Recognition: unknown
Escher-Loop: Mutual Evolution by Closed-Loop Self-Referential Optimization
Pith reviewed 2026-05-08 07:53 UTC · model grok-4.3
The pith
Escher-Loop lets task agents and optimizer agents evolve each other in a closed loop to exceed static performance limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
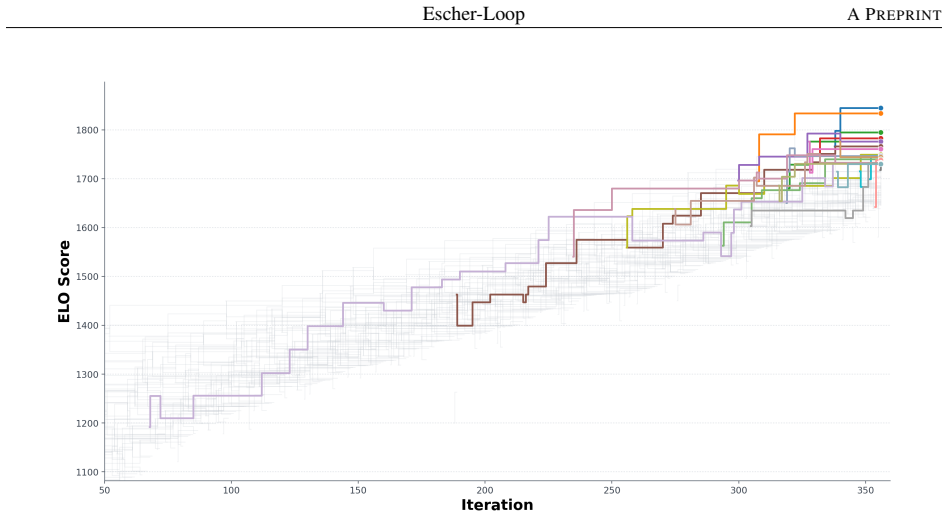
Escher-Loop operationalizes the mutual evolution of Task Agents that solve concrete problems and Optimizer Agents that recursively refine both the task agents and themselves. A dynamic benchmarking mechanism reuses the empirical scores of newly generated task agents as relative win-loss signals to update the optimizers without additional overhead. Empirical tests on mathematical optimization problems show the framework reaches higher absolute peak performance than static baselines under matched compute, with the optimizer agents adapting their strategies to the changing demands of stronger task agents.
What carries the argument
The closed-loop mutual evolution between two agent populations, connected by a dynamic benchmarking process that converts task performance scores into evaluation signals for the optimizers.
If this is right
- The framework reaches the highest absolute peak performance on all tested mathematical optimization tasks compared with static baselines.
- Optimizer agents change their refinement strategies to match the shifting needs of high-performing task agents.
- Improvement continues into later stages where static systems have already plateaued.
- The evaluation of optimizers requires no extra external scoring beyond the task solutions themselves.
Where Pith is reading between the lines
- The same dual-population loop could be tested on agent tasks outside mathematical optimization, such as code generation or planning, to check whether continuous gains appear without manual redesign.
- The observed strategy adaptation by optimizers suggests the system may automatically focus on weaknesses in current task agents, which could reduce the need for human-specified improvement directions.
- If the win-loss signals become correlated across populations, later gains might reflect internal consistency rather than genuine capability increases on the original problems.
Load-bearing premise
That scores from new task agents can serve as an unbiased, non-circular signal for judging and improving the optimizer agents without the loop simply rewarding its own self-reinforcing patterns.
What would settle it
Apply the system to optimization problems whose maximum performance is already known and fixed; if the reported peaks remain no higher than those of a static baseline run with identical compute, the central claim would be falsified.
Figures




read the original abstract
While recent autonomous agents demonstrate impressive capabilities, they predominantly rely on manually scripted workflows and handcrafted heuristics, inherently limiting their potential for open-ended improvement. To address this, we propose Escher-Loop, a fully closed-loop framework that operationalizes the mutual evolution of two distinct populations: Task Agents that solve concrete problems, and Optimizer Agents that recursively refine both the task agents and themselves. To sustain this self-referential evolution, we propose a dynamic benchmarking mechanism that seamlessly reuses the empirical scores of newly generated task agents as relative win-loss signals to update optimizers' scores. This mechanism leverages the evolution of task agents as an inherent signal to drive the evaluation and refinement of optimizers without additional overhead. Empirical evaluations on mathematical optimization problems demonstrate that Escher-Loop effectively pushes past the performance ceilings of static baselines, achieving the highest absolute peak performance across all evaluated tasks under matched compute. Remarkably, we observe that the optimizer agents dynamically adapt their strategies to match the shifting demands of high-performing task agents, which explains the system's continuous improvement and superior late-stage performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Escher-Loop, a fully closed-loop framework for the mutual evolution of Task Agents, which solve concrete problems, and Optimizer Agents, which refine both the task agents and themselves. To enable this self-referential process, a dynamic benchmarking mechanism is introduced that reuses the empirical scores of newly generated task agents as relative win-loss signals for updating the optimizers' scores. The paper claims that empirical evaluations on mathematical optimization problems show Escher-Loop achieving the highest absolute peak performance across all tasks under matched compute, with optimizer agents adapting their strategies to the shifting demands of high-performing task agents.
Significance. If the central empirical claims hold and the dynamic benchmarking provides a non-circular, unbiased signal for improvement, this work could be significant for the field of autonomous agents and evolutionary computation. It offers a pathway to open-ended improvement without manual scripting or handcrafted heuristics, potentially leading to more adaptive AI systems. The closed-loop design is an interesting conceptual contribution, though its practical impact depends on rigorous validation of the performance gains and strategy adaptation.
major comments (2)
- [Abstract] Abstract: The assertion that Escher-Loop 'effectively pushes past the performance ceilings of static baselines, achieving the highest absolute peak performance across all evaluated tasks under matched compute' and that 'optimizer agents dynamically adapt their strategies' is presented without any quantitative results, baseline definitions, statistical tests, or details on the dynamic benchmarking mechanism. This is load-bearing for the central claim.
- [Dynamic benchmarking mechanism] Dynamic benchmarking mechanism: Task-agent empirical scores are reused directly as relative win-loss signals to update optimizer scores in a closed co-evolutionary loop, with no external held-out validation, separate evaluator, or ablation showing independence from the evolving populations. This setup risks the signal rewarding self-reinforcing artifacts rather than objective gains on fixed problem metrics (e.g., distance to known optima).
minor comments (1)
- The abstract would benefit from naming the specific mathematical optimization problems (e.g., Rosenbrock, Rastrigin) and briefly indicating how compute is matched across methods.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment point by point below, clarifying the manuscript's content and indicating where revisions will be made to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that Escher-Loop 'effectively pushes past the performance ceilings of static baselines, achieving the highest absolute peak performance across all evaluated tasks under matched compute' and that 'optimizer agents dynamically adapt their strategies' is presented without any quantitative results, baseline definitions, statistical tests, or details on the dynamic benchmarking mechanism. This is load-bearing for the central claim.
Authors: The abstract is intentionally high-level to summarize the contribution, while the full manuscript (Experiments section and associated tables/figures) provides the quantitative results, baseline definitions (static single-population optimizers and non-adaptive heuristics), statistical tests (paired t-tests and Wilcoxon rank-sum tests with p-values), and mechanism details. We agree the abstract could better preview these elements without exceeding length limits and will revise it to incorporate concise quantitative highlights (e.g., peak performance deltas and adaptation observations) drawn directly from the reported experiments. revision: yes
-
Referee: [Dynamic benchmarking mechanism] Dynamic benchmarking mechanism: Task-agent empirical scores are reused directly as relative win-loss signals to update optimizer scores in a closed co-evolutionary loop, with no external held-out validation, separate evaluator, or ablation showing independence from the evolving populations. This setup risks the signal rewarding self-reinforcing artifacts rather than objective gains on fixed problem metrics (e.g., distance to known optima).
Authors: The task-agent scores derive from objective, fixed metrics on mathematical optimization benchmarks (Euclidean distance to known global optima, which remain constant across generations). The relative win-loss ranking serves only as a comparative update signal for optimizer selection and is grounded in these absolute performance values rather than purely internal artifacts. This design enables the closed loop without external overhead while still tying progress to external ground truth. We will add an expanded subsection in the Methods clarifying this grounding and include a new ablation experiment that compares the full closed-loop results against a variant using a small held-out validation set for optimizer scoring, to empirically demonstrate that performance trends and adaptation patterns are preserved. revision: partial
Circularity Check
No significant circularity; empirical claims rest on external benchmark metrics
full rationale
The paper proposes a closed-loop co-evolutionary framework in which task-agent performance on fixed mathematical optimization problems supplies fitness signals for optimizer agents. This is a standard evolutionary-computation design and does not reduce the reported result to its inputs by construction. The central empirical claim—highest absolute peak performance on the benchmark tasks under matched compute—is measured by the objective value of the underlying problem (e.g., Rosenbrock, Rastrigin), an external, fixed metric independent of the evolutionary loop. No equations, self-citations, uniqueness theorems, or fitted parameters are invoked that would make the performance gain tautological. The system remains externally falsifiable on the stated benchmarks.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Escher-Loop framework
no independent evidence
-
Dynamic benchmarking mechanism
no independent evidence
Forward citations
Cited by 2 Pith papers
-
Evolutionary Ensemble of Agents
EvE uses co-evolving populations of solvers and guidance states with Elo-based evaluation to autonomously discover a rescale-then-interpolate mechanism for better generalization in In-Context Operator Networks.
-
Evolutionary Ensemble of Agents
EvE co-evolves code solvers and guidance states via synchronous races and Elo updates, discovering a rescale-then-interpolate mechanism that enables example-count generalization in ICON.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2306.02224. Anthropic. Claude 3.7 sonnet and claude code, February 2025. URL https://www.anthropic.com/news/ claude-3-7-sonnet. Junyu Luo, Weizhi Zhang, Ye Yuan, Yusheng Zhao, Junwei Yang, Yiyang Gu, Bohan Wu, Binqi Chen, Ziyue Qiao, Qingqing Long, Rongcheng Tu, Xiao Luo, Wei Ju, Zhiping Xiao, Yifan Wang, Meng Xiao, Chenwu Liu, Ji...
-
[2]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao
URLhttps://openreview.net/forum?id=WE_vluYUL-X. Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: language agents with verbal reinforcement learning. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 8634–8652. Cur-...
2023
-
[3]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
ISSN 2835-8856. URLhttps://openreview.net/forum?id=ehfRiF0R3a. John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-agent: agent-computer interfaces enable automated software engineering. In A. Glober- son, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in...
-
[4]
During downstream task optimization, we reduce this temperature toT= 0.7to improve stability and reduce unproductive variance
Generation temperature.During optimizer evolution, we use a generation temperature of T= 1.0 to encourage exploratory variation in candidate proposals. During downstream task optimization, we reduce this temperature toT= 0.7to improve stability and reduce unproductive variance
-
[5]
" " Constructor - based circle packing for n =26 circles
Archive sampling temperature.The MAP-Elites archive (Mouret and Clune, 2015) uses rank-based Softmax sampling,P(i)∝exp(−rank i/T), with role-specific temperatures: – Matchmaking (T= 1.2 ):encourages moderate exploration when selecting opponents of comparable Elo level; – Mentoring (T= 0.5 ):emphasizes stronger optimizer agents as teachers, thereby reducin...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.