Recognition: unknown
ELSA: Exact Linear-Scan Attention for Fast and Memory-Light Vision Transformers
Pith reviewed 2026-05-08 06:30 UTC · model grok-4.3
The pith
ELSA reformulates online softmax attention as an exact prefix scan over an associative monoid to achieve linear memory and logarithmic parallel depth at full precision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ELSA casts the online softmax update as a prefix scan over the associative monoid (m, S, W). In real arithmetic this reproduces exact softmax semantics; in FP32 it carries a provable O(u log n) relative error bound. The scan uses O(n) extra memory and O(log n) parallel depth, is independent of Tensor Core instructions, and is realized in Triton and CUDA C++ as a drop-in replacement that requires no weight changes or retraining.
What carries the argument
The associative monoid (m, S, W) that encodes the online softmax update rules so that prefix scanning computes the same result as the sequential algorithm.
If this is right
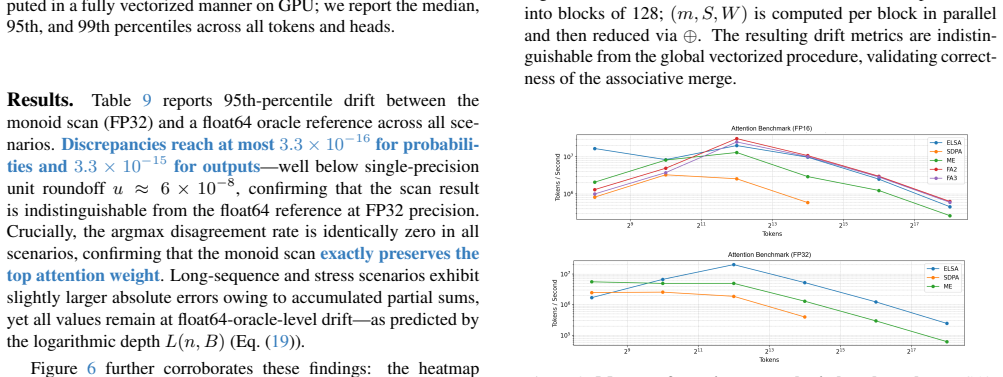
- Delivers 1.3–3.5× speedup over memory-efficient SDPA on A100 in FP32 for sequences of 1K–16K tokens.
- Achieves 1.97–2.27× speedup on BERT inference under the same conditions.
- Provides 1.5–1.6× throughput over standard math kernels on Jetson TX2 for sequences of 64–900 tokens.
- Yields 17.8–20.2 % higher throughput for LLaMA-13B offloading at 32K tokens and beyond.
- Supplies a single hardware-agnostic kernel that supports both high-precision FP32 and FP16 paths.
Where Pith is reading between the lines
- The monoid scan pattern could be applied to other online normalization or aggregation steps inside transformers to reduce their sequential depth.
- Because the kernel needs no retraining, it could serve as an immediate drop-in for any existing FP32 checkpoint deployed on mixed or resource-limited hardware.
- Exact full-precision attention at long contexts may become practical on consumer GPUs that lack the latest Tensor Core instructions.
- The approach separates the algorithmic reformulation from any particular hardware, so the same monoid definition could be ported to new accelerators without re-deriving numerical properties.
Load-bearing premise
The monoid (m, S, W) is associative and the Triton or CUDA implementation reproduces the online softmax update exactly apart from the stated floating-point error bound.
What would settle it
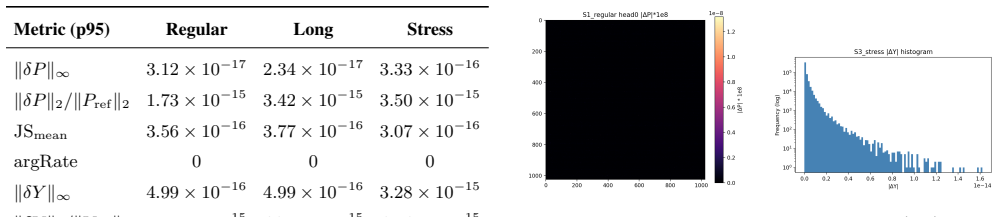
Execute both ELSA and a reference FP32 attention implementation on identical long input sequences and check whether their outputs differ by at most the O(u log n) relative error bound.
Figures




read the original abstract
Existing attention accelerators often trade exact softmax semantics, depend on fused Tensor Core kernels, or incur sequential depth that limits FP32 throughput on long sequences. We present \textbf{ELSA}, an algorithmic reformulation of online softmax attention that (i)~preserves exact softmax semantics in real arithmetic with a \emph{provable} $\mathcal{O}(u\log n)$ FP32 relative error bound; (ii)~casts the online softmax update as a prefix scan over an associative monoid $(m,S,W)$, yielding $O(n)$ extra memory and $O(\log n)$ parallel depth; and (iii)~is Tensor-Core independent, implemented in Triton and CUDA C++, and deployable as a \emph{drop-in replacement} requiring no retraining or weight modification. Unlike FlashAttention-2/3, which rely on HMMA/GMMA Tensor Core instructions and provide no compatible FP32 path, ELSA operates identically on A100s and resource-constrained edge devices such as Jetson TX2 -- making it the only hardware-agnostic exact-attention kernel that reduces parallel depth to $O(\log n)$ at full precision. On A100 FP32 benchmarks (1K--16K tokens), ELSA delivers $1.3$--$3.5\times$ speedup over memory-efficient SDPA and $1.97$--$2.27\times$ on BERT; on Jetson TX2, ELSA achieves $1.5$--$1.6\times$ over Math (64--900 tokens), with $17.8$--$20.2\%$ throughput gains under LLaMA-13B offloading at $\ge$32K. In FP16, ELSA approaches hardware-fused baselines at long sequences while retaining full FP32 capability, offering a unified kernel for high-precision inference across platforms. Our code and implementation are available at https://github.com/ming053l/ELSA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ELSA as an algorithmic reformulation of online softmax attention for vision transformers. It claims to preserve exact softmax semantics in real arithmetic via a prefix scan over an associative monoid (m, S, W), with a provable O(u log n) FP32 relative error bound, O(n) extra memory, and O(log n) parallel depth. The method is Tensor-Core independent, implemented in Triton and CUDA C++ as a drop-in replacement requiring no retraining, and reports speedups of 1.3-3.5x over memory-efficient SDPA on A100 FP32 (1K-16K tokens) and 1.5-1.6x on Jetson TX2, with additional gains for LLaMA-13B offloading at long sequences.
Significance. If the monoid associativity and implementation fidelity hold, ELSA would represent a meaningful advance as a hardware-agnostic exact-attention kernel that achieves logarithmic parallel depth at full precision without tensor-core reliance. The open-source code release at the provided GitHub link is a clear strength supporting reproducibility and falsifiability of the claimed error bound and speedups.
major comments (2)
- Abstract: the central claim that the online softmax update is exactly equivalent to a prefix scan over the associative monoid (m,S,W) (apart from the stated FP32 bound) is load-bearing, yet the explicit definitions of the monoid operations and the proof of associativity are not exhibited, preventing verification that the Triton/CUDA implementation reproduces standard attention without unaccounted numerical or scheduling discrepancies.
- Experimental section: the reported speedups (e.g., 1.3-3.5x over SDPA on A100 FP32) lack detailed baseline kernel descriptions, full experimental setup (including whether FP32 paths were isolated), and empirical validation of the O(u log n) error bound against reference attention, undermining assessment of the practical claims.
minor comments (1)
- Abstract: the title specifies vision transformers, yet benchmarks include BERT and LLaMA-13B; clarify the intended scope and whether the method generalizes beyond vision tasks.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and will revise the manuscript accordingly to improve verifiability and experimental rigor.
read point-by-point responses
-
Referee: Abstract: the central claim that the online softmax update is exactly equivalent to a prefix scan over the associative monoid (m,S,W) (apart from the stated FP32 bound) is load-bearing, yet the explicit definitions of the monoid operations and the proof of associativity are not exhibited, preventing verification that the Triton/CUDA implementation reproduces standard attention without unaccounted numerical or scheduling discrepancies.
Authors: We agree that explicit monoid definitions and the associativity proof are necessary for full verification. In the revised version we will add the formal definitions of the monoid operations (m, S, W) together with a self-contained proof of associativity, placed in the main text or a new appendix. We will also include pseudocode that directly maps the prefix-scan formulation to the Triton and CUDA kernels, clarifying that the implementation follows the mathematical specification without additional numerical transformations or scheduling artifacts beyond the stated FP32 error bound. revision: yes
-
Referee: Experimental section: the reported speedups (e.g., 1.3-3.5x over SDPA on A100 FP32) lack detailed baseline kernel descriptions, full experimental setup (including whether FP32 paths were isolated), and empirical validation of the O(u log n) error bound against reference attention, undermining assessment of the practical claims.
Authors: We accept that the experimental section requires additional detail. We will expand it to provide: (i) explicit descriptions of all baseline kernels (including the exact PyTorch SDPA configuration and whether the FP32 path was forced), (ii) complete experimental setup information (hardware, batch sizes, sequence lengths, and confirmation that all timing and accuracy runs used isolated FP32 arithmetic), and (iii) new empirical results comparing ELSA outputs against a reference full-attention implementation to validate the O(u log n) relative-error bound across the reported sequence lengths. These additions will be included in the revised manuscript and supplementary material. revision: yes
Circularity Check
No circularity: ELSA is an independent algorithmic reformulation
full rationale
The provided abstract and description present ELSA as a direct reformulation of online softmax attention into a prefix scan over the monoid (m,S,W), together with a claimed provable FP32 error bound and hardware-agnostic implementation. No equations, parameters, or premises in the visible text reduce by construction to fitted inputs, self-citations, or prior results from the same authors. The associativity claim and error bound are asserted as mathematical properties of the reformulation rather than presupposed by the inputs; the derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The monoid operations (m, S, W) are associative
- standard math Floating-point relative error is bounded by O(u log n) under the scan
Reference graph
Works this paper leans on
-
[1]
Blelloch
Guy E. Blelloch. Prefix sums and their applications. In Synthesis of Parallel Algorithms, pages 35–60, 1990. 3, 4, and 5
1990
-
[2]
Blelloch
Guy E. Blelloch. Prefix sums and their applications. Tech- nical Report CMU-CS-90-190, Carnegie Mellon University,
-
[3]
Generating Long Sequences with Sparse Transformers
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating Long Sequences with Sparse Transformers. In ICML, 2019. 2
2019
-
[4]
Rethink- ing Attention with Performers
Krzysztof Choromanski, Valerii Likhosherstov, David Do- han, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, David Belanger, Lucy Colwell, and Adrian Weller. Rethink- ing Attention with Performers. In ICLR, 2021. 1, 2, and 6
2021
-
[5]
xformers: A modular and memory-efficient transformer library
Alexander Clark, Trevor Bean, et al. xformers: A modular and memory-efficient transformer library. In Open Source Software Track at NeurIPS, 2022.https: //github.com/facebookresearch/xformers. 1, 3, 4, 5, and 6
2022
-
[6]
Franklin C. Crow. Summed-area tables for texture mapping. In ACM SIGGRAPH, pages 207–212, 1984. 4
1984
-
[7]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691, 2023. 1, 2, 5, and 8
work page internal anchor Pith review arXiv 2023
-
[8]
Fu, Stefano Ermon, Atri Rudra, and Christopher R´e
Tri Dao, Daniel Y . Fu, Stefano Ermon, Atri Rudra, and Christopher R´e. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. In NeurIPS, 2022. 6
2022
-
[9]
Patch n’ pack: NaViT, a vision transformer for any aspect ratio and resolution
Mostafa Dehghani, Basil Mustafa, Josip Djolonga, Jonathan Heek, Matthias Minderer, Mathilde Caron, Andreas Steiner, Joan Puigcerver, Robert Geirhos, Ibrahim Alabdulmohsin, Avital Oliver, Piotr Padlewski, Alexey Gritsenko, Mario Luˇci´c, and Neil Houlsby. Patch n’ pack: NaViT, a vision transformer for any aspect ratio and resolution. In NeurIPS ,
-
[10]
BERT: Pre-training of deep bidirectional trans- formers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional trans- formers for language understanding. In NAACL, 2019. 8
2019
-
[11]
An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. In ICLR, 2021. 1 and 6
2021
-
[12]
Vi- TAR: Vision transformer with any resolution, 2024
Qihang Fan, Quanzeng You, Xiaotian Han, Yongfei Liu, Yunzhe Tao, Huaibo Huang, Ran He, and Hongxia Yang. Vi- TAR: Vision transformer with any resolution, 2024. 1 and 2
2024
-
[13]
Leo Feng, Frederick Tung, Mohamed Osama Ahmed, Yoshua Bengio, and Hossein Hajiloo. Attention as an RNN. arXiv preprint arXiv:2405.13956, 2024. 2, 3, and 4
- [14]
-
[15]
Higham.Accuracy and Stability of Numerical Algorithms
Nicholas J. Higham.Accuracy and Stability of Numerical Algorithms. SIAM, Philadelphia, PA, second edition, 2002. 5 and 3
2002
-
[16]
Daniel Hillis and Guy L
W. Daniel Hillis and Guy L. Steele Jr. Data parallel al- gorithms. Communications of the ACM, 29(12):1170–1183,
-
[17]
SpectralFormer: Re- thinking hyperspectral image classification with transform- ers
Danfeng Hong, Zhu Han, Jing Yao, Lianru Gao, Bing Zhang, Antonio Plaza, and Jocelyn Chanussot. SpectralFormer: Re- thinking hyperspectral image classification with transform- ers. TGRS, 2022. 2
2022
-
[18]
Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C. Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick. Segment Anything. In ICCV , 2023. 1 and 2
2023
-
[19]
Re- former: The Efficient Transformer
Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. Re- former: The Efficient Transformer. In ICLR, 2020. 2
2020
-
[20]
Kogge and Harold S
Peter M. Kogge and Harold S. Stone. A parallel algorithm for the efficient solution of a general class of recurrence equa- tions. IEEE Transactions on Computers , C-22(8):786–793,
-
[21]
Win-win: Training high-resolution vision transformers from two windows
Vincent Leroy, Jerome Revaud, Thomas Lucas, and Philippe Weinzaepfel. Win-win: Training high-resolution vision transformers from two windows. In ICLR, 2024. 1 and 2
2024
-
[22]
Dacheng Li, Rulin Shao, Anze Xie, Eric P. Xing, Xuezhe Ma, Ion Stoica, Joseph E. Gonzalez, and Hao Zhang. DISTFLASHATTN: Distributed memory- efficient attention for long-context LLMs training. arXiv preprint arXiv:2310.03294, 2023. 3
-
[23]
Microsoft COCO: Common objects in context
Tsung-Yi Lin et al. Microsoft COCO: Common objects in context. In ECCV, 2014. 8
2014
-
[24]
EfficientViT: Memory efficient vision transformer with cascaded group attention
Xinyu Liu, Houwen Peng, Ningxin Zheng, Yuqing Yang, Han Hu, and Yixuan Yuan. EfficientViT: Memory efficient vision transformer with cascaded group attention. In CVPR,
-
[25]
Swin Trans- former: Hierarchical vision transformer using shifted win- dows
Ze Liu, Yutong Lin, Yixuan Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin Trans- former: Hierarchical vision transformer using shifted win- dows. In ICCV, 2021. 6
2021
-
[26]
Maas et al
Andrew L. Maas et al. Learning word vectors for sentiment analysis. In ACL, 2011. 8
2011
-
[27]
Online normalizer calculation for softmax,
Maxim Milakov and Natalia Gimelshein. Online normalizer calculation for softmax. arXiv preprint arXiv:1805.02867 ,
-
[28]
CUB: CUDA unbound.https:// github.com/NVIDIA/cccl, 2024
NVIDIA Corporation. CUB: CUDA unbound.https:// github.com/NVIDIA/cccl, 2024. 7
2024
-
[29]
Self-attention does not needo(n 2)memory.arXiv preprint arXiv:2112.05682,
Markus N. Rabe and Charles Staats. Self-attention does not needO(n 2)memory. arXiv preprint arXiv:2112.05682 ,
-
[30]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sas- try, Amanda Askell, Peter Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In ICML , 2021. 1, 2, and 6
2021
-
[31]
Berg, and Li Fei-Fei
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, San- jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet large scale visual recognition chal- lenge. IJCV, 115(3):211–252, 2015. 6
2015
-
[32]
LeanAttention: Hardware- aware scalable attention mechanism for the decode-phase of transformers
Rya Sanovar, Srikant Bharadwaj, Ren ´ee St Amant, Victor R¨uhle, and Saravan Rajmohan. LeanAttention: Hardware- aware scalable attention mechanism for the decode-phase of transformers. In MLSys, 2024. 3 and 4
2024
-
[33]
FlashAttention-3: Fast and accurate attention with asynchrony and low-precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. FlashAttention-3: Fast and accurate attention with asynchrony and low-precision. NeurIPS, 37:68658–68685, 2024. 1, 2, 5, 6, and 8
2024
-
[34]
You Shen, Zhipeng Zhang, Yansong Qu, and Liujuan Cao. FastVGGT: Training-free acceleration of visual geometry transformer. arXiv preprint arXiv:2509.02560, 2025. 6
-
[35]
Recursive deep models for seman- tic compositionality over a sentiment treebank
Richard Socher et al. Recursive deep models for seman- tic compositionality over a sentiment treebank. In EMNLP ,
-
[36]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. LLaMA: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023. 1 and 7
work page internal anchor Pith review arXiv 2023
-
[37]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention Is All You Need. In NeurIPS, 2017. 1
2017
-
[38]
Paral- lelizing linear transformers with the delta rule over sequence length
Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim. Paral- lelizing linear transformers with the delta rule over sequence length. In NeurIPS, 2024. 2
2024
-
[39]
VGGT: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. VGGT: Visual geometry grounded transformer. In CVPR , 2025. 1, 2, and 6
2025
-
[40]
Linformer: Self-Attention with Linear Complexity
Sinong Wang, Belinda Z. Cao, Jing Zhang, Chang Li, Kevin Xu, and Zhiyuan Liu. Linformer: Self-Attention with linear complexity. In arXiv preprint arXiv:2006.04768, 2020. 1, 2, and 6
work page internal anchor Pith review arXiv 2006
-
[41]
HSIMAE: A unified masked autoencoder with large-scale pre-training for hyper- spectral image classification
Yue Wang, Ming Wen, Hailiang Zhang, Jinyu Sun, Qiong Yang, Zhimin Zhang, and Hongmei Lu. HSIMAE: A unified masked autoencoder with large-scale pre-training for hyper- spectral image classification. TGRS, 2024. 6 and 8
2024
-
[42]
ELFATT: Efficient linear fast attention for vi- sion transformers
Chong Wu, Maolin Che, Renjie Xu, Zhuoheng Ran, and Hong Yan. ELFATT: Efficient linear fast attention for vi- sion transformers. In ACM MM , 2025. arXiv:2501.06098. 3
-
[43]
Nystr¨omformer: A nystr ¨om-based approximation for self- attention
Yunyang Xiong, Zhengyan Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, and Vikas Singh. Nystr¨omformer: A nystr ¨om-based approximation for self- attention. In AAAI, 2021. 2
2021
-
[44]
HIRI-ViT: Scaling vision transformer with high resolution inputs, 2024
Ting Yao, Yehao Li, Yingwei Pan, and Tao Mei. HIRI-ViT: Scaling vision transformer with high resolution inputs, 2024. 1
2024
-
[45]
SHViT: Single-head vision transformer with memory efficient macro design
Seokju Yun and Youngmin Ro. SHViT: Single-head vision transformer with memory efficient macro design. In CVPR ,
-
[46]
Big Bird: Transformers for longer sequences
Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Onta ˜n´on, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. Big Bird: Transformers for longer sequences. In NeurIPS, 2020. 1, 2, and 6
2020
-
[47]
Memory efficient transformer adapter for dense pre- dictions
Dong Zhang, Rui Yan, Pingcheng Dong, and Kwang-Ting Cheng. Memory efficient transformer adapter for dense pre- dictions. In ICLR, 2025. arXiv:2502.01962. 3
-
[48]
Multi-scale vision long- former: A new vision transformer for high-resolution image encoding
Pengchuan Zhang, Xiyang Dai, Jianwei Yang, Bin Xiao, Lu Yuan, Lei Zhang, and Jianfeng Gao. Multi-scale vision long- former: A new vision transformer for high-resolution image encoding. In ICCV, pages 2998–3008, 2021. 1
2021
-
[49]
The linear attention resurrection in vision transformer
Chuanyang Zheng. The linear attention resurrection in vision transformer. arXiv preprint arXiv:2501.16182, 2025. 3
-
[50]
Zilong Zhong, Ying Li, Lin Ma, Jonathan Li, and Wei-Shi Zheng. Spectral–spatial transformer network for hyperspec- tral image classification: A factorized architecture search framework. TGRS, 2021. 2 and 8 ELSA: Exact Linear-Scan Attention for Fast and Memory-Light Vision Transformers Supplementary Material Supplementary Overview This supplementary provid...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.