Recognition: unknown
JigsawRL: Assembling RL Pipelines for Efficient LLM Post-Training
Pith reviewed 2026-05-08 06:32 UTC · model grok-4.3
The pith
JigsawRL assembles efficient RL pipelines for LLM post-training by decomposing stages into sub-graphs and applying dynamic multiplexing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
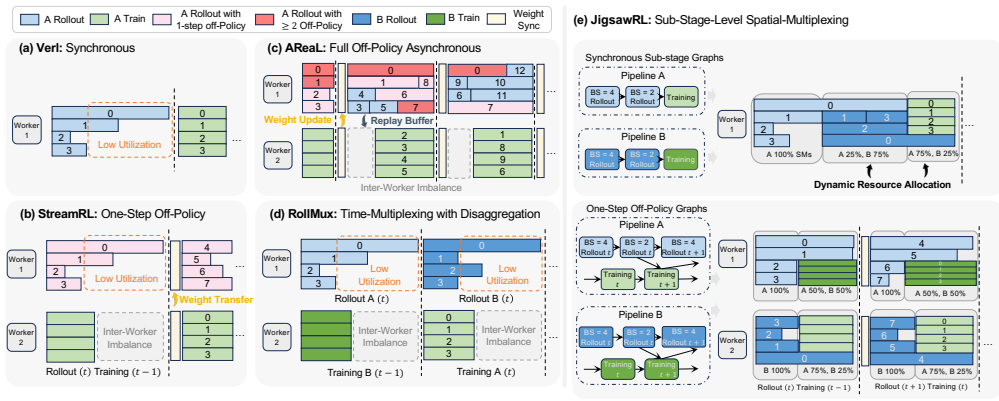
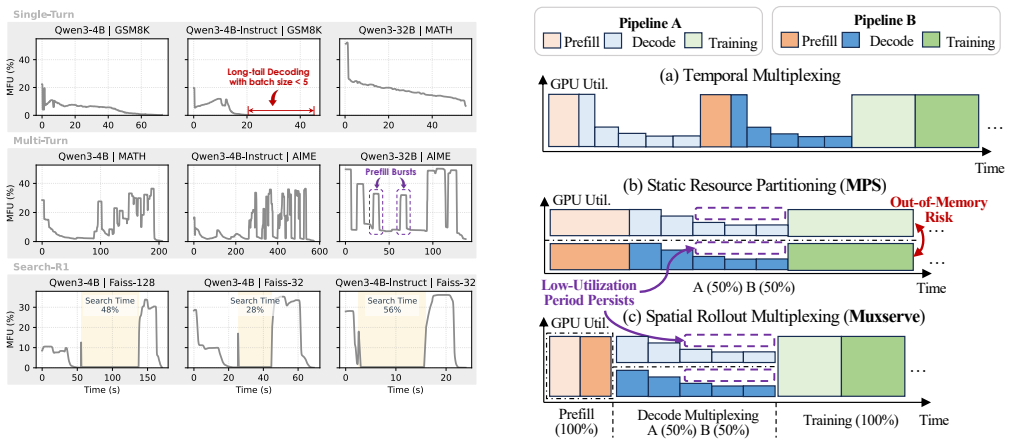
JigsawRL decomposes each RL pipeline into a Sub-Stage Graph to expose hidden imbalances, resolves multiplexing interference through dynamic resource allocation, eliminates fragmented utilization by migrating long-tail rollouts across workers, and formulates coordination as a graph scheduling problem solved with a look-ahead heuristic, delivering up to 1.85x throughput over Verl on synchronous RL and 1.54x over StreamRL and AReaL on asynchronous RL across 4-64 H100/A100 GPUs.
What carries the argument
The Sub-Stage Graph abstraction that breaks down pipeline stages to expose imbalances, paired with dynamic resource allocation, long-tail rollout migration, and look-ahead heuristic scheduling to manage pipeline multiplexing.
If this is right
- JigsawRL achieves up to 1.85x higher throughput than Verl in synchronous RL pipelines.
- It delivers up to 1.54x throughput gains over StreamRL and AReaL in asynchronous RL.
- The framework supports heterogeneous RL pipelines with only moderate increases in latency.
- Improved GPU utilization reduces the hardware requirements for large-scale LLM post-training.
- Pipeline multiplexing becomes a viable new dimension for parallelism in RL systems.
Where Pith is reading between the lines
- This method could be extended to other distributed ML training workflows with imbalanced stages.
- Better sub-stage visibility might inspire similar fine-grained scheduling in non-RL LLM inference serving.
- Testing on even larger GPU counts or more diverse models could reveal scalability limits of the heuristic.
- The approach highlights the potential for adaptive scheduling to handle variability in rollout lengths.
Load-bearing premise
The Sub-Stage Graph accurately captures all relevant imbalances and the dynamic allocation plus look-ahead scheduling can fix interference and long-tail issues with only moderate overhead and without introducing instability.
What would settle it
Running the system on pipelines with extreme rollout length variations or scaling to hundreds of GPUs and checking if the reported speedups hold or if overheads and instability appear.
Figures














read the original abstract
We present JigsawRL, a cost-efficient framework that explores Pipeline Multiplexing as a new dimension of RL parallelism. JigsawRL decomposes each pipeline into a Sub-Stage Graph that exposes the intra-stage and inter-worker imbalance hidden by stage-level systems. On this abstraction, JigsawRL resolves multiplexing interference through dynamic resource allocation, eliminates fragmented utilization by migrating long-tail rollouts across workers, and formulates their coordination as a graph scheduling problem solved with a look-ahead heuristic. On 4-64 H100/A100 GPUs across different agentic RL pipelines and models, JigsawRL achieves up to 1.85x throughput over Verl on synchronous RL, 1.54x over StreamRL and AReaL on asynchronous RL, and supports heterogeneous pipelines with moderate latency trade-off.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces JigsawRL, a framework for efficient LLM post-training via reinforcement learning that treats pipeline multiplexing as a new parallelism dimension. It decomposes RL pipelines into a Sub-Stage Graph to reveal intra-stage and inter-worker imbalances, applies dynamic resource allocation to resolve multiplexing interference, uses migration of long-tail rollouts to reduce fragmentation, and solves the resulting coordination via a graph scheduling problem with a look-ahead heuristic. Empirical results on 4-64 H100/A100 GPUs across agentic RL pipelines and models report up to 1.85x throughput gains versus Verl (synchronous) and 1.54x versus StreamRL/AReaL (asynchronous), plus support for heterogeneous pipelines at moderate latency cost.
Significance. If the throughput claims hold under rigorous controls, JigsawRL would represent a practical advance in systems for RL-based LLM post-training by improving GPU utilization through fine-grained multiplexing rather than stage-level parallelism. The empirical evaluation across multiple pipelines and scales is a strength, as is the focus on real hardware (H100/A100) and heterogeneous setups. However, the absence of worst-case analysis for the scheduling heuristic limits the result's generality beyond the tested workloads.
major comments (3)
- [Abstract / Experimental results] Abstract and experimental evaluation (throughput claims): the headline speedups (1.85x vs Verl, 1.54x vs StreamRL/AReaL) are reported without any information on run-to-run variance, statistical tests, baseline re-implementations, or controls for confounding factors such as model size, rollout length distribution, or batching strategy. This is load-bearing because the central contribution is an empirical systems improvement whose validity rests on these numbers.
- [Sub-Stage Graph and scheduling formulation] Section on Sub-Stage Graph and look-ahead heuristic: no worst-case analysis, convergence bound, or overhead characterization is provided for the dynamic allocation and migration decisions. The claim that these resolve multiplexing interference and long-tail effects with only moderate latency trade-off therefore rests entirely on the specific agentic pipelines tested; heavier-tailed rollout lengths could invalidate the moderate-overhead assertion.
- [Heterogeneous pipeline experiments] Heterogeneous pipeline support: the paper asserts that JigsawRL handles heterogeneous pipelines with moderate latency trade-off, yet no quantitative breakdown (e.g., per-pipeline latency histograms or migration frequency) is supplied to substantiate the trade-off magnitude or stability across differing pipeline compositions.
minor comments (2)
- [Sub-Stage Graph definition] Notation for the Sub-Stage Graph (nodes, edges, and resource attributes) should be defined more explicitly with a small example diagram or table to aid readability.
- [Conclusion / Experiments] The manuscript would benefit from a reproducibility statement indicating whether code, configuration files, or exact workload traces will be released.
Simulated Author's Rebuttal
We are grateful to the referee for their thorough review and valuable suggestions. We have carefully considered each major comment and provide point-by-point responses below, along with planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract / Experimental results] Abstract and experimental evaluation (throughput claims): the headline speedups (1.85x vs Verl, 1.54x vs StreamRL/AReaL) are reported without any information on run-to-run variance, statistical tests, baseline re-implementations, or controls for confounding factors such as model size, rollout length distribution, or batching strategy. This is load-bearing because the central contribution is an empirical systems improvement whose validity rests on these numbers.
Authors: We thank the referee for highlighting this important aspect of empirical validation. While the experimental setup in Section 5 describes the model sizes, rollout length distributions, and batching strategies employed, we acknowledge the lack of reported run-to-run variance and statistical tests. In the revised manuscript, we will include error bars representing standard deviations from at least three independent runs for each throughput measurement and add a note on the baseline re-implementations to improve transparency and address potential confounding factors. revision: yes
-
Referee: [Sub-Stage Graph and scheduling formulation] Section on Sub-Stage Graph and look-ahead heuristic: no worst-case analysis, convergence bound, or overhead characterization is provided for the dynamic allocation and migration decisions. The claim that these resolve multiplexing interference and long-tail effects with only moderate latency trade-off therefore rests entirely on the specific agentic pipelines tested; heavier-tailed rollout lengths could invalidate the moderate-overhead assertion.
Authors: We concur that a formal worst-case analysis or convergence bound for the look-ahead heuristic is not included in the current manuscript. Developing such bounds for a practical heuristic operating under dynamic conditions with variable rollout lengths is non-trivial and may not yield tight results. We will revise the paper to include a characterization of the scheduling and migration overheads based on our measurements, along with a discussion of the heuristic's behavior and potential limitations under heavier-tailed distributions. This will better contextualize the empirical results. revision: partial
-
Referee: [Heterogeneous pipeline experiments] Heterogeneous pipeline support: the paper asserts that JigsawRL handles heterogeneous pipelines with moderate latency trade-off, yet no quantitative breakdown (e.g., per-pipeline latency histograms or migration frequency) is supplied to substantiate the trade-off magnitude or stability across differing pipeline compositions.
Authors: We will update the heterogeneous pipeline experiments to provide the requested quantitative details. Specifically, we plan to add latency histograms for individual pipelines and report migration frequencies along with their contribution to the observed latency trade-off. These additions will offer a more rigorous substantiation of the moderate overhead in heterogeneous settings. revision: yes
- Formal worst-case analysis or convergence bounds for the dynamic scheduling heuristic
Circularity Check
No circularity: empirical systems framework with direct benchmark measurements
full rationale
The paper introduces JigsawRL as a practical framework for decomposing RL pipelines into a Sub-Stage Graph and applying dynamic allocation plus look-ahead scheduling. All performance claims (throughput gains versus Verl, StreamRL, AReAL) are presented as direct empirical results measured on 4-64 H100/A100 GPUs across concrete agentic workloads and models. No equations, derivations, fitted parameters, or first-principles predictions appear; the central claims rest on runtime observations rather than any reduction to inputs by construction. No self-citation chains or imported uniqueness theorems are load-bearing. The work is therefore self-contained against external baselines.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
FlashEvolve: Accelerating Agent Self-Evolution with Asynchronous Stage Orchestration
FlashEvolve accelerates LLM agent self-evolution via asynchronous stage orchestration and inspectable language-space staleness handling, reporting 3.5-4.9x proposal throughput gains over synchronous baselines on GEPA ...
Reference graph
Works this paper leans on
-
[1]
https://github.com/NVIDIA-NeMo/RL, 2025
Nemo rl: A scalable and efficient post-training li- brary. https://github.com/NVIDIA-NeMo/RL, 2025. GitHub repository
2025
-
[2]
https://www.aicerts.ai/news/alibaba-qwen- model-downloads-metrics-and-enterprise-impact/, 2026
Alibaba qwen model downloads: Metrics and enterprise impact. https://www.aicerts.ai/news/alibaba-qwen- model-downloads-metrics-and-enterprise-impact/, 2026
2026
-
[3]
Lmrl gym: Benchmarks for multi-turn reinforcement learning with language models, 2023
Marwa Abdulhai, Isadora White, Charlie Snell, Charles Sun, Joey Hong, Yuexiang Zhai, Kelvin Xu, and Sergey Levine. Lmrl gym: Benchmarks for multi-turn reinforce- ment learning with language models.arXiv preprint arXiv:2311.18232, 2023
-
[4]
Amazon EC2 On-Demand Pricing
Amazon Web Services. Amazon EC2 On-Demand Pricing. https://aws.amazon.com/ec2/pricing/ on-demand/. Accessed: 2026-03-21
2026
-
[5]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforce- ment learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review arXiv 2022
-
[6]
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, An- drew McNamara, Bhaskar Mitra, Tri Nguyen, et al. Ms marco: A human generated machine reading comprehen- sion dataset.arXiv preprint arXiv:1611.09268, 2016
work page internal anchor Pith review arXiv 2016
-
[7]
Respec: Towards optimizing speculative decoding in reinforcement learning systems
Qiaoling Chen, Zijun Liu, Peng Sun, Shenggui Li, Guoteng Wang, Ziming Liu, Yonggang Wen, Siyuan Feng, and Tianwei Zhang. Respec: Towards optimizing speculative decoding in reinforcement learning systems. arXiv preprint arXiv:2510.26475, 2025
-
[8]
Yixing Chen, Yiding Wang, Siqi Zhu, Haofei Yu, Tao Feng, Muhan Zhang, Mostofa Patwary, and Jiaxuan You. Multi-agent evolve: Llm self-improve through co-evolution.arXiv preprint arXiv:2510.23595, 2025
-
[9]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plap- pert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review arXiv 2021
-
[10]
The faiss library.IEEE Transactions on Big Data, 2025
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. The faiss library.IEEE Transactions on Big Data, 2025
2025
-
[11]
Jiangfei Duan, Runyu Lu, Haojie Duanmu, Xiuhong Li, Xingcheng Zhang, Dahua Lin, Ion Stoica, and Hao Zhang. Muxserve: flexible spatial-temporal multi- plexing for multiple llm serving.arXiv preprint arXiv:2404.02015, 2024
-
[12]
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yujia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, and Wanjun Zhong. Retool: Reinforcement learn- ing for strategic tool use in llms.arXiv preprint arXiv:2504.11536, 2025
work page internal anchor Pith review arXiv 2025
-
[13]
Wei Fu, Jiaxuan Gao, Xujie Shen, Chen Zhu, Zhiyu Mei, Chuyi He, Shusheng Xu, Guo Wei, Jun Mei, Ji- ashu Wang, et al. Areal: A large-scale asynchronous reinforcement learning system for language reasoning. arXiv preprint arXiv:2505.24298, 2025
-
[14]
Wei Gao, Yuheng Zhao, Dakai An, Tianyuan Wu, Lunxi Cao, Shaopan Xiong, Ju Huang, Weixun Wang, Siran Yang, Wenbo Su, et al. Rollpacker: Mitigating long-tail rollouts for fast, synchronous rl post-training.arXiv preprint arXiv:2509.21009, 2025
-
[15]
Wei Gao, Yuheng Zhao, Tianyuan Wu, Shaopan Xiong, Weixun Wang, Dakai An, Lunxi Cao, Dilxat Muhtar, Zichen Liu, Haizhou Zhao, et al. Rollart: Scaling agen- tic rl training via disaggregated infrastructure.arXiv preprint arXiv:2512.22560, 2025
-
[16]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shi- rong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review arXiv 2025
-
[17]
History doesn’t repeat itself but rollouts rhyme: Accelerating reinforce- ment learning with rhymerl
Jingkai He, Tianjian Li, Erhu Feng, Dong Du, Qian Liu, Tao Liu, Yubin Xia, and Haibo Chen. History doesn’t repeat itself but rollouts rhyme: Accelerating reinforce- ment learning with rhymerl. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, V olume 2, pages 929–945, 2026
2026
-
[18]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob 13 Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review arXiv 2021
-
[19]
OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework
Jian Hu, Xibin Wu, Zilin Zhu, Weixun Wang, Dehao Zhang, Yu Cao, et al. Openrlhf: An easy-to-use, scalable and high-performance rlhf framework.arXiv preprint arXiv:2405.11143, 6, 2024
work page internal anchor Pith review arXiv 2024
-
[20]
Hedrarag: Co- optimizing generation and retrieval for heterogeneous rag workflows
Zhengding Hu, Vibha Murthy, Zaifeng Pan, Wanlu Li, Xiaoyi Fang, Yufei Ding, and Yuke Wang. Hedrarag: Co- optimizing generation and retrieval for heterogeneous rag workflows. InProceedings of the ACM SIGOPS 31st symposium on operating systems principles, pages 623–638, 2025
2025
-
[21]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richard- son, Ahmed El-Kishky, Aiden Low, Alec Helyar, Alek- sander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review arXiv 2023
-
[23]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Ser- can Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516, 2025
work page internal anchor Pith review arXiv 2025
-
[24]
Efficient memory manage- ment for large language model serving with pagedatten- tion
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory manage- ment for large language model serving with pagedatten- tion. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
2023
-
[25]
In-the-flow agentic system optimization for effective planning and tool use
Zhuofeng Li, Haoxiang Zhang, Seungju Han, Sheng Liu, Jianwen Xie, Yu Zhang, Yejin Choi, James Zou, and Pan Lu. In-the-flow agentic system optimization for effective planning and tool use. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[26]
Bingshuai Liu, Ante Wang, Zijun Min, Liang Yao, Haibo Zhang, Yang Liu, Anxiang Zeng, and Jinsong Su. Spec- rl: Accelerating on-policy reinforcement learning via speculative rollouts.arXiv preprint arXiv:2509.23232, 2025
-
[27]
Conco: Optimizing compilation of concurrent tensor programs on shared gpu
Jiamin Lu, Jingwei Sun, Yunlong Xu, Peng Sun, and Guangzhong Sun. Conco: Optimizing compilation of concurrent tensor programs on shared gpu. InProceed- ings of the 39th ACM International Conference on Su- percomputing, pages 640–653, 2025
2025
-
[28]
Real: Efficient rlhf train- ing of large language models with parameter realloca- tion.Proceedings of Machine Learning and Systems, 7, 2025
Zhiyu Mei, Wei Fu, Kaiwei Li, Guangju Wang, Huanchen Zhang, and Yi Wu. Real: Efficient rlhf train- ing of large language models with parameter realloca- tion.Proceedings of Machine Learning and Systems, 7, 2025
2025
-
[29]
arXiv preprint arXiv:2410.18252 , year=
Michael Noukhovitch, Shengyi Huang, Sophie Xhon- neux, Arian Hosseini, Rishabh Agarwal, and Aaron Courville. Asynchronous rlhf: Faster and more effi- cient off-policy rl for language models.arXiv preprint arXiv:2410.18252, 2024
-
[30]
Multi-process service
NVIDIA. Multi-process service. https://docs. nvidia.com/deploy/mps/index.html, 2022
2022
-
[31]
Nvidia mig (multi-instance gpu)
NVIDIA. Nvidia mig (multi-instance gpu). https://www.nvidia.com/en-us/technologies/ multi-instance-gpu/, 2022
2022
-
[32]
Accessed: 2025-03-29
NVIDIA Corporation.CUDA Driver API: Green Con- texts, 2025. Accessed: 2025-03-29
2025
-
[33]
Serverless rl
OpenPipe. Serverless rl. https://openpipe.ai/ blog/serverless-rl, 2024. Accessed: 2026-03-04
2024
-
[34]
Training language models to follow instructions with human feedback.Advances in neural information pro- cessing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information pro- cessing systems, 35:27730–27744, 2022
2022
-
[35]
Gorilla: Large language model connected with massive apis.Advances in Neural Information Processing Systems, 37:126544–126565, 2024
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive apis.Advances in Neural Information Processing Systems, 37:126544–126565, 2024
2024
-
[36]
Seer: Online Context Learning for Fast Synchronous LLM Reinforcement Learning
Ruoyu Qin, Weiran He, Weixiao Huang, Yangkun Zhang, Yikai Zhao, Bo Pang, Xinran Xu, Yingdi Shan, Yongwei Wu, and Mingxing Zhang. Seer: Online con- text learning for fast synchronous llm reinforcement learning.arXiv preprint arXiv:2511.14617, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis.arXiv preprint arXiv:2307.16789, 2023
work page internal anchor Pith review arXiv 2023
-
[38]
Zero: Memory optimizations toward train- ing trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward train- ing trillion parameter models. InSC20: international conference for high performance computing, networking, storage and analysis, pages 1–16. IEEE, 2020
2020
-
[39]
arXiv preprint arXiv:2602.19362 , year=
Daniel Ritter, Owen Oertell, Bradley Guo, Jonathan Chang, Kianté Brantley, and Wen Sun. Llms can learn to reason via off-policy rl.arXiv preprint arXiv:2602.19362, 2026. 14
-
[40]
rstar2-agent: Agentic reasoning technical report, 2025
Ning Shang, Yifei Liu, Yi Zhu, Li Lyna Zhang, Wei- jiang Xu, Xinyu Guan, Buze Zhang, Bingcheng Dong, Xudong Zhou, Bowen Zhang, et al. rstar2-agent: Agentic reasoning technical report.arXiv preprint arXiv:2508.20722, 2025
-
[41]
Multi-turn re- inforcement learning with preference human feedback
Lior Shani, Aviv Rosenberg, Asaf Cassel, Oran Lang, Daniele Calandriello, Avital Zipori, Hila Noga, Orgad Keller, Bilal Piot, Idan Szpektor, et al. Multi-turn re- inforcement learning with preference human feedback. Advances in Neural Information Processing Systems, 37:118953–118993, 2024
2024
-
[42]
Zelei Shao, Vikranth Srivatsa, Sanjana Srivastava, Qingyang Wu, Alpay Ariyak, Xiaoxia Wu, Ameen Pa- tel, Jue Wang, Percy Liang, Tri Dao, Ce Zhang, Yiy- ing Zhang, Ben Athiwaratkun, Chenfeng Xu, and Junx- iong Wang. Beat the long tail: Distribution-aware speculative decoding for rl training.arXiv preprint arXiv:2511.13841, 2025
-
[43]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review arXiv 2024
-
[44]
arXiv preprint arXiv:2510.12633 , year=
Guangming Sheng, Yuxuan Tong, Borui Wan, Wang Zhang, Chaobo Jia, Xibin Wu, Yuqi Wu, Xiang Li, Chi Zhang, Yanghua Peng, et al. Laminar: A scalable asyn- chronous rl post-training framework.arXiv preprint arXiv:2510.12633, 2025
-
[45]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. InProceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025
2025
-
[46]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter lan- guage models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review arXiv 1909
-
[47]
Xin Tan, Yicheng Feng, Yu Zhou, Yimin Jiang, Yibo Zhu, and Hong Xu. Orchestrrl: Dynamic compute and network orchestration for disaggregated rl.arXiv preprint arXiv:2601.01209, 2026
-
[48]
Tinker documentation: Serverless api framework for modular rl
Thinking Machines. Tinker documentation: Serverless api framework for modular rl. https://tinker-docs. thinkingmachines.ai/, 2024. Accessed: 2026-03- 04
2024
-
[49]
Vagen:reinforcing world model reasoning for multi- turn vlm agents, 2025
Kangrui Wang*, Pingyue Zhang*, Zihan Wang*, Yaning Gao*, Linjie Li*, Qineng Wang, Hanyang Chen, Chi Wan, Yiping Lu, Zhengyuan Yang, Lijuan Wang, Ranjay Krishna, Jiajun Wu, Li Fei-Fei, Yejin Choi, and Manling Li. Vagen:reinforcing world model reasoning for multi- turn vlm agents, 2025
2025
-
[50]
Rlhfspec: Breaking the effi- ciency bottleneck in rlhf training via adaptive drafting
Siqi Wang, Hailong Yang, Junjie Zhu, Xuezhu Wang, Yufan Xu, and Depei Qian. Rlhfspec: Breaking the effi- ciency bottleneck in rlhf training via adaptive drafting. arXiv preprint arXiv:2512.04752, 2025
-
[51]
Weixun Wang, Shaopan Xiong, Gengru Chen, Wei Gao, Sheng Guo, Yancheng He, Ju Huang, Jiaheng Liu, Zhendong Li, Xiaoyang Li, et al. Reinforcement learning optimization for large-scale learning: An effi- cient and user-friendly scaling library.arXiv preprint arXiv:2506.06122, 2025
-
[52]
{WLB-LLM}:{Workload-Balanced} 4d parallelism for large language model training
Zheng Wang, Anna Cai, Xinfeng Xie, Zaifeng Pan, Yue Guan, Weiwei Chu, Jie Wang, Shikai Li, Jianyu Huang, Chris Cai, et al. {WLB-LLM}:{Workload-Balanced} 4d parallelism for large language model training. In 19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25), pages 785–801, 2025
2025
-
[53]
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
Zihan Wang, Kangrui Wang, Qineng Wang, Pingyue Zhang, Linjie Li, Zhengyuan Yang, Xing Jin, Kefan Yu, Minh Nhat Nguyen, Licheng Liu, et al. Ragen: Under- standing self-evolution in llm agents via multi-turn rein- forcement learning.arXiv preprint arXiv:2504.20073, 2025
work page internal anchor Pith review arXiv 2025
-
[54]
Rlhfless: Serverless computing for efficient rlhf
Rui Wei, Hanfei Yu, Shubham Jain, Yogarajan Sivaku- mar, Devesh Tiwari, Jian Li, Seung-Jong Park, and Hao Wang. Rlhfless: Serverless computing for efficient rlhf. arXiv preprint arXiv:2602.22718, 2026
-
[55]
Tianyuan Wu, Lunxi Cao, Yining Wei, Wei Gao, Yuheng Zhao, Dakai An, Shaopan Xiong, Zhiqiang Lv, Ju Huang, Siran Yang, et al. Rollmux: Phase-level multiplex- ing for disaggregated rl post-training.arXiv preprint arXiv:2512.11306, 2025
-
[56]
RLBoost: Harvesting Preemptible Resources for Cost-Efficient Reinforcement Learning on LLMs
Yongji Wu, Xueshen Liu, Haizhong Zheng, Juncheng Gu, Beidi Chen, Z Morley Mao, Arvind Krishnamurthy, and Ion Stoica. Rlboost: Harvesting preemptible re- sources for cost-efficient reinforcement learning on llms. arXiv preprint arXiv:2510.19225, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chen- gen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025. 15
work page internal anchor Pith review arXiv 2025
-
[58]
Hotpotqa: A dataset for diverse, ex- plainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Ben- gio, William Cohen, Ruslan Salakhutdinov, and Christo- pher D Manning. Hotpotqa: A dataset for diverse, ex- plainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2369–2380, 2018
2018
-
[59]
Webshop: Towards scalable real-world web interaction with grounded language agents.Ad- vances in Neural Information Processing Systems, 35:20744–20757, 2022
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents.Ad- vances in Neural Information Processing Systems, 35:20744–20757, 2022
2022
-
[60]
Deepspeed-chat: Easy, fast and affordable rlhf training of chatgpt-like models at all scales
Zhewei Yao, Reza Yazdani Aminabadi, Olatunji Ruwase, Samyam Rajbhandari, Xiaoxia Wu, Ammar Ahmad Awan, Jeff Rasley, Minjia Zhang, Conglong Li, Connor Holmes, et al. Deepspeed-chat: Easy, fast and affordable rlhf training of chatgpt-like models at all scales.arXiv preprint arXiv:2308.01320, 2023
-
[61]
TensorHub: Scalable and Elastic Weight Transfer for LLM RL Training
Chenhao Ye, Huaizheng Zhang, Mingcong Han, Bao- quan Zhong, Xiang Li, Qixiang Chen, Xinyi Zhang, Weidong Zhang, Kaihua Jiang, Wang Zhang, et al. Ten- sorhub: Scalable and elastic weight transfer for llm rl training.arXiv preprint arXiv:2604.09107, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[62]
Chao Yu, Yuanqing Wang, Zhen Guo, Hao Lin, Si Xu, Hongzhi Zang, Quanlu Zhang, Yongji Wu, Chunyang Zhu, Junhao Hu, et al. Rlinf: Flexible and efficient large- scale reinforcement learning via macro-to-micro flow transformation.arXiv preprint arXiv:2509.15965, 2025
-
[63]
Orca: A distributed serving system for {Transformer-Based} generative models
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soo- jeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for {Transformer-Based} generative models. In16th USENIX symposium on operating sys- tems design and implementation (OSDI 22), pages 521– 538, 2022
2022
-
[64]
Prism: Unleashing gpu sharing for cost-efficient multi-llm serving, 2025
Shan Yu, Jiarong Xing, Yifan Qiao, Mingyuan Ma, Yang- min Li, Yang Wang, Shuo Yang, Zhiqiang Xie, Shiyi Cao, Ke Bao, et al. Prism: Unleashing gpu sharing for cost-efficient multi-llm serving.arXiv preprint arXiv:2505.04021, 2025
-
[65]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Sho- janazeri, Myle Ott, Sam Shleifer, et al. Pytorch fsdp: experiences on scaling fully sharded data parallel.arXiv preprint arXiv:2304.11277, 2023
work page internal anchor Pith review arXiv 2023
-
[66]
Haizhong Zheng, Jiawei Zhao, and Beidi Chen. Prosper- ity before collapse: How far can off-policy rl reach with stale data on llms?arXiv preprint arXiv:2510.01161, 2025
-
[67]
Sglang: Efficient execution of structured language model pro- grams.Advances in neural information processing sys- tems, 37:62557–62583, 2024
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model pro- grams.Advances in neural information processing sys- tems, 37:62557–62583, 2024
2024
-
[68]
Yinmin Zhong, Zili Zhang, Xiaoniu Song, Hanpeng Hu, Chao Jin, Bingyang Wu, Nuo Chen, Yukun Chen, Yu Zhou, Changyi Wan, et al. Streamrl: Scalable, het- erogeneous, and elastic rl for llms with disaggregated stream generation.arXiv preprint arXiv:2504.15930, 2025
-
[69]
Optimizing {RLHF} training for large language models with stage fusion
Yinmin Zhong, Zili Zhang, Bingyang Wu, Shengyu Liu, Yukun Chen, Changyi Wan, Hanpeng Hu, Lei Xia, Ranchen Ming, Yibo Zhu, et al. Optimizing {RLHF} training for large language models with stage fusion. In 22nd USENIX Symposium on Networked Systems De- sign and Implementation (NSDI 25), pages 489–503, 2025
2025
-
[70]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023
work page internal anchor Pith review arXiv 2023
-
[71]
slime: An llm post-training framework for rl scaling
Zilin Zhu, Chengxing Xie, Xin Lv, and slime Contrib- utors. slime: An llm post-training framework for rl scaling. https://github.com/THUDM/slime, 2025. GitHub repository. Corresponding author: Xin Lv. 16
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.