Recognition: unknown
Reading in the Dark: Low-light Scene Text Recognition
Pith reviewed 2026-05-08 06:43 UTC · model grok-4.3
The pith
Joint training of low-light enhancement and OCR outperforms standalone models for reading text in the dark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Standalone LLIE or OCR models perform inadequately under low-light conditions, while specialized jointly trained text-centric approaches, especially those using a novel re-render LLIE module, deliver improved performance on both synthetic and real low-light scene text images.
What carries the argument
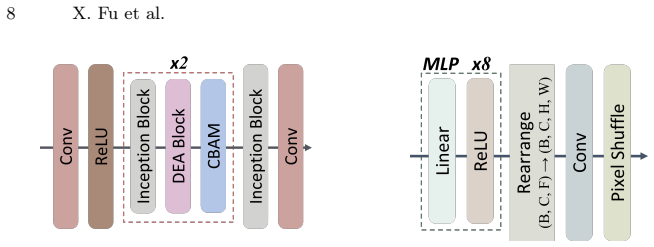
The re-render LLIE (RLLIE) module integrated into a joint training pipeline with an OCR model, which re-renders enhanced images to better preserve text details under low illumination.
Load-bearing premise
Synthetically darkened images from well-lit datasets accurately represent the challenges of real low-light text recognition.
What would settle it
Running the joint RLLIE-OCR model on a much larger set of genuine nighttime street-scene images would show whether the accuracy gains hold beyond the current 60-image real evaluation set.
Figures



read the original abstract
Accurate text recognition in low-light environments is essential for intelligent systems in applications ranging from autonomous vehicles to smart surveillance. However, challenges such as poor illumination and noise interference remain underexplored. To address this gap, we introduce LSTR, a large-scale Low-light Scene Text Recognition dataset comprising 11,273 low-light images generated from well-lit datasets (ICDAR2015, IIIT5K, and WordArt), along with ESTR, which includes 60 real nighttime street-scene images in English and Spanish for exclusive evaluation. We explore two solution strategies: (1) employing Optical Character Recognition (OCR) models with fine-tuning and LoRA-based fine-tuning and (2) a joint training strategy that integrates a low-light image enhancement (LLIE) module with an OCR model. In particular, we propose a novel re-render LLIE (RLLIE) module, which demonstrates improved performance on real-world data. Through extensive experimentation, we analyze various training strategies and address a key research question: \emph{How bright is bright enough for effective scene text recognition?} Our results indicate that standalone LLIE or OCR models perform inadequately under low-light conditions, highlighting the advantages of specialized, jointly trained text-centric approaches. Additionally, we provide a comprehensive benchmark to support future research in robust low-light scene text recognition. https://huggingface.co/datasets/lumimusta/Low-light_Scene_Text_Dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the LSTR dataset (11,273 synthetically darkened images derived from ICDAR2015, IIIT5K, and WordArt) and the ESTR real-world evaluation set (60 nighttime street-scene images). It proposes a re-render LLIE (RLLIE) module for joint low-light enhancement and OCR training, compares standalone LLIE/OCR fine-tuning against joint strategies, and explores the brightness threshold needed for effective scene text recognition. The central claim is that standalone models are inadequate while jointly trained text-centric approaches, including the proposed RLLIE, yield superior performance, supported by a new benchmark.
Significance. If substantiated, the work fills a practical gap in low-light scene text recognition relevant to surveillance and autonomous systems. The new datasets and text-centric RLLIE module could provide a useful starting point and benchmark for the community, particularly if the joint-training advantages prove robust beyond the current evaluation.
major comments (2)
- [Section 5 (Experiments) and Section 3.2 (ESTR dataset)] The decisive evidence for real-world superiority of joint training (including RLLIE) rests on the ESTR set of only 60 images (Section 3.2 and evaluation in Section 5). With no reported confidence intervals, multiple random splits, or diversity analysis of the 60 scenes, observed performance gaps cannot be distinguished from sampling variance or narrow scene distribution; this directly undermines the claim that joint approaches are reliably superior under real low-light conditions.
- [Section 3.1 (LSTR dataset construction)] The synthetic darkening procedure used to create the 11,273-image LSTR training set (Section 3.1) is not shown to reproduce the noise, color-cast, and non-uniform illumination statistics of the real ESTR images; without a quantitative domain-gap analysis (e.g., histogram or perceptual metrics between synthetic and real low-light patches), it is unclear whether the reported joint-training gains will generalize.
minor comments (3)
- [Abstract] The abstract states performance advantages but supplies no numerical metrics, error bars, or ablation summaries; adding at least the key accuracy deltas on ESTR would improve readability.
- [Section 4 (Proposed Method)] Notation for the RLLIE module (e.g., the re-rendering loss and its integration with the OCR backbone) is introduced without an explicit equation or diagram in the method section; a compact formulation would clarify the novelty.
- [Section 5 (Experiments)] Table captions and axis labels in the experimental figures should explicitly state the metric (e.g., word accuracy, character accuracy) and whether results are on synthetic or real data.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that highlight important aspects of evaluation robustness and dataset construction. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Section 5 (Experiments) and Section 3.2 (ESTR dataset)] The decisive evidence for real-world superiority of joint training (including RLLIE) rests on the ESTR set of only 60 images (Section 3.2 and evaluation in Section 5). With no reported confidence intervals, multiple random splits, or diversity analysis of the 60 scenes, observed performance gaps cannot be distinguished from sampling variance or narrow scene distribution; this directly undermines the claim that joint approaches are reliably superior under real low-light conditions.
Authors: We acknowledge that the ESTR set of 60 real-world images is small and that the absence of confidence intervals or diversity statistics limits the strength of statistical claims. Collecting accurately annotated real nighttime scene text images at scale is challenging, which is why ESTR was introduced as an initial evaluation benchmark rather than a comprehensive test set. The observed gains from joint training (including RLLIE) are consistent across multiple OCR architectures and LLIE baselines, reducing the likelihood that they arise solely from sampling variance. In the revised manuscript we will add a diversity analysis of the 60 scenes (e.g., distributions of text length, average scene brightness, and illumination uniformity) and report bootstrap confidence intervals on the primary metrics to better quantify uncertainty. revision: partial
-
Referee: [Section 3.1 (LSTR dataset construction)] The synthetic darkening procedure used to create the 11,273-image LSTR training set (Section 3.1) is not shown to reproduce the noise, color-cast, and non-uniform illumination statistics of the real ESTR images; without a quantitative domain-gap analysis (e.g., histogram or perceptual metrics between synthetic and real low-light patches), it is unclear whether the reported joint-training gains will generalize.
Authors: LSTR is generated by applying a controlled synthetic darkening process to existing well-annotated scene-text datasets, enabling large-scale training with precise text labels. While this procedure does not perfectly replicate every real-world artifact (sensor noise, specific color casts), the joint-training objective optimizes the enhancement module directly for OCR accuracy rather than generic perceptual quality, which helps the model adapt to domain differences. The fact that models trained on LSTR improve on the unseen real ESTR set provides empirical support for useful generalization. In the revision we will add a quantitative domain-gap analysis, including comparisons of mean brightness, contrast, noise variance, and histogram similarity between synthetic LSTR patches and real ESTR patches. revision: yes
Circularity Check
No circularity: purely empirical evaluation on new datasets
full rationale
The paper introduces new datasets (LSTR with 11,273 synthetic low-light images for training; ESTR with 60 real images for evaluation) and compares training strategies for LLIE+OCR models. No mathematical derivation chain, equations, or self-referential definitions exist that reduce any claimed result to its own inputs by construction. Claims rest on experimental performance metrics rather than fitted parameters renamed as predictions or self-citation load-bearing premises. This is the standard case of an empirical ML paper that remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions in deep neural network training such as optimizer convergence and generalization from synthetic to real data
invented entities (1)
-
RLLIE module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on Image Processing33, 1002–1015 (2024)
Chen, Z., He, Z., Lu, Z.M.: Dea-net: Single image dehazing based on detail- enhanced convolution and content-guided attention. IEEE Transactions on Image Processing33, 1002–1015 (2024)
2024
-
[2]
IEEE Transactions on Image Processing29, 4885–4897 (2020)
ElHelou,M.,Süsstrunk,S.:Blinduniversalbayesianimagedenoisingwithgaussian noise level learning. IEEE Transactions on Image Processing29, 4885–4897 (2020). https://doi.org/10.1109/TIP.2020.2976814
-
[3]
In: CVPR
Fei, B., Lyu, Z., Pan, L., Zhang, J., Yang, W., Luo, T., Zhang, B., Dai, B.: Gen- erative diffusion prior for unified image restoration and enhancement. In: CVPR. pp. 9935–9946 (2023)
2023
-
[4]
In: CVPR
Guo, C., Li, C., Guo, J., Loy, C.C., Hou, J., Kwong, S., Cong, R.: Zero-reference deep curve estimation for low-light image enhancement. In: CVPR. pp. 1780–1789 (2020)
2020
-
[5]
Journal of Visual Communication and Image Representation90, 103712 (2023)
Hai, J., Xuan, Z., Yang, R., Hao, Y., Zou, F., Lin, F., Han, S.: R2rnet: Low- light image enhancement via real-low to real-normal network. Journal of Visual Communication and Image Representation90, 103712 (2023)
2023
-
[6]
In: ICPR
Hsu, P.H., Lin, C.T., Ng, C.C., Kew, J.L., Tan, M.Y., Lai, S.H., Chan, C.S., Zach, C.: Extremely low-light image enhancement with scene text restoration. In: ICPR. pp. 317–323. IEEE (2022)
2022
-
[7]
IEEE transactions on image processing30, 2340–2349 (2021) Reading in the Dark: Low-light Scene Text Recognition 15
Jiang, Y., Gong, X., Liu, D., Cheng, Y., Fang, C., Shen, X., Yang, J., Zhou, P., Wang, Z.: Enlightengan: Deep light enhancement without paired supervision. IEEE transactions on image processing30, 2340–2349 (2021) Reading in the Dark: Low-light Scene Text Recognition 15
2021
-
[8]
Properties and performance of a center/surround retinex
Jobson, D., Rahman, Z., Woodell, G.: Properties and performance of a cen- ter/surround retinex. IEEE Transactions on Image Processing6(3), 451–462 (1997).https://doi.org/10.1109/83.557356
-
[9]
IEEE transactions on pattern analysis and machine intelli- gence44(8), 4225–4238 (2021)
Li, C., Guo, C., Loy, C.C.: Learning to enhance low-light image via zero-reference deep curve estimation. IEEE transactions on pattern analysis and machine intelli- gence44(8), 4225–4238 (2021)
2021
-
[10]
Signal Processing: Image Communication130, 117222 (2025)
Lin, C.T., Ng, C.C., Tan, Z.Q., Nah, W.J., Wang, X., Kew, J.L., Hsu, P., Lai, S.H., Chan, C.S., Zach, C.: Text in the dark: Extremely low-light text image enhance- ment. Signal Processing: Image Communication130, 117222 (2025)
2025
-
[11]
The Visual Computer38(9), 3231–3242 (2022)
Liu, H., Yuan, M., Wang, T., Ren, P., Yan, D.M.: List: low illumination scene text detector with automatic feature enhancement. The Visual Computer38(9), 3231–3242 (2022)
2022
-
[12]
In: CVPR
Liu, R., Ma, L., Zhang, J., Fan, X., Luo, Z.: Retinex-inspired unrolling with coop- erative prior architecture search for low-light image enhancement. In: CVPR. pp. 10561–10570 (2021)
2021
-
[13]
In: CVPR
Ma, L., Ma, T., Liu, R., Fan, X., Luo, Z.: Toward fast, flexible, and robust low-light image enhancement. In: CVPR. pp. 5637–5646 (2022)
2022
-
[14]
In: BMVC
Mishra, A., Alahari, K., Jawahar, C.: Scene text recognition using higher order language priors. In: BMVC. BMVA (2012)
2012
-
[15]
In: WACV
Nguyen, C.M., Chan, E.R., Bergman, A.W., Wetzstein, G.: Diffusion in the dark: A diffusion model for low-light text recognition. In: WACV. pp. 4146–4157 (2024)
2024
-
[16]
In: 2015 13th ICDAR
Peyrard, C., Baccouche, M., Mamalet, F., Garcia, C.: Icdar2015 competition on text image super-resolution. In: 2015 13th ICDAR. pp. 1201–1205. IEEE (2015)
2015
-
[17]
In: CVPR
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A.: Going deeper with convolutions. In: CVPR. pp. 1– 9 (2015)
2015
-
[18]
Deep retinex decomposition for low-light enhancement
Wei, C., Wang, W., Yang, W., Liu, J.: Deep retinex decomposition for low-light enhancement. arXiv preprint arXiv:1808.04560 (2018)
- [19]
-
[20]
In: ECCV
Woo, S., Park, J., Lee, J.Y., Kweon, I.S.: Cbam: Convolutional block attention module. In: ECCV. pp. 3–19 (2018)
2018
-
[21]
In: ECCV
Xie, X., Fu, L., Zhang, Z., Wang, Z., Bai, X.: Toward understanding wordart: Corner-guided transformer for scene text recognition. In: ECCV. pp. 303–321. Springer (2022)
2022
-
[22]
In: Proceedings of the 32nd ACM MM
Xu, C., Fu, H., Ma, L., Jia, W., Zhang, C., Xia, F., Ai, X., Li, B., Zhang, W.: Seeing text in the dark: Algorithm and benchmark. In: Proceedings of the 32nd ACM MM. pp. 2870–2878 (2024)
2024
-
[23]
IEEE Transactions on Multimedia23, 2706–2720 (2020)
Xue, M., Shivakumara, P., Zhang, C., Xiao, Y., Lu, T., Pal, U., Lopresti, D., Yang, Z.: Arbitrarily-oriented text detection in low light natural scene images. IEEE Transactions on Multimedia23, 2706–2720 (2020)
2020
-
[24]
In: ACM MM
Zhang, Y., Zhang, J., Guo, X.: Kindling the darkness: A practical low-light image enhancer. In: ACM MM. pp. 1632–1640 (2019)
2019
-
[25]
In: ICCV
Zhu, J.Y., Park, T., Isola, P., Efros, A.A.: Unpaired image-to-image translation using cycle-consistent adversarial networks. In: ICCV. pp. 2223–2232 (2017)
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.