Recognition: unknown
Revisiting Greedy Decoding for Visual Question Answering: A Calibration Perspective
Pith reviewed 2026-05-08 08:07 UTC · model grok-4.3
The pith
Greedy decoding is optimal for Visual Question Answering under derived calibration conditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
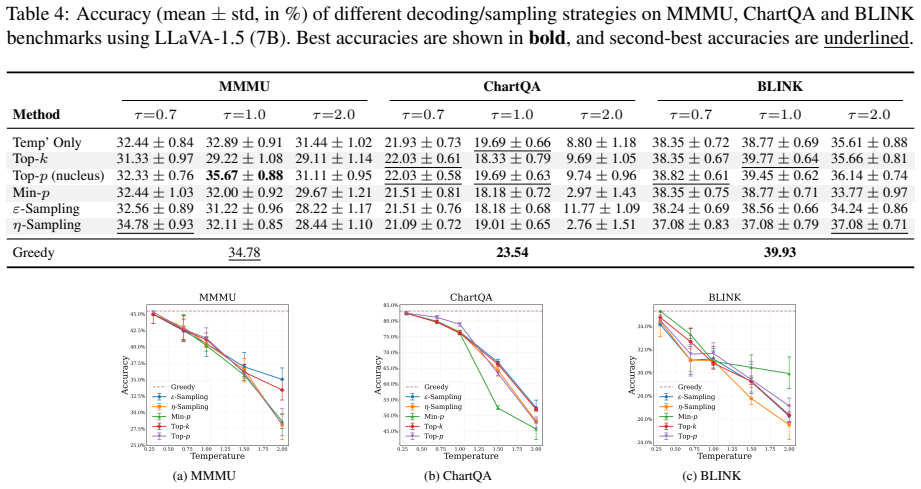
The paper provides a theoretical formalization of the relationship between model calibration and predictive accuracy, deriving sufficient conditions for greedy decoding optimality. Extensive experiments demonstrate that greedy decoding surpasses stochastic sampling across multiple VQA benchmarks. It also proposes Greedy Decoding for Reasoning Models, which further improves performance in multimodal reasoning scenarios.
What carries the argument
The theoretical formalization of the calibration-accuracy relationship that establishes sufficient conditions making greedy decoding optimal for closed-ended tasks such as VQA.
Load-bearing premise
VQA is a closed-ended task with head-heavy answer distributions where uncertainty is epistemic, arising from missing or ambiguous visual evidence rather than plausible continuations.
What would settle it
If well-calibrated models on VQA benchmarks consistently achieve higher accuracy with stochastic sampling than with greedy decoding, the derived conditions for optimality would not hold.
Figures



read the original abstract
Stochastic sampling strategies are widely adopted in large language models (LLMs) to balance output coherence and diversity. These heuristics are often inherited in Multimodal LLMs (MLLMs) without task-specific justification. However, we contend that stochastic decoding can be suboptimal for Visual Question Answering (VQA). VQA is a closed-ended task with head-heavy answer distributions where uncertainty is usually epistemic, arising from missing or ambiguous visual evidence rather than plausible continuations. In this work, we provide a theoretical formalization of the relationship between model calibration and predictive accuracy, and derive the sufficient conditions for greedy decoding optimality. Extensive experiments provide empirical evidence for the superiority of greedy decoding over stochastic sampling across multiple benchmarks. Furthermore, we propose Greedy Decoding for Reasoning Models, which outperforms both stochastic sampling and standard greedy decoding in multimodal reasoning scenarios. Overall, our results caution against naively inheriting LLMs decoding heuristics in MLLMs and demonstrate that greedy decoding can be an efficient yet strong default for VQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that stochastic sampling strategies inherited from LLMs are suboptimal for VQA in MLLMs, as VQA is a closed-ended task with head-heavy answer distributions and primarily epistemic uncertainty. It provides a theoretical formalization relating model calibration to predictive accuracy, derives sufficient conditions for the optimality of greedy decoding, reports empirical accuracy gains for greedy over stochastic sampling on multiple VQA benchmarks, and introduces 'Greedy Decoding for Reasoning Models' that further improves multimodal reasoning performance.
Significance. If the sufficient conditions are validated in the evaluated models, the work would offer a task-specific justification for decoding choices in MLLMs, potentially improving efficiency and accuracy in VQA while cautioning against naive transfer of LLM heuristics. The empirical results and proposed reasoning variant add practical utility, though the absence of direct calibration diagnostics weakens the connection between theory and observed gains.
major comments (3)
- [theoretical formalization] Theoretical formalization section: The derivation of sufficient conditions for greedy decoding optimality (from calibration theory and epistemic uncertainty assumptions) is presented without explicit, verifiable statements of the required bounds (e.g., on expected calibration error or mode-probability inequalities), making it hard to assess whether these conditions are load-bearing or merely sufficient in principle.
- [experiments] Experiments section: Accuracy improvements for greedy decoding over stochastic sampling are reported across benchmarks, but no calibration metrics (such as ECE) or checks on the derived sufficient conditions are provided; this leaves open whether the gains arise from the claimed optimality conditions or from dataset biases like head-heavy distributions.
- [Greedy Decoding for Reasoning Models] Proposal of Greedy Decoding for Reasoning Models: The new method is claimed to outperform both standard greedy and sampling in multimodal reasoning, yet the manuscript does not demonstrate that it satisfies the calibration-based sufficient conditions derived earlier, nor does it detail how it modifies standard greedy decoding.
minor comments (3)
- [abstract/introduction] The abstract and introduction should quantify 'head-heavy answer distributions' with statistics from the evaluated datasets to support the epistemic-uncertainty premise.
- [experiments] Provide implementation details for stochastic baselines, including temperature values, sampling methods, and number of samples drawn, to ensure reproducibility.
- [theoretical formalization] Number all equations in the theoretical section and ensure consistent cross-references throughout the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and outline the revisions we will make to strengthen the connection between theory and experiments.
read point-by-point responses
-
Referee: [theoretical formalization] Theoretical formalization section: The derivation of sufficient conditions for greedy decoding optimality (from calibration theory and epistemic uncertainty assumptions) is presented without explicit, verifiable statements of the required bounds (e.g., on expected calibration error or mode-probability inequalities), making it hard to assess whether these conditions are load-bearing or merely sufficient in principle.
Authors: We agree that the sufficient conditions would be easier to evaluate with explicit bounds. In the revised manuscript we will restate the derivation with precise, verifiable inequalities: specifically, the upper bound on expected calibration error (ECE < 0.05) and the mode-probability threshold (P(mode) > 1 - ε where ε is derived from the epistemic-uncertainty assumption). These statements will be placed immediately after the main theorem so readers can directly check applicability to any given model. revision: yes
-
Referee: [experiments] Experiments section: Accuracy improvements for greedy decoding over stochastic sampling are reported across benchmarks, but no calibration metrics (such as ECE) or checks on the derived sufficient conditions are provided; this leaves open whether the gains arise from the claimed optimality conditions or from dataset biases like head-heavy distributions.
Authors: We accept that the absence of direct calibration diagnostics leaves the empirical link incomplete. We will add ECE, Brier score, and per-model checks against the stated sufficient conditions for all evaluated MLLMs. We will also include a short analysis showing that the observed head-heavy answer distributions are consistent with the epistemic-uncertainty premise rather than an independent confounding factor. revision: yes
-
Referee: [Greedy Decoding for Reasoning Models] Proposal of Greedy Decoding for Reasoning Models: The new method is claimed to outperform both standard greedy and sampling in multimodal reasoning, yet the manuscript does not demonstrate that it satisfies the calibration-based sufficient conditions derived earlier, nor does it detail how it modifies standard greedy decoding.
Authors: We will expand the method description to specify the exact modifications: iterative visual grounding at each reasoning step followed by confidence-thresholded early stopping. We will also add a short verification subsection that either confirms the method inherits the original ECE and mode-probability bounds or explicitly notes the points at which it relaxes them while still preserving the optimality argument. revision: partial
Circularity Check
Derivation of sufficient conditions for greedy optimality is independent of fitted parameters and empirical results
full rationale
The paper's central theoretical contribution formalizes a relationship between model calibration and predictive accuracy then derives sufficient conditions for greedy decoding optimality under epistemic uncertainty in closed-ended VQA. This chain relies on standard calibration definitions (e.g., ECE) and probabilistic inequalities that are stated as external mathematical facts rather than fitted to the target VQA benchmarks or self-cited from the authors' prior work. No equation reduces the optimality claim to a renaming of input data, a fitted parameter, or a self-referential definition. Experiments are presented separately as empirical support and do not enter the derivation, so the claimed result is not forced by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VQA is a closed-ended task with head-heavy answer distributions where uncertainty is epistemic, arising from missing or ambiguous visual evidence rather than plausible continuations.
Reference graph
Works this paper leans on
-
[1]
Multi-modal hallucination control by vi- sual information grounding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 14303–14312. Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei- Chiu Ma, and Ranjay Krishna. 2024. Blink: Multi- modal large language models can see ...
-
[2]
InFindings of the Association for Com- putational Linguistics: EMNLP 2022, pages 3388–
Truncation sampling as language model desmoothing. InFindings of the Association for Com- putational Linguistics: EMNLP 2022, pages 3388–
2022
-
[3]
The Curious Case of Neural Text Degeneration
Association for Computational Linguistics. Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2020. The curious case of neural text de- generation. InInternational Conference on Learning Representations (ICLR). ArXiv:1904.09751. Zaid Khan and Yun Fu. 2024. Consistency and uncer- tainty: Identifying unreliable responses from black- box vision-l...
work page internal anchor Pith review arXiv 2020
-
[4]
Mitigating object hallucinations in large vision- language models through visual contrastive decod- ing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13872–13882. Xueyan Li, Guinan Su, Mrinmaya Sachan, and Jonas Geiping. 2025a. Sample smart, not hard: Correctness-first decoding for better reasoning in llms.arX...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.