Recognition: unknown
A Synergistic CNN-Transformer Network with Pooling Attention Fusion for Hyperspectral Image Classification
Pith reviewed 2026-05-08 06:31 UTC · model grok-4.3
The pith
A new network uses parallel CNN and transformer branches to extract and fuse spatial-spectral features from hyperspectral images, yielding higher classification accuracy than prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a Twin-Branch Feature Extraction module running 3D and 2D convolutions in parallel, a hybrid pooling attention module for spatial aggregation, a cascade transformer encoder for global spectral context, and a cross-layer feature fusion module together allow CNNs and vision transformers to collaborate on spatial-spectral data, producing superior pixel-level classification results on representative hyperspectral datasets.
What carries the argument
The Twin-Branch Feature Extraction (TBFE) module that applies 3D and 2D convolutions in parallel to capture spectral and spatial features separately, supported by hybrid pooling attention (HPA) for spatial weighting and cross-layer feature fusion (CFF) to retain information from earlier layers.
If this is right
- Pixel classification into land-cover categories improves on multiple public HSI benchmarks.
- Spatial and spectral features can be handled separately before fusion without excessive loss of detail.
- Global spectral dependencies captured by the cascade transformer contribute to the observed accuracy gains.
- Cross-layer fusion preserves information that would otherwise degrade in deeper networks.
Where Pith is reading between the lines
- The same branch-separation plus fusion pattern could be tested on other multi-band remote-sensing modalities such as multispectral or SAR data.
- Computational cost comparisons with pure CNN or pure transformer baselines would clarify whether the added modules remain practical for large-scale mapping.
- Ablation results on the individual modules could be examined across datasets to identify which component drives most of the gain.
Load-bearing premise
The newly added TBFE, HPA, and CFF modules together solve spatial-spectral fusion and layer-wise information loss without adding dataset-specific biases or requiring hyperparameter choices that were not disclosed in the experiments.
What would settle it
Apply the full model and each of its ablated variants to a fresh hyperspectral dataset never used in training or tuning; if accuracy gains disappear or if removing any single module leaves performance unchanged, the claimed benefit of the synergistic design is refuted.
Figures




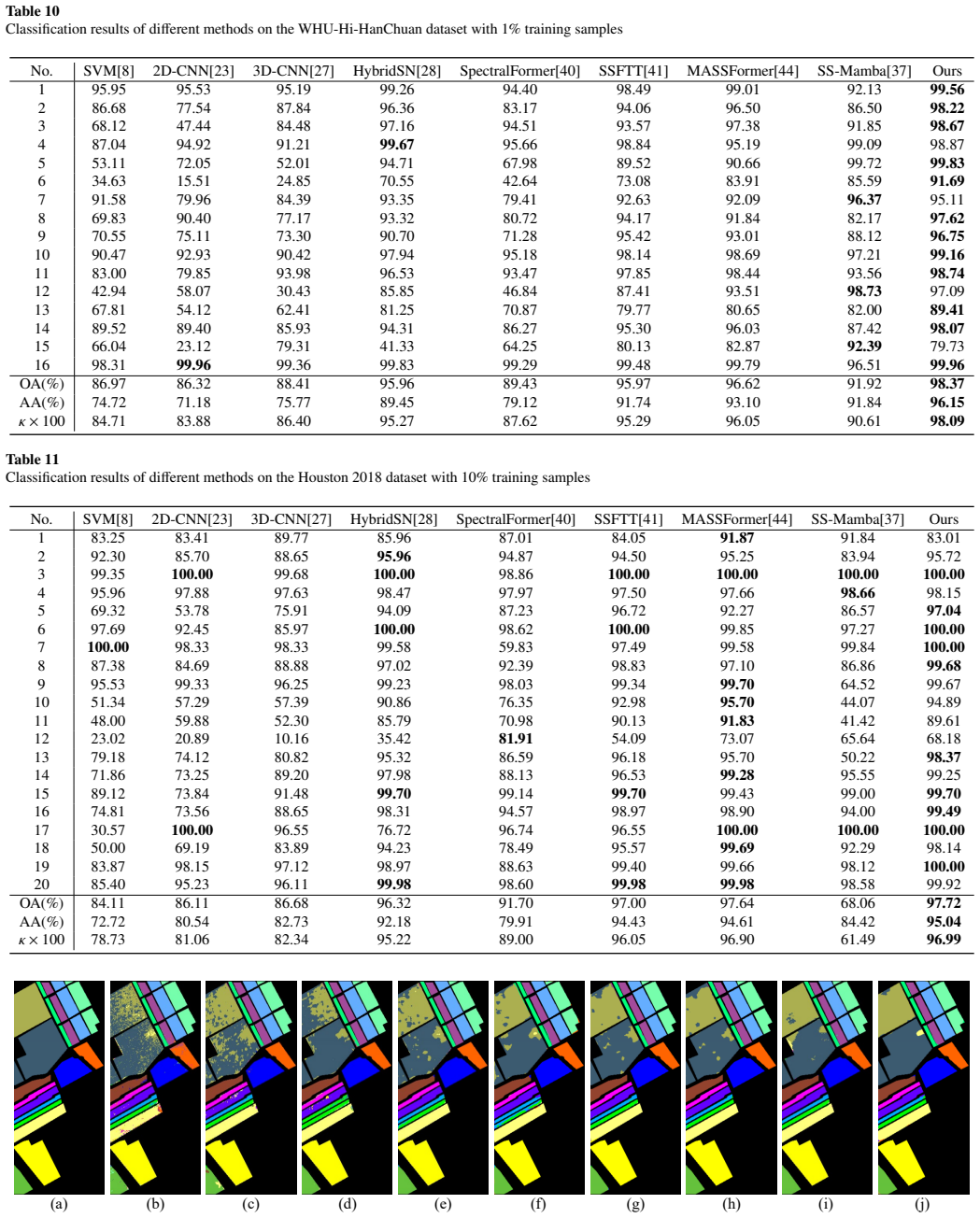
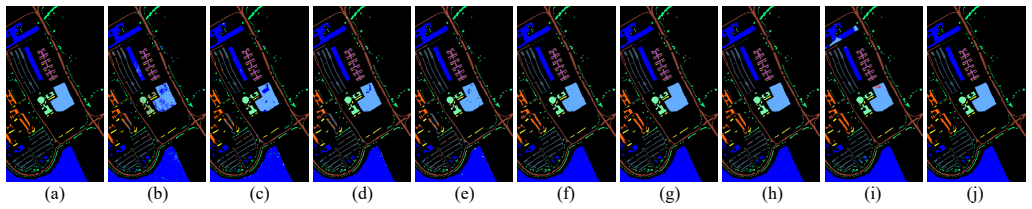


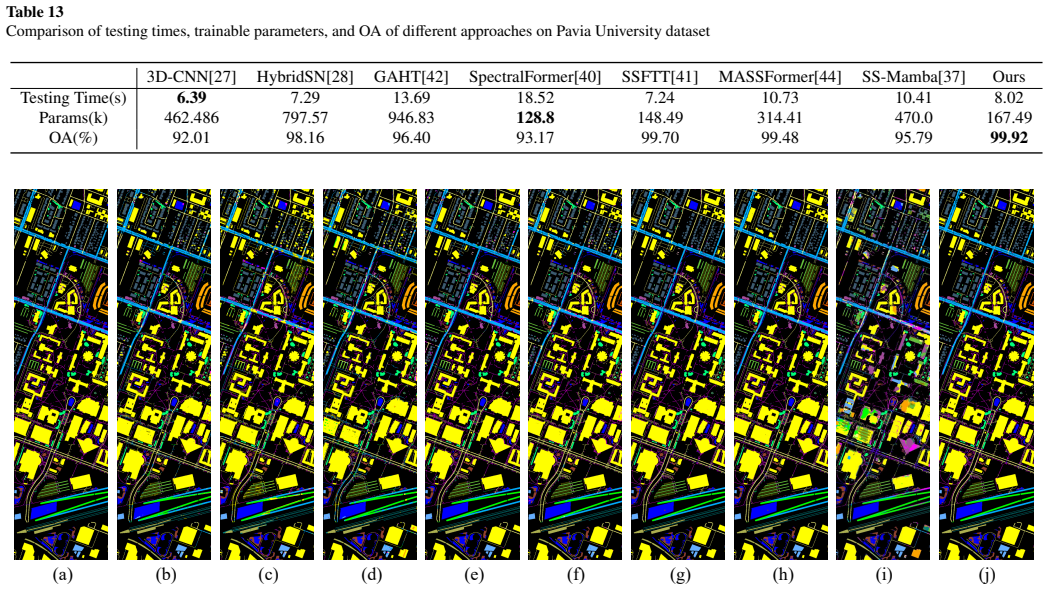
read the original abstract
In the hyperspectral image (HSI) classification task, each pixel is categorized into a specific land-cover category or material. Convolutional neural networks (CNNs) and transformers have been widely used to extract local and non-local features in HSI classification. Recent works have utilized a multi-scale vision transformer (ViT) to enhance spectral feature capture and yield promising results. However, most existing methods still face challenges in the effective joint use of spatial-spectral information and in preserving information across layers during the propagation process. To address these issues, we propose a synergistic CNN-Transformer network with pooling attention fusion for HSI classification, which collaboratively utilizes CNNs and ViT to process spatial and spectral features separately. Specifically, we propose a Twin-Branch Feature Extraction (TBFE) module, which employs 3D and 2D convolution in parallel to comprehensively extract spectral and spatial features from HSI. A hybrid pooling attention (HPA) module is designed to aggregate spatial attention. Moreover, a cascade transformer encoder is employed for global spectral feature extraction, and a simple yet efficient cross-layer feature fusion (CFF) module is designed to reduce the loss of crucial information in the previous network layers. Extensive experiments are conducted on several representative datasets to demonstrate the superior performance of our proposed method compared to the state-of-the-art works. Code is available at https://github.com/chenpeng052/SCT-Net.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a synergistic CNN-Transformer network for hyperspectral image classification. It introduces the Twin-Branch Feature Extraction (TBFE) module with parallel 3D and 2D convolutions to extract spectral and spatial features, the Hybrid Pooling Attention (HPA) module to aggregate spatial attention, a cascade transformer encoder for global spectral feature extraction, and the Cross-Layer Feature Fusion (CFF) module to reduce information loss across layers. The central claim is that this architecture collaboratively utilizes CNNs and ViT to achieve superior performance over state-of-the-art methods on representative HSI datasets.
Significance. If the results hold under controlled conditions, this work could advance hybrid CNN-Transformer models in hyperspectral imaging by addressing spatial-spectral fusion and information preservation. The open-source code link is a strength for reproducibility. However, the significance is limited because the empirical gains are not yet shown to be attributable to the proposed modules rather than training variations.
major comments (2)
- [Experimental results] Experimental results section: The manuscript reports superior accuracy on standard HSI benchmarks but provides no ablation studies isolating the contributions of TBFE, HPA, and CFF. This is load-bearing for the central claim, as the strongest assertion attributes the margins to the synergistic design and these modules; without component ablations or controlled re-runs of baselines using identical optimizer, patch size, and augmentation, attribution cannot be verified.
- [Method] Method section on CFF: The claim that the cross-layer feature fusion module reduces loss of crucial information across layers is supported only by end-to-end accuracy; no quantitative metrics (e.g., layer-wise feature similarity or information retention scores) are given to substantiate the reduction in layer-wise loss.
minor comments (1)
- [Abstract] The abstract states that CNNs and ViT process spatial and spectral features separately, yet the TBFE module uses parallel 3D/2D convolutions on the same input; a short clarification on the separation mechanism would aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We agree that additional experiments are needed to strengthen the attribution of performance gains and to provide quantitative support for the CFF module. We will revise the paper accordingly.
read point-by-point responses
-
Referee: [Experimental results] Experimental results section: The manuscript reports superior accuracy on standard HSI benchmarks but provides no ablation studies isolating the contributions of TBFE, HPA, and CFF. This is load-bearing for the central claim, as the strongest assertion attributes the margins to the synergistic design and these modules; without component ablations or controlled re-runs of baselines using identical optimizer, patch size, and augmentation, attribution cannot be verified.
Authors: We agree that ablation studies are essential to isolate module contributions and ensure fair attribution. In the revised manuscript, we will add comprehensive ablation experiments removing or replacing TBFE, HPA, and CFF individually. We will also re-implement all baseline methods under identical conditions (same optimizer, patch size, augmentation, and training protocol) to enable direct comparison and verify that the reported margins stem from the proposed synergistic design rather than implementation differences. revision: yes
-
Referee: [Method] Method section on CFF: The claim that the cross-layer feature fusion module reduces loss of crucial information across layers is supported only by end-to-end accuracy; no quantitative metrics (e.g., layer-wise feature similarity or information retention scores) are given to substantiate the reduction in layer-wise loss.
Authors: We acknowledge that end-to-end accuracy alone is insufficient to directly demonstrate information preservation by CFF. In the revision, we will include quantitative analyses such as layer-wise cosine similarity between features before and after fusion, as well as information retention metrics (e.g., mutual information or reconstruction error across layers), to provide explicit evidence supporting the claim that CFF reduces crucial information loss. revision: yes
Circularity Check
No circularity in empirical architecture proposal
full rationale
The manuscript proposes a new CNN-Transformer network (TBFE, HPA, cascade transformer encoder, CFF) for HSI classification and validates it via end-to-end accuracy on standard benchmarks. No mathematical derivations, equations, or first-principles results exist that could reduce to inputs by construction. Claims rest entirely on experimental comparisons rather than self-definitional fits, fitted inputs renamed as predictions, or load-bearing self-citations. The work is self-contained as an empirical ML architecture paper.
Axiom & Free-Parameter Ledger
free parameters (2)
- Number of transformer layers and attention heads
- Pooling sizes and fusion weights in HPA and CFF
axioms (2)
- domain assumption 3D and 2D convolutions can separately capture spectral and spatial features in HSI data
- domain assumption Transformer encoders can extract global spectral dependencies
invented entities (3)
-
Twin-Branch Feature Extraction (TBFE) module
no independent evidence
-
Hybrid Pooling Attention (HPA) module
no independent evidence
-
Cross-Layer Feature Fusion (CFF) module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Y . Fu, T. Zhang, Y . Zheng, D. Zhang, H. Huang, Joint camera spectral response selection and hyperspec- tral image recovery, IEEE Transactions on Pattern Anal- ysis and Machine Intelligence 44 (1) (2022) 256–272. doi:10.1109/TPAMI.2020.3009999
-
[2]
Z. Liang, S. Wang, T. Zhang, Y . Fu, Blind super- resolution of single remotely sensed hyperspectral image, IEEE Transactions on Geoscience and Remote Sensing 61 (2023) 1–14. doi:10.1109/TGRS.2023.3302128
-
[3]
S. Mohamed, M. Haghighat, T. Fernando, S. Sridharan, C. Fookes, P. Moghadam, Factoformer: Factorized hy- perspectral transformers with self-supervised pretraining, IEEE Transactions on Geoscience and Remote Sensing 62 (2024) 1–14. doi:10.1109/TGRS.2023.3343392
-
[4]
J. Deng, R. Wang, L. Yang, X. Lv, Z. Yang, K. Zhang, C. Zhou, L. Pengju, Z. Wang, A. Abdullah, M. Zhan- hong, Quantitative estimation of wheat stripe rust disease index using unmanned aerial vehicle hyperspectral im- agery and innovative vegetation indices, IEEE Transac- tions on Geoscience and Remote Sensing 61 (2023) 1–11. doi:10.1109/TGRS.2023.3292130
-
[5]
J. Wang, S. Guo, R. Huang, L. Li, X. Zhang, L. Jiao, Dual-channel capsule generation adversarial network for hyperspectral image classification, IEEE Transactions on Geoscience and Remote Sensing 60 (2022) 1–16. doi:10.1109/TGRS.2020.3044312
-
[6]
P. Chen, W. He, F. Qian, G. Shi, J. Yan, A synergistic cnn- transformer network with pooling attention fusion for hy- perspectral image classification, Digital Signal Processing 160 (2025) 105070
2025
-
[7]
S. Li, W. Song, L. Fang, Y . Chen, P. Ghamisi, J. A. Benediktsson, Deep learning for hyperspectral image classification: An overview, IEEE Transactions on Geo- science and Remote Sensing 57 (9) (2019) 6690–6709. doi:10.1109/TGRS.2019.2907932
-
[8]
F. Melgani, L. Bruzzone, Classification of hyper- spectral remote sensing images with support vec- tor machines, IEEE Transactions on Geoscience and Remote Sensing 42 (8) (2004) 1778–1790. doi:10.1109/TGRS.2004.831865. 15
-
[9]
L. Ma, M. M. Crawford, J. Tian, Local mani- fold learning-basedk-nearest-neighbor for hyperspec- tral image classification, IEEE Transactions on Geo- science and Remote Sensing 48 (11) (2010) 4099–4109. doi:10.1109/TGRS.2010.2055876
-
[10]
J. Ham, Y . Chen, M. Crawford, J. Ghosh, Investi- gation of the random forest framework for classifica- tion of hyperspectral data, IEEE Transactions on Geo- science and Remote Sensing 43 (3) (2005) 492–501. doi:10.1109/TGRS.2004.842481
-
[11]
M. Fauvel, J. A. Benediktsson, J. Chanussot, J. R. Sveins- son, Spectral and spatial classification of hyperspectral data using svms and morphological profiles, IEEE Trans- actions on Geoscience and Remote Sensing 46 (11) (2008) 3804–3814. doi:10.1109/TGRS.2008.922034
-
[12]
J. Benediktsson, J. Palmason, J. Sveinsson, Classifica- tion of hyperspectral data from urban areas based on extended morphological profiles, IEEE Transactions on Geoscience and Remote Sensing 43 (3) (2005) 480–491. doi:10.1109/TGRS.2004.842478
-
[13]
Dalla Mura, A
M. Dalla Mura, A. Villa, J. A. Benediktsson, J. Chanus- sot, L. Bruzzone, Classification of hyperspectral im- ages by using extended morphological attribute pro- files and independent component analysis, IEEE Geo- science and Remote Sensing Letters 8 (3) (2011) 542–
2011
-
[14]
doi:10.1109/LGRS.2010.2091253
-
[15]
M. Wang, Y . Sun, J. Xiang, Y . Zhong, Citnet: Con- volution interaction transformer network for hyperspec- tral and lidar image classification, IEEE Transactions on Geoscience and Remote Sensing 62 (2024) 1–18. doi:10.1109/TGRS.2024.3477965
-
[16]
L. Cao, K. Chua, W. Chong, H. Lee, Q. Gu, A comparison of pca, kpca and ica for dimensional- ity reduction in support vector machine, Neurocomput- ing 55 (1) (2003) 321–336, support Vector Machines. doi:https://doi.org/10.1016/S0925-2312(03)00433-8
-
[17]
H. Yuan, Y . Lu, L. Yang, H. Luo, Y . Y . Tang, Spectral- spatial linear discriminant analysis for hyperspectral im- age classification, in: 2013 IEEE International Con- ference on Cybernetics (CYBCO), 2013, pp. 144–149. doi:10.1109/CYBConf.2013.6617430
-
[18]
Z. Li, Z. Xue, Q. Xu, L. Zhang, T. Zhu, M. Zhang, Spformer: Self-pooling transformer for few-shot hy- perspectral image classification, IEEE Transactions on Geoscience and Remote Sensing 62 (2024) 1–19. doi:10.1109/TGRS.2023.3345923
-
[19]
P. Chen, C. Huang, Wmoe-clip: Wavelet-enhanced mixture-of-experts prompt learning for zero-shot anomaly detection, in: ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2026, pp. 22257–22261
2026
-
[20]
M. Farrell, R. Mersereau, On the impact of pca dimen- sion reduction for hyperspectral detection of difficult tar- gets, IEEE Geoscience and Remote Sensing Letters 2 (2) (2005) 192–195. doi:10.1109/LGRS.2005.846011
-
[21]
C. Yu, Y . Zhu, M. Song, Y . Wang, Q. Zhang, Unseen fea- ture extraction: Spatial mapping expansion with spectral compression network for hyperspectral image classifica- tion, IEEE Transactions on Geoscience and Remote Sens- ing 62 (2024) 1–15. doi:10.1109/TGRS.2024.3420137
-
[22]
P. Chen, F. Huang, C. Huang, Dyc-clip: Dynamic context- aware multi-modal prompt learning for zero-shot anomaly detection, Pattern Recognition (2026) 113215
2026
-
[23]
Y . Chen, X. Zhao, X. Jia, Spectral–spatial classifica- tion of hyperspectral data based on deep belief network, IEEE Journal of Selected Topics in Applied Earth Ob- servations and Remote Sensing 8 (6) (2015) 2381–2392. doi:10.1109/JSTARS.2015.2388577
-
[24]
W. Zhao, S. Du, Spectral–spatial feature extraction for hy- perspectral image classification: A dimension reduction and deep learning approach, IEEE Transactions on Geo- science and Remote Sensing 54 (8) (2016) 4544–4554. doi:10.1109/TGRS.2016.2543748
-
[25]
J. Yue, W. Zhao, S. Mao, H. Liu, Spectral– spatial classification of hyperspectral images us- ing deep convolutional neural networks, Re- mote Sensing Letters 6 (6) (2015) 468–477. doi:https://doi.org/10.1080/2150704X.2015.1047045
-
[26]
T. Chakraborty, U. Trehan, Spectralnet: Explor- ing spatial-spectral waveletcnn for hyperspectral image classification, arXiv preprint arXiv:2104.00341 (2021). doi:https://doi.org/10.48550/arXiv.2104.00341
-
[27]
C. Shi, S. Yue, L. Wang, A dual-branch multiscale trans- former network for hyperspectral image classification, IEEE Transactions on Geoscience and Remote Sensing 62 (2024) 1–20. doi:10.1109/TGRS.2024.3351486
-
[28]
Y . Chen, H. Jiang, C. Li, X. Jia, P. Ghamisi, Deep fea- ture extraction and classification of hyperspectral images based on convolutional neural networks, IEEE Transac- tions on Geoscience and Remote Sensing 54 (10) (2016) 6232–6251. doi:10.1109/TGRS.2016.2584107
-
[29]
S. K. Roy, G. Krishna, S. R. Dubey, B. B. Chaud- huri, Hybridsn: Exploring 3-d–2-d cnn feature hierar- chy for hyperspectral image classification, IEEE Geo- science and Remote Sensing Letters 17 (2) (2020) 277–
2020
-
[30]
doi:10.1109/LGRS.2019.2918719
-
[31]
J. Zhou, S. Zeng, G. Gao, Y . Chen, Y . Tang, A novel spatial–spectral pyramid network for hyper- spectral image classification, IEEE Transactions on Geoscience and Remote Sensing 61 (2023) 1–14. doi:10.1109/TGRS.2023.3303338. 16
-
[32]
K. Yang, H. Sun, C. Zou, X. Lu, Cross-attention spec- tral–spatial network for hyperspectral image classifica- tion, IEEE Transactions on Geoscience and Remote Sens- ing 60 (2022) 1–14. doi:10.1109/TGRS.2021.3133582
-
[33]
J. Wang, W. Li, M. Zhang, J. Chanussot, Large ker- nel sparse convnet weighted by multi-frequency attention for remote sensing scene understanding, IEEE Transac- tions on Geoscience and Remote Sensing 61 (2023) 1–12. doi:10.1109/TGRS.2023.3333401
-
[34]
F. Ullah, I. Ullah, R. U. Khan, S. Khan, K. Khan, G. Pau, Conventional to deep ensemble methods for hy- perspectral image classification: A comprehensive sur- vey, IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 17 (2024) 3878–3916. doi:10.1109/JSTARS.2024.3353551
-
[35]
L. Mou, P. Ghamisi, X. X. Zhu, Deep recurrent neural net- works for hyperspectral image classification, IEEE Trans- actions on Geoscience and Remote Sensing 55 (7) (2017) 3639–3655. doi:10.1109/TGRS.2016.2636241
-
[36]
L. Zhu, Y . Chen, P. Ghamisi, J. A. Benedikts- son, Generative adversarial networks for hyperspec- tral image classification, IEEE Transactions on Geo- science and Remote Sensing 56 (9) (2018) 5046–5063. doi:10.1109/TGRS.2018.2805286
-
[37]
Y . Ding, Z. Zhang, X. Zhao, D. Hong, W. Cai, C. Yu, N. Yang, W. Cai, Multi-feature fusion: Graph neu- ral network and cnn combining for hyperspectral im- age classification, Neurocomputing 501 (2022) 246–257. doi:https://doi.org/10.1016/j.neucom.2022.06.031
-
[38]
A. Gu, T. Dao, Mamba: Linear-time sequence modeling with selective state spaces, arXiv preprint arXiv:2312.00752 (2023)
work page internal anchor Pith review arXiv 2023
-
[39]
L. Huang, Y . Chen, X. He, Spectral-spatial mamba for hy- perspectral image classification, Remote Sensing 16 (13) (2024). doi:10.3390/rs16132449
-
[40]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, I. Polosukhin, Attention is all you need, Advances in neural information processing systems 30 (2017)
2017
-
[41]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al., An image is worth 16x16 words: Transformers for image recognition at scale, arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review arXiv 2010
-
[42]
D. Hong, Z. Han, J. Yao, L. Gao, B. Zhang, A. Plaza, J. Chanussot, Spectralformer: Rethinking hyperspectral image classification with transformers, IEEE Transac- tions on Geoscience and Remote Sensing 60 (2022) 1–15. doi:10.1109/TGRS.2021.3130716
-
[43]
L. Sun, G. Zhao, Y . Zheng, Z. Wu, Spectral–spatial feature tokenization transformer for hyperspec- tral image classification, IEEE Transactions on Geoscience and Remote Sensing 60 (2022) 1–14. doi:10.1109/TGRS.2022.3144158
-
[44]
S. Mei, C. Song, M. Ma, F. Xu, Hyperspectral image classification using group-aware hierarchical transformer, IEEE Transactions on Geoscience and Remote Sensing 60 (2022) 1–14. doi:10.1109/TGRS.2022.3207933
-
[45]
Z. Shu, Y . Wang, Z. Yu, Dual attention transformer net- work for hyperspectral image classification, Engineering Applications of Artificial Intelligence 127 (2024) 107351. doi:https://doi.org/10.1016/j.engappai.2023.107351
-
[46]
L. Sun, H. Zhang, Y . Zheng, Z. Wu, Z. Ye, H. Zhao, Mass- former: Memory-augmented spectral-spatial transformer for hyperspectral image classification, IEEE Transactions on Geoscience and Remote Sensing 62 (2024) 1–15. doi:10.1109/TGRS.2024.3392264. 17
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.