Recognition: unknown
Tandem: Riding Together with Large and Small Language Models for Efficient Reasoning
Pith reviewed 2026-05-08 06:03 UTC · model grok-4.3
The pith
A large language model supplies compact critical insights to guide a smaller model through complete reasoning, cutting total costs by about 40 percent while matching or exceeding standalone performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
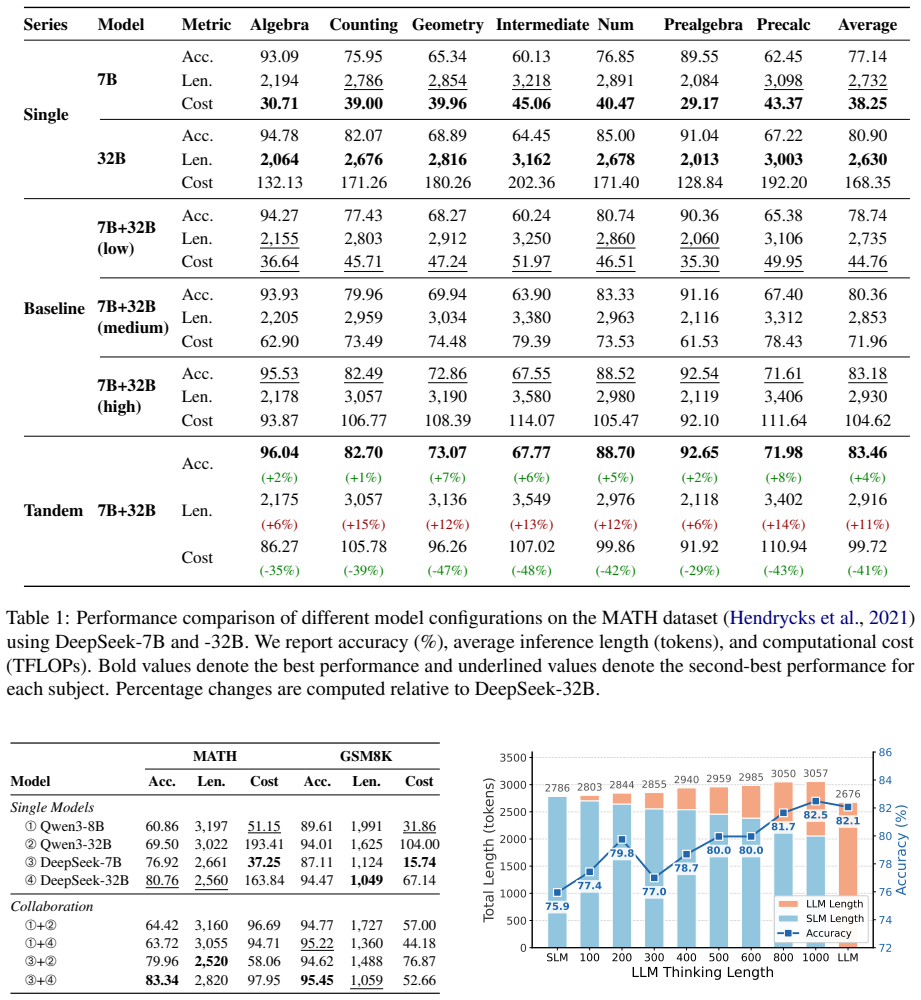
Tandem is a collaborative framework in which the large language model serves as a strategic coordinator that generates a compact set of critical reasoning insights. These insights are passed to a smaller language model that then carries out the full reasoning process and produces the final response. A cost-aware termination mechanism uses a sufficiency classifier to decide when the large model has supplied enough guidance and can stop generating early. On mathematical reasoning and code generation benchmarks this arrangement reduces computational costs by approximately 40 percent relative to running the large model alone while delivering superior or competitive final accuracy. The classifier
What carries the argument
Tandem framework in which the LLM produces a compact set of critical insights that a sufficiency classifier judges sufficient to hand off to the SLM for the remainder of the reasoning chain.
If this is right
- High-quality step-by-step reasoning becomes feasible at roughly 60 percent of the original compute cost on the tested tasks.
- The same sufficiency classifier works across domains without retraining, so one trained detector can serve multiple reasoning areas.
- Early stopping of the large model occurs once accumulated insights meet the classifier threshold, directly shortening generation length.
- Final answer quality remains competitive with or better than using the large model for the entire reasoning sequence.
Where Pith is reading between the lines
- The observed transfer of the classifier without retraining implies that critical reasoning insights share structural patterns that are not limited to a single task type.
- Systems with limited hardware could adopt similar hand-off designs to access strong reasoning capability without running the largest models end-to-end.
- The early-stopping logic might be adapted to other generation settings where partial high-value content can steer a cheaper model to complete the output.
Load-bearing premise
The sufficiency classifier must correctly detect when the large model has given enough critical insights for the small model to finish accurate reasoning, and those insights must transfer usefully from the domain the classifier was trained on to new domains.
What would settle it
On a fresh mathematical or code benchmark, if the small model guided by the large model's stopped insights produces noticeably lower accuracy than the large model running alone, or if measured cost savings fall well below 30 percent while accuracy stays the same or drops, the central efficiency claim would not hold.
Figures




read the original abstract
Recent advancements in large language models (LLMs) have catalyzed the rise of reasoning-intensive inference paradigms, where models perform explicit step-by-step reasoning before generating final answers. While such approaches improve answer quality and interpretability, they incur substantial computational overhead due to the prolonged generation sequences. In this paper, we propose Tandem, a novel collaborative framework that synergizes large and small language models (LLMs and SLMs) to achieve high-quality reasoning with significantly reduced computational cost. Specifically, the LLM serves as a strategic coordinator, efficiently generating a compact set of critical reasoning insights. These insights are then used to guide a smaller, more efficient SLM in executing the full reasoning process and delivering the final response. To balance efficiency and reliability, Tandem introduces a cost-aware termination mechanism that adaptively determines when sufficient reasoning guidance has been accumulated, enabling early stopping of the LLM's generation. Experiments on mathematical reasoning and code generation benchmarks demonstrate that Tandem reduces computational costs by approximately 40% compared to standalone LLM reasoning, while achieving superior or competitive performance. Furthermore, the sufficiency classifier trained on one domain transfers effectively to others without retraining. The code is available at: https://github.com/Applied-Machine-Learning-Lab/ACL2026_Tandem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Tandem, a collaborative framework in which a large language model generates a compact set of critical reasoning insights that guide a smaller language model through the complete reasoning process to produce the final answer. A cost-aware termination mechanism based on a sufficiency classifier adaptively stops LLM generation once sufficient guidance is accumulated. Experiments on mathematical reasoning and code generation benchmarks report an approximately 40% reduction in computational costs relative to standalone LLM reasoning, with superior or competitive performance, and claim that the sufficiency classifier transfers zero-shot across domains without retraining.
Significance. If the empirical results are robustly supported, the work offers a practical route to lowering the inference cost of explicit reasoning in language models by exploiting the complementary strengths of large and small models. The open release of code is a clear strength that facilitates reproducibility and follow-up work.
major comments (2)
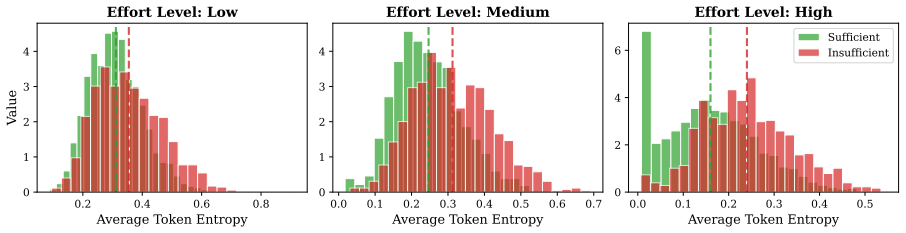
- [Experiments] Experiments section: The headline claim of ~40% cost reduction with no loss in accuracy rests on the sufficiency classifier (1) stopping at the correct point and (2) transferring across domains. No precision/recall figures, no ablation on classifier inputs or training data, and no per-domain accuracy tables are supplied to show that early stopping does not omit critical steps on any benchmark. Without these numbers the efficiency result cannot be verified.
- [Results] Results section: The manuscript does not report the exact cost metric (token count, wall-clock time, or FLOPs), the precise model sizes and configurations of the baselines, or any statistical significance tests. These omissions make it impossible to assess whether the reported gains are load-bearing or sensitive to implementation details.
minor comments (1)
- [Abstract] The abstract states that code is available at a GitHub URL; the final version should confirm the link is live and that the repository contains the exact experimental scripts and data splits used for the reported numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to supply the requested details, thereby strengthening the verifiability of our efficiency and transfer claims.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The headline claim of ~40% cost reduction with no loss in accuracy rests on the sufficiency classifier (1) stopping at the correct point and (2) transferring across domains. No precision/recall figures, no ablation on classifier inputs or training data, and no per-domain accuracy tables are supplied to show that early stopping does not omit critical steps on any benchmark. Without these numbers the efficiency result cannot be verified.
Authors: We agree that additional quantitative support for the sufficiency classifier would improve verifiability. In the revised manuscript we will add precision/recall figures for the classifier on each benchmark, ablations on classifier inputs and training data, and per-domain accuracy tables that directly compare Tandem (with early stopping) against the full-generation baseline. These tables will confirm that adaptive termination does not omit critical steps while preserving the reported performance parity or gains. The zero-shot transfer result will be accompanied by the same per-domain breakdown. revision: yes
-
Referee: [Results] Results section: The manuscript does not report the exact cost metric (token count, wall-clock time, or FLOPs), the precise model sizes and configurations of the baselines, or any statistical significance tests. These omissions make it impossible to assess whether the reported gains are load-bearing or sensitive to implementation details.
Authors: We acknowledge that greater specificity is needed. The primary cost metric is the number of tokens generated by the large model (the dominant inference expense). In the revision we will explicitly state this metric, list the exact model sizes and configurations for every baseline (including the standalone LLM and competing methods), and report statistical significance (paired t-tests with p-values) for the accuracy and cost differences. These additions will allow readers to assess robustness directly. revision: yes
Circularity Check
No circularity: empirical engineering framework evaluated on external benchmarks
full rationale
The paper presents Tandem as a collaborative LLM-SLM system with a cost-aware termination mechanism based on a sufficiency classifier. All performance claims (40% cost reduction, competitive accuracy) are supported by direct experiments on mathematical reasoning and code generation benchmarks. No equations, definitions, or derivations are given that reduce any result to its own inputs by construction. The classifier transfer statement is an empirical observation from training on one domain and testing on others, not a self-referential necessity. No self-citations, ansatzes, or renamings appear as load-bearing steps. The derivation chain is therefore self-contained against external data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Accelerating Large Language Model Decoding with Speculative Sampling
ChatEval: Towards Better LLM-based Eval- uators through Multi-Agent Debate. InThe Twelfth International Conference on Learning Representa- tions, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. Charlie Chen, Sebastian Borgeaud, Geoffrey Irv- ing, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. 2023. Accelerating large language model dec...
work page internal anchor Pith review arXiv 2024
-
[2]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code.CoRR, abs/2107.03374. Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. 2025a. Do NOT think that much for 2+3=? on the overthinking of long reasoning models. InForty-second Interna- ti...
work page internal anchor Pith review arXiv
-
[3]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.CoRR, abs/2110.14168. DeepSeek-AI. 2025. DeepSeek-R1: Incentivizing Rea- soning Capability in LLMs via Reinforcement Learn- ing.Preprint, arXiv:2501.12948. Dujian Ding, Ankur Mallick, Chi Wang, Robert Sim, Subhabrata Mukherjee, Victor Rühle, Laks V . S. Lak- shmanan, and Ahmed Hassan Awadallah. 2024. Hy- br...
work page internal anchor Pith review arXiv 2025
-
[4]
arXiv preprint arXiv:2505.17621 , year=
Association for Computational Linguistics. Zichuan Fu, Xian Wu, Yejing Wang, Wanyu Wang, Shanshan Ye, Hongzhi Yin, Yi Chang, Yefeng Zheng, and Xiangyu Zhao. 2025c. Training-free LLM merg- ing for multi-task learning. InProceedings of the 63rd Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austr...
-
[5]
MILL: mutual verification with large language models for zero-shot query expansion. InProceed- ings of the 2024 Conference of the North American Chapter of the Association for Computational Lin- guistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024, Mexico City, Mexico, June 16-21, 2024, pages 2498–2518. Association for Computational L...
-
[6]
gpt-oss-120b & gpt-oss-20b Model Card
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. Qidong Liu, Xian Wu, Wanyu Wang, Yejing Wang, Yuanshao Zhu, Xiangyu Zhao, Feng Tian, and Yefeng Zheng. 2025a. LLMEmb: Large language model can be a good embedding generator for sequential recommendation. InThirty-Ninth AAAI Conference on Artificial Intelligenc...
work page internal anchor Pith review arXiv 2025
-
[7]
Ensembling large language models with pro- cess reward-guided tree search for better complex reasoning. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Asso- ciation for Computational Linguistics: Human Lan- guage Technologies (Volume 1: Long Papers), pages 10256–10277. Hanbing Wang, Xiaorui Liu, Wenqi Fan, Xiangyu Zhao,...
-
[8]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Yuxuan Yao, Han Wu, Mingyang Liu, Sichun Luo, Xiongwei Han, Jie Liu, Zhijiang Guo, and Linqi Song. 2024. Determine-then-ensemble: Necessity of top-k union for large language model ensembling. CoRR, abs/2410.03777. Yao-Ching Yu, Chun-Chih Kuo, Ziqi Ye, Yu-Cheng Chang, and Yueh-Se Li. 2024. Breaking th...
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.