Recognition: unknown
Breaking the Resource Wall: Geometry-Guided Sequence Modeling for Efficient Semantic Segmentation
Pith reviewed 2026-05-08 08:37 UTC · model grok-4.3
The pith
DGM-Net achieves 82.3 percent mIoU on Cityscapes and 45.24 percent on ADE20K by guiding state space scans with centripetal flow fields and topological skeletons instead of scaling backbones or pretraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
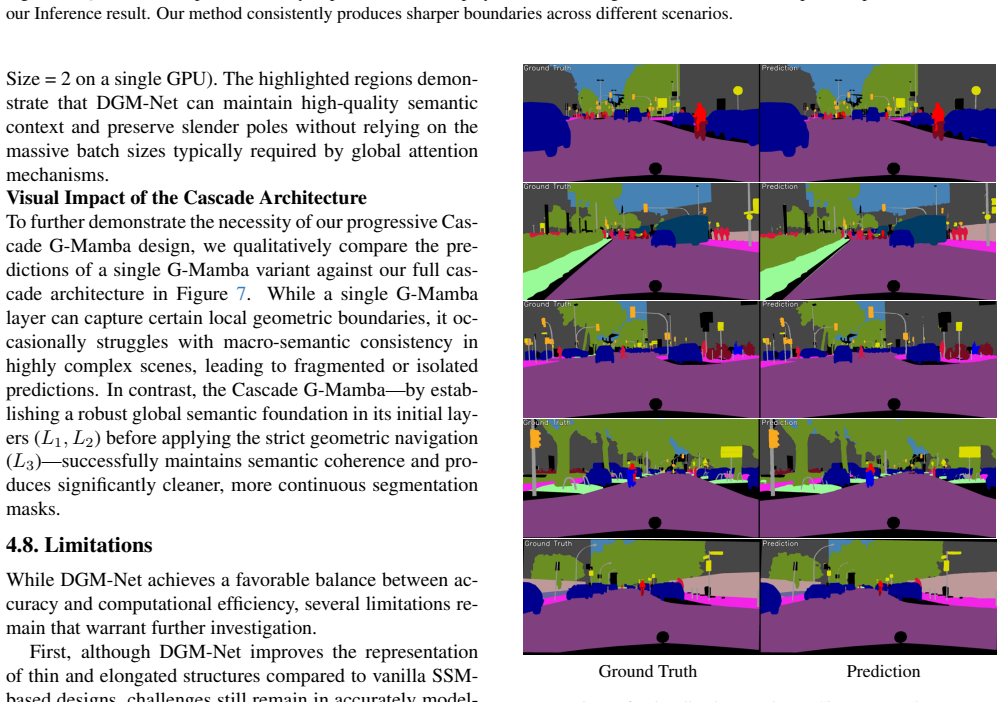
DGM-Net introduces the G-Mamba operator as a linear-complexity alternative to ASPP and PPM, then augments it with the DGM-Module that extracts centripetal flow fields and topological skeletons to direct scanning; this combination yields 80.8 percent mIoU after 28k iterations, 82.3 percent mIoU on the Cityscapes test set, and 45.24 percent mIoU on ADE20K without large-scale pretraining or heavy backbone scaling, while remaining stable under batch size 2 on 8 GB VRAM.
What carries the argument
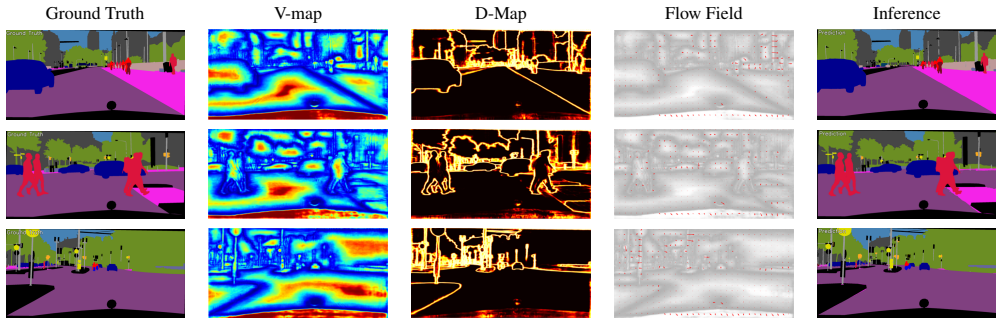
The DGM-Module extracts centripetal flow fields and topological skeletons to guide the scanning order inside the Directional Geometric Mamba (G-Mamba) operator.
If this is right
- Reaches competitive mIoU scores after only 28k training iterations without pretraining.
- Maintains performance when hardware forces batch size 2 on 8 GB VRAM.
- Provides a linear-time replacement for heavier context modules such as ASPP and PPM.
- Improves boundary detail through explicit geometric cues rather than larger model capacity.
Where Pith is reading between the lines
- The same geometric guidance pattern could be tested on other state-space or recurrent vision models for tasks like depth estimation or instance segmentation.
- Lower hardware requirements may allow segmentation models to run on edge devices without sacrificing much accuracy.
- Removing the need for large pretraining sets could make the method useful in domains where labeled data remain scarce.
- Ablation studies that isolate flow-field versus skeleton contributions would clarify which geometric signal drives the gains.
Load-bearing premise
That feeding centripetal flow fields and topological skeletons into the G-Mamba scan will improve boundary preservation and overall accuracy without creating new instabilities or needing heavy extra tuning.
What would settle it
Training an identical backbone with the DGM-Module removed and measuring whether mIoU on boundary pixels or overall scores drops by more than 1-2 points on Cityscapes would test the claimed benefit of the geometric guidance.
Figures





read the original abstract
High-performance semantic segmentation has achieved significant progress in recent years, often driven by increasingly large backbones and higher computational budgets. While effective, such approaches introduce substantial computational overhead and limit accessibility under constrained hardware settings. In this paper, we propose DGM-Net (Directional Geometric Mamba Network), an efficient architecture that improves modeling capability through structural design rather than increasing model capacity. We introduce Directional Geometric Mamba (G-Mamba), a linear-complexity O(N) operator as an alternative to conventional context modeling modules such as ASPP and PPM. To further enhance structural awareness in state space model (SSM)-based modeling, we design the DGM-Module, which extracts centripetal flow fields and topological skeletons to guide the scanning process and improve boundary preservation. Without relying on large-scale pretraining or heavy backbone scaling, DGM-Net achieves 80.8% mIoU within 28k iterations, 82.3% mIoU on Cityscapes test set, and 45.24% mIoU on ADE20K. In addition, the model maintains stable performance under constrained hardware settings (e.g., batch size of 2 on 8GB VRAM), highlighting its efficiency and practicality. These results demonstrate that incorporating geometric guidance into SSM-based architectures provides an effective and resource-efficient direction for semantic segmentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DGM-Net, an efficient semantic segmentation model that replaces conventional context modules (ASPP, PPM) with Directional Geometric Mamba (G-Mamba), a linear-complexity O(N) state-space operator. It further proposes the DGM-Module, which extracts centripetal flow fields and topological skeletons to guide the SSM scanning process and improve boundary preservation. Without large-scale pretraining or heavy backbone scaling, the model reports 80.8% mIoU after 28k iterations, 82.3% mIoU on the Cityscapes test set, and 45.24% mIoU on ADE20K, while remaining stable at batch size 2 on 8 GB VRAM.
Significance. If the results hold, the work shows that geometry-guided SSM scanning can deliver competitive semantic segmentation performance with substantially lower training cost and hardware requirements than backbone-scaling approaches. The manuscript supplies ablations, FLOPs comparisons, and cross-dataset results that directly support the headline numbers under the stated constraints, providing a concrete, resource-efficient alternative to current high-capacity designs.
minor comments (3)
- Abstract: the performance claims (80.8% mIoU in 28k iterations, 82.3% Cityscapes, 45.24% ADE20K) are stated without cross-references to the tables or sections that contain the corresponding ablations and baseline comparisons; adding these pointers would improve readability.
- §3 (DGM-Module description): the precise integration of centripetal flow fields and topological skeletons into the G-Mamba scan direction is described at a high level; a short pseudocode or explicit equation showing how the guidance modulates the state transition would eliminate ambiguity for readers wishing to re-implement the operator.
- Table captions and experimental protocol: error bars or standard deviations across multiple runs are not mentioned; including them (or stating that single-run results are reported) would strengthen the reproducibility claim.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our work, the recognition of DGM-Net's resource efficiency, and the recommendation for minor revision. We will incorporate any suggested minor changes in the revised manuscript.
Circularity Check
No significant circularity
full rationale
The paper's central claims rest on an architectural design choice (DGM-Module extracting centripetal flow fields and topological skeletons to steer G-Mamba scanning) whose performance is validated through direct empirical results on Cityscapes and ADE20K under stated hardware constraints. No equations, parameters, or performance metrics are shown to reduce by construction to fitted inputs, self-definitions, or self-citation chains; the reported mIoU numbers and efficiency claims are presented as outcomes of the independent design rather than tautological restatements of the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption State-space models benefit from explicit geometric guidance during scanning for boundary-sensitive tasks
invented entities (2)
-
Directional Geometric Mamba (G-Mamba)
no independent evidence
-
DGM-Module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Deep watershed transform for instance segmentation
Min Bai and Raquel Urtasun. Deep watershed transform for instance segmentation. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 5221–5229, 2017. 2
2017
-
[2]
Beit: Bert pre-training of image transformers
Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. Beit: Bert pre-training of image transformers. InInternational Conference on Learning Representations, 2022. 1
2022
-
[3]
The lov´asz-softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks
Maxim Berman, Amal Rhouma Triki, and Matthew B Blaschko. The lov´asz-softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4413–4421,
-
[4]
Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolu- tion, and fully connected crfs.IEEE transactions on pattern analysis and machine intelligence, 40(4):834–848, 2017. 1
2017
-
[5]
Rethinking Atrous Convolution for Semantic Image Segmentation
Liang-Chieh Chen, George Papandreou, Florian Schroff, and Hartwig Adam. Rethinking atrous convolution for seman- tic image segmentation.arXiv preprint arXiv:1706.05587,
work page internal anchor Pith review arXiv
-
[6]
Encoder-decoder with atrous separable convolution for semantic image segmentation
Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV), pages 801–818, 2018. 1, 2, 10
2018
-
[7]
A semi-supervised boundary segmentation network for remote sensing images.Scientific Reports, 15(1):2007, 2025
Yongdong Chen, Zaichun Yang, Liangji Zhang, and Weiwei Cai. A semi-supervised boundary segmentation network for remote sensing images.Scientific Reports, 15(1):2007, 2025. 2
2007
-
[8]
Masked-attention mask transformer for universal image segmentation
Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexan- der Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1290–1299, 2022. 2, 8
2022
-
[9]
The cityscapes dataset for semantic urban scene understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 3213–3223, 2016. 7
2016
-
[10]
Deformable convolutional networks
Jifeng Dai, Haozhi Qi, Yuwen Xiong, Yi Li, Guodong Zhang, Han Hu, and Yichen Wei. Deformable convolutional networks. InProceedings of the IEEE international confer- ence on computer vision, pages 764–773, 2017. 6
2017
-
[11]
Centripetalnet: Pursuing high- quality keypoint-based object detection
Zhiwei Dong, Guoxuan Li, Yue Liao, Fei Wang, Pengju Ren, and Chen Qian. Centripetalnet: Pursuing high- quality keypoint-based object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10519–10528, 2020. 2
2020
-
[12]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy et al. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021. 1
2021
-
[13]
Ecmnet: Lightweight semantic segmentation with efficient cnn-mamba network
Feixiang Du, Shengkun Wu, Xiang Wang, Aoxue Ding, Zhongliang Wang, and Joel CM Than. Ecmnet: Lightweight semantic segmentation with efficient cnn-mamba network. Science Progress, 109(1):00368504261419245, 2026. 2
2026
-
[14]
Dual attention network for scene seg- mentation
Jun Fu, Jing Liu, Haijie Tian, Yong Li, Yongjun Bao, Zhiwei Fang, and Hanqing Lu. Dual attention network for scene seg- mentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3146–3154,
-
[15]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023. 1, 2
work page internal anchor Pith review arXiv 2023
-
[16]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 3
2016
-
[17]
Ccnet: Criss-cross attention for semantic segmentation
Zilong Huang, Xinggang Wang, Lichao Huang, Chang Huang, Yunchao Wei, and Wenyu Liu. Ccnet: Criss-cross attention for semantic segmentation. InProceedings of the IEEE/CVF international conference on computer vision, pages 603–612, 2019. 2
2019
-
[18]
Alignseg: Feature- aligned segmentation networks
Zilong Huang, Yunchao Wei, Xinggang Wang, Wenyu Liu, Thomas S Huang, and Humphrey Shi. Alignseg: Feature- aligned segmentation networks. InIEEE Transactions on Pattern Analysis and Machine Intelligence, 2021. 3
2021
-
[19]
Spatial transformer networks
Max Jaderberg, Karen Simonyan, Andrew Zisserman, and Koray Kavukcuoglu. Spatial transformer networks. InAd- vances in neural information processing systems, volume 28,
-
[20]
Global and local mamba network for multi- modality medical image super-resolution.Pattern Recogni- tion, page 112888, 2025
Zexin Ji, Beiji Zou, Xiaoyan Kui, Sbastien Thureau, and Su Ruan. Global and local mamba network for multi- modality medical image super-resolution.Pattern Recogni- tion, page 112888, 2025. 2
2025
-
[21]
Afrda: Attentive feature refinement for domain adaptive se- mantic segmentation.IEEE Robotics and Automation Let- ters, 2025
Md Al-Masrur Khan, Durgakant Pushp, and Lantao Liu. Afrda: Attentive feature refinement for domain adaptive se- mantic segmentation.IEEE Robotics and Automation Let- ters, 2025. 3
2025
-
[22]
Pointrend: Image segmentation as rendering
Alexander Kirillov, Yuxin Wu, Kaiming He, and Ross Gir- shick. Pointrend: Image segmentation as rendering. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9769–9778, 2020. 2
2020
-
[23]
Semantic flow for fast and accurate scene parsing
Xiangtai Li, Ansheng You, Zhen Zhu, Houlong Zhao, Ming Yang, Kuiyuan Yang, and Yunhai Tong. Semantic flow for fast and accurate scene parsing. InEuropean Conference on Computer Vision, pages 775–793. Springer, 2020. 3
2020
-
[24]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014. 7
2014
-
[25]
arXiv preprint arXiv:2401.10166 , year=
Yue Liu, Yunjie Tian, Yuzhi Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, and Yu Qiao. Vmamba: Visual state space model.arXiv preprint arXiv:2401.10166, 2024. 2
-
[26]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021. 8
2021
-
[27]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yunchao Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10012–10022, 2021. 1
2021
-
[28]
A convnet for the 2020s
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feicht- enhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 11976–11986,
-
[29]
Fully convolutional networks for semantic segmentation
Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. InPro- ceedings of the IEEE conference on computer vision and pat- tern recognition, pages 3431–3440, 2015. 1, 2
2015
-
[30]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 7
work page internal anchor Pith review arXiv 2017
-
[31]
Attention-based conditioning methods for ex- ternal knowledge integration
Katerina Margatina, Christos Baziotis, and Alexandros Potamianos. Attention-based conditioning methods for ex- ternal knowledge integration. InProceedings of the 57th an- nual meeting of the association for computational linguis- tics, pages 3944–3951, 2019. 2
2019
-
[32]
Vcmamba: Bridging convolutions with multi-directional mamba for efficient visual representation
Mustafa Munir, Alex Zhang, and Radu Marculescu. Vcmamba: Bridging convolutions with multi-directional mamba for efficient visual representation. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 3037–3046, 2025. 2
2025
-
[33]
The mapillary vistas dataset for semantic understanding of street scenes
Gerhard Neuhold, Tobias Ollmann, Samuel Rota Bulo, and Peter Kontschieder. The mapillary vistas dataset for semantic understanding of street scenes. InProceedings of the IEEE international conference on computer vision, pages 4990– 4999, 2017. 7
2017
-
[34]
U- net: Convolutional networks for biomedical image segmen- tation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U- net: Convolutional networks for biomedical image segmen- tation. InInternational Conference on Medical image com- puting and computer-assisted intervention, pages 234–241. Springer, 2015. 2
2015
-
[35]
Imagenet large scale visual recognition challenge.International journal of computer vision, 115(3):211–252, 2015
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, San- jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge.International journal of computer vision, 115(3):211–252, 2015. 7
2015
-
[36]
Visual state space models with spiral selective scan for referring remote-sensing image segmentation.Geo- spatial Information Science, pages 1–19, 2026
Weihao Shen, Ailong Ma, Zhuo Zheng, Junjue Wang, and Yanfei Zhong. Visual state space models with spiral selective scan for referring remote-sensing image segmentation.Geo- spatial Information Science, pages 1–19, 2026. 2
2026
-
[37]
Training region-based object detectors with online hard ex- ample mining
Abhinav Shrivastava, Abhinav Gupta, and Ross Girshick. Training region-based object detectors with online hard ex- ample mining. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 761–769,
-
[38]
Gated convolutional neural network for semantic segmentation in high-resolution images
Towaki Takikawa, David Acuna, Varun Jampani, and Sanja Fidler. Gated convolutional neural network for semantic segmentation in high-resolution images. InProceedings of the IEEE/CVF international conference on computer vision, pages 5287–5296, 2019. 2, 8
2019
-
[39]
Training data-efficient image transform- ers & distillation through attention
Hugo Touvron et al. Training data-efficient image transform- ers & distillation through attention. InICML, 2021. 1
2021
-
[40]
Attention is all you need
Ashish Vaswani et al. Attention is all you need. InAdvances in neural information processing systems, 2017. 1
2017
-
[41]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 2
2017
-
[42]
Internimage: Exploring large-scale vision founda- tion models with deformable convolutions
Jice Wang, Jifeng Dai, Zhe Chen, Lewei Huang, Zhiqi Li, Xizhou Zhu, Xiaowei Hu, Tong Lu, Lewei Lu, Hongsheng Li, et al. Internimage: Exploring large-scale vision founda- tion models with deformable convolutions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14408–14419, 2023. 1
2023
-
[43]
Dfam-detr: De- formable feature based attention mechanism detr on slender object detection.IEICE TRANSACTIONS on Information and Systems, 106(3):401–409, 2023
Feng Wen, Mei Wang, and Xiaojie Hu. Dfam-detr: De- formable feature based attention mechanism detr on slender object detection.IEICE TRANSACTIONS on Information and Systems, 106(3):401–409, 2023. 3
2023
-
[44]
Segformer: Simple and efficient design for semantic segmentation with transform- ers.Advances in neural information processing systems, 34:12077–12090, 2021
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. Segformer: Simple and efficient design for semantic segmentation with transform- ers.Advances in neural information processing systems, 34:12077–12090, 2021. 1, 2, 8
2021
-
[45]
Deeperlab: Single-shot image parser.arXiv preprint arXiv:1902.05093, 2019
Tien-Ju Yang, Maxwell D Collins, Yukun Zhu, Jyh-Jing Hwang, Ting Liu, Xiao Zhang, Vivienne Sze, George Pa- pandreou, and Liang-Chieh Chen. Deeperlab: Single-shot image parser.arXiv preprint arXiv:1902.05093, 2019. 2
-
[46]
Context prior for scene segmentation
Changqian Yu, Jingbo Wang, Changxin Gao, Gang Yu, Chunhua Shen, and Nong Sang. Context prior for scene segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12416– 12425, 2020. 2
2020
-
[47]
Multi-Scale Context Aggregation by Dilated Convolutions
Fisher Yu and Vladlen Koltun. Multi-scale context aggregation by dilated convolutions.arXiv preprint arXiv:1511.07122, 2015. 3
work page Pith review arXiv 2015
-
[48]
Object- contextual representations for semantic segmentation
Yuhui Yuan, Xilin Chen, and Jingdong Wang. Object- contextual representations for semantic segmentation. In European conference on computer vision, pages 173–190. Springer, 2020. 8, 9
2020
-
[49]
Compact generalized non-local network.Ad- vances in neural information processing systems, 31, 2018
Kaiyu Yue, Ming Sun, Yuchen Yuan, Feng Zhou, Errui Ding, and Fuxin Xu. Compact generalized non-local network.Ad- vances in neural information processing systems, 31, 2018. 2
2018
-
[50]
Con- text encoding for semantic segmentation
Hang Zhang, Kristin Dana, Jianping Shi, Zhongyue Zhang, Xiaogang Wang, Ambrish Tyagi, and Amit Agrawal. Con- text encoding for semantic segmentation. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 7151–7160, 2018. 2
2018
-
[51]
Dual-path knowledge-augmented contrastive alignment network for spatially resolved transcriptomics
Wei Zhang, Jiajun Chu, Xinci Liu, Chen Tong, and Xinyue Li. Dual-path knowledge-augmented contrastive alignment network for spatially resolved transcriptomics. InProceed- ings of the AAAI Conference on Artificial Intelligence, vol- ume 40, pages 12807–12815, 2026. 3
2026
-
[52]
Pyramid scene parsing network
Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2881–2890, 2017. 1, 2, 10
2017
-
[53]
Psanet: Point-wise spatial attention network for scene parsing
Hengshuang Zhao, Yi Zhang, Shu Liu, Jianping Shi, Chen Change Loy, Dahua Lin, and Jiaya Jia. Psanet: Point-wise spatial attention network for scene parsing. InProceedings of the European conference on computer vision (ECCV), pages 267–283, 2018. 8
2018
-
[54]
Rsmamba: Remote sensing image classifi- cation with state space model.IEEE Geoscience and Remote Sensing Letters, 2024
Keyan Zhao et al. Rsmamba: Remote sensing image classifi- cation with state space model.IEEE Geoscience and Remote Sensing Letters, 2024. 2
2024
-
[55]
Rethinking semantic segmen- tation from a sequence-to-sequence perspective with trans- formers
Sixiao Zheng, Jiachen Lu, Hengshuang Zhao, Xiatian Zhu, Zekun Luo, Yabiao Wang, Yanwei Fu, Jianfeng Feng, Tao Xiang, Philip HS Torr, et al. Rethinking semantic segmen- tation from a sequence-to-sequence perspective with trans- formers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6881–6890,
-
[56]
Scene parsing through ade20k dataset
Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 633–641,
-
[57]
Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang. Vision mamba: Efficient visual representation learning with bidirectional state space model.arXiv preprint arXiv:2401.09417, 2024. 2, 8
work page internal anchor Pith review arXiv 2024
-
[58]
Asymmetric non-local neural net- works for semantic segmentation
Zhen Zhu, Mengde prescribed Xu, Song Bai, Tengteng Huang, and Xiang Bai. Asymmetric non-local neural net- works for semantic segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 593–602, 2019. 2
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.