Recognition: unknown
From Edges to Depth: Probing the Spatial Hierarchy in Vision Transformers
Pith reviewed 2026-05-08 08:18 UTC · model grok-4.3
The pith
Classification-trained Vision Transformers encode spatial structure in a clear layer-wise hierarchy, with boundaries appearing before depth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A classification-trained ViT develops an actively maintained spatial hierarchy that mirrors the early-to-late progression observed in the primate visual cortex.
What carries the argument
Layer-wise linear probing for patch boundaries and per-patch depth, combined with single-direction ablation and targeted activation patching to test causal maintenance of the signals.
If this is right
- Boundary information is encoded earlier than depth because local cues can be extracted from smaller receptive fields while depth requires integration across the image.
- The depth signal is actively re-derived at multiple layers rather than passively carried forward in the residual stream.
- Mid-layer interventions on the depth direction persist more strongly to later layers than early or late interventions.
- Both spatial signals are discarded by the time the model reaches its final classification output.
Where Pith is reading between the lines
- The observed ordering may explain why classification-pretrained ViTs transfer readily to dense prediction tasks even though they receive no spatial labels during training.
- If the hierarchy is general, similar probing on other architectures could reveal whether the same early-to-late spatial progression appears outside transformers.
- The collapse of spatial signals at the final layer suggests that any downstream spatial task must read from intermediate layers rather than the classifier head.
Load-bearing premise
Linear probes and single-direction ablations faithfully isolate the model's internal spatial representations without artifacts from the probing process or dataset choices.
What would settle it
Ablating the direction identified by the depth probe fails to degrade depth decoding performance by more than a few percent, or the same layer-wise ordering of boundary-then-depth does not appear when the same probes are applied to a different classification-trained ViT.
Figures



read the original abstract
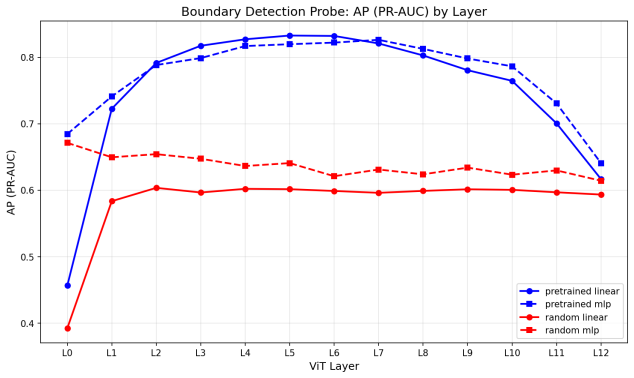
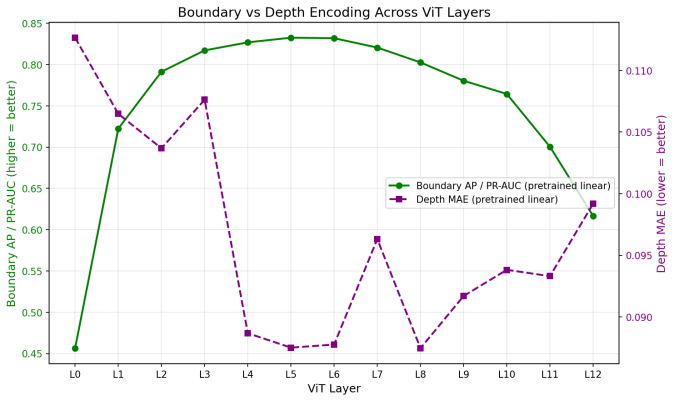
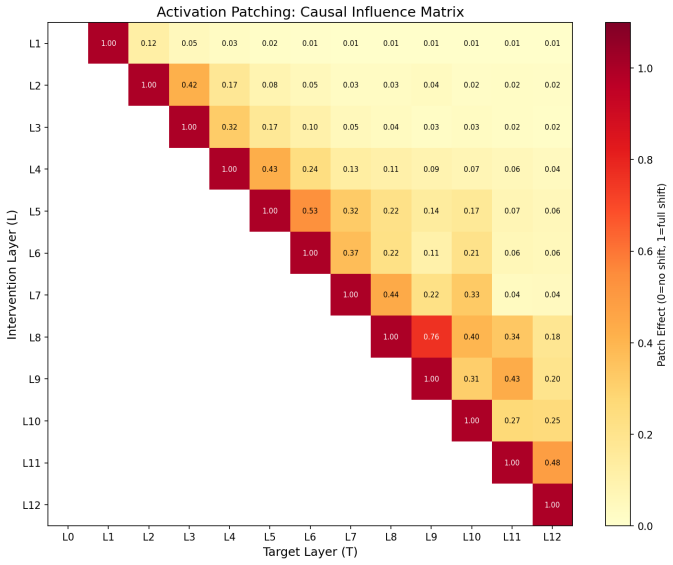
Vision Transformers trained only on image classification routinely transfer to tasks that demand spatial understanding, yet they receive no spatial supervision during pretraining. We ask where and how robustly such structure is encoded. Probing a frozen ViT-B/16 layerwise for two complementary properties, local patch boundaries (BSDS500) and per-patch depth (NYU Depth V2), reveals a clear hierarchy: boundary structure becomes linearly decodable at layers 5-6 (AP = 0.833), while depth, which requires integrating global cues, peaks two to three layers later at layer 8 (MAE = 0.0875). Both signals collapse at the final classification layer, and random-weight controls confirm the encodings are learned rather than architectural. Causal interventions add specificity: ablating the single direction a linear depth probe reads degrades depth decoding by up to 165%, while ablating any other direction changes it by less than 1%. Targeted activation patching along that direction shows the depth signal is partially re-derived at each layer rather than passively carried in the residual stream, with mid-layer interventions persisting most strongly downstream. The result is that a classification-trained ViT develops an actively maintained spatial hierarchy that mirrors the early-to-late progression observed in the primate visual cortex.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Vision Transformers pretrained solely on image classification develop an internal spatial hierarchy: linear probes on frozen ViT-B/16 layers show local boundary information (BSDS500) becoming decodable at layers 5-6 (AP=0.833) while global depth (NYU Depth V2) peaks at layer 8 (MAE=0.0875), both collapsing at the final layer. Random-weight controls confirm the encodings are learned. Causal interventions demonstrate specificity, with ablation of the depth-probe direction degrading performance by up to 165% (vs. <1% for other directions) and activation patching indicating the depth signal is actively re-derived rather than passively carried in the residual stream. The authors conclude this mirrors the early-to-late progression in primate visual cortex.
Significance. If the central claims hold after addressing verification gaps, the work provides concrete empirical evidence for emergent spatial structure in classification-only ViTs, using reproducible public datasets (BSDS500, NYU Depth V2) and linear probes. This strengthens understanding of how transformers acquire hierarchical representations without spatial supervision and offers a potential bridge to neuroscience findings on visual cortex organization. The ablation and patching results, if non-circular, would be a notable contribution to mechanistic interpretability in vision models.
major comments (3)
- [Abstract and §4] Abstract and §4 (causal interventions): The reported 165% degradation when ablating the single direction identified by the linear depth probe is partly tautological, as the direction is chosen precisely to align with that probe's readout; this does not independently establish that the model actively maintains a depth representation independent of the probe construction. A control using a held-out depth dataset, nonlinear probe, or orthogonal direction would be required to support the 'actively maintained' claim.
- [Abstract and §3] Abstract and §3 (probing results): The layer-wise progression (boundaries at 5-6, depth at 8) is reported with specific AP=0.833 and MAE=0.0875 but without error bars, multiple random seeds, or statistical tests for the differences across layers; this weakens the precision of the hierarchy claim and the assertion that depth 'peaks two to three layers later.'
- [§4] §4 (patching experiments): The claim that targeted patching shows the depth signal is 'partially re-derived at each layer' relies on persistence of the patched direction downstream, but without details on how re-derivation is quantified separately from residual-stream carry-over or probe sensitivity, it is unclear whether the intervention isolates active maintenance versus other dynamics.
minor comments (2)
- [Abstract] The abstract states 'random-weight controls confirm the encodings are learned' but provides no quantitative comparison values or layer-wise results for the random baseline.
- [§3 or §4] Notation for the depth direction (e.g., how the single direction is extracted from the probe weights) should be formalized with an equation in §3 or §4 to allow exact reproduction.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major point below, providing clarifications and indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (causal interventions): The reported 165% degradation when ablating the single direction identified by the linear depth probe is partly tautological, as the direction is chosen precisely to align with that probe's readout; this does not independently establish that the model actively maintains a depth representation independent of the probe construction. A control using a held-out depth dataset, nonlinear probe, or orthogonal direction would be required to support the 'actively maintained' claim.
Authors: We agree that the direction is identified via the linear probe and that this introduces some dependence. However, the key evidence for functional relevance lies in the extreme specificity of the effect: ablating this direction degrades depth decoding by up to 165%, while ablating any of the other 767 directions changes performance by less than 1%. This differential impact indicates that the direction encodes information the model relies upon, beyond mere probe construction. To further address the concern, we will add an orthogonal-direction ablation control in the revised §4, confirming that only the depth-aligned direction produces the large degradation. revision: partial
-
Referee: [Abstract and §3] Abstract and §3 (probing results): The layer-wise progression (boundaries at 5-6, depth at 8) is reported with specific AP=0.833 and MAE=0.0875 but without error bars, multiple random seeds, or statistical tests for the differences across layers; this weakens the precision of the hierarchy claim and the assertion that depth 'peaks two to three layers later.'
Authors: The referee correctly notes the absence of variability estimates and statistical support. We will recompute all linear probes across five random seeds, report mean values with standard-error bars, and include paired statistical tests (e.g., t-tests) comparing the peak-layer performance against the preceding and following layers. These additions will be incorporated into the revised §3 and abstract to rigorously substantiate the reported two-to-three-layer offset. revision: yes
-
Referee: [§4] §4 (patching experiments): The claim that targeted patching shows the depth signal is 'partially re-derived at each layer' relies on persistence of the patched direction downstream, but without details on how re-derivation is quantified separately from residual-stream carry-over or probe sensitivity, it is unclear whether the intervention isolates active maintenance versus other dynamics.
Authors: We will expand the methods and results in §4 to provide the missing quantification details. Re-derivation is measured by comparing the downstream probe readout after targeted patching against two controls: (i) a passive-carry baseline in which the same activation is injected but subsequent layer updates are zeroed, and (ii) a sensitivity-matched random-direction patch. The difference in persistence between the targeted patch and these controls isolates active re-derivation from residual-stream propagation and probe artifacts. Expanded equations and additional figures will be added to make this separation explicit. revision: partial
Circularity Check
Probe-derived direction ablation reduces to tautological degradation by construction
specific steps
-
fitted input called prediction
[Abstract (causal interventions)]
"ablating the single direction a linear depth probe reads degrades depth decoding by up to 165%, while ablating any other direction changes it by less than 1%."
The direction is extracted by fitting the linear probe to the model's activations for the depth task. Removing precisely that fitted direction and re-evaluating the identical linear probe on depth must produce large degradation by construction, as the probe's weights define the direction being removed. This does not independently establish that the ViT actively maintains depth information in that direction beyond the probe's own fitting assumptions.
full rationale
The paper's core results consist of layer-wise linear probing on external public datasets (BSDS500 for boundaries, NYU Depth V2 for depth) to measure when spatial signals become decodable in a frozen classification ViT. These measurements do not reduce to quantities defined by the probes themselves. However, the causal intervention step identifies a single direction via the linear depth probe and then ablates it to quantify degradation in the same depth decoding task. This step is partly tautological because any direction aligned by the probe fit will dominate removal effects on that probe. The patching experiments provide somewhat more independent evidence of re-derivation. Overall, the hierarchy claim retains independent empirical content from external benchmarks, but the ablation specificity claim has this reduction, warranting a moderate circularity score.
Axiom & Free-Parameter Ledger
free parameters (1)
- linear probe weights
axioms (2)
- domain assumption Linear decodability from activations indicates the presence of the corresponding information in the model
- domain assumption Ablating the probe direction isolates the causal contribution of that direction to downstream decoding
Reference graph
Works this paper leans on
-
[1]
Alain and Y
G. Alain and Y. Bengio. Understanding intermediate layers using linear classifier probes. In ICLR Workshop, 2017
2017
-
[2]
Belrose, D
N. Belrose, D. Schneider-Joseph, S. Ravfogel, R. Cotterell, E. Raff, and S. Biderman. LEACE : Perfect linear concept erasure in closed form. In NeurIPS, 2023
2023
-
[3]
Caron, H
M. Caron, H. Touvron, I. Misra, H. J \'e gou, J. Mairal, P. Bojanowski, and A. Joulin. Emerging properties in self-supervised vision transformers. In ICCV, 2021
2021
-
[4]
A. Chowdhury, S. Gupta, and A. Basu. PROMPT-CAM : A simpler interpretable transformer for fine-grained analysis. arXiv preprint arXiv:2501.09133, 2025
-
[5]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021
2021
-
[6]
How to use and interpret activation patching
S. Heimersheim and N. Nanda. How to use and interpret activation patching. arXiv preprint arXiv:2404.15255, 2024
work page internal anchor Pith review arXiv 2024
-
[7]
Hewitt and P
J. Hewitt and P. Liang. Designing and interpreting probes with control tasks. In EMNLP, 2019
2019
-
[8]
Hewitt and C
J. Hewitt and C. Manning. A structural probe for finding syntax in word representations. In NAACL, 2019
2019
-
[9]
Z. Lipton. The mythos of model interpretability. Queue, 16(3), 2018
2018
- [10]
-
[11]
Raghu, T
M. Raghu, T. Unterthiner, S. Kornblith, C. Zhang, and A. Dosovitskiy. Do vision transformers see like convolutional neural networks? In NeurIPS, 2021
2021
-
[12]
Silberman, D
N. Silberman, D. Hoiem, P. Kohli, and R. Fergus. Indoor segmentation and support inference from RGBD images. In ECCV, 2012
2012
- [13]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.