Recognition: unknown
Spore: Efficient and Training-Free Privacy Extraction Attack on LLMs via Inference-Time Hybrid Probing
Pith reviewed 2026-05-08 06:05 UTC · model grok-4.3
The pith
Spore extracts private user context from LLM agent memory with one black-box query and higher success than prior attacks while bypassing defenses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Spore is a hybrid probing technique that, without any training or white-box access, extracts private information held in LLM agent memory by issuing targeted inference-time queries whose token outputs contain the sensitive content in a recoverable form. In the black-box setting a single query suffices to produce a short candidate list containing the original private data; in the gray-box setting multi-ranked tokens further accelerate and improve recovery. Information-theoretic analysis establishes that each query leaks substantial entropy, and experiments confirm higher attack success rates, lower query cost, and resilience to existing defenses compared with prior schemes.
What carries the argument
Inference-time hybrid probing: a single crafted query (black-box) or ranked-token response (gray-box) that surfaces private memory tokens in the model's output distribution without prior training or model internals.
If this is right
- LLM agent deployments expose user context to extraction by a single well-crafted query.
- Existing detection and safety-alignment methods do not reliably block this form of inference-time probing.
- Privacy risk scales with the amount of personal data retained in agent memory rather than with model size or training regime.
- Attack cost remains low even when the target model changes, because the method relies only on output tokens.
Where Pith is reading between the lines
- Agent designers may need to avoid storing raw user context or to add per-query memory isolation that prevents probe leakage.
- Monitoring for atypical query patterns could serve as a practical countermeasure, though the paper does not test such detection.
- The same probing principle might apply to other contextual leakage vectors such as tool-use histories or multi-turn conversation summaries.
Load-bearing premise
Private information stored in an LLM agent's memory will appear among the tokens generated by a carefully chosen probe query even when the attacker has no training data or white-box access.
What would settle it
An experiment in which Spore's candidate set consistently excludes the true private string or in which its success rate falls below that of baseline attacks when the model applies stronger safety fine-tuning or output filtering.
Figures




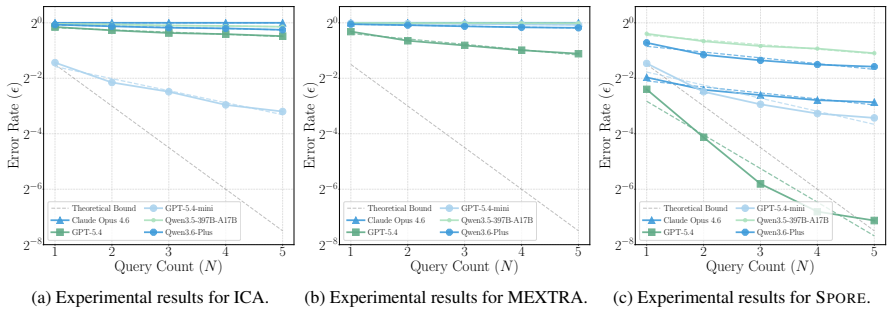
read the original abstract
With the wide adoption of personal AI assistants such as OpenClaw, privacy leakage in user interaction contexts with large language model (LLM) agents has become a critical issue. Existing privacy attacks against LLMs primarily target training data, while research on inference-time contextual privacy risks in LLM agent memory remains limited. Moreover, prior methods often incur high attack costs, requiring multiple queries or relying on white-box assumptions, which limits their practicality in real-world deployments. To address these issues, we propose a training-free privacy extraction attack targeting LLM agent memory, which we name \textsc{Spore}. \textsc{Spore} is compatible with both black-box and gray-box settings. In the black-box setting, \textsc{Spore} can efficiently extract a small candidate set via a single query to recover the original private information. In the gray-box setting, \textsc{Spore} allows the attacker to leverage multi-ranked tokens for more accurate and faster privacy extraction. We provide an information-theoretic analysis of \textsc{Spore} and show that it achieves high query efficiency with substantial per query information leakage. Experiments on multiple frontier LLMs show that \textsc{Spore} outperforms attack success rate over existing state-of-the-art (SOTA) schemes. It also maintains low attack cost and remains stable across different model parameter settings. We further evaluate the robustness of \textsc{Spore} against existing defense mechanisms. Our results show that \textsc{Spore} consistently bypasses both detection and strong safety alignment, demonstrating resilient performance in diverse defensive settings and real-world safety threats.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Spore, a training-free inference-time hybrid probing attack for extracting private information stored in LLM agent memory. It supports black-box settings via a single query that returns a small candidate set and gray-box settings that exploit ranked tokens for higher accuracy. The work includes an information-theoretic analysis claiming high query efficiency and substantial per-query leakage, plus experiments on frontier LLMs asserting higher attack success rates than prior SOTA methods, low cost, stability across model sizes, and consistent bypass of detection and safety-alignment defenses.
Significance. If the central claims hold under rigorous validation, the result would be significant for LLM security and privacy research. It identifies a practical, low-cost inference-time vector against contextual agent memory that existing training-data-focused attacks do not address. The training-free design and reported robustness to defenses could directly inform defense design for deployed personal AI assistants. The information-theoretic component supplies independent grounding beyond pure empirics, which is a strength.
major comments (3)
- [Method] Method section (hybrid probing description): The core claim that a single inference-time query reliably surfaces private memory content in a small recoverable candidate set (black-box) or top-ranked tokens (gray-box) rests on the untested assumption that the model's token distribution encodes the private datum without prior knowledge of its format or storage. This assumption is load-bearing for both the efficiency claims and the SOTA outperformance; if private data is indirectly stored, multi-turn, or suppressed by alignment, the candidate set misses the target and leakage drops sharply.
- [Experiments] Experiments section: The reported outperformance in attack success rate and robustness to defenses lacks sufficient controls and reporting. No details are given on how private information is injected into agent memory (direct statements vs. complex multi-turn), the exact composition of test cases, number of trials per setting, or statistical tests for the claimed superiority. Without these, it is impossible to determine whether results generalize or whether the hybrid probe itself activates suppression mechanisms.
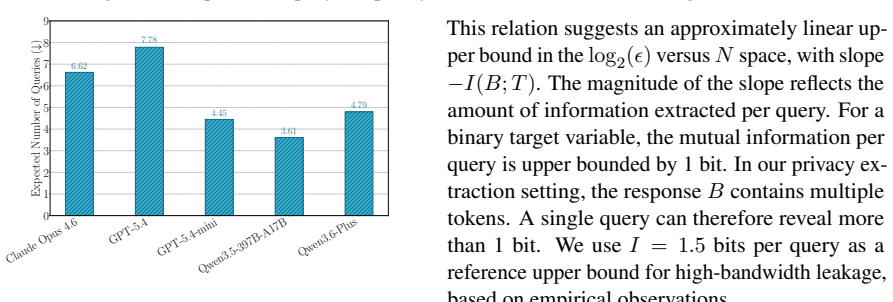
- [Analysis] Information-theoretic analysis: The analysis asserts high per-query information leakage and efficiency, yet provides no explicit derivation linking the hybrid probing strategy to concrete mutual-information or entropy-reduction bounds. The claims therefore risk being general statements rather than tight characterizations of the specific attack, weakening the grounding for the efficiency and leakage assertions.
minor comments (3)
- [Introduction] The distinction between black-box and gray-box threat models could be stated more crisply in the introduction and abstract, including the precise attacker capabilities assumed in each.
- [Experiments] Tables reporting attack success rates should include variance or confidence intervals across runs and models to support the stability claim.
- [Related Work] A few sentences on related inference-time privacy work (e.g., prompt-injection or memory-extraction baselines) would help situate the novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and outline planned revisions to improve the manuscript's clarity, rigor, and completeness.
read point-by-point responses
-
Referee: [Method] Method section (hybrid probing description): The core claim that a single inference-time query reliably surfaces private memory content in a small recoverable candidate set (black-box) or top-ranked tokens (gray-box) rests on the untested assumption that the model's token distribution encodes the private datum without prior knowledge of its format or storage. This assumption is load-bearing for both the efficiency claims and the SOTA outperformance; if private data is indirectly stored, multi-turn, or suppressed by alignment, the candidate set misses the target and leakage drops sharply.
Authors: We acknowledge that the effectiveness of hybrid probing depends on the model's token distribution reflecting stored private data. The attack is motivated by empirical observations that LLMs often surface contextual memory in inference-time probabilities, and our experiments on frontier models with direct memory injection achieve high success rates, supporting practical validity. To address the concern, we will add a new subsection in the Method section explicitly stating the assumptions, discussing limitations for indirect/multi-turn storage or strong suppression, and outlining adaptation strategies. We will also incorporate additional experiments with varied injection methods in the revised version. revision: partial
-
Referee: [Experiments] Experiments section: The reported outperformance in attack success rate and robustness to defenses lacks sufficient controls and reporting. No details are given on how private information is injected into agent memory (direct statements vs. complex multi-turn), the exact composition of test cases, number of trials per setting, or statistical tests for the claimed superiority. Without these, it is impossible to determine whether results generalize or whether the hybrid probe itself activates suppression mechanisms.
Authors: We agree that expanded reporting and controls are essential. In the revised Experiments section we will detail: injection methods (primarily direct statements in the agent context, with new multi-turn examples added); test case composition (50 private facts spanning categories such as identifiers and sensitive attributes); trial counts (100 independent runs per model/setting); and statistical tests (means with standard deviations plus t-tests with p < 0.05 confirming superiority over baselines). These additions will also report failure modes to evaluate potential suppression activation by the probe. revision: yes
-
Referee: [Analysis] Information-theoretic analysis: The analysis asserts high per-query information leakage and efficiency, yet provides no explicit derivation linking the hybrid probing strategy to concrete mutual-information or entropy-reduction bounds. The claims therefore risk being general statements rather than tight characterizations of the specific attack, weakening the grounding for the efficiency and leakage assertions.
Authors: We appreciate the call for tighter formalization. The existing analysis offers high-level entropy-reduction arguments; we will add an explicit derivation in a new appendix (or expanded main-text subsection) that defines mutual information I(Private Data; Probe Response) and shows how the hybrid strategy produces greater per-query entropy reduction than prior attacks. This will directly connect the bounds to the probing mechanism and strengthen the efficiency claims. revision: yes
Circularity Check
No significant circularity; empirical attack with independent analysis
full rationale
The paper presents Spore as a training-free inference-time probing method evaluated empirically on frontier LLMs, with success rates compared to external SOTA baselines and robustness tested against existing defenses. The information-theoretic analysis of query efficiency and per-query leakage is derived from standard entropy measures applied to the observed token distributions, without reducing to fitted parameters from the attack results themselves or self-referential definitions. No load-bearing steps invoke self-citations for uniqueness theorems, smuggle ansatzes, or rename known results as novel derivations. The central claims rest on experimental measurements and external comparisons rather than tautological reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM inference reveals information about stored context through output tokens and probabilities
Reference graph
Works this paper leans on
-
[1]
Wassim Bouaziz, Mathurin VIDEAU, Nicolas Usunier, and El-Mahdi El-Mhamdi
On the impossibility of separating intelli- gence from judgment: The computational intractabil- ity of filtering for ai alignment.arXiv preprint arXiv:2507.07341. Wassim Bouaziz, Mathurin VIDEAU, Nicolas Usunier, and El-Mahdi El-Mhamdi. 2026. Winter soldier: Backdooring language models at pre-training with indirect data poisoning. InThe Fourteenth Interna...
-
[2]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374. Yulin Chen, Haoran Li, Yuan Sui, Yufei He, Yue Liu, Yangqiu Song, and Bryan Hooi. 2025a. Can indirect prompt injection attacks be detected and removed? InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 18...
work page internal anchor Pith review arXiv 2025
-
[3]
In2023 IEEE Symposium on Security and Privacy (SP), pages 1401–1418
Rethinking searchable symmetric encryption. In2023 IEEE Symposium on Security and Privacy (SP), pages 1401–1418. Changzhou Han, Zehang Deng, Wanlun Ma, Xiaogang Zhu, Minhui Xue, Tianqing Zhu, Sheng Wen, and Yang Xiang. 2025. Codebreaker: Dynamic extraction attacks on code language models. In2025 IEEE Symposium on Security and Privacy (SP), pages 559– 575....
2025
-
[4]
Defending against indirect prompt injection attacks with spotlighting
Towards label-only membership inference at- tack against pre-trained large language models. In Proceedings of the 34th USENIX Conference on Se- curity Symposium, SEC ’25, USA. USENIX Associ- ation. Keegan Hines, Gary Lopez, Matthew Hall, Federico Zarfati, Yonatan Zunger, and Emre Kiciman. 2024. Defending against indirect prompt injection attacks with spot...
-
[5]
Analyzing leakage of personally identifiable information in language models. In2023 IEEE Sym- posium on Security and Privacy (SP), pages 346–363. Xingjun Ma, Yixu Wang, Hengyuan Xu, Yutao Wu, Yi- fan Ding, Yunhan Zhao, Zilong Wang, Jiabin Hua, Ming Wen, Jianan Liu, Ranjie Duan, Yifeng Gao, Yingshui Tan, Yunhao Chen, Hui Xue, Xin Wang, Wei Cheng, Jingjing ...
-
[6]
CIMemories: A compositional benchmark for contextual integrity in LLMs. InThe Fourteenth In- ternational Conference on Learning Representations. Milad Nasr, Javier Rando, Nicholas Carlini, Jonathan Hayase, Matthew Jagielski, A. Feder Cooper, Daphne Ippolito, Christopher A. Choquette-Choo, Florian Tramèr, and Katherine Lee. 2025. Scalable extraction of tra...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Internal safety collapse in frontier large language models.arXiv preprint arXiv:2603.23509, 2026
Membership inference attacks against in- context learning. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communica- tions Security, CCS ’24, page 3481–3495, New York, NY , USA. Association for Computing Machinery. Yutao Wu, Xiao Liu, Yifeng Gao, Xiang Zheng, Hanxun Huang, Yige Li, Cong Wang, Bo Li, Xingjun Ma, and Yu-Gang Jiang. 2026....
-
[8]
C Response from Detector Detection Results of an Attack Case
Bag of tricks for training data extraction from language models. InProceedings of the 40th Interna- tional Conference on Machine Learning, ICML’23. JMLR.org. Xiao Zhan, Juan Carlos Carrillo, William Seymour, and Jose Such. 2025. Malicious llm-based conversational 11 ai makes users reveal personal information. InPro- ceedings of the 34th USENIX Conference ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.