Recognition: unknown
HAC: Parameter-Efficient Hyperbolic Adaptation of CLIP for Zero-Shot VQA
Pith reviewed 2026-05-08 06:32 UTC · model grok-4.3
The pith
Lightweight adaptation moves pretrained CLIP into hyperbolic space and raises zero-shot VQA accuracy, especially on reasoning questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HAC performs parameter-efficient fine-tuning that projects pretrained CLIP embeddings into hyperbolic space, producing representations that outperform Euclidean CLIP and prior hyperbolic CLIP models on a range of zero-shot VQA benchmarks spanning general, reasoning, and OCR categories, with the largest lift on reasoning tasks.
What carries the argument
The HAC adaptation module, which adds a lightweight projection into hyperbolic space while freezing most of the original CLIP weights.
If this is right
- Existing CLIP checkpoints can be reused rather than discarded when moving to hyperbolic embeddings.
- Zero-shot VQA evaluation remains strict because no VQA data enters training.
- Reasoning tasks benefit most, suggesting hyperbolic space organizes the hierarchical relations needed for multi-step visual inference.
- The same adaptation recipe may apply to other CLIP-based tasks without task-specific data.
Where Pith is reading between the lines
- The approach could be tested on retrieval or captioning benchmarks that also rely on hierarchical structure.
- If hyperbolic geometry proves consistently superior, future foundation models might be trained directly in hyperbolic space from the start.
- The parameter budget used for adaptation offers a practical knob for trading compute against accuracy in other multimodal settings.
Load-bearing premise
The performance gains come specifically from the hyperbolic geometry rather than from the fine-tuning procedure or from incidental alignment between the adaptation data and the VQA tests.
What would settle it
An ablation that trains an otherwise identical Euclidean adapter with the same number of parameters and the same non-VQA data, then measures whether its VQA accuracy matches or exceeds the hyperbolic version.
Figures


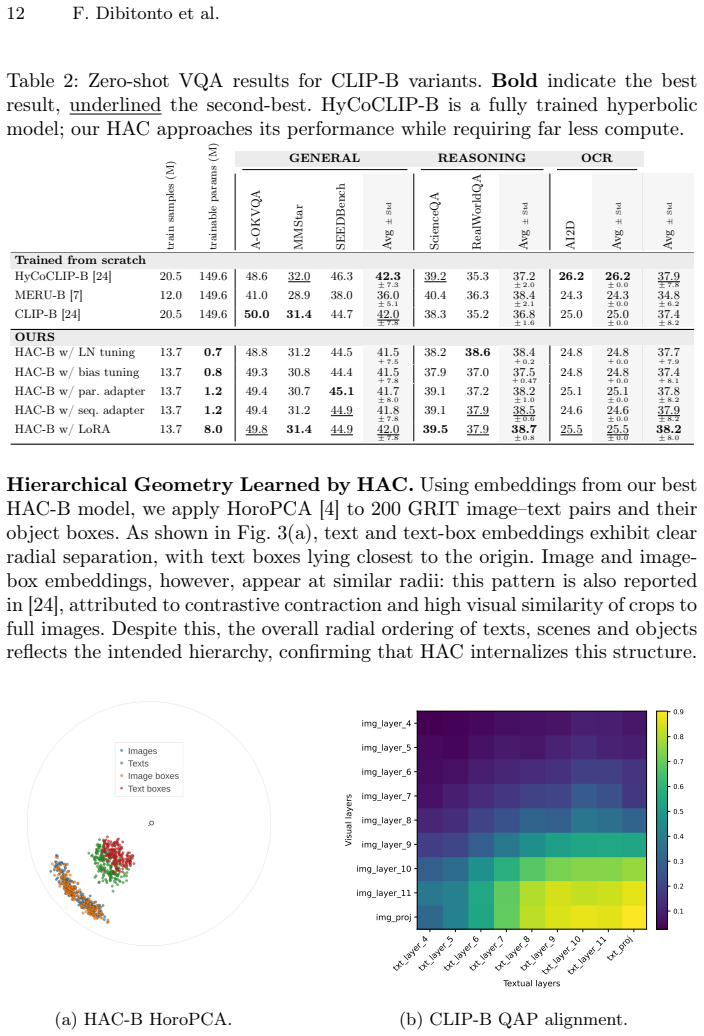
read the original abstract
Recent advances in representation learning have shown that hyperbolic geometry can offer a more expressive alternative to the Euclidean embeddings used in CLIP models, capturing hierarchical structures and leading to better-organized representations. However, current hyperbolic CLIP variants are trained entirely from scratch, which is computationally expensive and resource-intensive. In this work, we propose HAC (Hyperbolic Adaptation of CLIP), a parameter-efficient framework that enables pretrained CLIP models to transition into hyperbolic space via lightweight fine-tuning. We apply HAC to Visual Question Answering (VQA), where models must interpret visual elements and align them with textual queries. Notably, HAC's training is performed on a dataset with no overlap with any VQA benchmark, resulting in a strict zero-shot evaluation paradigm that underscores HAC's task-agnostic adaptability. We evaluate HAC across a diverse suite of VQA benchmarks spanning General, Reasoning, and OCR categories. Both HAC-S (small) and HAC-B (medium) consistently surpass Euclidean baselines and prior hyperbolic approaches, with HAC-B delivering up to a +1.9 point average improvement over CLIP-B on reasoning-intensive tasks. Our code is available at https://github.com/fdibiton/HAC
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HAC, a parameter-efficient framework for adapting pretrained CLIP models into hyperbolic space via lightweight fine-tuning on a non-VQA dataset. It evaluates the approach in a strict zero-shot setting on diverse VQA benchmarks (General, Reasoning, OCR), claiming consistent gains over Euclidean CLIP baselines and prior hyperbolic methods, including up to +1.9 average improvement for HAC-B on reasoning-intensive tasks.
Significance. If the gains can be attributed to hyperbolic geometry rather than adaptation alone, the work would offer a practical route to more expressive embeddings in vision-language models without full retraining from scratch. The task-agnostic training protocol and public code release strengthen the contribution by enabling verification and extension.
major comments (1)
- [Experimental Evaluation] Experimental section (results tables and ablation studies): the headline performance deltas (e.g., +1.9 on reasoning tasks) are reported only against standard CLIP-B and earlier hyperbolic CLIP variants. No Euclidean control is presented that applies the identical parameter-efficient adapter, training data, optimizer, and hyperparameters entirely in Euclidean space. Without this ablation, the central claim that improvements arise from hyperbolic geometry cannot be isolated from the effects of the adaptation procedure itself.
minor comments (2)
- [Abstract] Abstract and §3: the description of the adaptation architecture, loss functions, and hyperparameter selection is high-level; even with the code link, explicit equations or pseudocode for the hyperbolic projection and adapter modules would improve clarity.
- [Results] Table captions and §4: report standard deviations or statistical significance tests across runs to support the claim of consistent outperformance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment point by point below.
read point-by-point responses
-
Referee: Experimental section (results tables and ablation studies): the headline performance deltas (e.g., +1.9 on reasoning tasks) are reported only against standard CLIP-B and earlier hyperbolic CLIP variants. No Euclidean control is presented that applies the identical parameter-efficient adapter, training data, optimizer, and hyperparameters entirely in Euclidean space. Without this ablation, the central claim that improvements arise from hyperbolic geometry cannot be isolated from the effects of the adaptation procedure itself.
Authors: We appreciate the referee's observation that a direct Euclidean control using the identical adapter would better isolate the contribution of hyperbolic geometry. The current manuscript compares HAC against unadapted Euclidean CLIP-B baselines and prior hyperbolic CLIP variants trained from scratch. While these results support the overall effectiveness of the approach, we agree that the suggested ablation strengthens the central claim. We will add this control experiment to the revised manuscript, applying the same parameter-efficient adapter, training data, optimizer, and hyperparameters but operating entirely in Euclidean space. revision: yes
Circularity Check
No circularity: empirical method with independent evaluation
full rationale
The paper introduces HAC as a parameter-efficient adaptation procedure that fine-tunes pretrained CLIP into hyperbolic space on a non-VQA corpus, then reports zero-shot VQA performance gains. No equations, derivations, or first-principles predictions appear in the provided text. The central claims rest on direct experimental comparisons against Euclidean baselines and prior hyperbolic models; these comparisons are not forced by construction, self-definition, or load-bearing self-citation. The evaluation protocol (non-overlapping training data, strict zero-shot) is externally verifiable and does not reduce to a renaming or fitted input presented as a prediction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hyperbolic geometry captures hierarchical structures more effectively than Euclidean embeddings for vision-language tasks
Reference graph
Works this paper leans on
-
[1]
In: ICCV (2015) Parameter-Efficient Hyperbolic Adaptation of CLIP for Zero-Shot VQA 17
Antol, S., Agrawal, A., Lu, J., Mitchell, M., Batra, D., Zitnick, C.L., Parikh, D.: VQA: visual question answering. In: ICCV (2015) Parameter-Efficient Hyperbolic Adaptation of CLIP for Zero-Shot VQA 17
2015
-
[2]
Ba, J.L., Kiros, J.R., Hinton, G.E.: Layer normalization. arXiv:1607.06450 (2016)
work page internal anchor Pith review arXiv 2016
-
[3]
In: ACL (2023)
Cao, R., Jiang, J.: Modularized zero-shot VQA with pre-trained models. In: ACL (2023)
2023
-
[4]
In: ICML (2021)
Chami, I., Gu, A., Nguyen, D., Ré, C.: Horopca: Hyperbolic dimensionality reduc- tion via horospherical projections. In: ICML (2021)
2021
-
[5]
Chen, L., Li, J., Dong, X., Zhang, P., Zang, Y., Chen, Z., Duan, H., Wang, J., Qiao, Y., Lin, D., Zhao, F.: Are we on the right way for evaluating large vision-language models? In: Neurips (2024)
2024
-
[6]
In: NeurIPS (2021)
Desai, K., Kaul, G., Aysola, Z., Johnson, J.: Redcaps: Web-curated image-text data created by the people, for the people. In: NeurIPS (2021)
2021
-
[7]
In: ICML (2023)
Desai, K., Nickel, M., Rajpurohit, T., Johnson, J., Vedantam, S.R.: Hyperbolic image-text representations. In: ICML (2023)
2023
-
[8]
In: ICML (2018)
Ganea, O., Bécigneul, G., Hofmann, T.: Hyperbolic entailment cones for learning hierarchical embeddings. In: ICML (2018)
2018
-
[9]
In: ICLR (2022)
He, J., Zhou, C., Ma, X., Berg-Kirkpatrick, T., Neubig, G.: Towards a unified view of parameter-efficient transfer learning. In: ICLR (2022)
2022
-
[10]
In: CVPR (2016)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
2016
-
[11]
In: ICML (2019)
Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., de Laroussilhe, Q., Ges- mundo, A., Attariyan, M., Gelly, S.: Parameter-efficient transfer learning for NLP. In: ICML (2019)
2019
-
[12]
In: ICLR (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: Lora: Low-rank adaptation of large language models. In: ICLR (2022)
2022
-
[13]
In: EMNLP (2022)
Ivgi, M., Carmon, Y., Berant, J.: Scaling laws under the microscope: Predicting transformer performance from small scale experiments. In: EMNLP (2022)
2022
-
[14]
In: ICLR (2024)
Jain, N., Chiang, P., Wen, Y., Kirchenbauer, J., Chu, H., Somepalli, G.: Neftune: Noisy embeddings improve instruction finetuning. In: ICLR (2024)
2024
-
[15]
A rank stabilization scaling factor for fine-tuning with lora
Kalajdzievski, D.: A rank stabilization scaling factor for fine-tuning with lora. arXiv:2312.03732 (2023)
-
[16]
In: ECCV (2016)
Kembhavi, A., Salvato, M., Kolve, E., Seo, M.J., Hajishirzi, H., Farhadi, A.: A diagram is worth a dozen images. In: ECCV (2016)
2016
-
[17]
Graduate Texts in Mathematics (2019)
Lee, J.M.: Introduction to riemannian manifolds. Graduate Texts in Mathematics (2019)
2019
-
[18]
CVPR (2024)
Li, B., Ge, Y., Ge, Y., Wang, G., Wang, R., Zhang, R., Shan, Y.: Seed-bench: Benchmarking multimodal large language models. CVPR (2024)
2024
-
[19]
In: ICLR (2017)
Loshchilov, I., Hutter, F.: SGDR: stochastic gradient descent with warm restarts. In: ICLR (2017)
2017
-
[20]
In: ICLR (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: ICLR (2019)
2019
-
[21]
In: NeurIPS (2022)
Lu, P., Mishra, S., Xia, T., Qiu, L.e.a.: Learn to explain: Multimodal reasoning via thought chains for science question answering. In: NeurIPS (2022)
2022
-
[22]
Maniparambil, M., Akshulakov, R., Djilali, Y.A.D., Narayan, S., Seddik, M.E.A., Mangalam, K., O’Connor, N.E.: Do vision and language encoders represent the world similarly? CVPR (2024)
2024
-
[23]
In: Neurips (2017)
Nickel, M., Kiela, D.: Poincaré embeddings for learning hierarchical representa- tions. In: Neurips (2017)
2017
-
[24]
In: ICLR (2025)
Pal, A., van Spengler, M., di Melendugno, G.M.D., Flaborea, A., Galasso, F., Mettes, P.: Compositional entailment learning for hyperbolic vision-language mod- els. In: ICLR (2025)
2025
-
[25]
In: ICLR (2024) 18 F
Peng, Z., Wang, W., Dong, L., Hao, Y., Huang, S., Ma, S., Ye, Q., Wei, F.: Ground- ing multimodal large language models to the world. In: ICLR (2024) 18 F. Dibitonto et al
2024
-
[26]
In: EMNLP (2023)
Poth, C., Sterz, H., Paul, I., Purkayastha, S., Engländer, L., Imhof, T., Vulić, I., Ruder, S., Gurevych, I., Pfeiffer, J.: Adapters: A unified library for parameter- efficient and modular transfer learning. In: EMNLP (2023)
2023
-
[27]
In: ICML (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: ICML (2021)
2021
-
[28]
Graduate Texts in Mathe- matics (2006)
Ratcliffe, J.G.: Foundations of hyperbolic manifolds. Graduate Texts in Mathe- matics (2006)
2006
-
[29]
In: ECCV (2022)
Schwenk, D., Khandelwal, A., Clark, C., Marino, K., Mottaghi, R.: A-okvqa: A benchmark for visual question answering using world knowledge. In: ECCV (2022)
2022
-
[30]
Shen, S., Li, L.H., Tan, H., Bansal, M., Rohrbach, A., Chang, K., Yao, Z., Keutzer, K.: How much can CLIP benefit vision-and-language tasks? In: ICLR (2022)
2022
-
[31]
In: MICCAI (2025)
Shiri, M., Beyan, C., Murino, V.: MadCLIP: Few-shot medical anomaly detection with CLIP. In: MICCAI (2025)
2025
-
[32]
In: ICIAP (2025)
Shiri,M.,Beyan,C.,Murino,V.:MADPOT:MedicalanomalydetectionwithCLIP adaptation and partial optimal transport. In: ICIAP (2025)
2025
-
[33]
In: ACL (2022)
Song, H., Dong, L., Zhang, W., Liu, T., Wei, F.: CLIP models are few-shot learners: Empirical studies on VQA and visual entailment. In: ACL (2022)
2022
-
[34]
xAI: Realworldqa dataset.https://x.ai/news/grok-1.5v(2024)
2024
-
[35]
In: ACL (2022)
Zaken, E.B., Goldberg, Y., Ravfogel, S.: Bitfit: Simple parameter-efficient fine- tuning for transformer-based masked language-models. In: ACL (2022)
2022
-
[36]
In: ICLR (2024)
Zhao, B., Tu, H., Wei, C., Mei, J., Xie, C.: Tuning layernorm in attention: Towards efficient multi-modal LLM finetuning. In: ICLR (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.