Recognition: unknown
RTCFake: Speech Deepfake Detection in Real-Time Communication
Pith reviewed 2026-05-08 05:26 UTC · model grok-4.3
The pith
Routing speech deepfakes through real apps like Zoom produces paired recordings that expose how unknown codecs and enhancements defeat existing detectors, while a phoneme-guided consistency strategy restores cross-platform performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
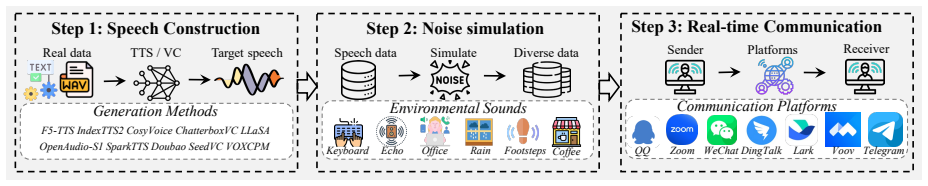
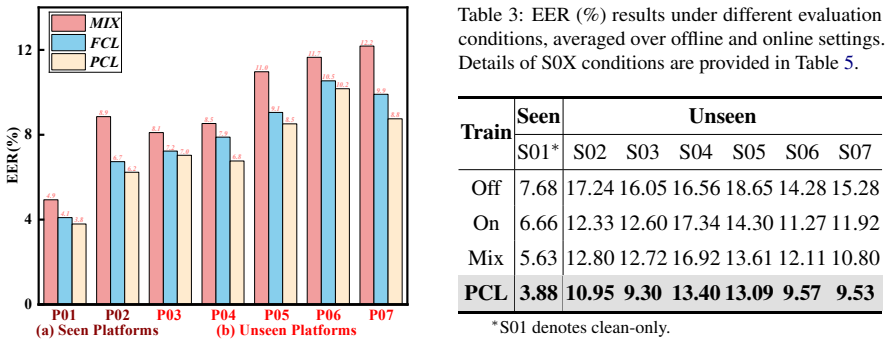
The authors transmit speech through multiple social media and conferencing platforms to generate a 600-hour dataset of precisely paired offline and online versions. They partition the data so the evaluation portion contains both unseen platforms and unseen complex noise. Their phoneme-guided consistency learning strategy trains detectors to produce consistent representations for the same phoneme sequences despite platform-specific distortions, yielding measurable gains in generalization and noise robustness.
What carries the argument
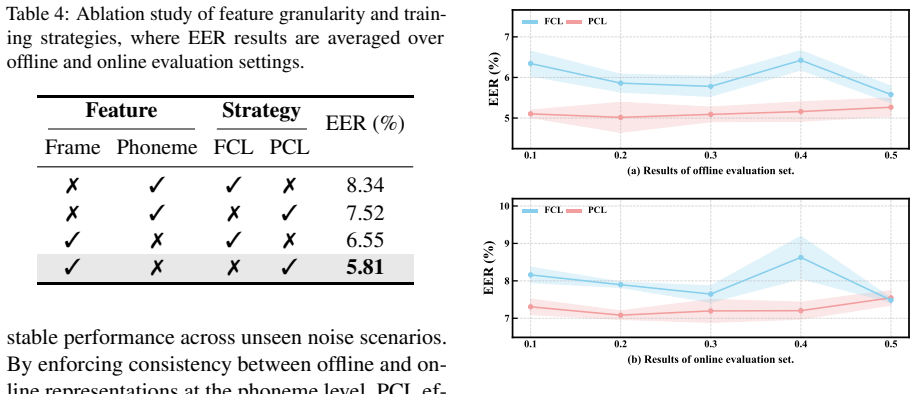
Phoneme-guided consistency learning (PCL), which enforces platform-invariant semantic structural representations by aligning model outputs on phoneme sequences across differently distorted versions of the same utterance.
If this is right
- Models trained with PCL maintain higher accuracy when the test platform differs from any platform seen during training.
- The same consistency objective improves detection under additive noise and enhancement artifacts that were absent from the training distribution.
- Precise offline-online pairing allows direct measurement of how much each transmission step degrades detection performance.
- The dataset splits supply a fixed benchmark for comparing future methods on cross-platform and noise-robust deepfake detection.
Where Pith is reading between the lines
- The transmission-based data collection method could be reused for other audio classification tasks that must survive variable codec chains, such as speaker verification or emotion recognition.
- If the invariance learned by PCL proves stable, it could be combined with lightweight on-device models to enable real-time deepfake screening inside conferencing applications.
- Extending the same pairing technique to video streams would allow joint audio-visual deepfake benchmarks for RTC scenarios.
Load-bearing premise
That distortions created by routing speech through current mainstream platforms match the unknown enhancement and codec processes present in actual real-time communication use.
What would settle it
Test a PCL-trained detector on deepfake speech transmitted through a conferencing platform never used in the dataset construction and compare its equal-error rate against the same detector run on the original RTCFake evaluation set.
Figures



read the original abstract
With the rapid advancement of speech generation technologies, the threat posed by speech deepfakes in real-time communication (RTC) scenarios has intensified. However, existing detection studies mainly focus on offline simulations and struggle to cope with the complex distortions introduced during RTC transmission, including unknown speech enhancement processes (e.g., noise suppression) and codec compression. To address this challenge, we present the first large-scale speech deepfake dataset tailored for RTC scenarios, termed \textit{RTCFake}, totaling approximately 600 hours. The dataset is constructed by transmitting speech through multiple mainstream social media and conferencing platforms (e.g., Zoom), enabling precise pairing between offline and online speech. In addition, we propose a phoneme-guided consistency learning (PCL) strategy that enforces models to learn platform-invariant semantic structural representations. In this paper, the RTCFake dataset is divided into training, development, and evaluation sets. The evaluation set further includes both unseen RTC platforms and unseen complex noise conditions, thereby providing a more realistic and challenging evaluation benchmark for speech deepfake detection. Furthermore, the proposed PCL strategy achieves significant improvements in both cross-platform generalization and noise robustness, offering an effective and generalizable modeling paradigm. The \textit{RTCFake} dataset is provided in the {https://huggingface.co/datasets/JunXueTech/RTCFake}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RTCFake, the first large-scale (~600-hour) paired speech deepfake dataset for real-time communication (RTC) scenarios. It is constructed by routing offline deepfake and bona fide speech through mainstream platforms (e.g., Zoom) to simulate transmission distortions from unknown enhancement and codecs. The authors propose a phoneme-guided consistency learning (PCL) strategy that enforces platform-invariant semantic representations. They split the dataset into train/dev/eval sets, with the evaluation set containing unseen platforms and complex noise, and claim that PCL yields significant gains in cross-platform generalization and noise robustness. The dataset is released publicly on Hugging Face.
Significance. If the empirical results hold, the work would be significant for closing the gap between offline deepfake detection and practical RTC use cases, where adaptive codecs and real-time processing introduce distortions absent from existing benchmarks. The public release of a large, precisely paired dataset is a clear strength that enables reproducible research on invariant learning. The PCL paradigm, if shown to be effective via ablations, offers a generalizable modeling approach that could extend to other audio robustness tasks.
major comments (2)
- [Dataset Construction] Dataset Construction section: the central assumption that offline transmission through platforms produces distortions representative of live RTC (including adaptive bitrate, jitter buffers, and real-time noise suppression) is not supported by any acoustic validation such as codec signature histograms, PESQ/STOI distributions, or spectral comparisons to live sessions. This assumption is load-bearing for the PCL invariance claims and cross-platform generalization results.
- [Results] Results section: the abstract and evaluation claim 'significant improvements' from PCL in cross-platform and noise-robust settings, yet the manuscript supplies no quantitative metrics, ablation studies isolating the phoneme-guidance component, or error analysis. Without these, the magnitude and reliability of the reported gains cannot be assessed.
minor comments (2)
- [Methods] The methods description of PCL would benefit from an explicit diagram or pseudocode showing how phoneme guidance is combined with consistency loss, as the current high-level description leaves the implementation details unclear.
- [Related Work] Related work could add citations to prior studies on RTC codec distortions and real-time enhancement pipelines to better contextualize the novelty of the platform-transmission approach.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our paper introducing the RTCFake dataset and the PCL strategy. We address the major comments point-by-point below, agreeing where revisions are needed to strengthen the claims, and describe the planned changes.
read point-by-point responses
-
Referee: Dataset Construction section: the central assumption that offline transmission through platforms produces distortions representative of live RTC (including adaptive bitrate, jitter buffers, and real-time noise suppression) is not supported by any acoustic validation such as codec signature histograms, PESQ/STOI distributions, or spectral comparisons to live sessions. This assumption is load-bearing for the PCL invariance claims and cross-platform generalization results.
Authors: We agree that the manuscript currently lacks explicit acoustic validation metrics to confirm that the offline transmission through platforms accurately represents live RTC distortions. Our dataset construction relies on routing speech through the platforms to capture real-world codec and enhancement effects, which we posit simulates the distortions effectively due to the precise offline-online pairing. To address this concern and better support the PCL claims, we will revise the Dataset Construction section to include acoustic analysis, such as PESQ and STOI score distributions, spectral comparisons, and available codec signature information, comparing the transmitted audio to expected live RTC characteristics. revision: yes
-
Referee: Results section: the abstract and evaluation claim 'significant improvements' from PCL in cross-platform and noise-robust settings, yet the manuscript supplies no quantitative metrics, ablation studies isolating the phoneme-guidance component, or error analysis. Without these, the magnitude and reliability of the reported gains cannot be assessed.
Authors: We acknowledge that while the manuscript reports performance improvements with PCL in the cross-platform and noise-robust evaluation settings, it does not provide detailed quantitative metrics (e.g., specific EER or accuracy deltas), ablations isolating the phoneme-guidance aspect, or error analysis. The 'significant improvements' are derived from comparative experiments against baselines. In the revised manuscript, we will enhance the Results section by adding quantitative metrics from the experiments, dedicated ablation studies to isolate the contribution of the phoneme-guided component in PCL, and an error analysis discussing cases where detection fails under unseen platforms or noise conditions. revision: yes
Circularity Check
PCL is a proposed modeling choice; no derivation reduces to inputs by construction or self-citation.
full rationale
The paper constructs RTCFake by transmitting pre-recorded speech through platforms to create paired offline/online versions and introduces PCL as an enforcement strategy for platform-invariant representations. No equations, fitted parameters, or uniqueness theorems are referenced in the provided text that would make any prediction equivalent to its inputs. The reported gains in cross-platform generalization are presented as empirical outcomes rather than forced by self-definition or load-bearing self-citations. This is a standard dataset-plus-method contribution with independent experimental content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https://www.volcengine.com/docs/6561/1257584?lang=en
2025. https://www.volcengine.com/docs/6561/1257584?lang=en
2025
-
[2]
Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, and 1 others. 2022. Xls-r: Self-supervised cross-lingual speech representation learning at scale. In Proc. Interspeech 2022, pages 2278--2282
2022
-
[3]
Channel News Asia . 2025. https://www.channelnewsasia.com/singapore/deepfake-scam-impersonate-ceo-company-finance-director-5048706 Company finance director nearly loses over US \ 499 , 000 to scammers using deepfake to impersonate ceo . Accessed: 2025-11-6
2025
-
[4]
Yushen Chen, Zhikang Niu, Ziyang Ma, Keqi Deng, Chunhui Wang, JianZhao JianZhao, Kai Yu, and Xie Chen. 2025. F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6255--6271
2025
-
[5]
Jiawei Du, I-Ming Lin, I-Hsiang Chiu, Xuanjun Chen, Haibin Wu, Wenze Ren, Yu Tsao, Hung-yi Lee, and Jyh-Shing Roger Jang. 2024 a . Dfadd: The diffusion and flow-matching based audio deepfake dataset. In 2024 IEEE Spoken Language Technology Workshop (SLT), pages 921--928. IEEE
2024
- [6]
-
[7]
Cunhang Fan, Mingming Ding, Jianhua Tao, Ruibo Fu, Jiangyan Yi, Zhengqi Wen, and Zhao Lv. 2024 a . Dual-branch knowledge distillation for noise-robust synthetic speech detection. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 32:2453--2466
2024
-
[8]
Cunhang Fan, Jun Xue, Jianhua Tao, Jiangyan Yi, Chenglong Wang, Chengshi Zheng, and Zhao Lv. 2024 b . Spatial reconstructed local attention res2net with f0 subband for fake speech detection. Neural Networks, 175:106320
2024
-
[9]
Wen Huang, Yanmei Gu, Zhiming Wang, Huijia Zhu, and Yanmin Qian. 2025. Speechfake: A large-scale multilingual speech deepfake dataset incorporating cutting-edge generation methods. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), page 9985–9998. Association for Computational Linguistics
2025
-
[10]
Jee-weon Jung, Hee-Soo Heo, Hemlata Tak, Hye-jin Shim, Joon Son Chung, Bong-Jin Lee, Ha-Jin Yu, and Nicholas Evans. 2022. Aasist: Audio anti-spoofing using integrated spectro-temporal graph attention networks. In ICASSP 2022-2022 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 6367--6371. IEEE
2022
-
[11]
Jee-weon Jung, Yihan Wu, Xin Wang, Ji-Hoon Kim, Soumi Maiti, Yuta Matsunaga, Hye-jin Shim, Jinchuan Tian, Nicholas Evans, Joon Son Chung, and 1 others. 2025. Spoofceleb: Speech deepfake detection and sasv in the wild. IEEE Open Journal of Signal Processing
2025
-
[12]
Wei Kang, Xiaoyu Yang, Zengwei Yao, Fangjun Kuang, Yifan Yang, Liyong Guo, Long Lin, and Daniel Povey. 2024. Libriheavy: A 50,000 hours asr corpus with punctuation casing and context. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 10991--10995. IEEE
2024
-
[13]
Xinfeng Li, Kai Li, Yifan Zheng, Chen Yan, Xiaoyu Ji, and Wenyuan Xu. 2024 a . Safeear: Content privacy-preserving audio deepfake detection. In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pages 3585--3599
2024
-
[14]
Yuang Li, Min Zhang, Mengxin Ren, Xiaosong Qiao, Miaomiao Ma, Daimeng Wei, and Hao Yang. 2024 b . Cross-domain audio deepfake detection: Dataset and analysis. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 4977--4983
2024
- [15]
- [16]
-
[17]
Xuechen Liu, Xin Wang, Md Sahidullah, Jose Patino, H \'e ctor Delgado, Tomi Kinnunen, Massimiliano Todisco, Junichi Yamagishi, Nicholas Evans, Andreas Nautsch, and 1 others. 2023. Asvspoof 2021: Towards spoofed and deepfake speech detection in the wild. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:2507--2522
2023
-
[18]
u ller, Piotr Kawa, Wei Herng Choong, Edresson Casanova, Eren G \
Nicolas M M \"u ller, Piotr Kawa, Wei Herng Choong, Edresson Casanova, Eren G \"o lge, Thorsten M \"u ller, Piotr Syga, Philip Sperl, and Konstantin B \"o ttinger. 2024. Mlaad: The multi-language audio anti-spoofing dataset. In 2024 International Joint Conference on Neural Networks (IJCNN), pages 1--7. IEEE
2024
-
[19]
Karol J Piczak. 2015. Esc: Dataset for environmental sound classification. In Proceedings of the 23rd ACM international conference on Multimedia, pages 1015--1018
2015
-
[20]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2023. Robust speech recognition via large-scale weak supervision. In International conference on machine learning, pages 28492--28518. PMLR
2023
-
[21]
Resemble AI . 2025. Chatterbox-TTS . https://github.com/resemble-ai/chatterbox. GitHub repository
2025
-
[22]
Hemlata Tak, Madhu Kamble, Jose Patino, Massimiliano Todisco, and Nicholas Evans. 2022 a . Rawboost: A raw data boosting and augmentation method applied to automatic speaker verification anti-spoofing. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6382--6386. IEEE
2022
-
[23]
Hemlata Tak, Massimiliano Todisco, Xin Wang, Jee-weon Jung, Junichi Yamagishi, and Nicholas Evans. 2022 b . Automatic speaker verification spoofing and deepfake detection using wav2vec 2.0 and data augmentation. In The Speaker and Language Recognition Workshop (Odyssey 2022). ISCA
2022
-
[24]
Massimiliano Todisco, Xin Wang, Ville Vestman, Md Sahidullah, Hector Delgado, Andreas Nautsch, Junichi Yamagishi, Nicholas Evans, Tomi Kinnunen, and Kong Aik Lee. 2019. Asvspoof 2019: Future horizons in spoofed and fake audio detection. In Interspeech 2019, pages 1008--1012. International Speech Communication Association
2019
-
[25]
Xin Wang, H \'e ctor Delgado, Hemlata Tak, Jee-Weon Jung, Hye-Jin Shim, Massimiliano Todisco, Ivan Kukanov, Xuechen Liu, Md Sahidullah, Tomi Kinnunen, and 1 others. 2024. Asvspoof 5: crowdsourced speech data, deepfakes, and adversarial attacks at scale. In The Automatic Speaker Verification Spoofing Countermeasures Workshop (ASVspoof 2024), pages 1--8. ISCA
2024
- [26]
-
[27]
Haibin Wu, Yuan Tseng, and Hung-yi Lee. 2024. Codecfake: Enhancing anti-spoofing models against deepfake audios from codec-based speech synthesis systems. In Proc. Interspeech 2024, pages 1770--1774
2024
- [28]
-
[29]
Yuankun Xie, Yi Lu, Ruibo Fu, Zhengqi Wen, Zhiyong Wang, Jianhua Tao, Xin Qi, Xiaopeng Wang, Yukun Liu, Haonan Cheng, and 1 others. 2025 b . The codecfake dataset and countermeasures for the universally detection of deepfake audio. IEEE Transactions on Audio, Speech and Language Processing
2025
-
[30]
Qiantong Xu, Alexei Baevski, and Michael Auli. 2022. Simple and effective zero-shot cross-lingual phoneme recognition. In Proc. Interspeech 2022, pages 2113--2117
2022
-
[31]
Jun Xue, Cunhang Fan, Zhao Lv, Jianhua Tao, Jiangyan Yi, Chengshi Zheng, Zhengqi Wen, Minmin Yuan, and Shegang Shao. 2022. Audio deepfake detection based on a combination of f0 information and real plus imaginary spectrogram features. In Proceedings of the 1st international workshop on deepfake detection for audio multimedia, pages 19--26
2022
-
[32]
Jun Xue, Cunhang Fan, Jiangyan Yi, Chenglong Wang, Zhengqi Wen, Dan Zhang, and Zhao Lv. 2023. Learning from yourself: A self-distillation method for fake speech detection. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1--5. IEEE
2023
-
[33]
Jun Xue, Cunhang Fan, Jiangyan Yi, Jian Zhou, and Zhao Lv. 2024. Dynamic ensemble teacher-student distillation framework for light-weight fake audio detection. IEEE Signal Processing Letters, 31:2305--2309
2024
-
[34]
Junichi Yamagishi, Xin Wang, Massimiliano Todisco, Md Sahidullah, Jose Patino, Andreas Nautsch, Xuechen Liu, Kong Aik Lee, Tomi Kinnunen, Nicholas Evans, and 1 others. 2021. Asvspoof 2021: accelerating progress in spoofed and deepfake speech detection. In Proc. ASVSPOOF 2021, pages 47--54
2021
- [35]
-
[36]
Jiangyan Yi, Ruibo Fu, Jianhua Tao, Shuai Nie, Haoxin Ma, Chenglong Wang, Tao Wang, Zhengkun Tian, Ye Bai, Cunhang Fan, and 1 others. 2022. Add 2022: the first audio deep synthesis detection challenge. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 9216--9220. IEEE
2022
- [37]
-
[38]
Qishan Zhang, Shuangbing Wen, and Tao Hu. 2024. Audio deepfake detection with self-supervised xls-r and sls classifier. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 6765--6773
2024
- [39]
- [40]
- [41]
-
[42]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[43]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.