Recognition: unknown
StateScribe: Towards Accessible Change Awareness Across Real-World Revisits
Pith reviewed 2026-05-08 05:39 UTC · model grok-4.3
The pith
StateScribe uses dual-layer memory to describe meaningful changes across revisits for blind and low-vision users.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
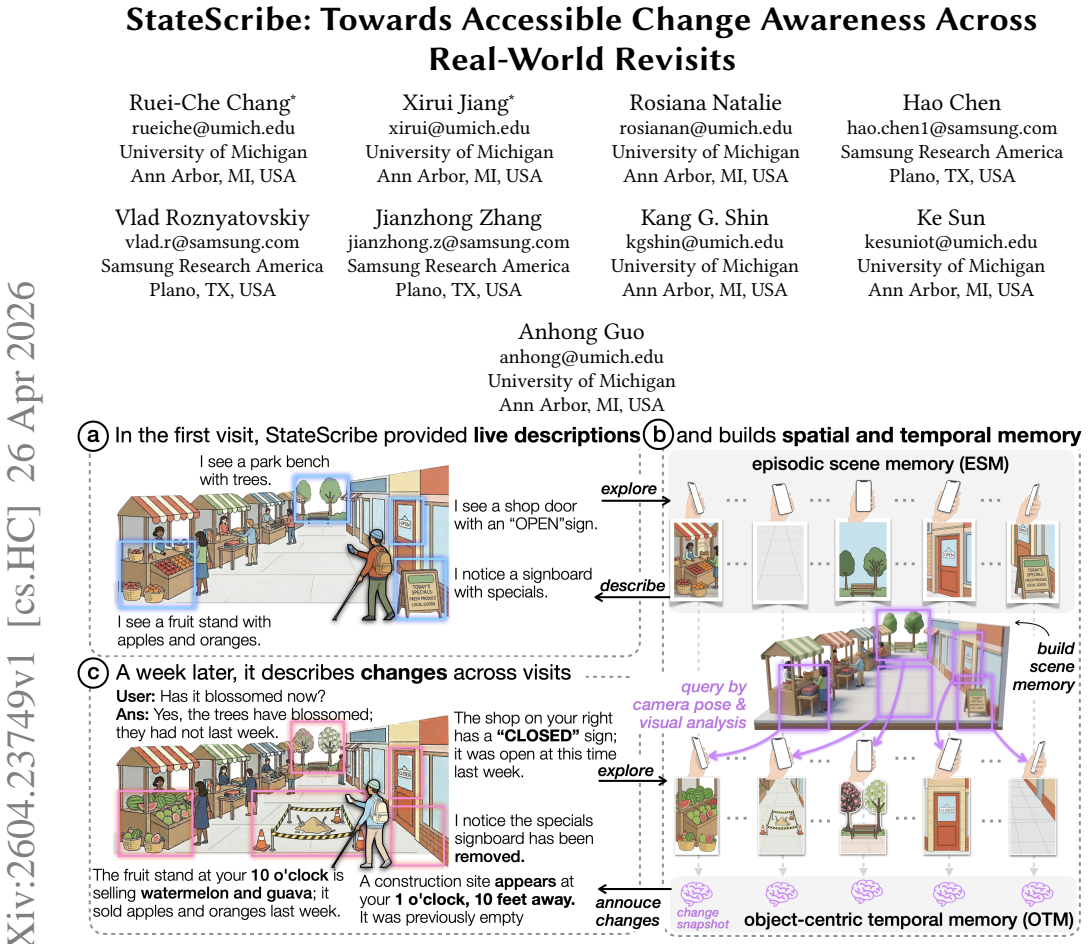
StateScribe employs a dual-layer memory architecture integrating episodic scene memory and object-centric temporal memory to enable scalable change tracking, delivering live scene descriptions alongside details of what has changed, when, and where across revisits.
What carries the argument
dual-layer memory architecture that combines episodic scene memory for overall context with object-centric temporal memory for tracking individual changes over time
If this is right
- Users receive both immediate scene descriptions and summaries of changes since previous visits.
- The system sustains high accuracy and low latency over repeated uses in the same locations.
- Memory usage stays low even after over 100 revisits, supporting long-term deployment.
- Participants in real-world tests report better awareness of updates like relocated objects or new signs.
Where Pith is reading between the lines
- Such memory systems could extend to other senses or multimodal data for more complete environmental monitoring.
- Personalization based on user habits or specific intents might reduce irrelevant change alerts over time.
- Integration with broader AI companions could allow proactive notifications about changes that affect safety or routines.
Load-bearing premise
The dual-layer memory architecture can consistently distinguish meaningful real-world changes from noise in diverse, uncontrolled environments without generating excessive false positives or missing important ones over extended periods.
What would settle it
Deploy StateScribe in a new, dynamic location with frequent minor alterations and measure whether accuracy drops below acceptable levels or users report missing critical changes like safety hazards.
Figures










read the original abstract
Real-world environments evolve continuously, yet blind and low-vision (BLV) individuals often have limited access to understanding how they change over time. Unexpected or relocated objects, layout modifications, and content updates (e.g., price changes) can introduce safety risks and cognitive burden. While existing visual assistive technologies can describe immediate surroundings, they operate as one-off interactions and lack mechanisms to surface meaningful changes across revisits. Informed by a survey of 33 BLV individuals, we develop StateScribe, a system that supports accessible awareness of real-world changes across revisits. StateScribe employs a dual-layer memory architecture that integrates episodic scene memory and object-centric temporal memory to enable scalable and structured change tracking. It provides both live descriptions of the current scene, and descriptions of what has changed, when and where it occurred across revisits, such as "The shop on your right has a "CLOSED" sign; it was open at this time last week.'' Our evaluation shows that StateScribe maintains high accuracy (F1-score=83.1%) across 11 revisits, while remaining low-latency (mean<1.54s) and memory-efficient (<54MB) across 110 revisits. A user study with nine BLV participants demonstrates that StateScribe improves change awareness across revisits in three real-world locations. Finally, we discuss implications for long-term AI-assisted companions that support broader change observation using multimodal sensing, extend beyond changes to other memory capabilities, and adapt to individual users, intents, and contexts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces StateScribe, a system to support blind and low-vision (BLV) users in maintaining awareness of real-world environmental changes across revisits. Informed by a survey of 33 BLV individuals, it employs a dual-layer memory architecture (episodic scene memory combined with object-centric temporal memory) to deliver live scene descriptions alongside change reports specifying what changed, when, and where (e.g., object relocations or content updates). Evaluation reports an F1-score of 83.1% for change detection across 11 revisits, mean latency below 1.54s, and memory usage under 54MB across 110 revisits. A user study with nine BLV participants in three real-world locations indicates improved change awareness.
Significance. If the performance and usability claims are substantiated, the work addresses a clear gap in assistive technologies by moving from one-off scene descriptions to longitudinal change tracking, with potential to reduce safety risks and cognitive burden for BLV users in dynamic environments. The dual-layer architecture provides a structured, scalable approach to memory that could inform future multimodal AI companions. The efficiency metrics support mobile feasibility, and grounding in user survey data strengthens relevance. The user study offers initial evidence of practical value, though broader validation would be needed for long-term deployment implications.
major comments (3)
- [Evaluation / Abstract] The headline F1-score of 83.1% for change detection (reported in the abstract and evaluation) rests on unstated criteria for labeling 'meaningful' changes and lacks any protocol for ground-truth annotation or inter-annotator agreement. Without these details, it is impossible to determine whether the dual-layer memory suppresses noise (lighting shifts, transient objects) or overfits to controlled test sequences, directly undermining the claim of reliability across real-world revisits.
- [Evaluation] No baseline comparisons are described against simpler single-layer memory, standard change-detection algorithms, or existing visual-assistive tools. This omission makes it impossible to attribute the reported accuracy, latency, and memory efficiency specifically to the episodic-plus-object-centric architecture rather than to the underlying vision models or test conditions.
- [User Study] The user study (nine BLV participants, three locations) claims improved change awareness but provides no details on task design, quantitative metrics, statistical tests, or qualitative coding of participant feedback. With such limited scale and diversity, the study cannot yet support generalizable conclusions about real-world utility.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly summarized the key survey findings that motivated the dual-layer design choices.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each of the major comments below and indicate the revisions we will make to improve clarity and rigor.
read point-by-point responses
-
Referee: [Evaluation / Abstract] The headline F1-score of 83.1% for change detection (reported in the abstract and evaluation) rests on unstated criteria for labeling 'meaningful' changes and lacks any protocol for ground-truth annotation or inter-annotator agreement. Without these details, it is impossible to determine whether the dual-layer memory suppresses noise (lighting shifts, transient objects) or overfits to controlled test sequences, directly undermining the claim of reliability across real-world revisits.
Authors: We agree that additional details are necessary to substantiate the F1-score. In the revised manuscript, we will expand the evaluation section to include: (1) explicit criteria for 'meaningful' changes, derived from our survey of BLV users (focusing on changes that impact navigation, safety, or awareness, such as object relocations and content updates, while excluding transient elements like lighting variations or moving people); (2) the ground-truth annotation protocol, which involved two researchers independently labeling changes in the revisit sequences with a consensus discussion for disagreements; and (3) inter-annotator agreement metrics (e.g., Cohen's kappa). This will demonstrate that the dual-layer architecture effectively filters noise rather than overfitting to controlled conditions. We will also clarify that the test sequences included real-world variability across 11 revisits in dynamic environments. revision: yes
-
Referee: [Evaluation] No baseline comparisons are described against simpler single-layer memory, standard change-detection algorithms, or existing visual-assistive tools. This omission makes it impossible to attribute the reported accuracy, latency, and memory efficiency specifically to the episodic-plus-object-centric architecture rather than to the underlying vision models or test conditions.
Authors: We acknowledge the value of baseline comparisons for isolating the contribution of the dual-layer architecture. In the revision, we will add a new subsection in the evaluation that includes comparisons against: (a) a single-layer memory baseline (using only episodic scene memory), (b) standard change detection methods such as pixel-wise differencing and feature-based approaches (e.g., using CLIP embeddings for similarity), and (c) a simulated existing visual-assistive tool that provides only live descriptions without change tracking. We will report accuracy, latency, and memory usage for these baselines under the same test conditions. This will help attribute performance gains to the object-centric temporal memory component. If space constraints arise, we will prioritize key metrics in the main text and move detailed tables to the appendix. revision: yes
-
Referee: [User Study] The user study (nine BLV participants, three locations) claims improved change awareness but provides no details on task design, quantitative metrics, statistical tests, or qualitative coding of participant feedback. With such limited scale and diversity, the study cannot yet support generalizable conclusions about real-world utility.
Authors: We agree that more details on the user study methodology are required. In the revised version, we will elaborate on: (1) task design, including the specific scenarios and change types presented to participants; (2) quantitative metrics used (e.g., accuracy in identifying changes, time to complete tasks, NASA-TLX for cognitive load); (3) statistical tests applied (e.g., paired t-tests or Wilcoxon signed-rank tests for pre/post comparisons); and (4) qualitative coding process for open-ended feedback, including themes identified and inter-coder reliability. We will also expand the discussion to explicitly address the limitations of the small sample size (n=9) and limited locations, framing the results as preliminary evidence and outlining plans for larger-scale studies. This will temper the claims appropriately while highlighting the positive trends observed. revision: yes
Circularity Check
No circularity detected; claims rest on external empirical evaluation and user study.
full rationale
The paper describes a dual-layer memory system for change awareness and reports performance via F1-score on 11 revisits, efficiency metrics across 110 revisits, and a 9-participant user study in three locations. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. All quantitative claims are evaluated against independent real-world revisit data and participant feedback rather than reducing to the system's own inputs or definitions by construction. The architecture is presented as an engineering design choice informed by a survey, with no load-bearing uniqueness theorems or ansatzes smuggled via self-citation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Real-world environments contain discrete, detectable changes that can be meaningfully described to users.
- domain assumption Multimodal sensing can capture sufficient state for change detection without continuous human annotation.
invented entities (1)
-
dual-layer memory architecture (episodic scene memory + object-centric temporal memory)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Introducing Be My AI (formerly Virtual Volunteer) for People who are Blind or Have Low Vision, Powered by OpenAI’s GPT-4
2023. Introducing Be My AI (formerly Virtual Volunteer) for People who are Blind or Have Low Vision, Powered by OpenAI’s GPT-4. https://www.bemyeyes. com/blog/introducing-be-my-eyes-virtual-volunteer
2023
-
[2]
2026. Aira. https://aira.io/
2026
-
[3]
BeMyEyes
2026. BeMyEyes. https://www.bemyeyes.com/
2026
-
[4]
Gemini Live
2026. Gemini Live. https://gemini.google/overview/gemini-live/
2026
-
[5]
SeeingAI
2026. SeeingAI. https://www.seeingai.com/
2026
-
[6]
Voice with real-time video in ChatGPT
2026. Voice with real-time video in ChatGPT. https://chatgpt.com/features/voice- with-video/
2026
-
[7]
Taslima Akter, Tousif Ahmed, Apu Kapadia, and Manohar Swaminathan. 2022. Shared Privacy Concerns of the Visually Impaired and Sighted Bystanders with Camera-Based Assistive Technologies.ACM Trans. Access. Comput.15, 2, Article 11 (May 2022), 33 pages. doi:10.1145/3506857
-
[8]
Samantha W. T. Chan. 2020. Biosignal-Sensitive Memory Improvement and Support Systems. InExtended Abstracts of the 2020 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI EA ’20). Association for Computing Machinery, New York, NY, USA, 1–7. doi:10.1145/3334480.3375031
-
[9]
Samantha W. T. Chan, Shardul Sapkota, Rebecca Mathews, Haimo Zhang, and Suranga Nanayakkara. 2020. Prompto: Investigating Receptivity to Prompts Based on Cognitive Load from Memory Training Conversational Agent.Proc. ACM Interact. Mob. Wearable Ubiquitous Technol.4, 4, Article 121 (Dec. 2020), 23 pages. doi:10.1145/3432190
-
[10]
Samantha W. T. Chan, Haimo Zhang, and Suranga Nanayakkara. 2019. Prospero: A Personal Wearable Memory Coach. InProceedings of the 10th Augmented Human International Conference 2019(Reims, France)(AH2019). Association for Computing Machinery, New York, NY, USA, Article 26, 5 pages. doi:10.1145/ 3311823.3311870
-
[11]
Ruei-Che Chang, Yuxuan Liu, and Anhong Guo. 2024. WorldScribe: Towards Context-Aware Live Visual Descriptions. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology(Pittsburgh, PA, USA)(UIST ’24). Association for Computing Machinery, New York, NY, USA, Article 140, 18 pages. doi:10.1145/3654777.3676375
-
[12]
Ruei-Che Chang, Yuxuan Liu, Lotus Zhang, and Anhong Guo. 2024. EditScribe: Non-Visual Image Editing with Natural Language Verification Loops. InPro- ceedings of the 26th International ACM SIGACCESS Conference on Computers and Accessibility(St. John’s, NL, Canada)(ASSETS ’24). Association for Computing Machinery, New York, NY, USA, Article 65, 19 pages. do...
-
[13]
Ruei-Che Chang, Rosiana Natalie, Wenqian Xu, Jovan Zheng Feng Yap, and Anhong Guo. 2025. Probing the Gaps in ChatGPT’s Live Video Chat for Real- World Assistance for People who are Blind or Visually Impaired. InProceedings of the 27th International ACM SIGACCESS Conference on Computers and Accessibility (ASSETS ’25). Association for Computing Machinery, N...
-
[14]
Ruei-Che Chang, Rosiana Natalie, Wenqian Xu, Jovan Zheng Feng Yap, Tiange Luo, Venkatesh Potluri, and Anhong Guo. 2026. TouchScribe: Augmenting Non- Visual Hand-Object Interactions with Automated Live Visual Descriptions. In Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems (CHI ’26). Association for Computing Machinery, New Yor...
-
[15]
Chufeng Chen, Michael Oakes, and John Tait. 2006. Browsing personal images using episodic memory (time+ location). InAdvances in Information Retrieval: 28th European Conference on IR Research, ECIR 2006, London, UK, April 10-12, 2006. Proceedings 28. Springer, 362–372
2006
-
[16]
Matthew Cooper, Jonathan Foote, Andreas Girgensohn, and Lynn Wilcox. 2005. Temporal event clustering for digital photo collections.ACM Trans. Multimedia Comput. Commun. Appl.1, 3 (Aug. 2005), 269–288. doi:10.1145/1083314.1083317
-
[17]
Laura Cushley, Neil Galway, and Tunde Peto. 2023. The unseen barriers of the built environment: navigation for people with visual impairment.Town planning review94, 1 (2023), 11–35
2023
-
[18]
Fatma El-Zahraa El-Taher, Luis Miralles-Pechuán, Jane Courtney, Kristina Millar, Chantelle Smith, and Susan Mckeever. 2023. A survey on outdoor navigation applications for people with visual impairments.IEEE Access11 (2023), 14647– 14666
2023
-
[19]
Martin Ester, Hans-Peter Kriegel, Jörg Sander, and Xiaowei Xu. 1996. A density- based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining(Portland, Oregon)(KDD’96). AAAI Press, 226–231
1996
-
[20]
Yue Fan, Xiaojian Ma, Rongpeng Su, Jun Guo, Rujie Wu, Xi Chen, and Qing Li
-
[21]
arXiv:2501.00358 [cs.CV] https://arxiv.org/abs/2501.00358
Embodied VideoAgent: Persistent Memory from Egocentric Videos and Em- bodied Sensors Enables Dynamic Scene Understanding. arXiv:2501.00358 [cs.CV] https://arxiv.org/abs/2501.00358
-
[22]
Maxwell Forbes, Christine Kaeser-Chen, Piyush Sharma, and Serge Belongie. 2019. Neural naturalist: Generating fine-grained image comparisons. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP- IJCNLP). 708–717
2019
-
[23]
Jim Gemmell, Lyndsay Williams, Ken Wood, Roger Lueder, and Gordon Bell. 2004. Passive capture and ensuing issues for a personal lifetime store. InProceedings of the the 1st ACM Workshop on Continuous Archival and Retrieval of Personal Experiences(New York, New York, USA)(CARPE’04). Association for Computing Machinery, New York, NY, USA, 48–55. doi:10.1145...
-
[24]
Rúben Gouveia and Evangelos Karapanos. 2013. Footprint tracker: supporting diary studies with lifelogging. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems(Paris, France)(CHI ’13). Association for Computing Machinery, New York, NY, USA, 2921–2930. doi:10.1145/2470654.2481405
-
[25]
Anhong Guo, Saige McVea, Xu Wang, Patrick Clary, Ken Goldman, Yang Li, Yu Zhong, and Jeffrey P. Bigham. 2018. Investigating Cursor-based Interactions to Support Non-Visual Exploration in the Real World. InProceedings of the 20th International ACM SIGACCESS Conference on Computers and Accessibility(Galway, Ireland)(ASSETS ’18). Association for Computing Ma...
-
[26]
Danna Gurari, Qing Li, Abigale J Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P Bigham. 2018. Vizwiz grand challenge: Answering visual questions from blind people. InProceedings of the IEEE conference on computer vision and pattern recognition. 3608–3617
2018
-
[27]
Gillian R Hayes, Shwetak N Patel, Khai N Truong, Giovanni Iachello, Julie A Kientz, Rob Farmer, and Gregory D Abowd. 2004. The personal audio loop: Designing a ubiquitous audio-based memory aid. InInternational Conference on Mobile Human-Computer Interaction. Springer, 168–179
2004
-
[28]
Jennifer Healey and Rosalind W Picard. 1998. Startlecam: A cybernetic wear- able camera. InDigest of Papers. Second International Symposium on Wearable Computers (Cat. No. 98EX215). IEEE, 42–49
1998
-
[29]
Naoki Hirabayashi, Masakazu Iwamura, Zheng Cheng, Kazunori Minatani, and Koichi Kise. 2023. VisPhoto: Photography for People with Visual Impairments via Post-Production of Omnidirectional Camera Imaging. InProceedings of the 25th International ACM SIGACCESS Conference on Computers and Accessibility (New York, NY, USA)(ASSETS ’23). Association for Computin...
-
[30]
Steve Hodges, Lyndsay Williams, Emma Berry, Shahram Izadi, James Srinivasan, Alex Butler, Gavin Smyth, Narinder Kapur, and Ken Wood. 2006. SenseCam: A retrospective memory aid. InUbiComp 2006: Ubiquitous Computing: 8th Interna- tional Conference, UbiComp 2006 Orange County, CA, USA, September 17-21, 2006 Proceedings 8. Springer, 177–193
2006
-
[31]
Tetsuro Hori and Kiyoharu Aizawa. 2003. Context-based video retrieval system for the life-log applications. InProceedings of the 5th ACM SIGMM International Workshop on Multimedia Information Retrieval(Berkeley, California)(MIR ’03). Association for Computing Machinery, New York, NY, USA, 31–38. doi:10.1145/ 973264.973270
-
[32]
Wenbo Hu, Yining Hong, Yanjun Wang, Leison Gao, Zibu Wei, Xingcheng Yao, Nanyun Peng, Yonatan Bitton, Idan Szpektor, and Kai-Wei Chang. 2025. 3DLLM- Mem: Long-Term Spatial-Temporal Memory for Embodied 3D Large Language Model. arXiv:2505.22657 [cs.CV] https://arxiv.org/abs/2505.22657
-
[33]
Mina Huh, Yi-Hao Peng, and Amy Pavel. 2023. GenAssist: Making Image Gen- eration Accessible. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology(San Francisco, CA, USA)(UIST ’23). Asso- ciation for Computing Machinery, New York, NY, USA, Article 38, 17 pages. doi:10.1145/3586183.3606735
-
[34]
Harsh Jhamtani and Taylor Berg-Kirkpatrick. 2018. Learning to describe differ- ences between pairs of similar images. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 4024–4034. 11 arXiv ’26, April, 2026 Chang and Jiang et al
2018
-
[35]
Shiqi Jiang, Zhenjiang Li, Pengfei Zhou, and Mo Li. 2019. Memento: An Emotion- driven Lifelogging System with Wearables.ACM Trans. Sen. Netw.15, 1, Article 8 (Jan. 2019), 23 pages. doi:10.1145/3281630
-
[36]
Doaa Khattab, Julie Buelow, and Donna Saccuteli. 2015. Understanding the barriers: Grocery stores and visually impaired shoppers.Journal of accessibility and design for all: JACCES5, 2 (2015), 157–173
2015
-
[37]
Marion Koelle, Torben Wallbaum, Wilko Heuten, and Susanne Boll. 2019. Evaluat- ing a Wearable Camera’s Social Acceptability In-the-Wild. InExtended Abstracts of the 2019 CHI Conference on Human Factors in Computing Systems(Glasgow, Scotland Uk)(CHI EA ’19). Association for Computing Machinery, New York, NY, USA, 1–6. doi:10.1145/3290607.3312837
-
[38]
Mik Lamming, Peter Brown, Kathleen Carter, Margery Eldridge, Mike Flynn, Gifford Louie, Peter Robinson, and Abigail Sellen. 1994. The design of a human memory prosthesis.Comput. J.37, 3 (1994), 153–163
1994
-
[39]
Kyungjun Lee, Jonggi Hong, Simone Pimento, Ebrima Jarjue, and Hernisa Kacorri
-
[40]
Revisiting Blind Photography in the Context of Teachable Object Recog- nizers. InProceedings of the 21st International ACM SIGACCESS Conference on Computers and Accessibility(Pittsburgh, PA, USA)(ASSETS ’19). Association for Computing Machinery, New York, NY, USA, 83–95. doi:10.1145/3308561.3353799
-
[41]
Kyungjun Lee and Hernisa Kacorri. 2019. Hands Holding Clues for Object Recog- nition in Teachable Machines. InProceedings of the 2019 CHI Conference on Human Factors in Computing Systems(Glasgow, Scotland Uk)(CHI ’19). Association for Computing Machinery, New York, NY, USA, 1–12. doi:10.1145/3290605.3300566
-
[42]
Kyungyeon Lee, Sohyeon Park, and Uran Oh. 2021. Designing Product De- scriptions for Supporting Independent Grocery Shopping of People with Visual Impairments. InExtended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems(Yokohama, Japan)(CHI EA ’21). Association for Computing Machinery, New York, NY, USA, Article 425, 6 pages. doi...
-
[43]
Matthew L. Lee and Anind K. Dey. 2007. Providing good memory cues for people with episodic memory impairment. InProceedings of the 9th International ACM SIGACCESS Conference on Computers and Accessibility(Tempe, Arizona, USA) (Assets ’07). Association for Computing Machinery, New York, NY, USA, 131–138. doi:10.1145/1296843.1296867
-
[44]
Matthew L. Lee and Anind K. Dey. 2008. Lifelogging memory appliance for people with episodic memory impairment. InProceedings of the 10th International Conference on Ubiquitous Computing(Seoul, Korea)(UbiComp ’08). Association for Computing Machinery, New York, NY, USA, 44–53. doi:10.1145/1409635.1409643
- [45]
-
[46]
Jongho Lim, Yongjae Yoo, Hanseul Cho, and Seungmoon Choi. 2019. TouchPhoto: Enabling Independent Picture Taking and Understanding for Visually-Impaired Users. In2019 International Conference on Multimodal Interaction(Suzhou, China) (ICMI ’19). Association for Computing Machinery, New York, NY, USA, 124–134. doi:10.1145/3340555.3353728
-
[47]
Roberto Manduchi and James M. Coughlan. 2014. The last meter: blind visual guidance to a target. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems(Toronto, Ontario, Canada)(CHI ’14). Association for Computing Machinery, New York, NY, USA, 3113–3122. doi:10.1145/2556288. 2557328
-
[48]
Steve Mann. 1998. ’WearCam’(The wearable camera): personal imaging systems for long-term use in wearable tetherless computer-mediated reality and personal photo/videographic memory prosthesis. InDigest of Papers. Second International Symposium on Wearable Computers (Cat. No. 98EX215). IEEE, 124–131
1998
-
[49]
Steve Mann, James Fung, Chris Aimone, Anurag Sehgal, and Daniel Chen. 2005. Designing EyeTap digital eyeglasses for continuous lifelong capture and sharing of personal experiences.Alt. Chi, Proc. CHI 2005(2005)
2005
-
[50]
Anushka Patil and Smruti Raghani. 2025. Designing accessible and independent living spaces for visually impaired individuals: a barrier-free approach to interior design.International Journal for Equity in Health24, 1 (2025), 137
2025
-
[51]
Yi-Hao Peng, Jason Wu, Jeffrey Bigham, and Amy Pavel. 2022. Diffscriber: Describ- ing Visual Design Changes to Support Mixed-Ability Collaborative Presentation Authoring. InProceedings of the 35th Annual ACM Symposium on User Interface Software and Technology(Bend, OR, USA)(UIST ’22). Association for Computing Machinery, New York, NY, USA, Article 35, 13 ...
-
[52]
Halley Profita, Reem Albaghli, Leah Findlater, Paul Jaeger, and Shaun K. Kane
-
[53]
The AT Effect: How Disability Affects the Perceived Social Acceptability of Head-Mounted Display Use. InProceedings of the 2016 CHI Conference on Human Factors in Computing Systems(San Jose, California, USA)(CHI ’16). Association for Computing Machinery, New York, NY, USA, 4884–4895. doi:10.1145/2858036. 2858130
-
[54]
Bradley J Rhodes. 1997. The wearable remembrance agent: A system for aug- mented memory.Personal Technologies1 (1997), 218–224
1997
-
[55]
Fiannaca, Melanie Kneisel, Edward Cutrell, and Meredith Ringel Morris
Manaswi Saha, Alexander J. Fiannaca, Melanie Kneisel, Edward Cutrell, and Meredith Ringel Morris. 2019. Closing the Gap: Designing for the Last-Few- Meters Wayfinding Problem for People with Visual Impairments. InProceedings of the 21st International ACM SIGACCESS Conference on Computers and Accessibility (Pittsburgh, PA, USA)(ASSETS ’19). Association for...
-
[56]
Yasuhito Sawahata and Kiyoharu Aizawa. 2003. Wearable imaging system for summarizing personal experiences. In2003 International Conference on Multime- dia and Expo. ICME’03. Proceedings (Cat. No. 03TH8698), Vol. 1. IEEE, I–45
2003
-
[57]
Oriane Siméoni, Huy V Vo, Maximilian Seitzer, Federico Baldassarre, and Maxime Oquab. 2025. Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.101042, 4 (2025), 5
work page internal anchor Pith review arXiv 2025
-
[58]
Kentaro Toyama, Ron Logan, and Asta Roseway. 2003. Geographic location tags on digital images. InProceedings of the eleventh ACM international conference on Multimedia. 156–166
2003
-
[59]
Sandra Tullio-Pow, Hong Yu, and Megan Strickfaden. 2021. Do You See What I See? The shopping experiences of people with visual impairment.Interdisci- plinary Journal of Signage and Wayfinding5, 1 (2021), 42–61
2021
-
[60]
Lily M Turkstra, Tanya Bhatia, Alexa Van Os, and Michael Beyeler. 2025. Assistive technology use in domestic activities by people who are blind.Scientific Reports 15, 1 (2025), 7486
2025
-
[61]
Marynel Vázquez and Aaron Steinfeld. 2012. Helping visually impaired users properly aim a camera. InProceedings of the 14th International ACM SIGACCESS Conference on Computers and Accessibility(Boulder, Colorado, USA)(ASSETS ’12). Association for Computing Machinery, New York, NY, USA, 95–102. doi:10.1145/ 2384916.2384934
-
[62]
Sunil Vemuri, Chris Schmandt, Walter Bender, Stefanie Tellex, and Brad Lassey
-
[63]
InUbiComp 2004: Ubiquitous Com- puting: 6th International Conference, Nottingham, UK, September 7-10, 2004
An audio-based personal memory aid. InUbiComp 2004: Ubiquitous Com- puting: 6th International Conference, Nottingham, UK, September 7-10, 2004. Pro- ceedings 6. Springer, 400–417
2004
-
[64]
Michele A. Williams, Amy Hurst, and Shaun K. Kane. 2013. "Pray before you step out": describing personal and situational blind navigation behaviors. In Proceedings of the 15th International ACM SIGACCESS Conference on Computers and Accessibility(Bellevue, Washington)(ASSETS ’13). Association for Computing Machinery, New York, NY, USA, Article 28, 8 pages....
-
[65]
Shaomei Wu, Jeffrey Wieland, Omid Farivar, and Julie Schiller. 2017. Automatic Alt-text: Computer-generated Image Descriptions for Blind Users on a Social Network Service. InProceedings of the 2017 ACM Conference on Computer Sup- ported Cooperative Work and Social Computing(Portland, Oregon, USA)(CSCW ’17). Association for Computing Machinery, New York, N...
-
[66]
Shuchang Xu, Chang Chen, Zichen Liu, Xiaofu Jin, Lin-Ping Yuan, Yukang Yan, and Huamin Qu. 2024. Memory Reviver: Supporting Photo-Collection Reminis- cence for People with Visual Impairment via a Proactive Chatbot. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (Pittsburgh, PA, USA)(UIST ’24). Association for Comp...
-
[67]
Hong Yu, Sandra Tullio-Pow, and Ammar Akhtar. 2015. Retail design and the visually impaired: A needs assessment.Journal of Retailing and Consumer Services 24 (2015), 121–129
2015
-
[68]
Lotus Zhang, Zhuohao (Jerry) Zhang, Gina Clepper, Franklin Mingzhe Li, Patrick Carrington, Jacob O. Wobbrock, and Leah Findlater. 2025. VizXpress: Towards Expressive Visual Content by Blind Creators Through AI Support. InProceedings of the 27th International ACM SIGACCESS Conference on Computers and Accessi- bility (ASSETS ’25). Association for Computing ...
-
[69]
Wobbrock, Anhong Guo, and Liang He
Zhuohao (Jerry) Zhang, Haichang Li, Chun Meng Yu, Faraz Faruqi, Junan Xie, Gene S-H Kim, Mingming Fan, Angus Forbes, Jacob O. Wobbrock, Anhong Guo, and Liang He. 2025. A11yShape: AI-Assisted 3-D Modeling for Blind and Low- Vision Programmers. InProceedings of the 27th International ACM SIGACCESS Con- ference on Computers and Accessibility (ASSETS ’25). As...
-
[70]
Zhuohao (Jerry) Zhang and Jacob O. Wobbrock. 2023. A11yBoard: Making Digital Artboards Accessible to Blind and Low-Vision Users. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany) (CHI ’23). Association for Computing Machinery, New York, NY, USA, Article 55, 17 pages. doi:10.1145/3544548.3580655
- [71]
- [72]
-
[73]
Wazeer Deen Zulfikar, Samantha Chan, and Pattie Maes. 2024. Memoro: Using Large Language Models to Realize a Concise Interface for Real-Time Memory Augmentation. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 450, 18 pages. doi:10.1...
-
[74]
If evidence is insufficient, output a static present-tense scene statement
-
[75]
the content of the screen has changed
If latest_live_description contains close-up details or readable on-object text, preserve those details exactly when you restate them. Do not rewrite the text content. Whenchange_snapshotsIs Empty •One to two sentences, natural spoken English, about 15 words total. •Present tense, static scene description only. •Mention at most 2–3 salient objects fromlat...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.