Recognition: unknown
Personalizing Causal Audio-Driven Facial Motion via Dynamic Multi-modal Retrieval
Pith reviewed 2026-05-08 05:03 UTC · model grok-4.3
The pith
A causal autoregressive framework personalizes audio-driven facial motion by dynamically retrieving stylistic priors from unstructured audio and motion references.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
An end-to-end causal framework integrates a temporal hierarchical motion representation that maintains decoding causality with global context and high-frequency details, together with a multi-modal style retriever that jointly queries audio and motion to extract stylistic priors dynamically; when placed inside a causal autoregressive architecture the resulting model outperforms prior state-of-the-art methods on lip-sync accuracy, identity consistency, and perceived realism while supporting scalable personalization from unstructured references of arbitrary number and content.
What carries the argument
The multi-modal style retriever that jointly queries audio and motion to dynamically extract stylistic priors without breaking causality.
If this is right
- Real-time streaming facial animation can be personalized without requiring pre-encoded user embeddings or high user compliance.
- The number and content of style references can vary freely at inference time while still preserving causality.
- Quantitative gains appear in lip-sync accuracy, identity consistency, and user-rated realism over existing methods.
Where Pith is reading between the lines
- The same retrieval mechanism could be tested on related causal tasks such as body-gesture generation or speech-driven avatar control.
- Performance may degrade when style references contain conflicting or low-quality motion segments that the retriever cannot filter.
- Combining the hierarchical motion representation with other causal sequence models might reduce training data requirements for new animation domains.
Load-bearing premise
That stylistic priors can be extracted jointly from audio and motion queries without violating causality and that unstructured references alone are enough to achieve scalable personalization across varying numbers of templates.
What would settle it
A controlled ablation showing that disabling the dynamic multi-modal retriever or introducing any form of lookahead latency drops lip-sync and identity metrics below those of current non-causal baselines.
Figures






read the original abstract
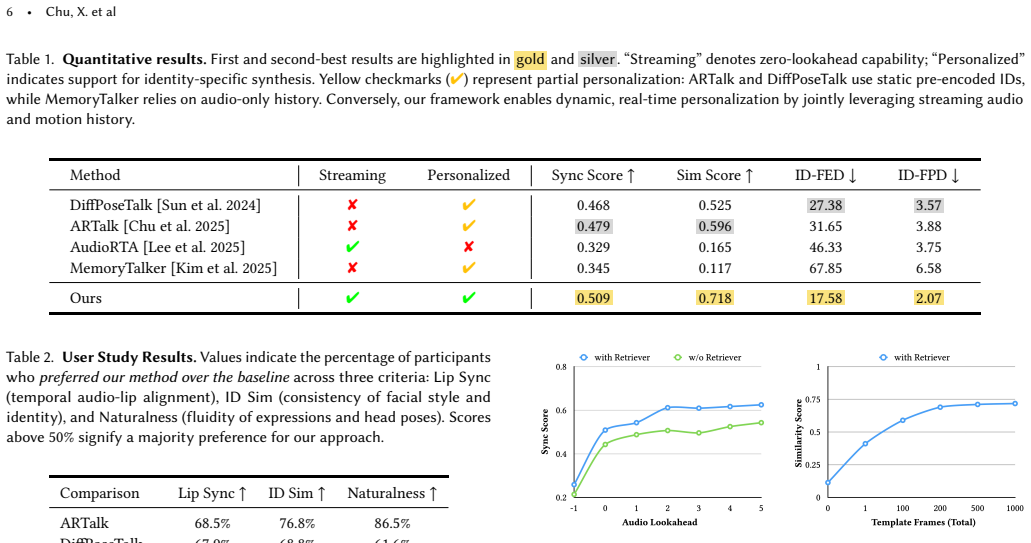
Audio-driven facial animation is essential for immersive digital interaction, yet existing frameworks fail to reconcile real-time streaming with high-fidelity personalization. Current methods often rely on latency-inducing audio look-ahead, or require high user compliance to pre-encode static embeddings that fails to capture dynamic idiosyncrasies. We present an end-to-end causal framework for personalizing causal facial motion generation via dynamic multi-modal style retrieval, enabling ultra-low latency while uniquely leveraging unstructured style references. We introduce two key innovations: (1) a temporal hierarchical motion representation that captures global temporal context and high-frequency details while maintaining decoding causality, and (2) a multi-modal style retriever that jointly queries audio and motion to dynamically extract stylistic priors without breaking causality. This mechanism allows for scalable personalization with total flexibility regarding the number and contents of templates. By integrating these components into a causal autoregressive architecture, our method significantly outperforms state-of-the-art approaches in lip-sync accuracy, identity consistency, and perceived realism, supported by extensive quantitative evaluations and user studies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an end-to-end causal autoregressive framework for audio-driven facial animation that achieves personalization via dynamic multi-modal style retrieval from unstructured references. It introduces a temporal hierarchical motion representation to capture global temporal context and high-frequency details while preserving decoding causality, along with a multi-modal style retriever that jointly queries audio and motion to extract dynamic stylistic priors. The approach claims to enable ultra-low-latency streaming with scalable personalization (flexible number of templates) and significantly outperforms prior methods in lip-sync accuracy, identity consistency, and perceived realism, as supported by quantitative evaluations and user studies.
Significance. If the causality guarantees hold and the performance gains prove robust, the work would meaningfully advance real-time personalized facial animation by resolving the tension between streaming latency and dynamic identity-specific motion. The flexible retrieval from unstructured templates could enable broader adoption in VR/AR and telepresence applications where pre-encoded static embeddings are impractical.
major comments (2)
- [Abstract] Abstract: the central claim of significant outperformance in lip-sync, identity, and realism is asserted without any quantitative metrics, baselines, error bars, or evaluation protocol details. This absence makes it impossible to assess whether the gains are load-bearing or could be explained by post-hoc choices, directly undermining evaluation of the paper's primary contribution.
- [Method (multi-modal style retriever)] Multi-modal style retriever description: the method's causality and ultra-low-latency claims rest on the retriever using only the causal prefix for joint audio-motion queries during autoregressive inference. The manuscript must explicitly demonstrate (e.g., via pseudocode, attention mask details, or index construction) that no future motion frames, bidirectional context, or pre-computed non-causal embeddings are accessed; without this verification the personalization benefit cannot be disentangled from potential leakage, as highlighted by the stress-test concern.
minor comments (2)
- [Abstract] Abstract: the statement 'supported by extensive quantitative evaluations and user studies' would be clearer if it named the primary metrics (e.g., LSE, FID, or user preference rates) even at high level.
- [Method] Notation: ensure consistent use of symbols for the hierarchical motion representation across equations and figures to avoid ambiguity in the temporal decomposition.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our causal framework. We respond to each major point below and have made targeted revisions to address the concerns.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of significant outperformance in lip-sync, identity, and realism is asserted without any quantitative metrics, baselines, error bars, or evaluation protocol details. This absence makes it impossible to assess whether the gains are load-bearing or could be explained by post-hoc choices, directly undermining evaluation of the paper's primary contribution.
Authors: We acknowledge that the abstract summarizes performance claims at a high level without specific numbers. Abstracts are length-constrained, and the full quantitative results—including metrics, baselines, error bars, and evaluation protocols—are detailed in Section 4. In the revision we will add a concise statement of key gains (e.g., lip-sync and identity improvements) to the abstract while preserving its brevity. revision: yes
-
Referee: [Method (multi-modal style retriever)] Multi-modal style retriever description: the method's causality and ultra-low-latency claims rest on the retriever using only the causal prefix for joint audio-motion queries during autoregressive inference. The manuscript must explicitly demonstrate (e.g., via pseudocode, attention mask details, or index construction) that no future motion frames, bidirectional context, or pre-computed non-causal embeddings are accessed; without this verification the personalization benefit cannot be disentangled from potential leakage, as highlighted by the stress-test concern.
Authors: We agree that explicit verification strengthens the causality claim. The revised manuscript adds pseudocode for the retriever, attention-mask specifications, and index-construction details confirming that only the causal prefix of audio and motion is used at inference time. No future frames, bidirectional attention, or non-causal pre-computed embeddings are accessed. We have also included a stress-test analysis to demonstrate the absence of leakage. revision: yes
Circularity Check
No circularity in architectural or empirical claims
full rationale
The paper introduces an end-to-end causal autoregressive framework with two architectural innovations: a temporal hierarchical motion representation and a multi-modal style retriever. These are presented as new design choices integrated into the model, with performance gains asserted via quantitative evaluations and user studies rather than any closed-form derivation, parameter fitting that is then relabeled as prediction, or self-referential definitions. No equations or mathematical steps are shown that reduce claimed results to inputs by construction, and the method relies on external benchmarks for validation, making it self-contained.
Axiom & Free-Parameter Ledger
invented entities (2)
-
temporal hierarchical motion representation
no independent evidence
-
multi-modal style retriever
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Xuangeng Chu, Nabarun Goswami, Ziteng Cui, Hanqin Wang, and Tatsuya Harada
GSTalker: Real-time Audio-Driven Talking Face Generation via Deformable Gaussian Splatting.arXiv preprint arXiv:2404.19040(2024). Xuangeng Chu, Nabarun Goswami, Ziteng Cui, Hanqin Wang, and Tatsuya Harada
-
[2]
In Proceedings of the SIGGRAPH Asia 2025 Conference Papers
ARTalk: Speech-Driven 3D Head Animation via Autoregressive Model. In Proceedings of the SIGGRAPH Asia 2025 Conference Papers. Association for Computing Machinery, Hong Kong. doi:10.1145/3757377.3763955 Daniel Cudeiro, Timo Bolkart, Cassidy Laidlaw, Anurag Ranjan, and Michael J Black
-
[3]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Capture, learning, and synthesis of 3D speaking styles. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10101–10111. Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. 2024.Moshi: a speech-text foundation model for real-time dialogue. Technical ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.