Recognition: unknown
Enhanced Privacy and Communication Efficiency in Non-IID Federated Learning with Adaptive Quantization and Differential Privacy
Pith reviewed 2026-05-08 08:19 UTC · model grok-4.3
The pith
Adaptive quantization and Laplacian differential privacy cut communication in non-IID federated learning by up to 52 percent while keeping competitive accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
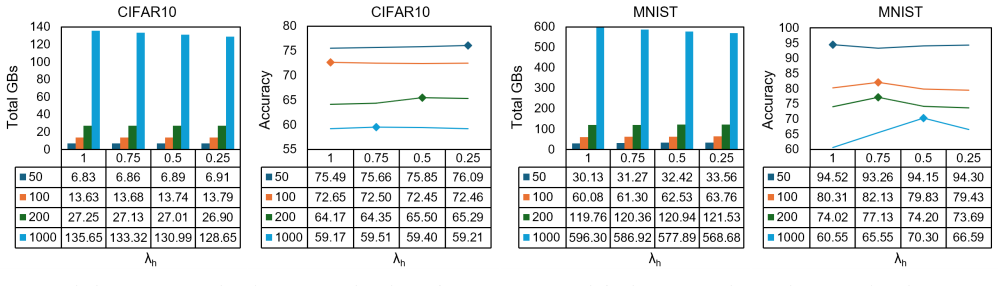
The authors demonstrate that Laplacian differential privacy combined with a round-based cosine-annealing global scheduler and an entropy-driven client scheduler reduces the total volume of communicated data by up to 52.64 percent on MNIST, 45.06 percent on CIFAR-10, and 31 to 37 percent on medical imaging datasets relative to 32-bit float training, while model accuracy remains competitive and privacy guarantees hold under the chosen privacy budgets.
What carries the argument
Dual adaptive quantization schedulers paired with Laplacian noise: the global scheduler varies bit length via cosine annealing across rounds, and the client scheduler selects bits according to local dataset entropy to reduce gradient transmission size while preserving contribution and privacy.
If this is right
- Communication volume drops 30-50 percent on standard image benchmarks without substantial accuracy loss.
- The same schedulers deliver 31-37 percent savings on medical imaging data while adding privacy protection.
- Laplacian noise provides the required privacy bounds across the tested client counts and non-IID partitions.
- Accuracy stays competitive when bit lengths are adapted dynamically rather than fixed at full precision.
Where Pith is reading between the lines
- The entropy measure may need re-validation when the approach is applied to non-image data such as text or sensor streams.
- Further savings could appear if the schedulers are combined with existing gradient compression methods beyond quantization.
- Production deployments would require checking whether the chosen bit-length schedules remain stable when client data statistics drift over time.
Load-bearing premise
The entropy-based client scheduler and cosine-annealing global scheduler continue to preserve model accuracy on non-IID partitions even after bit lengths are lowered and Laplacian noise is added, without the choices being tuned too closely to these particular datasets.
What would settle it
Apply the method to a new non-IID medical imaging dataset with 50 or more clients using the same schedulers and privacy budget; if accuracy drops more than 4 percentage points below the 32-bit baseline or communication savings fall below 25 percent, the central claim does not hold.
Figures






read the original abstract
Federated learning (FL) is a distributed machine learning method where multiple devices collaboratively train a model under the management of a central server without sharing underlying data. One of the key challenges of FL is the communication bottleneck caused by variations in connection speed and bandwidth across devices. Therefore, it is essential to reduce the size of transmitted data during training. Additionally, there is a potential risk of exposing sensitive information through the model or gradient analysis during training. To address both privacy and communication efficiency, we combine differential privacy (DP) and adaptive quantization methods. We use Laplacian-based DP to preserve privacy, which is relatively underexplored in FL and offers tighter privacy guarantees than Gaussian-based DP. We propose a simple and efficient global bit-length scheduler using round-based cosine annealing, along with a client-based scheduler that dynamically adapts based on client contribution estimated through dataset entropy analysis. We evaluate our approach through extensive experiments on CIFAR10, MNIST, and medical imaging datasets, using non-IID data distributions across varying client counts, bit-length schedulers, and privacy budgets. The results show that our adaptive quantization methods reduce total communicated data by up to 52.64% for MNIST, 45.06% for CIFAR10, and 31% to 37% for medical imaging datasets compared to 32-bit float training while maintaining competitive model accuracy and ensuring robust privacy through differential privacy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes combining Laplacian differential privacy with adaptive quantization in non-IID federated learning. It introduces a cosine-annealing global bit-length scheduler and an entropy-based client scheduler to reduce communication overhead while preserving privacy and model accuracy. Experiments on MNIST, CIFAR10, and medical imaging datasets report communication reductions of up to 52.64%, 45.06%, and 31-37% versus 32-bit float baselines, with competitive accuracy under varying client counts, non-IID partitions, and privacy budgets.
Significance. If the experimental claims hold after addressing robustness concerns, the work could meaningfully advance practical FL systems by jointly tackling bandwidth limits and privacy in heterogeneous data regimes. The use of Laplacian noise (less common than Gaussian in FL) and dynamic schedulers based on entropy and annealing represent targeted contributions to efficiency without sacrificing utility.
major comments (3)
- [Abstract] Abstract and experimental results: The reported accuracy maintenance and percentage reductions (e.g., 52.64% for MNIST) are stated without baselines beyond 32-bit floats, run-to-run variance, statistical significance tests, or exact epsilon/delta values for the Laplacian DP mechanism; this is load-bearing for the central claim that the schedulers incur no unacceptable accuracy cost.
- [Method (schedulers)] Schedulers description and evaluation: The entropy-based client scheduler and cosine-annealing global scheduler are inherently data-dependent (entropy computed per-client local distribution; bits annealed per round); the manuscript must include ablations on modest changes to Dirichlet non-IID parameters, client counts, and unseen partitions to show the bit-length sequences are not implicitly overfit to the reported setups, as this directly supports generalization of the communication savings.
- [Experiments] Privacy-utility tradeoff section: While Laplacian DP is claimed to provide robust privacy, the paper should report the precise privacy budgets (epsilon values) used in each dataset/experiment and quantify any accuracy degradation attributable to the added noise versus the quantization alone.
minor comments (2)
- [Abstract] The abstract would benefit from briefly stating the range of client counts and training rounds employed to contextualize the results.
- [Figures] Ensure all figures include error bars or multiple-run statistics for accuracy and communication metrics.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. We address each of the major comments below and have revised the manuscript accordingly to strengthen the presentation of our results and methods.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental results: The reported accuracy maintenance and percentage reductions (e.g., 52.64% for MNIST) are stated without baselines beyond 32-bit floats, run-to-run variance, statistical significance tests, or exact epsilon/delta values for the Laplacian DP mechanism; this is load-bearing for the central claim that the schedulers incur no unacceptable accuracy cost.
Authors: We acknowledge that the abstract and main results would be strengthened by including measures of variability and explicit privacy parameters. In the revised manuscript, we have updated the abstract to mention that results are averaged over multiple runs with standard deviations reported in the experimental tables. We have also added statistical significance testing (Wilcoxon signed-rank test) to confirm that accuracy differences are not significant in most cases. Furthermore, we now explicitly report the epsilon and delta values used for the Laplacian mechanism in each experiment (e.g., ε=2.0, δ=10^{-5} for MNIST). These details are added to Section 4 and the abstract has been lightly revised for clarity. This addresses the concern regarding the robustness of our accuracy claims. revision: yes
-
Referee: [Method (schedulers)] Schedulers description and evaluation: The entropy-based client scheduler and cosine-annealing global scheduler are inherently data-dependent (entropy computed per-client local distribution; bits annealed per round); the manuscript must include ablations on modest changes to Dirichlet non-IID parameters, client counts, and unseen partitions to show the bit-length sequences are not implicitly overfit to the reported setups, as this directly supports generalization of the communication savings.
Authors: We agree that demonstrating robustness to variations in the non-IID degree and client numbers is important for validating the schedulers. While our original experiments already varied client counts (from 10 to 100) and used different Dirichlet parameters for partitioning, we have added dedicated ablation studies in the revised version. These include results for alpha values of 0.1, 0.5, and 1.0, additional client counts, and evaluation on partitions not seen during any hyperparameter selection. The communication reduction percentages remain consistent (within 5% variation), supporting that the schedulers generalize well. We have included these in a new subsection of the experiments. revision: yes
-
Referee: [Experiments] Privacy-utility tradeoff section: While Laplacian DP is claimed to provide robust privacy, the paper should report the precise privacy budgets (epsilon values) used in each dataset/experiment and quantify any accuracy degradation attributable to the added noise versus the quantization alone.
Authors: This is a valid point for clarifying the contributions. In the revised manuscript, we have added a new table in the privacy-utility tradeoff section that lists the exact epsilon values for every reported experiment across all datasets. Additionally, we include a comparison where we run the adaptive quantization without the Laplacian noise and report the accuracy difference, isolating the impact of the DP mechanism (typically a 0.5-2.5% drop in accuracy for the epsilon values used). This quantification helps readers understand the tradeoff more precisely. revision: yes
Circularity Check
No significant circularity; empirical claims rest on experimental outcomes
full rationale
The paper proposes adaptive quantization schedulers (cosine-annealing global and entropy-based client) combined with Laplacian DP for non-IID FL, then reports measured communication reductions (e.g., 52.64% on MNIST) and accuracy maintenance across datasets and client counts. No derivation chain, first-principles equations, or predictions are presented that reduce by construction to fitted inputs, self-citations, or ansatzes. All load-bearing claims are grounded in direct experimental runs rather than algebraic identities or renamed empirical patterns, rendering the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, ‘‘Communication-efficient learning of deep networks from decentralized data,’’ inProc. 20th Int. Conf. Artif. Intell. Stat. (AISTATS), ser. Proc. Mach. Learn. Res., vol. 54, Apr. 2017, pp. 1273–1282
2017
-
[2]
T. Li, A. K. Sahu, A. Talwalkar, and V . Smith, ‘‘Federated learning: Challenges, methods, and future directions,’’IEEE Signal Process. Mag., vol. 37, no. 3, pp. 50–60, 2020
2020
-
[3]
Huang, F
J. Huang, F. Qian, Y . Guo, Y . Zhou, Q. Xu, Z. M. Mao, S. Sen, and O. Spatscheck, ‘‘An in-depth study of lte: Effect of network protocol and application behavior on performance,’’ACM SIGCOMM Comput. Commun. Rev., vol. 43, no. 4, pp. 363–374, 2013
2013
-
[4]
Protection Against Reconstruction and Its Applications in Private Federated Learning, June 2019
A. Bhowmick, J. Duchi, J. Freudiger, G. Kapoor, and R. Rogers, ‘‘Pro- tection against reconstruction and its applications in private federated learning,’’ 2018, arXiv:1812.00984
-
[5]
Carlini, C
N. Carlini, C. Liu, Ú. Erlingsson, J. Kos, and D. Song, ‘‘The secret sharer: Evaluating and testing unintended memorization in neural networks,’’ in Proc. 28th USENIX Security Symp. (USENIX Security), Aug. 2019, pp. 267–284
2019
-
[6]
Sattler, S
F. Sattler, S. Wiedemann, K.-R. Müller, and W. Samek, ‘‘Robust and communication-efficient federated learning from non-i.i.d. data,’’IEEE Trans. Neural Netw. Learn. Syst., vol. 31, no. 9, pp. 3400–3413, 2020
2020
-
[7]
R. M. Gray,Entropy and Information Theory. Springer, 2011
2011
-
[8]
Federated Learning: Strategies for Improving Communication Efficiency
J. Konečn `y, H. B. McMahan, F. X. Y u, P . Richtárik, A. T. Suresh, and D. Bacon, ‘‘Federated learning: Strategies for improving communication efficiency,’’ 2016, arXiv:1610.05492
work page internal anchor Pith review arXiv 2016
-
[9]
Wangni, J
J. Wangni, J. Wang, J. Liu, and T. Zhang, ‘‘Gradient sparsification for communication-efficient distributed optimization,’’ inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 31, 2018
2018
-
[10]
H. Wang, S. Sievert, S. Liu, Z. Charles, D. Papailiopoulos, and S. Wright, ‘‘Atomo: Communication-efficient learning via atomic sparsification,’’ in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 31, 2018
2018
- [11]
-
[12]
H. Tang, S. Gan, C. Zhang, T. Zhang, and J. Liu, ‘‘Communication com- pression for decentralized training,’’ inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 31, 2018
2018
- [13]
-
[14]
L. Chen, W. Liu, Y . Chen, and W. Wang, ‘‘Communication-efficient de- sign for quantized decentralized federated learning,’’IEEE Trans. Signal Process., vol. 72, pp. 1175–1188, 2024
2024
-
[15]
Y ang, S
Y . Y ang, S. Dang, and Z. Zhang, ‘‘An adaptive compression and commu- nication framework for wireless federated learning,’’IEEE Trans. Mobile Comput., vol. 23, no. 12, pp. 10 835–10 854, 2024
2024
-
[16]
Bernstein, Y .-X
J. Bernstein, Y .-X. Wang, K. Azizzadenesheli, and A. Anandkumar, ‘‘signsgd: Compressed optimisation for non-convex problems,’’ inProc. 35th Int. Conf. Machine Learning (ICML), 2018, pp. 560–569
2018
-
[17]
W. Wen, C. Xu, F. Y an, C. Wu, Y . Wang, Y . Chen, and H. Li, ‘‘Terngrad: Ternary gradients to reduce communication in distributed deep learning,’’ inProc. Adv. Neural Inf. Process. Syst., vol. 30, 2017
2017
-
[18]
Alistarh, D
D. Alistarh, D. Grubic, J. Li, R. Tomioka, and M. V ojnovic, ‘‘Qsgd: Communication-efficient sgd via gradient quantization and encoding,’’ in Proc. Adv. Neural Inf. Process. Syst., vol. 30, 2017
2017
-
[19]
Jhunjhunwala, A
D. Jhunjhunwala, A. Gadhikar, G. Joshi, and Y . C. Eldar, ‘‘Adaptive quan- tization of model updates for communication-efficient federated learning,’’ inProc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP), 2021, pp. 3110–3114
2021
-
[20]
L. Qu, S. Song, and C.-Y . Tsui, ‘‘Feddq: Communication-efficient feder- ated learning with descending quantization,’’ inProc. IEEE Global Com- mun. Conf. (GLOBECOM), 2022, pp. 281–286
2022
- [21]
-
[22]
Abadi, A
M. Abadi, A. Chu, I. Goodfellow, H. B. McMahan, I. Mironov, K. Talwar, and L. Zhang, ‘‘Deep learning with differential privacy,’’ inProc. ACM SIGSAC Conf. Comput. Commun. Security (CCS), 2016, pp. 308–318
2016
-
[23]
Iyengar, J
R. Iyengar, J. P . Near, D. Song, O. Thakkar, A. Thakurta, and L. Wang, ‘‘Towards practical differentially private convex optimization,’’ inProc. IEEE Symp. Security Privacy (SP), 2019, pp. 299–316
2019
-
[24]
Y . Zhou, R. Wang, J. Liu, D. Wu, S. Y u, and Y . Wen, ‘‘Exploring the practicality of differentially private federated learning: A local iteration tuning approach,’’IEEE Trans. Dependable Secure Comput., vol. 21, no. 4, pp. 3280–3294, 2024. 14
2024
- [25]
- [26]
- [27]
- [28]
-
[29]
Andrew, O
G. Andrew, O. Thakkar, B. McMahan, and S. Ramaswamy, ‘‘Differentially private learning with adaptive clipping,’’ inProc. Adv. Neural Inf. Process. Syst., vol. 34, 2021, pp. 17 455–17 466
2021
-
[30]
Bonawitz, V
K. Bonawitz, V . Ivanov, B. Kreuter, A. Marcedone, H. B. McMahan, S. Patel, D. Ramage, A. Segal, and K. Seth, ‘‘Practical secure aggregation for privacy-preserving machine learning,’’ inProc. ACM SIGSAC Conf. Comput. Commun. Security (CCS), 2017, pp. 1175–1191
2017
- [31]
-
[32]
Tariq, M
A. Tariq, M. A. Serhani, F. M. Sallabi, E. S. Barka, T. Qayyum, H. M. Khater, and K. A. Shuaib, ‘‘Trustworthy federated learning: A comprehen- sive review, architecture, key challenges, and future research prospects,’’ IEEE Open J. Commun. Soc., vol. 5, pp. 4920–4998, 2024
2024
-
[33]
N. Lang, E. Sofer, T. Shaked, and N. Shlezinger, ‘‘Joint privacy enhance- ment and quantization in federated learning,’’IEEE Trans. Signal Process., vol. 71, pp. 295–310, 2023
2023
- [34]
- [35]
- [36]
-
[37]
Deng, ‘‘The mnist database of handwritten digit images for machine learning research,’’IEEE Signal Process
L. Deng, ‘‘The mnist database of handwritten digit images for machine learning research,’’IEEE Signal Process. Mag., vol. 29, no. 6, pp. 141– 142, 2012
2012
-
[38]
Krizhevsky and G
A. Krizhevsky and G. Hinton, ‘‘Learning multiple layers of features from tiny images,’’ Univ. Toronto, Tech. Rep., 2009, [Online]. Available: https: //www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
2009
-
[39]
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smith, ‘‘Fed- erated optimization in heterogeneous networks,’’ inProc. Mach. Learn. Syst., vol. 2, 2020, pp. 429–450
2020
- [40]
-
[41]
K. Wei, J. Li, M. Ding, C. Ma, H. H. Y ang, F. Farokhi, S. Jin, T. Q. S. Quek, and H. V . Poor, ‘‘Federated learning with differential privacy: Algorithms and performance analysis,’’IEEE Trans. Inf. F orensics Security, vol. 15, pp. 3454–3469, 2020
2020
-
[42]
C. Ma, J. Li, M. Ding, H. H. Y ang, F. Shu, T. Q. Quek, and H. V . Poor, ‘‘On safeguarding privacy and security in the framework of federated learning,’’ IEEE Netw., vol. 34, no. 4, pp. 242–248, 2020
2020
-
[43]
Z. Wang, M. Song, Z. Zhang, Y . Song, Q. Wang, and H. Qi, ‘‘Beyond inferring class representatives: User-level privacy leakage from federated learning,’’ inProc. IEEE Conf. Comput. Commun. (INFOCOM), 2019, pp. 2512–2520
2019
-
[44]
C. He, S. Li, J. So, X. Zeng, M. Zhang, H. Wang, X. Wang, P . V epakomma, A. Singh, H. Qiu, X. Zhu, J. Wang, L. Shen, P . Zhao, Y . Kang, Y . Liu, R. Raskar, Q. Y ang, M. Annavaram, and S. Avestimehr, ‘‘Fedml: A research library and benchmark for federated machine learning,’’ 2020, arXiv:2007.13518
- [45]
-
[46]
A. Li, L. Zhang, J. Tan, Y . Qin, J. Wang, and X.-Y . Li, ‘‘Sample-level data selection for federated learning,’’ inProc. IEEE Conf. Comput. Commun. (INFOCOM), 2021, pp. 1–10
2021
-
[47]
Ardıç and Y
E. Ardıç and Y . Genç, ‘‘Data valuation methods for federated learning,’’ in Proc. 31st Signal Process. Commun. Appl. Conf. (SIU), 2023, pp. 1–4
2023
-
[48]
——, ‘‘Sample selection using multi-task autoencoders in federated learn- ing with non-iid data,’’Eng. Sci. Technol. Int. J., vol. 61, p. 101920, 2025
2025
-
[49]
M. E. Plissiti, P . Dimitrakopoulos, G. Sfikas, C. Nikou, O. Krikoni, and A. Charchanti, ‘‘Sipakmed: A new dataset for feature and image based clas- sification of normal and pathological cervical cells in pap smear images,’’ inProc. IEEE Int. Conf. Image Process. (ICIP), 2018, pp. 3144–3148
2018
-
[50]
D. Kermany, K. Zhang, and M. Goldbaum, ‘‘Large dataset of labeled opti- cal coherence tomography (oct) and chest x-ray images,’’ 2018, Mendeley Data, doi: 10.17632/rscbjbr9sj.3
-
[51]
F. A. Spanhol, L. S. Oliveira, C. Petitjean, and L. Heutte, ‘‘A dataset for breast cancer histopathological image classification,’’IEEE Trans. Biomed. Eng., vol. 63, no. 7, pp. 1455–1462, 2016. EMRE ARDIÇreceived the B.S. and M.S. degrees in computer engineering from Gebze Technical University, Kocaeli, Turkey, in 2014 and 2018, respectively. Since 2018, ...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.