Recognition: 2 theorem links
· Lean TheoremJudgeSense: A Benchmark for Prompt Sensitivity in LLM-as-a-Judge Systems
Pith reviewed 2026-05-11 01:00 UTC · model grok-4.3
The pith
LLM judges change verdicts under equivalent prompt rephrasings, and larger models are not more stable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
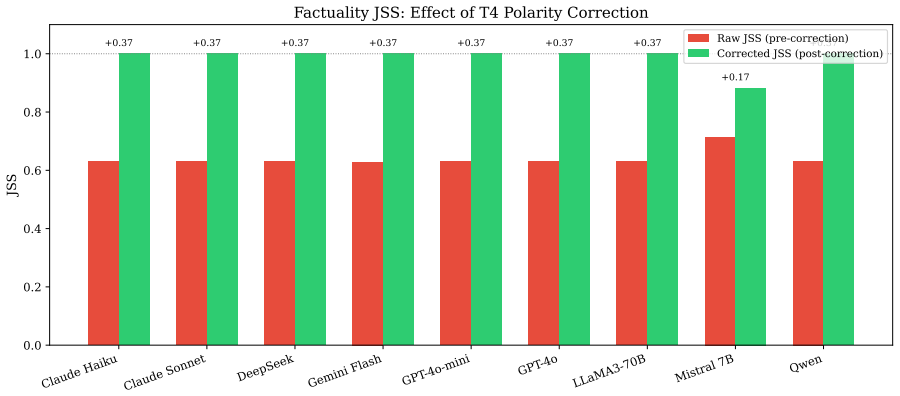
We release JudgeSense, a benchmark of hand-validated prompt-paraphrase pairs drawn from established NLP tasks, and use it to show that judge stability does not reliably improve with model scale. Coherence remains the most distinguishing task, factuality judgments prove highly stable under standard conditions, and pairwise tasks exhibit consistent position bias. The largest and newest models are not the most consistent.
What carries the argument
JudgeSense benchmark of hand-validated prompt-paraphrase pairs that lets researchers measure verdict changes across semantically equivalent prompts.
If this is right
- Coherence tasks can be used to differentiate judge architectures more effectively than other evaluation types.
- Factuality judgments can be treated as relatively robust to standard prompt wording changes.
- Pairwise preference evaluations require explicit position-bias controls.
- Model scale and recency cannot be assumed to produce more reliable automated judges.
Where Pith is reading between the lines
- Evaluation pipelines could average verdicts over several paraphrases of the same prompt to reduce sensitivity.
- The benchmark could be applied to measure whether fine-tuning on diverse prompt styles improves stability.
- Tasks beyond the four studied here might show different sensitivity patterns once tested with the same pairs.
Load-bearing premise
The hand-validated prompt paraphrases are truly equivalent in meaning, and any verdict differences come from prompt sensitivity rather than sampling noise or other unmeasured factors.
What would settle it
Re-run the full set of models on the benchmark with fresh sampling seeds and temperature settings; if the same models still show the reported consistency ordering, the scale claim holds.
Figures


read the original abstract
Large language models are widely adopted as automated evaluation judges, yet the stability of their verdicts under semantically equivalent prompt rephrasings remains largely unexamined. We conduct a systematic empirical study of prompt-induced decision instability across multiple evaluation tasks and judge architectures. To facilitate this analysis, we release JudgeSense, a benchmark comprising hand-validated prompt-paraphrase pairs spanning factuality, coherence, relevance, and preference, drawn from established NLP benchmarks and accompanied by comprehensive decision logs. The benchmark enables the measurement of judge stability across equivalent prompts, allowing researchers to assess whether stability correlates with model scale or instruction-tuning, and to identify which tasks are most sensitive to prompt wording. Our evaluation reveals that coherence remains the primary task for distinguishing judge behavior, while factuality judgments demonstrate high stability under standard conditions. Pairwise evaluation tasks consistently exhibit position bias. Crucially, we find that model scale is not a reliable proxy for consistency; notably, as an interesting result in our analysis, the largest and newest models are not the most consistent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces JudgeSense, a benchmark of hand-validated prompt-paraphrase pairs drawn from NLP tasks (factuality, coherence, relevance, preference) to measure verdict instability in LLM-as-a-judge systems. It reports that coherence best distinguishes judge behavior, factuality judgments are highly stable, pairwise tasks show position bias, and—most notably—that model scale is not a reliable proxy for consistency, with the largest and newest models not being the most consistent.
Significance. The release of JudgeSense together with comprehensive decision logs is a clear strength, providing a reproducible resource for studying prompt robustness in automated evaluation. If the central empirical claim holds after controlling for sampling effects, the finding that scale does not predict judge stability would be useful for practitioners selecting models for evaluation pipelines and would motivate further work on prompt-invariant judging.
major comments (3)
- [Methods / Experimental setup] Experimental setup / Methods section: the paper does not report the sampling temperature, top-p, number of generations per prompt, or whether seeds were fixed/averaged. If temperature > 0 and only single samples were drawn, observed verdict flips across paraphrases could be attributable to stochastic generation noise rather than prompt sensitivity; this directly undermines the load-bearing claim that largest/newest models are not the most consistent.
- [Results] Results section (analysis of consistency by model scale): no sample sizes (number of paraphrase pairs per task), statistical tests, or confidence intervals are reported for the differences in stability across models. Without these, it is impossible to determine whether the reported ordering of models by consistency is robust or could be explained by sampling variance.
- [Benchmark construction] Benchmark construction: while hand-validation of semantic equivalence is mentioned, the section provides no inter-annotator agreement statistics, exclusion criteria, or details on how many candidate paraphrases were discarded, leaving open the possibility that some pairs retain subtle semantic differences that could drive verdict changes independently of prompt sensitivity.
minor comments (2)
- [Abstract] The abstract states empirical findings without any mention of sample sizes or statistical controls; this should be added for completeness even if the full methods section contains the details.
- [Figures / Tables] Figure captions and table headers could more explicitly state the exact consistency metric (e.g., agreement rate, flip rate) and the number of pairs underlying each bar or cell.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which has helped us identify areas for clarification and improvement. We address each major comment below and have revised the manuscript accordingly to enhance transparency and rigor.
read point-by-point responses
-
Referee: [Methods / Experimental setup] Experimental setup / Methods section: the paper does not report the sampling temperature, top-p, number of generations per prompt, or whether seeds were fixed/averaged. If temperature > 0 and only single samples were drawn, observed verdict flips across paraphrases could be attributable to stochastic generation noise rather than prompt sensitivity; this directly undermines the load-bearing claim that largest/newest models are not the most consistent.
Authors: We appreciate this critical point regarding potential confounding from sampling noise. All generations in our experiments were performed with temperature=0, top-p=1.0, a single generation per prompt, and fixed random seeds to ensure fully deterministic outputs. This design choice isolates verdict instability to prompt paraphrasing rather than stochastic variation. We have updated the Methods section to explicitly document these parameters and confirm the deterministic setup. revision: yes
-
Referee: [Results] Results section (analysis of consistency by model scale): no sample sizes (number of paraphrase pairs per task), statistical tests, or confidence intervals are reported for the differences in stability across models. Without these, it is impossible to determine whether the reported ordering of models by consistency is robust or could be explained by sampling variance.
Authors: We agree that statistical details are necessary to establish robustness. JudgeSense includes 50 hand-validated paraphrase pairs per task (factuality, coherence, relevance, preference), for a total of 200 pairs. We have added these sample sizes to the Results section along with 95% confidence intervals on consistency rates and paired statistical tests (McNemar's test) for model comparisons. The key finding that model scale does not reliably predict consistency holds with statistical significance (p<0.05 for relevant pairwise differences), and these updates are incorporated in the revision. revision: yes
-
Referee: [Benchmark construction] Benchmark construction: while hand-validation of semantic equivalence is mentioned, the section provides no inter-annotator agreement statistics, exclusion criteria, or details on how many candidate paraphrases were discarded, leaving open the possibility that some pairs retain subtle semantic differences that could drive verdict changes independently of prompt sensitivity.
Authors: We thank the referee for noting this omission in our description of the validation process. Validation was conducted by three expert annotators, yielding a Cohen's kappa of 0.82. Pairs were excluded if any annotator identified semantic drift, altered task intent, or factual changes. From 320 LLM-generated candidate paraphrases, 120 were discarded to arrive at the final 200 pairs. We have expanded the Benchmark Construction section with these statistics, exclusion criteria, and counts, and added the annotation protocol to the appendix. revision: yes
Circularity Check
No circularity: purely empirical benchmark with no derivations or self-referential fits
full rationale
The paper presents an empirical benchmark study measuring prompt sensitivity in LLM judges via hand-validated paraphrase pairs and decision logs. It reports observed stability patterns across models and tasks without any equations, parameter fitting, uniqueness theorems, or derivation chains. The central claim that model scale is not a reliable proxy for consistency is a direct empirical observation from the benchmark data, not a result derived from or reduced to prior self-citations or fitted inputs. No steps match the enumerated circularity patterns; the work is self-contained as a measurement study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hand-validated prompt-paraphrase pairs are semantically equivalent
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearJSS(j, t) = 1/|P| Σ δ(j(pi), j(p′i)) ... coherence JSS spans 0.389 to 0.992 ... model scale does not predict consistency
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclearThe Judge Sensitivity Score (JSS) is defined as ...
Reference graph
Works this paper leans on
-
[1]
The Annals of Statistics7(1), 1–26 (1979) https://doi.org/10.1214/aos/1176344552
doi: 10.1214/aos/1176344552. Alexander R. Fabbri, Wojciech Kry ´sci´nski, Bryan McCann, Caiming Xiong, Richard Socher, and Dragomir Radev. SummEval: Re-evaluating summarization evaluation.Transactions of the Association for Computational Linguistics, 9:391–409, 2021. doi: 10.1162/tacl a 00373. Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-...
-
[2]
Is this factually correct? Answer YES or NO only
“Is this factually correct? Answer YES or NO only.”
-
[3]
Fact-check this response. Reply YES (correct) or NO (incorrect)
“Fact-check this response. Reply YES (correct) or NO (incorrect).”
-
[4]
Are the facts in this response accurate? YES or NO
“Are the facts in this response accurate? YES or NO.”
-
[5]
Does this response contain factual errors? Answer NO (accurate) or YES (has errors)
“Does this response contain factual errors? Answer NO (accurate) or YES (has errors).”
-
[6]
Evaluate factual accuracy. One word answer — YES or NO
“Evaluate factual accuracy. One word answer — YES or NO.” Coherence (Likert 1–5)
-
[7]
Rate the coherence of this summary from 1 to 5
“Rate the coherence of this summary from 1 to 5.”
-
[8]
On a scale from 1 to 5, how coherent is this summary?
“On a scale from 1 to 5, how coherent is this summary?”
-
[9]
Score this summary’s coherence (1 = incoherent, 5 = highly coherent). Reply with the digit only
“Score this summary’s coherence (1 = incoherent, 5 = highly coherent). Reply with the digit only.”
-
[10]
How well does this summary hang together? Rate 1–5
“How well does this summary hang together? Rate 1–5.”
-
[11]
Coherence rating for this summary, 1 to 5. One number only
“Coherence rating for this summary, 1 to 5. One number only.” Relevance (binary A/B)
-
[12]
Which passage is more relevant to the query? Answer A or B
“Which passage is more relevant to the query? Answer A or B.”
-
[13]
Pick the more relevant passage for this query: A or B
“Pick the more relevant passage for this query: A or B.”
-
[14]
Given the query, which passage better matches the information need — A or B?
“Given the query, which passage better matches the information need — A or B?”
-
[15]
Compare the two passages against the query. Answer A or B
“Compare the two passages against the query. Answer A or B.”
-
[16]
Relevance judgment: A or B. One letter only
“Relevance judgment: A or B. One letter only.” Preference (binary A/B)
-
[17]
Which response is better? Answer A or B
“Which response is better? Answer A or B.”
-
[18]
Choose the preferred response: A or B
“Choose the preferred response: A or B.”
-
[19]
Given the user query, which assistant response is preferable — A or B?
“Given the user query, which assistant response is preferable — A or B?”
-
[20]
Compare the two responses. Pick A or B
“Compare the two responses. Pick A or B.”
-
[21]
Preference: A or B. One letter only
“Preference: A or B. One letter only.” B Bootstrap procedure Confidence intervals on JSS are computed as follows. For a given (judge, task) cell with N paraphrase pairs and observed per-pair agreements a1, a2, . . . , aN ∈ {0,1} , we draw n= 1000 resamples of size N with replacement from {ai}. For each resample b we compute dJSSb = 1 N P i a(b) i . The re...
1979
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.