Recognition: unknown
Intention-Aware Semantic Agent Communications for AI Glasses
Pith reviewed 2026-05-08 05:29 UTC · model grok-4.3
The pith
AI glasses use intention inference to cut bandwidth by over 50% while preserving task performance
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
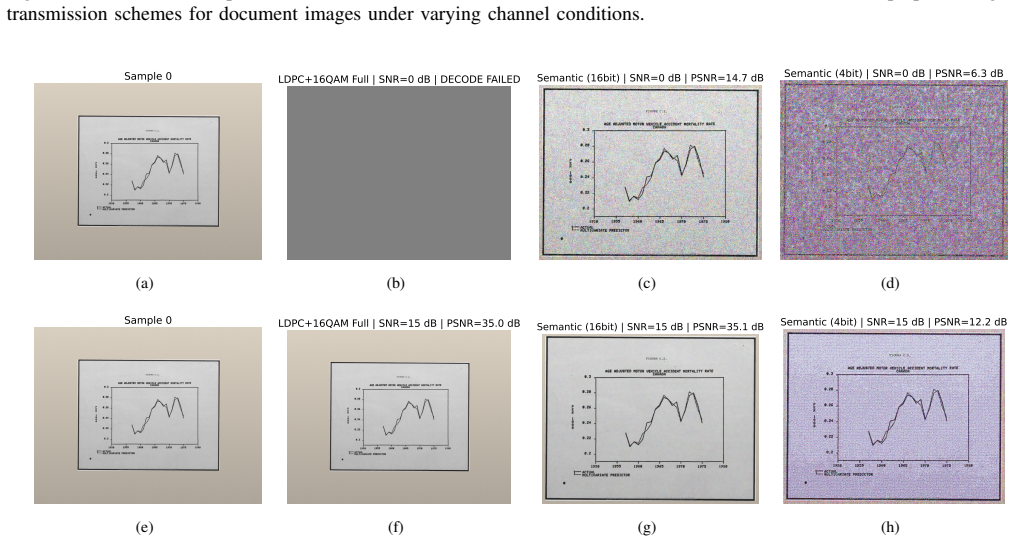
The central claim is that an intention-aware semantic agent communication framework lets AI glasses preprocess and transmit visual data selectively according to server-inferred user intentions. The server-side VLM deduces intent from the partially transmitted content plus historical prompts, prompting the glasses to preserve only the relevant semantics (text, layout, or objects) via lightweight local tools. Across three representative scenarios this approach delivers more than 50% bandwidth reduction while task performance stays intact, and the semantic stream degrades gracefully rather than failing under low signal-to-noise ratios.
What carries the argument
Intention inference plus adaptive semantic preservation, in which the server VLM identifies the needed elements from context and the glasses apply lightweight filters to retain only those elements before transmission.
If this is right
- Task-specific bandwidth consumption falls by more than half depending on the application.
- Downstream VLM performance holds steady even though far fewer pixels are sent.
- Transmission quality declines gradually with worsening channel conditions instead of collapsing.
- The same principle supports continuous real-time assistance on power- and spectrum-limited wearables.
Where Pith is reading between the lines
- The approach could extend to audio or depth sensors by inferring intent across multiple modalities.
- Sending less raw visual data may reduce privacy exposure of complete scenes.
- Pairing the method with lightweight on-device intention models could lower cloud dependency further.
Load-bearing premise
The server VLM can accurately infer the user's current intention from the partially transmitted content and past prompts, and that keeping only selected semantic elements is sufficient to maintain downstream task accuracy.
What would settle it
An experiment in which the inferred intention repeatedly causes the wrong semantic elements to be preserved, resulting in clear drops in VLM task accuracy relative to full-image baselines, would falsify the central claim.
Figures







read the original abstract
Smart glasses are emerging as a promising interface between humans and artificial intelligence (AI) agents, enabling first-person perception, contextual awareness, and real-time assistance. However, continuous offloading of visual data from wearable devices to cloud-based vision-language models (VLMs) is fundamentally constrained by limited wireless bandwidth and energy resources. This paper proposes an intention-aware semantic agent communication framework for AI glasses, where data transmission is guided by user intention rather than raw pixel fidelity. In the proposed architecture, AI glasses act as an edge semantic agent while a server-side VLM executes high-level cognition and reasoning. The user intention can be inferred by the server-side VLM through the current transmitted content and the historical prompts. Driven by specific user intentions, the glasses adaptively preserve textual content, document layout, or object semantics before transmission. We evaluate three representative scenarios with different lightweight preprocessing tools on the AI glasses. Simulation results demonstrate that intention-aware preprocessing significantly achieves more than 50% bandwidth reduction depending on the current task while maintaining task performance. Moreover, semantic transmission exhibits graceful degradation under low SNRs. The findings demonstrate that aligning communication resources with user intention is essential for robust and efficient wearable AI agent systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an intention-aware semantic communication framework for AI glasses, where glasses act as edge agents performing adaptive preprocessing (preserving text, layout, or object semantics) based on user intentions inferred by a server-side VLM from the transmitted content plus historical prompts. Simulations in three scenarios demonstrate >50% bandwidth reduction while preserving task performance, plus graceful degradation under low SNR.
Significance. If the central claims hold after addressing protocol details, the work offers a practical step toward bandwidth-efficient wearable AI agents by aligning transmission with inferred intent rather than pixel-level fidelity. The multi-scenario simulation evaluation provides initial evidence of task-dependent savings, which could inform semantic comms designs for resource-limited devices.
major comments (2)
- [Architecture/Protocol] Architecture description (likely §2-3): The server infers intention from the already-adapted transmitted content, yet the glasses require intention knowledge to perform the adaptation step beforehand. No bootstrap procedure, separate low-rate intention signaling channel, or iterative exchange protocol is described, creating an unresolved ordering inconsistency that is load-bearing for the framework's feasibility.
- [Evaluation/Simulations] Evaluation section (likely §4): The >50% bandwidth reduction claim and graceful degradation result rest on simulations whose setup is insufficiently detailed (no explicit baselines, preprocessing tool parameters, trial counts, error bars, or intention-inference accuracy metrics). Performance under imperfect or erroneous intention inference is not reported, weakening the robustness assertion.
minor comments (2)
- [Abstract] Abstract: The three scenarios and lightweight preprocessing tools are referenced but not named or characterized, reducing clarity for readers.
- [Throughout] Notation and figures: Ensure consistent use of terms such as 'semantic agent' and 'intention-aware preprocessing' across text and diagrams; add axis labels or legends if any simulation plots lack them.
Simulated Author's Rebuttal
We appreciate the referee's insightful comments on our manuscript. We have carefully considered the points raised and provide point-by-point responses below. We agree that additional clarifications and details are needed and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Architecture/Protocol] Architecture description (likely §2-3): The server infers intention from the already-adapted transmitted content, yet the glasses require intention knowledge to perform the adaptation step beforehand. No bootstrap procedure, separate low-rate intention signaling channel, or iterative exchange protocol is described, creating an unresolved ordering inconsistency that is load-bearing for the framework's feasibility.
Authors: We thank the referee for highlighting this important architectural detail. Upon re-examination, we acknowledge that the current description in Sections 2-3 does not explicitly address the initialization of the intention inference process. The framework relies on historical prompts for initial intention estimation, with the current transmitted content used for refinement. However, to resolve the potential ordering issue, we will revise the manuscript to include a detailed bootstrap procedure: the glasses initially transmit a low-resolution or default-preprocessed version of the content (e.g., using a fixed semantic preservation mode based on the last known intention from history), allowing the server to infer the initial intention. This intention is then used for subsequent adaptive preprocessing in an iterative manner if needed. We will also add a figure or pseudocode to illustrate the protocol flow. This revision will be made in the next version. revision: yes
-
Referee: [Evaluation/Simulations] Evaluation section (likely §4): The >50% bandwidth reduction claim and graceful degradation result rest on simulations whose setup is insufficiently detailed (no explicit baselines, preprocessing tool parameters, trial counts, error bars, or intention-inference accuracy metrics). Performance under imperfect or erroneous intention inference is not reported, weakening the robustness assertion.
Authors: We agree with the referee that the simulation setup in Section 4 requires more detailed description to ensure reproducibility and to strengthen the claims. In the revised manuscript, we will expand the evaluation section to include: explicit description of the baselines used (e.g., standard semantic communication without intention awareness, raw transmission, etc.), specific parameters for the preprocessing tools (such as OCR thresholds, object detection models, compression ratios), number of trials conducted, error bars on the reported bandwidth reduction and performance metrics, and metrics for intention-inference accuracy (e.g., precision/recall of the VLM's intention prediction). Additionally, we will include new simulation results showing performance under imperfect intention inference, such as cases with 10-20% inference error rates, to demonstrate robustness. These additions will support the >50% bandwidth reduction and graceful degradation claims more rigorously. revision: yes
Circularity Check
No significant circularity; framework is a simulation-evaluated proposal without self-referential derivations
full rationale
The paper describes an architectural proposal for intention-aware semantic communications in AI glasses, with claims supported by simulation results on bandwidth reduction and graceful degradation. No mathematical derivation chain, equations, or fitted parameters are presented that reduce by construction to the inputs. The intention inference mechanism is stated as using transmitted content plus historical prompts, but this does not create a self-definitional loop or fitted-input prediction; the work remains an engineering framework evaluated externally via simulation rather than internally forced. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way from the provided text. The derivation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption User intention can be reliably inferred by the server VLM from the current transmitted content and historical prompts
- domain assumption Lightweight preprocessing on the edge can selectively preserve task-relevant semantics without degrading downstream VLM performance
Reference graph
Works this paper leans on
-
[1]
Meta smart glasses—large language models and the future for assistive glasses for individuals with vision impairments,
E. Waisberg, J. Ong, M. Masalkhi, N. Zaman, P. Sarker, A. G. Lee, and A. Tavakkoli, “Meta smart glasses—large language models and the future for assistive glasses for individuals with vision impairments,”Eye, vol. 38, no. 6, pp. 1036–1038, 2024
2024
-
[2]
A systematic literature review on integrating ai-powered smart glasses into digital health management for proactive healthcare solutions,
B. Wang, Y . Zheng, X. Han, L. Kong, G. Xiao, Z. Xiao, and S. Chen, “A systematic literature review on integrating ai-powered smart glasses into digital health management for proactive healthcare solutions,”NPJ digital medicine, vol. 8, no. 1, p. 410, 2025
2025
-
[3]
Applying smart glasses in situated exploration for learning english in a national science museum,
H.-R. Chen, W.-S. Lin, T.-Y . Hsu, T.-C. Lin, and N.-S. Chen, “Applying smart glasses in situated exploration for learning english in a national science museum,”IEEE Trans. Learn. Techn., vol. 16, no. 5, pp. 820– 830, 2023
2023
-
[4]
Enabling mobile AI agent in 6g era: Architecture and key technologies,
Z. Chen, Q. Sun, N. Li, X. Li, Y . Wanget al., “Enabling mobile AI agent in 6g era: Architecture and key technologies,”IEEE Network, vol. 38, no. 5, pp. 66–75, 2024
2024
-
[5]
AI embodiment through 6g: Shaping the future of agi,
L. Bariah and M. Debbah, “AI embodiment through 6g: Shaping the future of agi,”IEEE Wireless Commun., vol. 31, no. 5, pp. 174–181, Oct. 2024
2024
-
[6]
Unleashing the power of edge-cloud generative AI in mobile networks: A survey of aigc services,
M. Xu, H. Du, D. Niyato, J. Kang, Z. Xiong, S. Mao, Z. Han, A. Jamalipour, D. I. Kim, X. Shenet al., “Unleashing the power of edge-cloud generative AI in mobile networks: A survey of aigc services,” IEEE Commun. Surv. Tutor ., vol. 26, no. 2, pp. 1127–1170, Jan. 2024
2024
-
[7]
Large language models empowered autonomous edge AI for connected intelligence,
Y . Shen, J. Shao, X. Zhang, Z. Lin, H. Pan, D. Li, J. Zhang, and K. B. Letaief, “Large language models empowered autonomous edge AI for connected intelligence,”arXiv preprint arXiv:2307.02779, 2023
-
[8]
Towards a theory of semantic communication,
J. Bao, P. Basu, M. Dean, C. Partridge, A. Swami, W. Leland, and J. A. Hendler, “Towards a theory of semantic communication,” inIEEE Netw. Sci. Workshop, 2011, pp. 110–117
2011
-
[9]
Beyond transmitting bits: Context, seman- tics, and task-oriented communications,
D. Gündüz, Z. Qin, I. E. Aguerri, H. S. Dhillon, Z. Yang, A. Yener, K. K. Wong, and C.-B. Chae, “Beyond transmitting bits: Context, seman- tics, and task-oriented communications,”IEEE J. Sel. Areas Commun., vol. 41, no. 1, pp. 5–41, Jan. 2023
2023
-
[10]
Semantic communications: Principles and challenges,
Z. Qin, X. Tao, J. Lu, W. Tong, and G. Y . Li, “Semantic communications: Principles and challenges,”arXiv preprint arXiv:2201.01389, 2021
-
[11]
From semantic communication to semantic-aware networking: Model, architecture, and open problems,
G. Shi, Y . Xiao, Y . Li, and X. Xie, “From semantic communication to semantic-aware networking: Model, architecture, and open problems,” IEEE Commun. Mag., vol. 59, no. 8, pp. 44–50, Aug. 2021
2021
-
[12]
Semantic communications for future internet: Fundamentals, applications, and challenges,
W. Yang, H. Du, Z. Q. Liew, W. Y . B. Lim, Z. Xiong, D. Niyato, X. Chi, X. Shen, and C. Miao, “Semantic communications for future internet: Fundamentals, applications, and challenges,”IEEE Commun. Surv. Tutorials, vol. 25, no. 1, pp. 213–250, 2022
2022
-
[13]
Deep learning enabled semantic communication systems,
H. Xie, Z. Qin, G. Y . Li, and B.-H. Juang, “Deep learning enabled semantic communication systems,”IEEE Trans. Signal Process., vol. 69, pp. 2663–2675, Apr. 2021
2021
-
[14]
Wireless deep video semantic transmission,
S. Wang, J. Dai, Z. Liang, K. Niu, Z. Si, C. Dong, X. Qin, and P. Zhang, “Wireless deep video semantic transmission,”IEEE J. Sel. Areas Commun., vol. 41, no. 1, pp. 214–229, Jan, 2022
2022
-
[15]
Task-oriented explainable semantic communications,
S. Ma, W. Qiao, Y . Wu, H. Li, G. Shi, D. Gao, Y . Shi, S. Li, and N. Al-Dhahir, “Task-oriented explainable semantic communications,” IEEE Trans. Wireless commun., vol. 22, no. 12, pp. 9248–9262, 2023
2023
-
[16]
Intellicise wireless networks from semantic communications: A survey, research issues, and challenges,
P. Zhang, W. Xu, Y . Liu, X. Qin, K. Niu, S. Cui, G. Shi, Z. Qin, X. Xu, F. Wanget al., “Intellicise wireless networks from semantic communications: A survey, research issues, and challenges,”IEEE Commun. Surv. Tutorials, 2024
2024
-
[17]
Large AI model-based semantic communications,
F. Jiang, Y . Peng, L. Dong, K. Wang, K. Yang, C. Pan, and X. You, “Large AI model-based semantic communications,”IEEE Wireless Com- mun., vol. 31, no. 3, pp. 68–75, June 2024
2024
-
[18]
Semantic satellite communications based on generative foundation model,
P. Jiang, C.-K. Wen, X. Li, S. Jin, and G. Y . Li, “Semantic satellite communications based on generative foundation model,”IEEE J. Sel. Areas Commun., vol. 43, no. 7, pp. 2431–2445, Jul. 2025
2025
-
[19]
End-to-end gener- ative semantic communication powered by shared semantic knowledge base,
S. Li, Y . Sun, J. Zhang, K. Cai, S. Cui, and X. Xu, “End-to-end gener- ative semantic communication powered by shared semantic knowledge base,”arXiv preprint arXiv:2405.05738, 2024
-
[20]
Generative semantic communication: Diffusion models beyond bit recovery,
E. Grassucci, S. Barbarossa, and D. Comminiello, “Generative semantic communication: Diffusion models beyond bit recovery,”arXiv preprint arXiv:2306.04321, 2023
-
[21]
Semantic-aware power allocation for generative semantic communications with foundation models,
C. Xu, M. B. Mashhadi, Y . Ma, and R. Tafazolli, “Semantic-aware power allocation for generative semantic communications with foundation models,”arXiv preprint arXiv:2407.03050, 2024
-
[22]
WirelessLLM: Empowering large language models towards wireless intelligence,
J. Shao, J. Tong, Q. Wu, W. Guo, Z. Li, Z. Lin, and J. Zhang, “WirelessLLM: Empowering large language models towards wireless intelligence,”Journal of Commun. Info. Netw., vol. 9, no. 2, pp. 99– 112, June 2024
2024
-
[23]
Position-aided semantic communication for efficient image transmission: Design, implementa- tion, and experimental results,
P. Jiang, C.-K. Wen, S. Jin, and J. Zhang, “Position-aided semantic communication for efficient image transmission: Design, implementa- tion, and experimental results,”IEEE Trans. Wireless Commun., vol. 25, pp. 4887–4902, 2026
2026
-
[24]
From LLM Reasoning to Autonomous AI Agents: A Comprehensive Review
M. A. Ferrag, N. Tihanyi, and M. Debbah, “From LLM reasoning to autonomous AI agents: A comprehensive review,”arXiv preprint arXiv:2504.19678, 2025
work page internal anchor Pith review arXiv 2025
-
[25]
Deep source-channel coding for sentence semantic transmission with HARQ,
P. Jiang, C.-K. Wen, S. Jin, and G. Y . Li, “Deep source-channel coding for sentence semantic transmission with HARQ,”IEEE Trans. Commun., vol. 70, no. 8, pp. 5225–5240, Aug. 2022
2022
-
[26]
H. Zou, Q. Zhao, L. Bariah, M. Bennis, and M. Debbah, “Wireless multi-agent generative AI: From connected intelligence to collective intelligence,”arXiv preprint arXiv:2307.02757, 2023
-
[27]
Agentic AI: The era of semantic decoding,
M. Peyrard, M. Josifoski, and R. West, “Agentic AI: The era of semantic decoding,”arXiv preprint arXiv:2403.14562, 2024
-
[28]
Semantic- driven AI agent communications: Challenges and solutions,
K. Yu, M. Sun, Z. Qin, X. Xu, P. Yang, Y . Xiao, and G. Wu, “Semantic- driven AI agent communications: Challenges and solutions,”arXiv preprint arXiv:2510.00381, 2025
-
[29]
Semantic information extraction and multi-agent communica- tion optimization based on generative pre-trained transformer,
L. Zhou, X. Deng, Z. Wang, X. Zhang, Y . Dong, X. Hu, Z. Ning, and J. Wei, “Semantic information extraction and multi-agent communica- tion optimization based on generative pre-trained transformer,”IEEE Trans. Cogn. Commun. Netw., vol. 11, no. 2, pp. 725–737, 2024
2024
-
[30]
Goal-oriented multi-agent semantic networking: Unifying intents, semantics, and intelligence,
S. Chen, Q. Liao, A. Aijaz, and Y . Deng, “Goal-oriented multi-agent semantic networking: Unifying intents, semantics, and intelligence,” arXiv preprint arXiv:2512.01035, 2025
-
[31]
Toward goal-oriented communication in multi-agent systems: An overview,
T. Charalambous, N. Pappas, N. Nomikos, and R. Wichman, “Toward goal-oriented communication in multi-agent systems: An overview,” arXiv preprint arXiv:2508.07720, 2025
-
[32]
Less data, more knowledge: Building next-generation semantic communication networks,
C. Chaccour, W. Saad, M. Debbah, Z. Han, and H. V . Poor, “Less data, more knowledge: Building next-generation semantic communication networks,”IEEE Commun. Surv. Tutor ., vol. 26, no. 1, pp. 1–36, First Quart. 2024
2024
-
[33]
The information bottleneck method,
N. Tishby, F. C. Pereira, and W. Bialek, “The information bottleneck method,”Proc. 37th Annu. Allerton Conf. Commun., Control, Comput., pp. 368–377, Sep. 1999
1999
-
[34]
The perception-distortion tradeoff,
Y . Blau and T. Michaeli, “The perception-distortion tradeoff,” inProc. IEEE Conf. Comput. Vision Patt. Recogn. (CVPR), 2018, pp. 6228–6237
2018
-
[35]
Deep joint source–channel coding for wireless image transmission,
E. Bourtsoulatze, D. Kurka, and D. Gündüz, “Deep joint source–channel coding for wireless image transmission,”IEEE Trans. Cogn. Commun. Netw., vol. 5, no. 3, pp. 567–579, Sep. 2019
2019
-
[36]
Vision transformer for adaptive image transmission over MIMO channels,
H. Wu, Y . Shao, C. Bian, K. Mikolajczyk, and D. Gündüz, “Vision transformer for adaptive image transmission over MIMO channels,”
-
[37]
Available: http://arxiv.org/abs/2210.15347
[Online]. Available: http://arxiv.org/abs/2210.15347
-
[38]
Real-time semantic communications with a vision transformer,
H. Yoo, T. Jung, L. Dai, S. Kim, and C.-B. Chae, “Real-time semantic communications with a vision transformer,” in2022 IEEE Int. Conf. Commun. Workshops (ICC Workshops). IEEE, 2022, pp. 1–2
2022
-
[39]
Reinforcement learning-powered semantic communication via semantic similarity,
K. Lu, R. Li, X. Chen, Z. Zhao, and H. Zhang, “Reinforcement learning-powered semantic communication via semantic similarity,” arXiv preprint arXiv:2108.12121, 2021
-
[40]
Adaptive resource allocation for semantic communication networks,
L. Wang, W. Wu, F. Zhou, Z. Yang, Z. Qin, and Q. Wu, “Adaptive resource allocation for semantic communication networks,”IEEE Trans- actions on Communications, vol. 72, no. 11, pp. 6900–6916, 2024
2024
-
[41]
Goal-oriented semantic communication for wireless video transmission via generative AI,
N. Li, Y . Deng, and D. Niyato, “Goal-oriented semantic communication for wireless video transmission via generative AI,”IEEE Trans. Wireless Commun., vol. 25, pp. 10 841–10 854, Jan. 2026
2026
-
[42]
From large AI models to agentic AI: A tutorial on future intelligent communications,
F. Jiang, C. Pan, K. Wang, P. Michiardi, O. A. Dobre, and M. Debbah, “From large AI models to agentic AI: A tutorial on future intelligent communications,”IEEE J. Sel. Areas Commun., vol. 44, pp. 3507–3540, Feb. 2026
2026
-
[43]
Large AI models for wireless physical layer,
J. Guo, Y . Cui, S. Jin, and J. Zhang, “Large AI models for wireless physical layer,”IEEE Communications Magazine, 2026, Early access
2026
-
[44]
Wireless agentic AI with retrieval-augmented multi- modal semantic perception,
G. Liu, Y . Liu, R. Zhang, H. Du, D. Niyato, Z. Xiong, S. Sun, and A. Jamalipour, “Wireless agentic AI with retrieval-augmented multi- modal semantic perception,”IEEE Communications Magazine, vol. 64, no. 1, pp. 230–236, Jan. 2026
2026
-
[45]
R. Zhang, S. Tang, Y . Liu, D. Niyato, Z. Xiong, S. Sun, S. Mao, and Z. Han, “Toward agentic AI: Generative information retrieval inspired intelligent communications and networking,”arXiv preprint arXiv:2502.16866, 2025
-
[46]
Generative AI-driven semantic communication framework for nextg wireless network,
A. D. Raha, M. S. Munir, A. Adhikary, M. Gain, Y . Qiao, and C. S. Hong, “Generative AI-driven semantic communication framework for nextg wireless network,”IEEE Trans. V ehi. Techn., pp. 1–6, 2026, Early access
2026
-
[47]
LLM-based semantic communication: The way from task-originated to general,
M. Chen, Z. Sun, X. He, L. Wang, and A. Al-Dulaimi, “LLM-based semantic communication: The way from task-originated to general,” IEEE Wireless Commun. Lett., vol. 14, no. 10, pp. 3029–3033, Oct. 2025
2025
-
[48]
Large AI model-based semantic communications,
F. Jiang, Y . Peng, L. Dong, K. Wang, K. Yang, C. Pan, and X. You, “Large AI model-based semantic communications,”IEEE Wireless Com- mun., vol. 31, no. 3, pp. 68–75, Jun. 2024
2024
-
[49]
Large AI model empowered multimodal semantic communications,
F. Jiang, L. Dong, Y . Peng, K. Wang, K. Yang, C. Pan, and X. You, “Large AI model empowered multimodal semantic communications,” IEEE Commun. Mag., vol. 63, no. 1, pp. 76–82, Jan. 2025
2025
-
[50]
Large language model enhanced multi-agent systems for 6g communications,
F. Jiang, Y . Peng, L. Dong, K. Wang, K. Yang, C. Pan, D. Niyato, and O. A. Dobre, “Large language model enhanced multi-agent systems for 6g communications,”IEEE Wireless Commun., vol. 31, no. 6, pp. 48–55, Dec. 2024
2024
-
[51]
Camel: Communicative agents for mind exploration of large language model society,
G. Li, R. Wang, Y . Chen, and X. Zhang, “Camel: Communicative agents for mind exploration of large language model society,” inAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[52]
Agentverse: Facilitating multi- agent collaboration and exploring emergent behaviors,
W. Chen, Y . Zhao, H. Liu, and et al., “Agentverse: Facilitating multi- agent collaboration and exploring emergent behaviors,” inIn The 12th Int. Conf. Learning Represent. (ICLR), 2024
2024
-
[53]
A dynamic LLM-powered agent net- work for task-oriented agent collaboration,
Z. Liu, Y . Zhang, and X. Chen, “A dynamic LLM-powered agent net- work for task-oriented agent collaboration,” inProc. 1st Conf. Language Model. (COLM), 2024
2024
-
[54]
AgentComm: Semantic Communication for Embodied Agents
P. Jiang, Y . Feng, J. Guo, C.-K. Wen, and S. Jin, “Agentcomm: Semantic communication for embodied agents,”arXiv preprint arXiv:2604.13558, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[55]
Generative AI agents with large language model for satellite networks via a mixture of experts transmission,
R. Zhang, H. Du, Y . Liu, D. Niyato, J. Kang, Z. Xiong, A. Jamalipour, and D. I. Kim, “Generative AI agents with large language model for satellite networks via a mixture of experts transmission,”IEEE J. Sel. Areas Commun., vol. 42, no. 12, pp. 3581–3596, Dec. 2024
2024
-
[56]
Intellicise wireless networks meet agentic AI: A security and privacy perspective,
R. Meng, Z. Zhang, S. Gao, Y . Wang, X. Xu, Y . Lin, Y . Liu, C. Feng, L. Xu, Y . Maet al., “Intellicise wireless networks meet agentic AI: A security and privacy perspective,”arXiv preprint arXiv:2602.15290, 2026
-
[57]
Towards semantic-based agent communication networks: Vision, technologies, and challenges,
P. Zhang, R. Meng, X. Xu, Y . Wang, Z. Huang, Y . Liu, R. Zhang, Y . Liu, H. Tong, H. Songet al., “Towards semantic-based agent communication networks: Vision, technologies, and challenges,”arXiv preprint arXiv:2603.24328, 2026
-
[58]
Agentic AI-RAN: Enabling intent-driven, explainable and self-evolving open ran intelligence,
Z. He, Y . Luo, X. Liu, M. B. Mashhadi, M. Shojafar, M. Debbah, and R. Tafazolli, “Agentic AI-RAN: Enabling intent-driven, explainable and self-evolving open ran intelligence,”arXiv preprint arXiv:2602.24115, 2026
-
[59]
Scomcp: Task-oriented semantic communication for collaborative per- ception,
J. Gan, Y . Sheng, H. Zhang, L. Liang, H. Ye, C. Guo, and S. Jin, “Scomcp: Task-oriented semantic communication for collaborative per- ception,”IEEE Trans. V ehi. Techn., pp. 1–15, Jan. 2026
2026
-
[60]
PaLM-E: An Embodied Multimodal Language Model
D. Driess, F. Xia, M. S. Sajjadi, and et al., “Palm-e: An embodied multimodal language model,”arXiv preprint arXiv:2303.03378, 2023
work page internal anchor Pith review arXiv 2023
-
[61]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, and et al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inProc. Conf. Robot Learn., 2023
2023
-
[62]
Vrkitchen: An interactive 3d virtual environment for task-oriented learning,
X. Gao, R. Gong, T. Shu, and et al., “Vrkitchen: An interactive 3d virtual environment for task-oriented learning,” inProc. Int. Conf. Machine Learn. (ICML) Worshop Reinforcement Learning for Real Life, 2019
2019
-
[63]
X. Puig, E. Undersander, A. Szot, and et al., “Habitat 3.0: A co-habitat for humans, avatars and robots,”arXiv preprint arXiv:2310.13724, 2023
-
[64]
Corporation
N. Corporation. Phy abstraction tutorial - effective sinr. [Online]. Available: https://nvlabs.github.io/sionna/sys/tutorials/PHY_Abstraction. html#Effective-SINR
-
[65]
J. Bégaint, F. Racapé, S. Feltman, and A. Pushparaja, “Compressai: a pytorch library and evaluation platform for end-to-end compression research,”arXiv preprint arXiv:2011.03029, 2020
-
[66]
A deep learning framework performance evaluation to use YOLO in nvidia jetson platform,
D.-J. Shin and J.-J. Kim, “A deep learning framework performance evaluation to use YOLO in nvidia jetson platform,”Applied Sci., vol. 12, no. 8, p. 3734, 2022
2022
-
[67]
Poster: xg. glass: Develop AI glasses applications in 10 lines of code and easily deploy onto different glasses,
J. Xu, Y . Zhuang, Z. Li, J. Zhang, and Z. Meng, “Poster: xg. glass: Develop AI glasses applications in 10 lines of code and easily deploy onto different glasses,” inProc. of 27th Int. Workshop Mobile Comput. Syst. Appl., 2026, pp. 160–160
2026
-
[68]
Opencv: Open source computer vision library
OpenCV . Opencv: Open source computer vision library. [Online]. Available: https://github.com/opencv/opencv
-
[69]
Docvqa: A dataset for vqa on document images,
M. Mathew, D. Karatzas, and C. Jawahar, “Docvqa: A dataset for vqa on document images,” inProc. IEEE Winter Conf. Appl. Comput. Vision, 2021, pp. 2200–2209
2021
-
[70]
A review on yolov8 and its advancements,
M. Sohan, T. Sai Ram, and C. V . Rami Reddy, “A review on yolov8 and its advancements,” inInt. Conf. Data Intell. Cogn. Informat., Tirunelveli, India, June 2024, pp. 529–545
2024
-
[71]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inEuropean Conf. Comput. Vision (ECCV). Springer, 2014, pp. 740–755
2014
-
[72]
Thinking in space: How multimodal large language models see, remember, and recall spaces,
J. Yang, S. Yang, A. W. Gupta, R. Han, L. Fei-Fei, and S. Xie, “Thinking in space: How multimodal large language models see, remember, and recall spaces,” inIEEE Comput Vision Pattern Recogn. Conf. (CVPR), 2025, pp. 10 632–10 643
2025
-
[73]
BERTScore: Evaluating text generation with BERT,
T. Zhang, V . Kishore, F. Wu, K. Q. Weinberger, and Y . Artzi, “BERTScore: Evaluating text generation with BERT,” in8th Int. Conf. Learn. Represent., (ICLR), Addis Ababa, Ethiopia, April 26-30, 2020
2020
-
[74]
Reproducibility issues for bert-based evaluation metrics,
Y . Chen, J. Belouadi, and S. Eger, “Reproducibility issues for bert-based evaluation metrics,” in2022 Conf. Empirical Methods Natural Language Process.(EMNL), 2022, pp. 2965–2989
2022
-
[75]
Analysis of focus measure operators for shape-from-focus,
S. Pertuz, D. Puig, and M. A. Garcia, “Analysis of focus measure operators for shape-from-focus,”Pattern Recognition, vol. 46, no. 5, pp. 1415–1432, 2013
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.