Recognition: unknown
Ghost in the Agent: Redefining Information Flow Tracking for LLM Agents
Pith reviewed 2026-05-08 08:04 UTC · model grok-4.3
The pith
NeuroTaint tracks information flow in LLM agents by auditing semantic evidence and causal influences across execution traces rather than exact string matches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NeuroTaint is the first comprehensive taint tracking framework for LLM agents. It audits execution traces offline to reconstruct provenance from untrusted sources to privileged sinks by combining semantic evidence, causal reasoning, and persistent context tracking instead of relying on exact string matches or pre-defined source-sink paths alone.
What carries the argument
NeuroTaint's offline execution-trace audit that applies semantic evidence, causal reasoning, and persistent context tracking to follow information provenance.
Load-bearing premise
Semantic evidence and causal reasoning can reliably reconstruct information provenance even when LLM reasoning is probabilistic and does not preserve exact strings.
What would settle it
A concrete test case in which an untrusted input subtly influences a privileged tool call through semantic or causal means yet NeuroTaint reports no flow, or reports a flow where none exists.
Figures


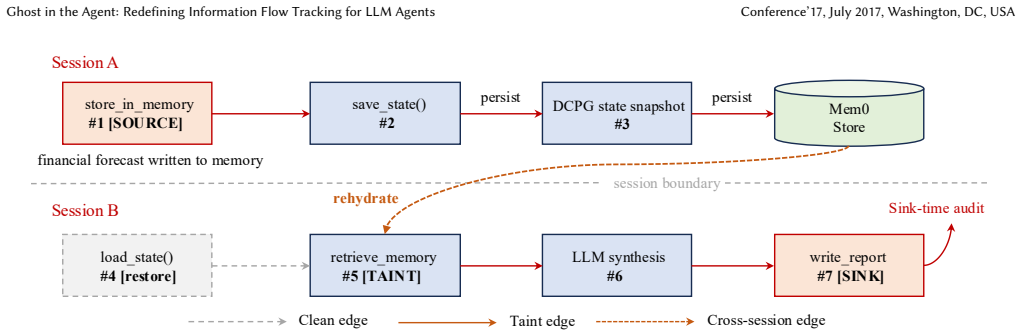

read the original abstract
Autonomous Large Language Model (LLM) agents are increasingly deployed to conduct complex tasks by interacting with external tools, APIs, and memory stores. However, processing untrusted external data exposes these agents to severe security threats, such as indirect prompt injection and unauthorized tool execution. Securing these systems requires effective information flow tracking. Yet, traditional taint analysis that is designed for program memory states fundamentally fails when applied to LLMs, where data propagation is governed by probabilistic natural language reasoning. In this paper, we present NeuroTaint, the first comprehensive taint tracking framework tailored for the unique information flow characteristics of LLM agents. Our key insight is that taint propagation in LLM agents must be understood not only as explicit content transfer, but also as semantic transformation, causal influence on decisions, and cross-session persistence through memory. NeuroTaint therefore audits execution traces offline to reconstruct provenance from untrusted sources to privileged sinks using semantic evidence, causal reasoning, and persistent context tracking, rather than relying on exact string matches or pre-defined source-sink paths alone. Extensive evaluation using TaintBench, our 400-scenario benchmark spanning 20 real-world agent frameworks, shows that NeuroTaint substantially outperforms FIDES, an information-flow-control (IFC)-style baseline for LLM agents, in source-sink propagation detection. We further show that NeuroTaint remains effective on established agent-security benchmarks, including InjecAgent and ToolEmu, while operating offline with modest additional auditing cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NeuroTaint as the first taint-tracking framework specifically designed for LLM agents. It argues that conventional taint analysis fails because LLM information flow is governed by probabilistic natural-language reasoning rather than explicit memory states. NeuroTaint instead performs offline auditing of execution traces, reconstructing provenance from untrusted sources to privileged sinks via semantic evidence, causal reasoning, and persistent context tracking. The central empirical claim is that this approach substantially outperforms the IFC-style baseline FIDES on the authors' new TaintBench (400 scenarios across 20 real-world agent frameworks) while remaining effective on InjecAgent and ToolEmu.
Significance. If the causal-reasoning component can be made reproducible and shown to avoid circularity with the agent's own LLM, the work would constitute a meaningful advance in practical security auditing for autonomous LLM agents. The introduction of TaintBench as a multi-framework benchmark is a concrete positive contribution that could facilitate future comparisons.
major comments (3)
- [Section 3] Section 3 (NeuroTaint framework description): the causal-reasoning step is presented only at the level of 'semantic evidence, causal reasoning, and persistent context tracking' with no explicit algorithm, decision procedure, or pseudocode. If this component is itself realized by an LLM call (a common pattern in such systems), the method inherits the nondeterminism and potential for hallucinated causal links that it seeks to audit, directly undermining the central claim that offline reconstruction is more reliable than string matching.
- [Section 5] Section 5 (Evaluation on TaintBench): the abstract states that NeuroTaint 'substantially outperforms' FIDES, yet no false-positive rates, benchmark-construction methodology, statistical significance tests, or per-scenario breakdowns are reported. Without these data the performance claim cannot be assessed for robustness or generalizability.
- [Abstract and Section 4] Abstract and Section 4: the paper asserts that NeuroTaint 'operates offline with modest additional auditing cost,' but no quantitative overhead measurements, scalability results, or comparison against online IFC baselines are supplied. This leaves the practicality claim unsupported.
minor comments (2)
- [Abstract] The abstract is lengthy and mixes high-level claims with evaluation results; a shorter version focused on the core technical insight would improve readability.
- [Section 3] Notation for sources, sinks, and provenance edges is introduced informally; a small table or diagram in Section 3 would clarify the data model.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recognition of NeuroTaint's potential contribution and the value of TaintBench. We address each major comment below with specific plans for revision.
read point-by-point responses
-
Referee: [Section 3] Section 3 (NeuroTaint framework description): the causal-reasoning step is presented only at the level of 'semantic evidence, causal reasoning, and persistent context tracking' with no explicit algorithm, decision procedure, or pseudocode. If this component is itself realized by an LLM call (a common pattern in such systems), the method inherits the nondeterminism and potential for hallucinated causal links that it seeks to audit, directly undermining the central claim that offline reconstruction is more reliable than string matching.
Authors: We appreciate the referee's identification of this gap in Section 3. The causal-reasoning step is realized through a deterministic procedure that combines embedding-based semantic similarity for evidence extraction with a rule-based causal inference engine operating on structured execution traces (e.g., tool call sequences and memory updates). This design deliberately avoids any additional LLM invocation to prevent circularity or hallucination risks. We will add explicit pseudocode, the full decision procedure, and implementation details demonstrating reproducibility in the revised Section 3. revision: yes
-
Referee: [Section 5] Section 5 (Evaluation on TaintBench): the abstract states that NeuroTaint 'substantially outperforms' FIDES, yet no false-positive rates, benchmark-construction methodology, statistical significance tests, or per-scenario breakdowns are reported. Without these data the performance claim cannot be assessed for robustness or generalizability.
Authors: We agree that the current presentation of results in Section 5 is insufficient for full evaluation of the claims. In the revision we will report false-positive rates for NeuroTaint and the FIDES baseline, provide a detailed account of TaintBench construction (including scenario generation, source/sink labeling, and coverage across the 20 frameworks), include statistical significance testing on the detection differences, and supply per-scenario or aggregated breakdowns with confidence intervals. These additions will directly support assessment of robustness and generalizability. revision: yes
-
Referee: [Abstract and Section 4] Abstract and Section 4: the paper asserts that NeuroTaint 'operates offline with modest additional auditing cost,' but no quantitative overhead measurements, scalability results, or comparison against online IFC baselines are supplied. This leaves the practicality claim unsupported.
Authors: We acknowledge that quantitative evidence for the overhead and practicality claims is currently missing. We will add concrete measurements of auditing time and resource cost across trace lengths, scalability results on extended benchmarks, and direct comparisons of offline auditing cost versus the runtime overhead incurred by online IFC methods such as FIDES. These data will be incorporated into Section 4 and referenced from the abstract to substantiate the 'modest additional auditing cost' statement. revision: yes
Circularity Check
No circularity: NeuroTaint presents independent offline auditing framework
full rationale
The paper describes NeuroTaint as an auditing method that reconstructs provenance via semantic evidence, causal reasoning, and persistent context tracking on execution traces. No equations, fitted parameters, self-definitional steps, or load-bearing self-citations appear in the abstract or described claims. The central method is positioned as an alternative to string matching or pre-defined paths and is evaluated on external benchmarks (TaintBench, InjecAgent, ToolEmu). This is self-contained against external benchmarks with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents process untrusted external data through probabilistic natural language reasoning rather than deterministic program states
invented entities (1)
-
NeuroTaint framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sahar Abdelnabi, Kai Greshake, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not What You’ve Signed Up For: Compromising Real- World LLM-Integrated Applications with Indirect Prompt Injection. InProceedings of the 16th ACM Workshop on Artificial Intelligence and Security, AISec 2023, Copenhagen, Denmark, 30 November 2023, Maura ...
-
[2]
Steven Arzt, Siegfried Rasthofer, Christian Fritz, Eric Bodden, Alexandre Bar- tel, Jacques Klein, Yves Le Traon, Damien Octeau, and Patrick McDaniel. 2014. FlowDroid: precise context, flow, field, object-sensitive and lifecycle-aware taint analysis for Android apps. InProceedings of the 35th ACM SIGPLAN Conference on Programming Language Design and Imple...
-
[4]
Eugene Bagdasaryan, Tsung-Yin Hsieh, Ben Nassi, and Vitaly Shmatikov. 2023. (Ab)using Images and Sounds for Indirect Instruction Injection in Multi-Modal LLMs. https://doi.org/10.48550/ARXIV.2307.10490 arXiv:2307.10490
-
[5]
Nicholas Boucher, Ilia Shumailov, Ross Anderson, and Nicolas Papernot. 2022. Bad Characters: Imperceptible NLP Attacks. In43rd IEEE Symposium on Security and Privacy, SP 2022, San Francisco, CA, USA, May 22-26, 2022. IEEE, 1987–2004. https://doi.org/10.1109/SP46214.2022.9833641 12 Ghost in the Agent: Redefining Information Flow Tracking for LLM Agents Con...
-
[6]
Harrison Chase. 2022. LangChain: Building applications with LLMs through composability. https://github.com/langchain-ai/langchain
2022
-
[7]
Harrison Chase and Nuno Campos. 2024. LangGraph: Building stateful, multi- actor applications with LLMs. https://github.com/langchain-ai/langgraph
2024
-
[8]
Sizhe Chen, Julien Piet, Chawin Sitawarin, and David A. Wagner. 2025. StruQ: Defending Against Prompt Injection with Structured Queries. In34th USENIX Security Symposium, USENIX Security 2025, Seattle, W A, USA, August 13-15, 2025, Lujo Bauer and Giancarlo Pellegrino (Eds.). USENIX Association, 2383–2400. https://www.usenix.org/conference/usenixsecurity25...
2025
-
[9]
Sizhe Chen, Arman Zharmagambetov, Saeed Mahloujifar, Kamalika Chaudhuri, David A. Wagner, and Chuan Guo. 2025. SecAlign: Defending Against Prompt Injection with Preference Optimization. (2025), 2833–2847. https://doi.org/10. 1145/3719027.3744836
-
[10]
Zhaorun Chen, Zhen Xiang, Chaowei Xiao, Dawn Song, and Bo Li. 2024. AgentPoison: Red-teaming LLM Agents via Poisoning Memory or Knowl- edge Bases. InAdvances in Neural Information Processing Systems 38: An- nual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, Amir Globersons, Lester Ma...
2024
-
[11]
Yiu Wai Chow, Max Schäfer, and Michael Pradel. 2023. Beware of the Unexpected: Bimodal Taint Analysis. InProceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2023, Seattle, W A, USA, July 17-21, 2023, René Just and Gordon Fraser (Eds.). ACM, 211–222. https://doi.org/ 10.1145/3597926.3598050
-
[12]
Manuel Costa, Boris Köpf, Aashish Kolluri, Andrew Paverd, Mark Russinovich, Ahmed Salem, Shruti Tople, Lukas Wutschitz, and Santiago Zanella-Béguelin
-
[13]
Securing AI agents with information-flow control,
Securing AI Agents with Information-Flow Control.CoRRabs/2505.23643 (2025). https://doi.org/10.48550/ARXIV.2505.23643 arXiv:2505.23643
-
[14]
Edoardo Debenedetti, Ilia Shumailov, Tianqi Fan, Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, Chongyang Shi, Andreas Terzis, and Florian Tramèr. 2025. Defeating Prompt Injections by Design.CoRRabs/2503.18813 (2025). https://doi.org/10.48550/ARXIV.2503.18813 arXiv:2503.18813
work page internal anchor Pith review doi:10.48550/arxiv.2503.18813 2025
-
[15]
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. 2024. AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Informa- tion Processing Systems 2024, NeurIPS 2024, Vancouver,...
2024
-
[16]
Shen Dong, Shaochen Xu, Pengfei He, Yige Li, Jiliang Tang, Tianming Liu, Hui Liu, and Zhen Xiang. 2026. Memory Injection Attacks on LLM Agents via Query- Only Interaction. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=QINnsnppv8
2026
-
[17]
Cox, Jaeyeon Jung, Patrick D
William Enck, Peter Gilbert, Byung-Gon Chun, Landon P. Cox, Jaeyeon Jung, Patrick D. McDaniel, and Anmol Sheth. 2010. TaintDroid: An Information-Flow Tracking System for Realtime Privacy Monitoring on Smartphones. In9th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2010, October 4-6, 2010, Vancouver, BC, Canada, Proceedings, Remzi ...
2010
-
[18]
Keegan Hines, Gary Lopez, Matthew Hall, Federico Zarfati, Yonatan Zunger, and Emre Kiciman. 2024. Defending Against Indirect Prompt Injection Attacks With Spotlighting.CoRRabs/2403.14720 (2024). https://doi.org/10.48550/ARXIV.2403. 14720 arXiv:2403.14720
-
[19]
Feiran Jia, Tong Wu, Xin Qin, and Anna Cinzia Squicciarini. 2025. The Task Shield: Enforcing Task Alignment to Defend Against Indirect Prompt Injection in LLM Agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025, Wanxiang Che, Joyce Na...
2025
-
[20]
Nicole Kobie. 2025. OpenAI says prompt injection attacks are a serious threat for AI browsers – and it’s a problem that’s unlikely to ever be fully solved.ITPro (24 Dec. 2025). https://www.itpro.com/technology/artificial-intelligence/openai- chatgpt-atlas-ai-browser-prompt-injection-attack-risk
2025
-
[21]
Fengyu Liu, Yuan Zhang, Jiaqi Luo, Jiarun Dai, Tian Chen, Letian Yuan, Zhengmin Yu, Youkun Shi, Ke Li, Chengyuan Zhou, Hao Chen, and Min Yang. 2025. Make Agent Defeat Agent: Automatic Detection of Taint-Style Vulnerabilities in LLM- based Agents. In34th USENIX Security Symposium, USENIX Security 2025, Seattle, W A, USA, August 13-15, 2025, Lujo Bauer and ...
2025
-
[22]
Xiaogeng Liu, Somesh Jha, Patrick McDaniel, Bo Li, and Chaowei Xiao. 2025. Au- toHijacker: Automatic Indirect Prompt Injection Against Black-box LLM Agents. https://openreview.net/forum?id=2VmB01D9Ef
2025
-
[23]
Yi Liu, Gelei Deng, Yuekang Li, Kailong Wang, Tianwei Zhang, Yepang Liu, Haoyu Wang, Yan Zheng, and Yang Liu. 2023. Prompt Injection attack against LLM-integrated Applications. https://doi.org/10.48550/ARXIV.2306.05499 arXiv:2306.05499
work page internal anchor Pith review doi:10.48550/arxiv.2306.05499 2023
-
[24]
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. 2024. Formalizing and Benchmarking Prompt Injection Attacks and Defenses. https: //www.usenix.org/conference/usenixsecurity24/presentation/liu-yupei
2024
-
[25]
Mem0 Team. 2024. Mem0: The Memory Layer for Personalized AI. https://github. com/mem0ai/mem0
2024
-
[26]
Microsoft. 2024. AutoGen: A programming framework for agentic AI. https: //github.com/microsoft/autogen
2024
-
[27]
Fábio Perez and Ian Ribeiro. 2022. Ignore Previous Prompt: Attack Techniques For Language Models. arXiv:2211.09527 [cs.CL] https://arxiv.org/abs/2211.09527
work page internal anchor Pith review arXiv 2022
-
[28]
Maddison, and Tatsunori Hashimoto
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J. Maddison, and Tatsunori Hashimoto. 2024. Identi- fying the Risks of LM Agents with an LM-Emulated Sandbox. InThe Twelfth Inter- national Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. https://openreview...
2024
-
[30]
Dongdong She, Yizheng Chen, Abhishek Shah, Baishakhi Ray, and Suman Jana
-
[31]
In2020 IEEE Symposium on Security and Privacy, SP 2020, San Francisco, CA, USA, May 18-21, 2020
Neutaint: Efficient Dynamic Taint Analysis with Neural Networks. In2020 IEEE Symposium on Security and Privacy, SP 2020, San Francisco, CA, USA, May 18-21, 2020. IEEE, 1527–1543. https://doi.org/10.1109/SP40000.2020.00022
-
[32]
Shoaib Ahmed Siddiqui, Radhika Gaonkar, Boris Köpf, David Krueger, Andrew Paverd, Ahmed Salem, Shruti Tople, Lukas Wutschitz, Menglin Xia, and Santi- ago Zanella-Béguelin. 2024. Permissive Information-Flow Analysis for Large Language Models.CoRRabs/2410.03055 (2024). https://doi.org/10.48550/ARXIV. 2410.03055 arXiv:2410.03055
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[33]
Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, and Alex Beutel. 2024. The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions.CoRRabs/2404.13208 (2024). https://doi.org/10.48550/ARXIV.2404. 13208 arXiv:2404.13208
-
[34]
Jackson Wang. 2026. AttackEval: A Systematic Empirical Study of Prompt Injec- tion Attack Effectiveness Against Large Language Models.CoRRabs/2604.03598 (2026). https://arxiv.org/abs/2604.03598
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Simon Willison. 2023. Dual LLM pattern for building AI assistants that can resist prompt injection.Blog post, simonwillison.net(2023). https://simonwillison.net/ 2023/Apr/25/dual-llm-pattern/
2023
-
[36]
Jingwei Yi, Yueqi Xie, Bin Zhu, Keegan Hines, Emre Kiciman, Guangzhong Sun, Xing Xie, and Fangzhao Wu. 2023. Benchmarking and Defending Against Indirect Prompt Injection Attacks on Large Language Models.CoRRabs/2312.14197. https://doi.org/10.48550/ARXIV.2312.14197 arXiv:2312.14197
-
[37]
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. 2024. InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents. InFindings of the Association for Computational Linguistics: ACL
2024
-
[38]
https://doi.org/10.18653/v1/2024.findings-acl.624
Association for Computational Linguistics, 10471–10506. https://doi.org/ 10.18653/v1/2024.findings-acl.624
-
[39]
Hang Zhang, Weiteng Chen, Yu Hao, Guoren Li, Yizhuo Zhai, Xiaochen Zou, and Zhiyun Qian. 2021. Statically Discovering High-Order Taint Style Vulnerabili- ties in OS Kernels. InCCS ’21: 2021 ACM SIGSAC Conference on Computer and Communications Security, Virtual Event, Republic of Korea, November 15 - 19, 2021, Yongdae Kim, Jong Kim, Giovanni Vigna, and Ela...
-
[40]
Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, and Yongfeng Zhang. 2025. Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net. https://op...
2025
-
[41]
Yiyu Zhang, Tianyi Liu, Yueyang Wang, Yun Qi, Kai Ji, Jian Tang, Xiaoliang Wang, Xuandong Li, and Zhiqiang Zuo. 2024. HardTaint: Production-Run Dynamic Taint Analysis via Selective Hardware Tracing.Proc. ACM Program. Lang.8, OOPSLA2 (2024), 1615–1640. https://doi.org/10.1145/3689768
-
[42]
Titzer, Heather Miller, and Phillip B
Peter Yong Zhong, Siyuan Chen, Ruiqi Wang, McKenna McCall, Ben L. Titzer, Heather Miller, and Phillip B. Gibbons. 2025. RTBAS: Defending LLM Agents Against Prompt Injection and Privacy Leakage.CoRRabs/2502.08966 (2025). https://doi.org/10.48550/ARXIV.2502.08966 arXiv:2502.08966 13 Conference’17, July 2017, Washington, DC, USA Yuandao Cai, Wensheng Tang, C...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.