? enhancing gcn from the node perspective. InForty-first International Conference on Machine Learning, 2024. 2
2024
-
[14]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review arXiv
-
[15]
Semi-supervised classi- fication with graph convolutional networks
Thomas N Kipf and Max Welling. Semi-supervised classi- fication with graph convolutional networks. InInternational Conference on Learning Representations, 2017. 1, 2, 6
2017
-
[16]
The mnist database of handwritten digits
Yann LeCun and Corinna Cortes. The mnist database of handwritten digits. Technical report, ATT Labs, 2010. 6
2010
-
[17]
Deepgcns: Making gcns go as deep as cnns.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021
Guohao Li, Matthias M ¨uller, Guocheng Qian, Itzel Car- olina Delgadillo Perez, Abdulellah Abualshour, Ali Kassem Thabet, and Bernard Ghanem. Deepgcns: Making gcns go as deep as cnns.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021. 1
2021
-
[18]
Agmixup: Adaptive graph mixup for semi-supervised node classification
Weigang Lu, Ziyu Guan, Wei Zhao, Yaming Yang, Yibing Zhan, Yiheng Lu, and Dapeng Tao. Agmixup: Adaptive graph mixup for semi-supervised node classification. InPro- ceedings of the AAAI Conference on Artificial Intelligence, pages 19143–19151, 2025. 6
2025
-
[19]
Co-embedding attributed networks
Zaiqiao Meng, Shangsong Liang, Hongyan Bao, and Xian- gliang Zhang. Co-embedding attributed networks. InPro- ceedings of the twelfth ACM international conference on web search and data mining, pages 393–401, 2019. 6
2019
-
[20]
Revisit- ing over-smoothing and over-squashing using ollivier-ricci curvature
Khang Nguyen, Nong Minh Hieu, Vinh Duc NGUYEN, Nhat Ho, Stanley Osher, and Tan Minh Nguyen. Revisit- ing over-smoothing and over-squashing using ollivier-ricci curvature. 2025. 6
2025
-
[21]
Geom-gcn: Geometric graph convolu- tional networks
Hongbin Pei, Bingzhe Wei, Kevin Chen-Chuan Chang, Yu Lei, and Bo Yang. Geom-gcn: Geometric graph convolu- tional networks. 2020. 2
2020
-
[22]
Dropedge: Towards deep graph convolutional net- works on node classification
Yu Rong, Wenbing Huang, Tingyang Xu, and Junzhou Huang. Dropedge: Towards deep graph convolutional net- works on node classification. InInternational Conference on Learning Representations, 2019. 2
2019
-
[23]
Multi- scale attributed node embedding.Journal of Complex Net- works, 9(2):cnab014, 2021
Benedek Rozemberczki, Carl Allen, and Rik Sarkar. Multi- scale attributed node embedding.Journal of Complex Net- works, 9(2):cnab014, 2021. 6
2021
-
[24]
Gnns getting comfy: Community and feature sim- ilarity guided rewiring
Celia Rubio-Madrigal, Adarsh Jamadandi, and Rebekka Burkholz. Gnns getting comfy: Community and feature sim- ilarity guided rewiring. InThe Thirteenth International Con- ference on Learning Representations, 2025. 6
2025
-
[25]
Learning representations by back-propagating er- rors.nature, 323(6088):533–536, 1986
David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning representations by back-propagating er- rors.nature, 323(6088):533–536, 1986. 6
1986
-
[26]
Pitfalls of Graph Neural Network Evaluation
Oleksandr Shchur, Maximilian Mumme, Aleksandar Bo- jchevski, and Stephan G ¨unnemann. Pitfalls of graph neural network evaluation.arXiv preprint arXiv:1811.05868, 2018. 6
work page Pith review arXiv 2018
-
[27]
Graph at- tention networks
Petar Veli ˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Li `o, and Yoshua Bengio. Graph at- tention networks. InInternational Conference on Learning Representations, 2018. 1, 2, 6
2018
-
[28]
Heterogeneous graph attention network
Xiao Wang, Houye Ji, Chuan Shi, Bai Wang, Yanfang Ye, Peng Cui, and Philip S Yu. Heterogeneous graph attention network. InThe world wide web conference, pages 2022– 2032, 2019. 6
2022
-
[29]
Am-gcn: Adaptive multi-channel graph convolu- tional networks
Xiao Wang, Meiqi Zhu, Deyu Bo, Peng Cui, Chuan Shi, and Jian Pei. Am-gcn: Adaptive multi-channel graph convolu- tional networks. InProceedings of the 26th ACM SIGKDD International conference on knowledge discovery & data mining, pages 1243–1253, 2020. 2
2020
-
[30]
Backpropagation through time: what it does and how to do it.Proceedings of the IEEE, 78(10):1550– 1560, 2002
Paul J Werbos. Backpropagation through time: what it does and how to do it.Proceedings of the IEEE, 78(10):1550– 1560, 2002. 6
2002
-
[31]
How Powerful are Graph Neural Networks?
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks?arXiv preprint arXiv:1810.00826, 2018. 6
work page internal anchor Pith review arXiv 2018
-
[32]
Representa- tion learning on graphs with jumping knowledge networks
Keyulu Xu, Chengtao Li, Yonglong Tian, Tomohiro Sonobe, Ken-ichi Kawarabayashi, and Stefanie Jegelka. Representa- tion learning on graphs with jumping knowledge networks. InInternational conference on machine learning, pages 5453–5462. PMLR, 2018. 2
2018
-
[33]
Link prediction based on graph neural networks.Advances in neural information pro- cessing systems, 31, 2018
Muhan Zhang and Yixin Chen. Link prediction based on graph neural networks.Advances in neural information pro- cessing systems, 31, 2018. 1
2018
-
[34]
An end-to-end deep learning architecture for graph classification
Muhan Zhang, Zhicheng Cui, Marion Neumann, and Yixin Chen. An end-to-end deep learning architecture for graph classification. InProceedings of the AAAI conference on ar- tificial intelligence, 2018. 1
2018
-
[35]
Node depen- dent local smoothing for scalable graph learning.Advances in Neural Information Processing Systems, 34:20321–20332,
Wentao Zhang, Mingyu Yang, Zeang Sheng, Yang Li, Wen Ouyang, Yangyu Tao, Zhi Yang, and Bin Cui. Node depen- dent local smoothing for scalable graph learning.Advances in Neural Information Processing Systems, 34:20321–20332,
-
[36]
Pairnorm: Tackling over- smoothing in gnns
Lingxiao Zhao and Leman Akoglu. Pairnorm: Tackling over- smoothing in gnns. InInternational Conference on Learning Representations, 2020. 1 Layer Embedding Deep Fusion Graph Neural Network Supplementary Material
2020
-
[37]
Attention-based Fusion Method To further validate our claim that attention-based layer fu- sion inherently suffers from weight collapse, especially on heterophilic graphs, we conduct a detailed empirical anal- ysis of attention weights (averaging all nodes) distributions across different propagation depths. 6.1. Experimental Setup We evaluate attention-ba...
-
[38]
The details are provided in Table 3
The Details of Dataset In total, fourteen datasets are used in this work, with each being fixedly divided. The details are provided in Table 3. ACM Shallow Deep ACM Cora ACM Cora Wisconsin BlogCatalog Wisconsin BlogCatalog Original Topology Reconstructed Topology Figure 9. The proportion of attention weights in shallow and deep layers of the GCN predictor...
-
[39]
Note that for both the ablation and validation experiments, the parameter settings are identical to those used in the semi-supervised node classification experiment
Parameter Setup Table 4 introduces the parameter settings for the semi- supervised node classification experiments, including the kparameter ofT op k in LSC, as well as the propagation depthsQ1andQ2used in the LEDF operator. Note that for both the ablation and validation experiments, the parameter settings are identical to those used in the semi-supervise...
-
[40]
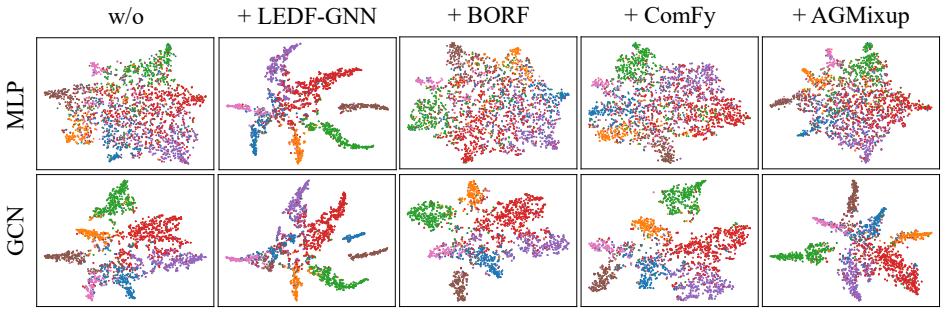
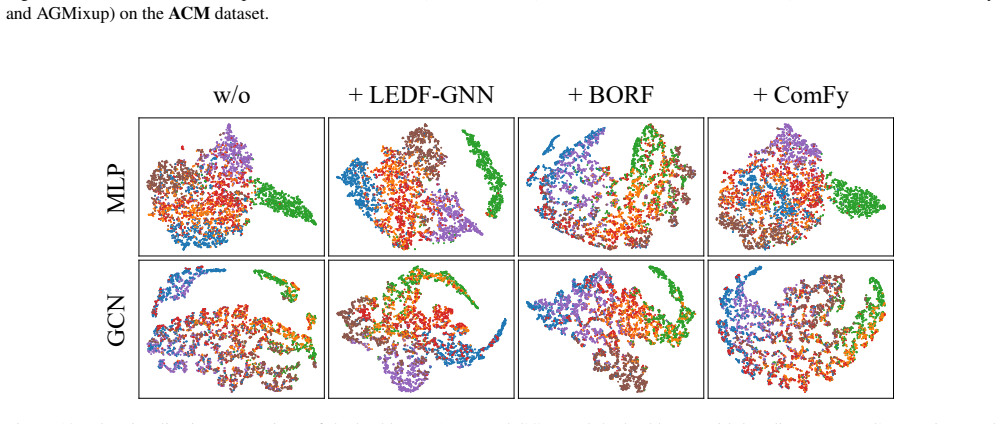
Visualization on Semi-supervised Node Classification Figure 10 illustrates the qualitative comparison on the Cora dataset, showcasing the visual differences among the back- bones (MLP and GCN) themselves, backbones with base- lines (LEDF-GNN, BORF, ComFy and AGMixup). Fig- ure 11 illustrates the qualitative comparison on the ACM dataset, showcasing the vi...
-
[41]
Bit operations based LSC needs lower memory overhead than floating-point co- Dataset Nodes Edges Features Class Homo
LSCvs.Cosine Similarity Table 5 shows that the more intuitive LSC can obtain bet- ter homophily than cosine similarity. Bit operations based LSC needs lower memory overhead than floating-point co- Dataset Nodes Edges Features Class Homo. Train/Valid/Test Cora 2708 10556 1433 7 0.81 140/500/1000 CiteSeer 3327 9104 3703 6 0.74 120/500/1000 PubMed 19717 8864...
2000
-
[42]
Accordingly, the runtime and memory overhead reported in Tables 6 also exhibit that our model only needs lightweight overhead beyond the backbone
Complexity Analysis The time and space complexity of our method beyond the backbone model areO(cm+n)andO(cn), respectively, wherenis node number,mis edge number andcis class number. Accordingly, the runtime and memory overhead reported in Tables 6 also exhibit that our model only needs lightweight overhead beyond the backbone
-
[43]
Figure 14 shows the robustness of our method across different settings
Hyperparameter Analysis We conduct sensitivity analysis on two key hyperparame- ters, depthQand reconstruction hyperparameterK, by us- ing the heterophilic Wisconsin dataset. Figure 14 shows the robustness of our method across different settings
-
[44]
Comparison with Heterophliy-focused and Deep-GNN Baseline The comparison results are reported in Table 7. JKNet- Mean focus on layer fusion, GCNII and NDLS are deep- GNNs, H 2GCN is the representative heterophily-focused method. The datasets of Wisconsin and Chameleon are het- erophilic. w/o + LEDF-GNN + BORF + ComFy + AGMixup MLPGCN Figure 10. The visual...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.