Recognition: unknown
Vibe Medicine: Redefining Biomedical Research Through Human-AI Co-Work
Pith reviewed 2026-05-08 06:12 UTC · model grok-4.3
The pith
Clinicians direct AI agents via natural language to run complex biomedical workflows while retaining oversight and decision authority.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
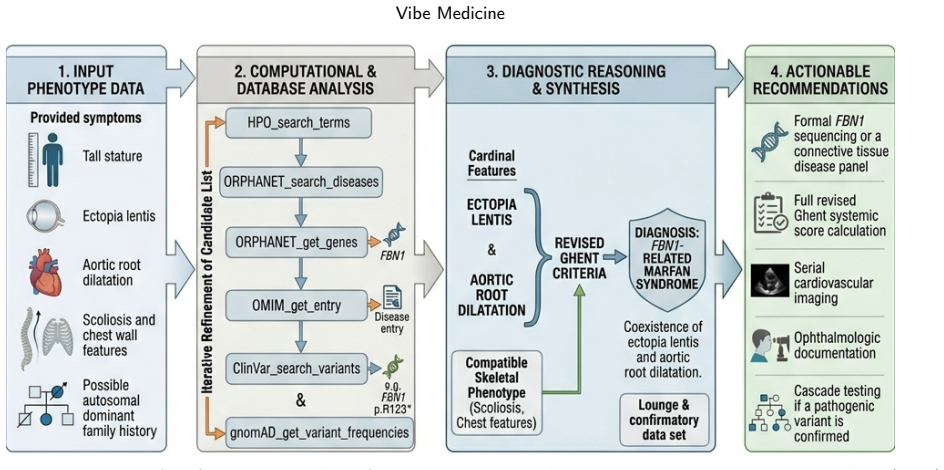
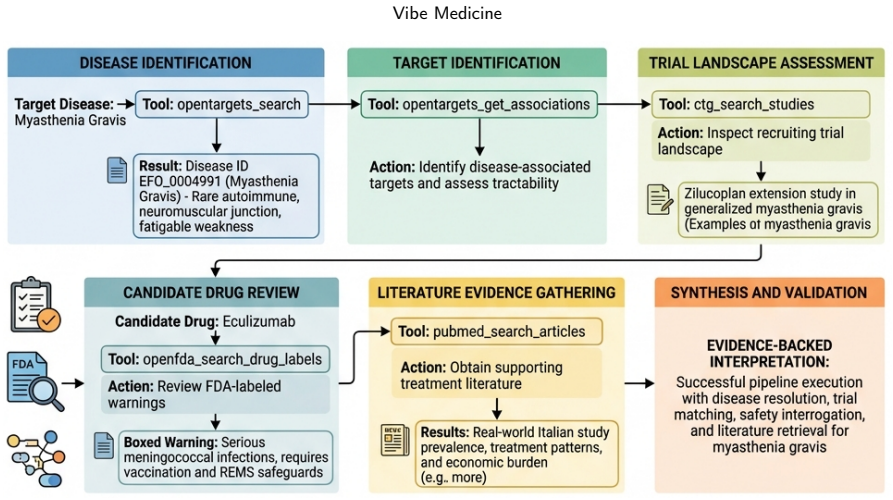
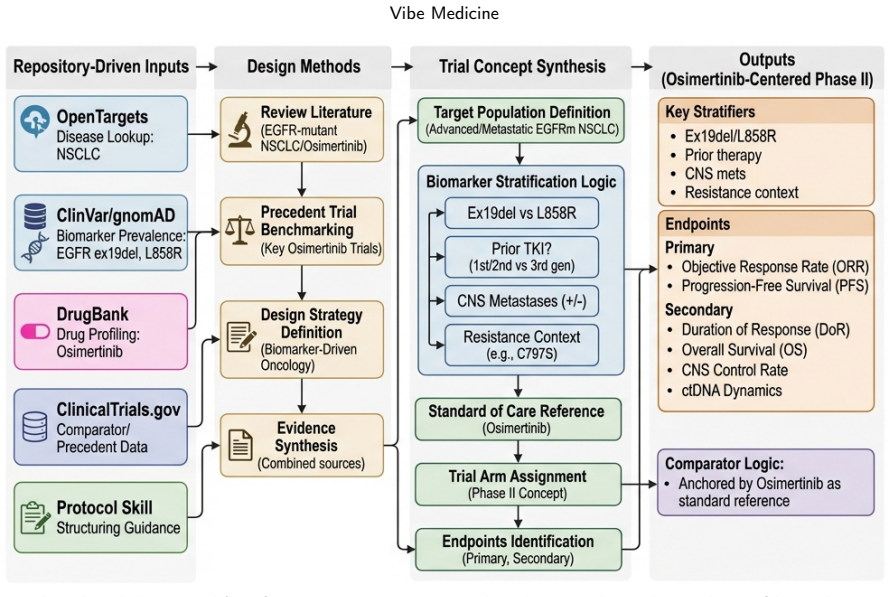
Vibe Medicine is a co-work paradigm in which clinicians and researchers direct skill-augmented AI agents through natural language to execute complex, multi-step biomedical workflows. The enabling layers are capable LLMs, agent frameworks such as OpenClaw and Hermes Agent, and the OpenClaw medical skills collection of more than 1,000 curated skills drawn from open-source repositories across ten domains. Humans retain the role of research director by specifying objectives, reviewing results, and making domain-informed decisions. Demonstrations in rare disease diagnosis, drug repurposing, and clinical trial design illustrate end-to-end execution, with the broader goal of advancing research and,
What carries the argument
The OpenClaw medical skills collection of more than 1,000 curated skills across ten biomedical domains, which augments agent frameworks so that natural-language instructions can trigger reliable multi-step analysis on heterogeneous data.
If this is right
- End-to-end biomedical workflows become executable from natural language instructions without requiring the user to write code.
- Applications extend to rare disease diagnosis, drug repurposing, and clinical trial design through demonstrated case studies.
- Specialized labor demands decrease, enabling more independent researchers and those in low-resource settings to conduct advanced work.
- Risks of hallucination, privacy breaches, and over-reliance must be addressed to reach clinically trustworthy integration.
- Future development focuses on more reliable and equitable agent-assisted biomedical research systems.
Where Pith is reading between the lines
- Similar skill-augmented agent collections could be built for non-biomedical domains to support analogous co-work models.
- Training for biomedical researchers may shift emphasis toward task specification and result interpretation rather than tool implementation details.
- Real-world deployment would require quantitative benchmarks of agent accuracy against expert performance on representative pipelines.
- Wider use could shorten the time from hypothesis to analyzed results by enabling rapid iteration on analytical choices.
Load-bearing premise
Current large language models together with existing agent frameworks and the medical skills collection can handle mixed biomedical data types and multi-step pipelines at acceptably low rates of hallucination or error.
What would settle it
A head-to-head test on a multi-step task such as drug repurposing where an expert performs the analysis manually and an agent performs it under Vibe Medicine direction, then measures the frequency of factual errors or invalid conclusions in the agent output.
Figures


read the original abstract
With the emergence of large language models (LLMs) and AI agent frameworks, the human-AI co-work paradigm known as Vibe Coding is changing how people code, making it more accessible and productive. In scientific research, where workflows are more complex and the burden of specialized labor limits independent researchers and those in low-resource areas, the potential impact is even greater, particularly in biomedicine, which involves heterogeneous data modalities and multi-step analytical pipelines. In this paper, we introduce Vibe Medicine, a co-work paradigm in which clinicians and researchers direct skill-augmented AI agents through natural language to execute complex, multi-step biomedical workflows, while retaining the role of research director who specifies objectives, reviews intermediate results, and makes domain-informed decisions. The enabling infrastructure consists of three layers: capable LLMs, agent frameworks such as OpenClaw and Hermes Agent, and the OpenClaw medical skills collection, which includes more than 1,000 curated skills from multiple open-source repositories. We analyze the architecture and skill categories of this collection across ten biomedical domains, and present case studies covering rare disease diagnosis, drug repurposing, and clinical trial design that demonstrate end-to-end workflows in practice. We also identify the principal risks, such as hallucination, data privacy, and over-reliance, and outline directions toward more reliable, trustworthy, and clinically integrated agent-assisted research that advances research and technological equity and reduces health care resource disparities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes 'Vibe Medicine' as a human-AI co-work paradigm in which clinicians and researchers direct skill-augmented AI agents (via LLMs, frameworks such as OpenClaw and Hermes, and a collection of >1,000 curated medical skills) through natural language to execute complex multi-step biomedical workflows, while humans retain oversight as research directors. It describes the three-layer enabling infrastructure, analyzes skill categories across ten biomedical domains, presents three illustrative case studies (rare disease diagnosis, drug repurposing, and clinical trial design) as end-to-end demonstrations, and discusses risks including hallucination, data privacy, and over-reliance along with future directions for trustworthy integration.
Significance. If the core assumption holds, the paradigm could meaningfully lower barriers to advanced biomedical research for independent investigators and low-resource settings by shifting specialized labor to AI agents, thereby supporting greater equity in research output and healthcare innovation. The structured analysis of the skills collection across domains provides a useful inventory of current agent capabilities, and the explicit treatment of risks contributes to responsible framing of AI-assisted science.
major comments (3)
- [Case Studies] The case studies (rare disease diagnosis, drug repurposing, clinical trial design) are presented as demonstrations of end-to-end workflows, yet they consist solely of qualitative prompt-and-response traces with no reported quantitative metrics such as success rates, step-wise error rates, hallucination frequency, or expert-validated accuracy. This absence directly undermines the central claim that current LLMs combined with the OpenClaw/Hermes frameworks and skills collection can reliably handle heterogeneous data modalities and multi-step pipelines.
- [Infrastructure Description] The infrastructure section asserts that the OpenClaw medical skills collection (>1,000 curated skills from open-source repositories) enables the described co-work, but provides no details on curation criteria, accuracy validation of individual skills, or empirical testing against multi-modal biomedical data; without such grounding, the feasibility of the 'skill-augmented agents' premise remains untested.
- [Case Studies] The paper states that humans retain the role of research director who reviews results and makes domain-informed decisions, but the case studies supply no data on intervention frequency, error propagation, or how often AI outputs require correction, leaving the practicality of this oversight model unsupported.
minor comments (2)
- [Abstract] The abstract claims the case studies 'demonstrate end-to-end workflows in practice,' but this phrasing should be qualified to reflect their illustrative rather than evaluative nature.
- [Introduction] The distinction between 'Vibe Medicine' and the referenced 'Vibe Coding' paradigm could be clarified with a brief explicit comparison to avoid potential reader confusion.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. The comments identify important gaps in the empirical support for our claims, and we have revised the manuscript to clarify the illustrative nature of the case studies, expand details on the skills collection, and add explicit discussion of limitations and future validation needs.
read point-by-point responses
-
Referee: [Case Studies] The case studies (rare disease diagnosis, drug repurposing, clinical trial design) are presented as demonstrations of end-to-end workflows, yet they consist solely of qualitative prompt-and-response traces with no reported quantitative metrics such as success rates, step-wise error rates, hallucination frequency, or expert-validated accuracy. This absence directly undermines the central claim that current LLMs combined with the OpenClaw/Hermes frameworks and skills collection can reliably handle heterogeneous data modalities and multi-step pipelines.
Authors: We agree that the case studies are qualitative demonstrations rather than quantitative benchmarks and do not include metrics such as success rates or hallucination frequency. The manuscript frames them as illustrations of the Vibe Medicine paradigm in practice. In the revised version, we have added explicit statements in the case studies section and a new 'Limitations and Future Directions' subsection clarifying their illustrative purpose and outlining plans for systematic quantitative evaluation, including error rates and expert validation in follow-up studies. This addresses the concern by tempering the claims accordingly. revision: partial
-
Referee: [Infrastructure Description] The infrastructure section asserts that the OpenClaw medical skills collection (>1,000 curated skills from open-source repositories) enables the described co-work, but provides no details on curation criteria, accuracy validation of individual skills, or empirical testing against multi-modal biomedical data; without such grounding, the feasibility of the 'skill-augmented agents' premise remains untested.
Authors: The referee is correct that the original infrastructure section lacked sufficient detail on curation and validation. We have revised this section to describe the curation criteria, which prioritized skills from established open-source biomedical repositories based on task relevance, documentation quality, and existing community adoption. We also note that comprehensive per-skill accuracy validation and large-scale empirical testing on multi-modal data remain ongoing community efforts rather than completed work. The updated text now presents the collection as an enabling starting point while acknowledging the need for further grounding. revision: partial
-
Referee: [Case Studies] The paper states that humans retain the role of research director who reviews results and makes domain-informed decisions, but the case studies supply no data on intervention frequency, error propagation, or how often AI outputs require correction, leaving the practicality of this oversight model unsupported.
Authors: We acknowledge that the case studies are narrative and do not quantify human interventions, error propagation, or correction frequency. In the revision, we have added text in the case studies and limitations sections recognizing this gap and proposing that future agent frameworks incorporate logging to enable such measurements. This supports the conceptual oversight model while making clear that empirical data on its practicality will require dedicated follow-on studies. revision: partial
Circularity Check
No derivation chain or fitted results; purely descriptive proposal
full rationale
The paper introduces the Vibe Medicine paradigm as a human-AI co-work model enabled by existing LLMs, agent frameworks (OpenClaw, Hermes), and a curated skills collection. It analyzes skill categories across domains and presents three illustrative case studies as qualitative demonstrations. No equations, predictions, first-principles derivations, or parameter fittings appear anywhere in the text. The central claim does not reduce any result to quantities defined by its own inputs, nor does it rely on self-citation chains for uniqueness theorems or ansatzes. The proposal remains self-contained as a descriptive framework without circular reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs and agent frameworks can be reliably augmented with curated domain skills to execute multi-step biomedical workflows under human direction
invented entities (1)
-
Vibe Medicine paradigm
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Abramson,J.,Adler,J.,Dunger,J.,Evans,R.,Green,T.,Pritzel,A., Ronneberger, O., Willmore, L., Ballard, A.J., Bambrick, J., et al.,
-
[2]
Nature 630, 493–500
Accurate structure prediction of biomolecular interactions with AlphaFold 3. Nature 630, 493–500
-
[3]
medical-research-skills.https://github.com/ aipoch/medical-research-skills.GitHubrepository,accessed2026- 04-04
AIPOCH, 2026. medical-research-skills.https://github.com/ aipoch/medical-research-skills.GitHubrepository,accessed2026- 04-04
2026
-
[4]
The repertoire of mutational signatures in human cancer
Alexandrov,L.B.,Kim,J.,Haradhvala,N.J.,Huang,M.N.,TianNg, A.W., Wu, Y., Boot, A., et al., 2020. The repertoire of mutational signatures in human cancer. Nature 578, 94–101
2020
-
[5]
Introducing the Model Context Protocol.https: //www.anthropic.com/news/model-context-protocol
Anthropic, 2024. Introducing the Model Context Protocol.https: //www.anthropic.com/news/model-context-protocol. Open standard for connecting AI assistants to data sources and tools
2024
-
[6]
MOFA+:astatisticalframeworkfor comprehensiveintegrationofmulti-modalsingle-celldata
Argelaguet, R., Arnol, D., Bredikhin, D., Deloro, Y., Velten, B., Marioni,J.C.,Stegle,O.,2020. MOFA+:astatisticalframeworkfor comprehensiveintegrationofmulti-modalsingle-celldata. Genome Biology 21, 111
2020
-
[7]
Genomics in the cloud: Using Docker, GATK, and WDL in Terra
Van der Auwera, G.A., O’Connor, B.D., 2020. Genomics in the cloud: Using Docker, GATK, and WDL in Terra
2020
-
[8]
Integrating taxonomic, functional, and strain-level profiling of diverse microbial communi- ties with bioBakery 3
Beghini, F., McIver, L.J., Blanco-Miguez, A., Dubois, L., Asnicar, F., Maharjan, S., Mailyan, A., et al., 2021. Integrating taxonomic, functional, and strain-level profiling of diverse microbial communi- ties with bioBakery 3. eLife 10, e65088
2021
-
[9]
Reproducible, interactive, scalable and extensible microbiome data science using QIIME 2
Bolyen, E., Rideout, J.R., Dillon, M.R., Bokulich, N.A., Abnet, C.C., Al-Ghalith, G.A., Alexander, H., et al., 2019. Reproducible, interactive, scalable and extensible microbiome data science using QIIME 2. Nature Biotechnology 37, 852–857
2019
-
[10]
Augmenting large language models with chemistry tools
Bran, A.M., Cox, S., Schilter, O., Baldassari, C., White, A.D., Schwaller, P., 2024. Augmenting large language models with chemistry tools. Nat. Mach. Intell. 6, 525–535
2024
-
[11]
Borg, omega, and kubernetes
Burns, B., et al., 2016. Borg, omega, and kubernetes. Communica- tions of the ACM
2016
-
[12]
Chai-1: Decoding the molecular interactions of life
Chai Discovery team, Boitreaud, J., Dent, J., McPartlon, M., Meier, J., Reis, V., Rogozhonikov, A., Wu, K., 2024. Chai-1: Decoding the molecular interactions of life. bioRxiv , 2024–10
2024
-
[13]
Analysis of 100,000 human cancer genomes reveals the landscape of tumor mutational burden
Chalmers, Z.R., Connelly, C.F., Fabrizio, D., Gay, L., Ali, S.M., Ennis, R., Schrock, A., et al., 2017. Analysis of 100,000 human cancer genomes reveals the landscape of tumor mutational burden. Genome Medicine 9, 34
2017
-
[14]
fastp:anultra-fastall-in- one FASTQ preprocessor
Chen,S.,Zhou,Y.,Chen,Y.,Gu,J.,2018. fastp:anultra-fastall-in- one FASTQ preprocessor. Bioinformatics 34, i884–i890
2018
-
[15]
Manta: rapid detection of structural variants and indels for germline and cancer sequencing applications
Chen,X.,Schulz-Trieglaff,O.,Shaw,R.,Barnes,B.,Schlesinger,F., Källberg,M.,Cox,A.J.,Kruglyak,S.,Saunders,C.T.,2016. Manta: rapid detection of structural variants and indels for germline and cancer sequencing applications. Bioinformatics 32, 1220–1222
2016
-
[16]
PRSice-2: Polygenic Risk Score software for biobank-scale data
Choi, S.W., O’Reilly, P.F., 2019. PRSice-2: Polygenic Risk Score software for biobank-scale data. GigaScience 8, giz082
2019
-
[17]
Integration of customised LLM for discharge summary generation in real-world clinical settings: a pilot study on RUSSELL GPT
Chua, C.E., Clara, N.L.Y., Furqan, M.S., Kit, J.L.W., Makmur, A., Tham, Y.C., Santosa, A., Ngiam, K.Y., 2024. Integration of customised LLM for discharge summary generation in real-world clinical settings: a pilot study on RUSSELL GPT. The Lancet Regional Health–Western Pacific 51
2024
-
[18]
NanoClaw: Secure AI agent for WhatsApp, Telegram and more.https://nanoclaw.dev/
Cohen, G., 2026. NanoClaw: Secure AI agent for WhatsApp, Telegram and more.https://nanoclaw.dev/. Built on Anthropic Claude Agent SDK; container-isolated execution
2026
-
[19]
Regression models and life-tables
Cox, D.R., 1972. Regression models and life-tables. J. R. Stat. Soc. Ser. B 34, 187–202
1972
-
[20]
Agentic AI in radiology: emerging potential and unresolved challenges
Dietrich, N., 2025. Agentic AI in radiology: emerging potential and unresolved challenges. Br. J. Radiol. 98, 1582–1584. doi:10.1093/ bjr/tqaf173
2025
-
[21]
STAR: ultrafast universal RNA-seq aligner
Dobin,A.,Davis,C.A.,Schlesinger,F.,Drenkow,J.,Zaleski,C.,Jha, S., Batut, P., Chaisson, M., Gingeras, T.R., 2013. STAR: ultrafast universal RNA-seq aligner. Bioinformatics 29, 15–21
2013
-
[22]
Regulation (EU) 2024/1689 laying down harmonised rules on ar- tificialintelligence(AIact)
European Parliament and Council of the European Union, 2024. Regulation (EU) 2024/1689 laying down harmonised rules on ar- tificialintelligence(AIact). OfficialJournaloftheEuropeanUnion; high-risk AI medical device obligations effective August 2027
2024
-
[23]
MultiQC: summarizeanalysisresultsformultipletoolsandsamplesinasingle report
Ewels, P., Magnusson, M., Lundin, S., Käller, M., 2016. MultiQC: summarizeanalysisresultsformultipletoolsandsamplesinasingle report. Bioinformatics 32, 3047–3048
2016
-
[24]
Uncover this tech term: Agentic artificial intelligence in radiology
Faghani, S., Moassefi, M., Rouzrokh, P., Khosravi, B., Erickson, B.J., 2025. Uncover this tech term: Agentic artificial intelligence in radiology. Korean J. Radiol. 26, 888–892. doi:10.3348/kjr.2025. 0370
-
[25]
Towards trustworthy AI: A review of ethical and robust large language models
Ferdaus, M.M., Abdelguerfi, M., Ioup, E., Niles, K.N., Pathak, K., Sloan, S., 2026. Towards trustworthy AI: A review of ethical and robust large language models. ACM Computing Surveys 58, 1–43. doi:10.1145/3777382
-
[26]
The evolving role of preprints in the disseminationofCOVID-19researchandtheirimpactonthescience Z
Fraser, N., Brierley, L., Dey, G., Polka, J.K., Pálfy, M., Nanni, F., Coates, J.A., 2021. The evolving role of preprints in the disseminationofCOVID-19researchandtheirimpactonthescience Z. Wu et al.:Preprint submitted to ElsevierPage 17 of 20 Vibe Medicine communication landscape. PLOS Biology 19, e3000959. doi:10. 1371/journal.pbio.3000959
2021
-
[27]
OpenClaw Medical Skills: The largest open-source medical AI skills library.https://github.com/ FreedomIntelligence/OpenClaw-Medical-Skills
FreedomIntelligence, 2025. OpenClaw Medical Skills: The largest open-source medical AI skills library.https://github.com/ FreedomIntelligence/OpenClaw-Medical-Skills
2025
-
[28]
The REporting of A disproportionality analysis forDrUgsafetysignaldetectionusingindividualcasesafetyreports inPharmacoVigilance(READUS-PV):explanationandelaboration
Fusaroli, M., Salvo, F., Begaud, B., AlShammari, T.M., Bate, A., Battini, V., Brueckner, A., Candore, G., Carnovale, C., Crisafulli, S., et al., 2024. The REporting of A disproportionality analysis forDrUgsafetysignaldetectionusingindividualcasesafetyreports inPharmacoVigilance(READUS-PV):explanationandelaboration. Drug Safety 47, 585–599
2024
-
[29]
Gao, S., Zhu, R., Kong, Z., Noori, A., Su, X., Ginder, C., Tsiligkaridis, T., Zitnik, M., 2025a. TxAgent: An AI agent for therapeutic reasoning across a universe of tools. arXiv preprint arXiv:2503.10970
-
[30]
Democratizing ai scientists using tooluniverse.arXiv preprint arXiv:2509.23426, 2025
Gao, S., Zhu, R., Sui, P., Kong, Z., Aldogom, S., Huang, Y., Noori, A.,Shamji,R.,Parvataneni,K.,Tsiligkaridis,T.,Zitnik,M.,2025b. Democratizing AI scientists using ToolUniverse. arXiv preprint arXiv:2509.23426
-
[31]
ChEMBL:alarge-scalebioactivitydatabasefordrug discovery
Gaulton, A., Bellis, L.J., Bento, A.P., Chambers, J., Davies, M., Hersey,A.,Light,Y.,McGlinchey,S.,Michalovich,D.,Al-Lazikani, B.,etal.,2012. ChEMBL:alarge-scalebioactivitydatabasefordrug discovery. Nucleic Acids Research 40, D1100–D1107
2012
-
[32]
arXiv preprint arXiv:2510.12399 , year=
Ge, Y., Mei, L., Duan, Z., Li, T., Zheng, Y., Wang, Y., Wang, L., Yao, J., Liu, T., Cai, Y., et al., 2025. A survey of vibe coding with large language models. arXiv preprint arXiv:2510.12399
-
[33]
GRADE: an emerging consensus on rating quality of evidence and strength of recommen- dations
Guyatt, G.H., Oxman, A.D., Vist, G.E., Kunz, R., Falck-Ytter, Y., Alonso-Coello, P., Schünemann, H.J., 2008. GRADE: an emerging consensus on rating quality of evidence and strength of recommen- dations. BMJ 336, 924–926
2008
-
[34]
Integratedanalysisofmultimodal single-cell data
Hao,Y.,Hao,S.,Andersen-Nissen,E.,MauckIII,W.M.,Zheng,S., Butler,A.,Lee,M.J.,etal.,2021. Integratedanalysisofmultimodal single-cell data. Cell 184, 3573–3587
2021
-
[35]
Metagpt:Metaprogrammingfor amulti-agentcollaborativeframework
Hong, S., Zhuge, M., Chen, J., Zheng, X., Cheng, Y., Wang, J., Zhang, C., Wang, Z., Yau, S.K.S., Lin, Z., Zhou, L., Ran, C., Xiao, L.,Wu,C.,Schmidhuber,J.,2024. Metagpt:Metaprogrammingfor amulti-agentcollaborativeframework. Int.Conf.Learn.Represent
2024
-
[36]
Huang, K., Zhang, S., Wang, H., Qu, Y., Lu, Y., Roohani, Y., et al.,
-
[37]
Biomni: A general-purpose biomedical ai agent.bioRxiv preprint, 2025
Biomni: A general-purpose biomedical AI agent. bioRxiv doi:10.1101/2025.05.30.656746
-
[38]
Huang, X., Ruan, W., Huang, W., Jin, G., Dong, Y., Wu, C., Ben- salem, S., Mu, R., Qi, Y., Zhao, X., Cai, K., Zhang, Y., Wu, S., Xu, P., Wu, D., Freitas, A., Mustafa, M.A., 2024a. A survey of safety and trustworthiness of large language models through the lens of verification and validation. Artificial Intelligence Review 57, 175. doi:10.1007/s10462-024-10824-0
-
[39]
Trustllm: Trustworthiness in large language models
Huang, Y., Sun, L., Wang, H., Wu, S., Zhang, Q., Li, Y., Gao, C., Huang, Y., Lyu, W., Zhang, Y., et al., 2024b. Trustllm: Trustwor- thiness in large language models. arXiv preprint arXiv:2401.05561
-
[40]
Hunter,J.D.,2007.Matplotlib:A2dgraphicsenvironment.Comput. Sci. Eng. 9, 90–95
2007
-
[41]
Agentmd: Empowering language agents for risk predictionwithlarge-scaleclinicaltoollearning
Jin, Q., Wang, Z., Yang, Y., Zhu, Q., Wright, D., Huang, T., Khan- dekar,N.,Wan,N.,Ai,X.,Wilbur,W.J.,He,Z.,Taylor,R.A.,Chen, Q., Lu, Z., 2025. Agentmd: Empowering language agents for risk predictionwithlarge-scaleclinicaltoollearning. Nat.Commun.16,
2025
-
[42]
doi:10.1038/s41467-025-64430-x
-
[43]
Inference and analysis of cell-cell communication using CellChat
Jin, S., Guerrero-Juarez, C.F., Zhang, L., Chang, I., Ramos, R., Kuan, C.H., Myung, P., Plikus, M.V., Nie, Q., 2021. Inference and analysis of cell-cell communication using CellChat. Nature Communications 12, 1088
2021
-
[44]
Highly accurate protein structure prediction with AlphaFold
Jumper, J., Evans, R., Pritzel, A., Green, T., Figurnov, M., Ron- neberger,O.,Tunyasuvunakool,K.,Bates,R.,Žídek,A.,Potapenko, A., et al., 2021. Highly accurate protein structure prediction with AlphaFold. Nature 596, 583–589
2021
-
[45]
Antibody engineering and its therapeutic applications
Kandari, D., Bhatnagar, R., 2023. Antibody engineering and its therapeutic applications. International Reviews of Immunology 42, 156–183
2023
-
[46]
Nonparametric estimation from incomplete observations
Kaplan, E.L., Meier, P., 1958. Nonparametric estimation from incomplete observations. J. Am. Stat. Assoc. 53, 457–481
1958
-
[47]
The mutational constraint spectrum quantified from variation in 141,456 humans
Karczewski, K.J., Francioli, L.C., Tiao, G., Cummings, B.B., Alföldi, J., Wang, Q., Collins, R.L., et al., 2020. The mutational constraint spectrum quantified from variation in 141,456 humans. Nature 581, 434–443
2020
-
[48]
Graph-based genome alignment and genotyping with HISAT2 and HISAT-genotype
Kim, D., Paggi, J.M., Park, C., Bennett, C., Salzberg, S.L., 2019. Graph-based genome alignment and genotyping with HISAT2 and HISAT-genotype. Nature Biotechnology 37, 907–915
2019
-
[49]
EchoFM: Foundation model for generalizable echocardiogram analysis
Kim, S., Jin, P., Song, S., Chen, C., Li, Y., Ren, H., Li, X., Liu, T., Li, Q., 2025. EchoFM: Foundation model for generalizable echocardiogram analysis. IEEE Transactions on Medical Imaging 44, 4049–4062. doi:10.1109/TMI.2025.3580713
-
[50]
Strelka2: fast and accurate calling of germline and somatic variants
Kim, S., Scheffler, K., Halpern, A.L., Bekritsky, M.A., Noh, E., Källberg, M., Chen, X., et al., 2018. Strelka2: fast and accurate calling of germline and somatic variants. Nature Methods 15, 591– 594
2018
-
[51]
The PHQ- 9: Validity of a brief depression severity measure
Kroenke, K., Spitzer, R.L., Williams, J.B.W., 2001. The PHQ- 9: Validity of a brief depression severity measure. Journal of General Internal Medicine 16, 606–613. doi:10.1046/j.1525-1497. 2001.016009606.x
-
[52]
ClinVar: improving access to variant interpretations and supporting evidence
Landrum, M.J., Lee, J.M., Benson, M., Brown, G.R., Chao, C., Chitipiralla, S., Gu, B., et al., 2018. ClinVar: improving access to variant interpretations and supporting evidence. Nucleic Acids Research 46, D1062–D1067
2018
-
[53]
Langchain.https://github.com/ langchain-ai/langchain
LangChain Team, 2023. Langchain.https://github.com/ langchain-ai/langchain
2023
-
[54]
How can clinicians leverage vibe coding for machine learning and deep learning research? Endocrinol
Lee, Y., Huh, S., 2025. How can clinicians leverage vibe coding for machine learning and deep learning research? Endocrinol. Metab. (Seoul) 40, 659–667. doi:10.3803/EnM.2025.2675
-
[55]
Li, G., Hammoud, H.A.A.K., Itani, H., Khizbullin, D., Ghanem, B.,
-
[56]
Camel:Communicativeagentsfor“mind”explorationoflarge language model society. Adv. Neural Inf. Process. Syst. 36, 51991– 52008
-
[57]
Deeplearningfordrug- drug interaction prediction: A comprehensive review
Li,X.,Xiong,Z.,Zhang,W.,Liu,S.,2024a. Deeplearningfordrug- drug interaction prediction: A comprehensive review. Quantitative Biology 12, 30–52
-
[58]
Li, X., Zhao, L., Zhang, L., Wu, Z., Liu, Z., Jiang, H., Cao, C., Xu, S., Li, Y., Dai, H., Yuan, Y., Liu, J., Li, G., Zhu, D., Yan, P., Li, Q., Liu, W., Liu, T., Shen, D., 2024b. Artificial general intelligence for medicalimaginganalysis.IEEEReviewsinBiomedicalEngineering 17, 337–358. doi:10.1109/RBME.2023.3339966
-
[59]
Deep generative modeling for single-cell transcriptomics
Lopez, R., Regier, J., Cole, M.B., Jordan, M.I., Yosef, N., 2018. Deep generative modeling for single-cell transcriptomics. Nature Methods 15, 1053–1058
2018
-
[60]
Moderated estimation of foldchangeanddispersionforRNA-seqdatawithDESeq2
Love, M.I., Huber, W., Anders, S., 2014. Moderated estimation of foldchangeanddispersionforRNA-seqdatawithDESeq2. Genome Biology 15, 550
2014
-
[61]
Nature Medicine 30(3), 863–874 (2024)
Lu,M.Y.,Chen,B.,Williamson,D.F.K.,Chen,R.J.,Liang,I.,Ding, T.,Jaume,G.,Odintsov,I.,Le,L.P.,Gerber,G.,etal.,2024.Avisual- language foundation model for computational pathology. Nature Medicine 30, 863–874. doi:10.1038/s41591-024-02856-4
-
[62]
Luo, R., Sun, L., Xia, Y., Qin, T., Zhang, S., Poon, H., Liu, T.Y., 2022.Biogpt:Generativepre-trainedtransformerforbiomedicaltext generation and mining. Brief. Bioinform. 23, bbac409
2022
-
[63]
The Ensembl Variant Effect Predictor
McLaren, W., Gil, L., Hunt, S.E., Riat, H.S., Ritchie, G.R.S., Thor- mann, A., Flicek, P., Cunningham, F., 2016. The Ensembl Variant Effect Predictor. Genome Biology 17, 122
2016
-
[64]
Docker: Lightweight linux containers for consis- tent development and deployment
Merkel, D., 2014. Docker: Lightweight linux containers for consis- tent development and deployment. Linux Journal
2014
-
[65]
Vibe coding: a new paradigm for biomedical software development
Moore, J.H., Tatonetti, N., 2025a. Vibe coding: a new paradigm for biomedical software development. BioData Mining 18, 46. doi:10.1186/s13040-025-00462-9
-
[66]
From prompt engineering to agent engineering: expanding the ai toolbox with autonomous agentic ai collaborators for biomedical discovery
Moore, J.H., Tatonetti, N.P., 2025b. From prompt engineering to agent engineering: expanding the ai toolbox with autonomous agentic ai collaborators for biomedical discovery. BioData Mining 18, 78. Z. Wu et al.:Preprint submitted to ElsevierPage 18 of 20 Vibe Medicine
-
[67]
Drug repurposing using FDA adverse event reporting system (FAERS) database
Morris, R., Ali, R., Cheng, F., 2024. Drug repurposing using FDA adverse event reporting system (FAERS) database. Current Drug Targets 25, 454–464
2024
-
[68]
Murad, M.H., Asi, N., Alsawas, M., Alahdab, F., 2016. New evidence pyramid. BMJ Evidence-Based Medicine 21, 125–127. doi:10.1136/ebmed-2016-110401
-
[69]
Artificial intelligence agents in healthcare research: A scoping review
Njei, B., Al-Ajlouni, Y.A., Kanmounye, U.S., Boateng, S., Ngue- fang, G.L., Njei, N., Hamouri, S., Al-Ajlouni, A.F., 2026. Artificial intelligence agents in healthcare research: A scoping review. PLoS One 21, e0342182. doi:10.1371/journal.pone.0342182
-
[70]
Hermes Agent: The self-improving AI agent.https://github.com/NousResearch/hermes-agent
Nous Research, 2026. Hermes Agent: The self-improving AI agent.https://github.com/NousResearch/hermes-agent. MIT Li- cense;closedlearningloopwithGEPA-basedskillevolution;Open- Claw skill migration
2026
-
[71]
Development and evaluation of a clinical note sum- marization system using large language models
Oliveira, J.D., Santos, H.D., Ulbrich, A.H.D., Couto, J.C., Arocha, M., Santos, J., Costa, M.M., Faccio, D., Tabalipa, F.O., Nogueira, R.F., 2025. Development and evaluation of a clinical note sum- marization system using large language models. Communications Medicine 5, 376
2025
-
[72]
Openai function calling and tool use.https:// platform.openai.com/docs/guides/function-calling
OpenAI, 2023. Openai function calling and tool use.https:// platform.openai.com/docs/guides/function-calling
2023
-
[73]
OpenClaw: Personal AI assis- tant.https://github.com/openclaw/openclaw
OpenClaw Community, 2025–2026. OpenClaw: Personal AI assis- tant.https://github.com/openclaw/openclaw
2025
-
[74]
Opentrons python protocol API documentation
Opentrons, 2026. Opentrons python protocol API documentation. https://docs.opentrons.com/python-api/
2026
-
[75]
OWASPtop10forlargelanguagemodel applications2025.https://genai.owasp.org/
OWASPFoundation,2025. OWASPtop10forlargelanguagemodel applications2025.https://genai.owasp.org/. LLM01:2025Prompt Injection
2025
-
[76]
BindCraft: one-shot design of functional protein binders
Pacesa, M., Nickel, L., Schellhaas, C., Schmidt, J., Pyatova, E., Kissling,L.,Barendse,P.,Choudhury,J.,Kapoor,S.,Alcaraz-Serna, A., et al., 2024. BindCraft: one-shot design of functional protein binders. bioRxiv , 2024–09
2024
-
[77]
The PRISMA 2020 statement: An updated guideline for reporting systematic reviews
Page, M.J., McKenzie, J.E., Bossuyt, P.M., Boutron, I., Hoffmann, T.C., Mulrow, C.D., Shamseer, L., Tetzlaff, J.M., Akl, E.A., Bren- nan, S.E., et al., 2021. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ 372, n71. doi:10. 1136/bmj.n71
2021
-
[78]
Nature Methods 19, 171–178
Palla, G., Spitzer, H., Klein, M., Fischer, D., Schaar, A.C., Kuem- merle,L.B.,Rybakov,S.,etal.,2022.Squidpy:ascalableframework for spatial omics analysis. Nature Methods 19, 171–178
2022
-
[79]
Passaro, S., Corso, G., Wohlwend, J., Reveiz, M., Thaler, S., Som- nath,V.R.,Getz,N.,Portnoi,T.,Roy,J.,Stark,H.,etal.,2025.Boltz- 2:Towardsaccurateandefficientbindingaffinityprediction.bioRxiv
2025
-
[80]
Gorilla: Large Language Model Connected with Massive APIs
Patil, S.G., et al., 2023. Gorilla: Large language model connected with massive apis. arXiv preprint arXiv:2305.15334
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.