Recognition: unknown
ragR: Retrieval-Augmented Generation and RAG Assessment in R
Pith reviewed 2026-05-08 04:58 UTC · model grok-4.3
The pith
The ragR package unifies RAG construction and evaluation in R with metric behavior matching Python RAGAS.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
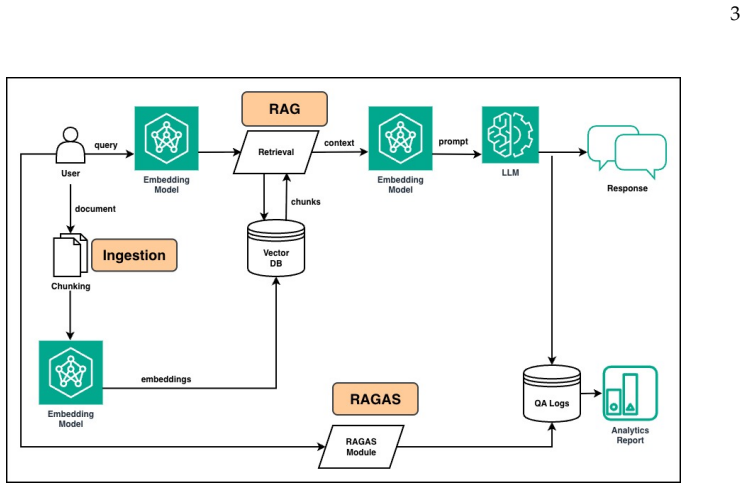
The authors create ragR to combine document ingestion, embedding and vector storage, similarity-based retrieval, grounded generation, question-answer logging, and RAGAS-style evaluation with LLM scoring for context precision, context recall, faithfulness, and answer relevance all inside R. Validation under controlled settings demonstrates that ragR captures similar metric behavior to the reference Python RAGAS workflow across multiple use cases.
What carries the argument
The ragR package, which supplies an R-native workflow for the complete RAG pipeline plus LLM-based scoring of the four RAGAS metrics.
If this is right
- R users can perform end-to-end RAG work without Python dependencies.
- Reproducible RAG experiments and teaching become possible inside the R ecosystem.
- Moderate-scale RAG testing can use only R tools and libraries.
- Structured logging of question-answer pairs supports further analysis in R.
Where Pith is reading between the lines
- R's statistical tools could now be applied directly to analyze RAG performance distributions.
- The package could be extended to compare different embedding or retrieval methods using R's existing data analysis functions.
- This lowers the barrier for statisticians to test RAG ideas without adopting a second programming language.
Load-bearing premise
That the R implementation of LLM-based scoring for the four RAGAS metrics produces results comparable to the Python reference without systematic differences from language-specific libraries or random seeds.
What would settle it
A side-by-side run of the same documents, queries, models, and prompts in both ragR and Python RAGAS that checks whether the four metric scores differ beyond ordinary random variation.
Figures







read the original abstract
Retrieval-augmented generation (RAG) combines document retrieval with large language models to produce responses grounded in external evidence. While several R packages support core components of RAG workflows, integrated evaluation of RAG systems in R remains limited and is often conducted through Python-based tools, most notably the RAG assessment (RAGAS) framework. To address this gap, we introduce ragR, an R package that unifies document ingestion, embedding and vector storage, similarity-based retrieval, grounded generation, structured question-answer logging, and RAGAS-style evaluation within a single R-native workflow. The current implementation provides LLM-based scoring for four core RAGAS metrics: context precision, context recall, faithfulness, and answer relevance. Validation experiments under controlled settings show that ragR captures similar metric behavior to the reference Python RAGAS workflow across multiple use cases. By integrating RAG construction and evaluation within a reproducible workflow in R, ragR provides a practical framework for research, teaching, and moderate-scale experimentation on RAG systems entirely within the R ecosystem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the ragR R package, which unifies document ingestion, embedding, vector storage, similarity-based retrieval, grounded generation, question-answer logging, and LLM-based scoring for four RAGAS metrics (context precision, context recall, faithfulness, and answer relevance) into a single R-native workflow. The central claim is that validation experiments under controlled settings demonstrate that ragR captures similar metric behavior to the reference Python RAGAS implementation across multiple use cases.
Significance. If the equivalence claim holds, ragR would provide a practical contribution by enabling fully reproducible RAG construction and evaluation within the R ecosystem, reducing the need to switch to Python for assessment and supporting teaching and moderate-scale research. The integration of all components in one package is a clear strength for workflow reproducibility.
major comments (2)
- [Abstract] Abstract: The claim that 'validation experiments under controlled settings show that ragR captures similar metric behavior to the reference Python RAGAS workflow' lacks any details on datasets, LLMs/endpoints, temperature/seed settings, prompt templates, or quantitative agreement measures (e.g., correlations or mean differences). This directly undermines the ability to confirm that observed similarity is not due to language-specific differences in prompt serialization, API parsing, or sampling, as the central equivalence claim requires matched conditions.
- [Validation experiments] Validation experiments section (or equivalent): No experimental setup, results tables, or statistical comparisons are described, leaving the supporting evidence for the key claim of metric equivalence unsubstantiated and preventing assessment of whether R-specific libraries introduce systematic shifts relative to Python RAGAS.
minor comments (3)
- [Abstract] The abstract should include a citation to the original RAGAS framework paper to properly attribute the four metrics being re-implemented.
- [Introduction] Provide explicit installation instructions, GitHub/CRAN link, and at least one complete reproducible example workflow in the main text or supplementary material to support the claim of a practical R-native framework.
- [Methods] Clarify in the methods whether the LLM calls use a specific R package (e.g., httr, reticulate) and how prompt templates are ensured to match the Python reference exactly.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation for minor revision. We agree that the validation experiments require substantially more detail to substantiate the central claim of metric equivalence between ragR and the Python RAGAS reference implementation. We will revise the manuscript to address both comments by expanding the abstract and adding a dedicated validation section with full experimental specifications, quantitative results, and statistical comparisons.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'validation experiments under controlled settings show that ragR captures similar metric behavior to the reference Python RAGAS workflow' lacks any details on datasets, LLMs/endpoints, temperature/seed settings, prompt templates, or quantitative agreement measures (e.g., correlations or mean differences). This directly undermines the ability to confirm that observed similarity is not due to language-specific differences in prompt serialization, API parsing, or sampling, as the central equivalence claim requires matched conditions.
Authors: We acknowledge that the abstract statement is insufficiently supported. In the revised version we will modify the abstract to include a concise summary of the controlled experimental conditions: the specific datasets (standard RAGAS benchmark QA pairs drawn from public sources), the LLMs and API endpoints used for both generation and scoring, temperature set to 0 with fixed seeds for reproducibility, the prompt templates employed, and quantitative agreement statistics (Pearson and Spearman correlations plus mean absolute differences between ragR and Python RAGAS metric scores). This will allow readers to evaluate whether any observed similarity could be attributable to implementation differences. revision: yes
-
Referee: [Validation experiments] Validation experiments section (or equivalent): No experimental setup, results tables, or statistical comparisons are described, leaving the supporting evidence for the key claim of metric equivalence unsubstantiated and preventing assessment of whether R-specific libraries introduce systematic shifts relative to Python RAGAS.
Authors: We agree that the manuscript currently lacks a dedicated validation section with the required methodological transparency. We will add a new section titled 'Validation Experiments' that details: (i) the datasets and number of QA pairs, (ii) the exact LLMs, endpoints, and temperature/seed settings for both ragR and the reference Python implementation, (iii) the prompt templates used for each RAGAS metric, (iv) side-by-side results tables reporting context precision, context recall, faithfulness, and answer relevance scores from both packages, and (v) statistical comparisons including correlation coefficients and mean differences. This addition will directly address concerns about potential systematic shifts introduced by R-specific libraries and will make the equivalence claim verifiable. revision: yes
Circularity Check
No circularity: software implementation paper with empirical comparison to external reference
full rationale
The paper introduces an R package for RAG workflows and RAGAS-style evaluation. Its central claim is that validation experiments show similar metric behavior to the Python RAGAS reference under controlled settings. No derivations, equations, fitted parameters, predictions, or self-citations are present in the provided text. The validation is a direct empirical comparison to an independent external implementation (Python RAGAS), not a reduction to the paper's own inputs or fitted quantities. This matches the default expectation for non-circular software/implementation papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
RAGAS: Automated evalu- ation of retrieval-augmented generation.arXiv preprint arXiv:2309.15217,
URL https://www.rplumber.io/. R package version. [p7] S. Es, J. James, L. Espinosa-Anke, and S. Schockaert. Automated evaluation of retrieval augmented generation.arXiv preprint arXiv:2309.15217,
-
[2]
Retrieval-Augmented Generation for Large Language Models: A Survey
URL https://docs.ragas.io/en/ stable/. Accessed 2026-02-22. [p1, 2, 7, 9, 12, 13] Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pan, Y. Bi, Y. Dai, J. Sun, M. Wang, and H. Wang. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997,
work page internal anchor Pith review arXiv 2026
-
[3]
R package version 0.1.7
URL https://CRAN.R-project.org/package= RAGFlowChainR. R package version 0.1.7. [p1, 2, 13] Package source code.The development version of ragR is available at https://github. com/aimalrehman92/ragR. Muhammad Aimal Rehman Department of Mathematics and Statistics Georgia State University 25 Park Place, Atlanta, GA 30303 United States of America mrehman3@st...
2096
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.