Recognition: 2 theorem links
· Lean TheoremFlashEvolve: Accelerating Agent Self-Evolution with Asynchronous Stage Orchestration
Pith reviewed 2026-05-12 01:43 UTC · model grok-4.3
The pith
FlashEvolve accelerates LLM agent self-evolution by replacing synchronized stages with asynchronous workers and queues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
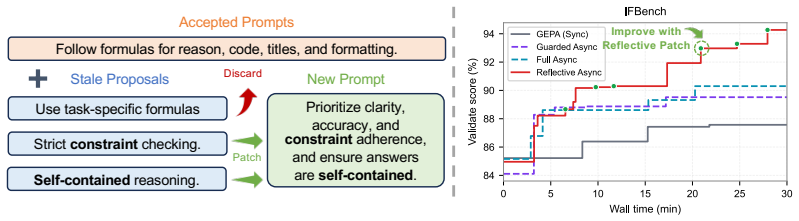
FlashEvolve replaces synchronized stage execution with asynchronous workers and queues, allowing different stages and steps to overlap. It tracks artifact versions to handle the resulting staleness and applies policies that update, discard, or patch stale language artifacts. Unlike weight-space staleness, language-space staleness is inspectable and repairable: a stale artifact provides readable evidence that the LLM can reflect on, revise, and convert into useful evolution signal. Speculative stage completion and adaptive workflow control further raise throughput and token efficiency.
What carries the argument
Asynchronous workers and queues combined with version tracking and update/discard/patch policies for stale language artifacts
If this is right
- Higher proposal throughput directly shortens the wall-clock time required for each evolution cycle.
- The same asynchronous design transfers to other agent evolution frameworks such as ACE and Meta-Harness.
- Speculative stage completion and adaptive workflow control raise both throughput and token efficiency.
- Language-space staleness can be turned into an additional source of evolution signal rather than pure waste.
Where Pith is reading between the lines
- The approach could make self-evolving agents practical for longer-horizon tasks whose synchronous runs currently exceed available compute budgets.
- The inspectable nature of language artifacts suggests similar version-and-repair logic could be added to other multi-step LLM pipelines that currently wait for full synchronization.
- Different patch policies might be tested to see whether they increase or reduce diversity among the evolved agent populations.
Load-bearing premise
Policies for updating, discarding, or patching stale language artifacts preserve or enhance evolution quality and do not introduce systematic biases from asynchrony.
What would settle it
A side-by-side run of the same GEPA workload in which agents evolved under FlashEvolve reach measurably lower final task performance than agents evolved under the synchronous baseline.
Figures





read the original abstract
LLM-based evolution has emerged as a promising way to improve agents by refining non-parametric artifacts, but its wall-clock cost remains a major bottleneck. We identify that this cost comes from synchronized stage execution and imbalance inside each LLM-heavy stage. We present FlashEvolve, an efficient framework that replaces synchronized execution with asynchronous workers and queues, allowing different stages and steps to overlap. To handle data staleness introduced by asynchrony, FlashEvolve tracks artifact versions and applies different policies to update, discard, or patch stale artifacts. Unlike weight-space staleness in asynchronous RL, language-space staleness is inspectable and repairable: a stale artifact is not just delayed work, but readable evidence that the LLM can reflect on, revise, and turn into useful evolution signal. FlashEvolve further improves throughput and token efficiency with speculative stage completion and adaptive workflow control. On GEPA workloads, FlashEvolve improves proposal throughput by $3.5\times$ on local vLLM and $4.9\times$ on API serving over synchronous GEPA. The same design also applies to ACE and Meta-Harness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FlashEvolve, a framework for accelerating LLM-based agent self-evolution by replacing synchronized stage execution with asynchronous workers and queues. It incorporates version tracking and policies (update, discard, patch) to manage staleness in language artifacts, plus speculative stage completion and adaptive workflow control. The central empirical claim is a 3.5× proposal throughput gain on local vLLM and 4.9× on API serving versus synchronous GEPA on GEPA workloads, with the design stated to generalize to ACE and Meta-Harness.
Significance. If the quality of evolved agents is preserved, the work addresses a practical bottleneck in iterative agent refinement and could make self-evolution more scalable. The paper earns credit for explicitly distinguishing language-space staleness (inspectable and repairable) from weight-space staleness in asynchronous RL, which is a useful conceptual contribution. The reported throughput numbers, if backed by proper controls, would represent a concrete engineering advance in LLM orchestration for evolutionary search.
major comments (2)
- [§5 (Experiments)] §5 (Experiments): The reported 3.5× and 4.9× throughput improvements on GEPA workloads supply no head-to-head quality metrics (final agent success rate, proposal acceptance rate, or downstream task performance) comparing asynchronous FlashEvolve to synchronous GEPA, leaving open whether the speedup preserves evolution dynamics or arises from altered search behavior due to the staleness policies.
- [§4 (Method)] §4 (Method, Staleness Policies): The description of versioned update/discard/patch policies for stale artifacts lacks any ablation or direct measurement demonstrating that these policies avoid systematic bias relative to synchronous execution; without such evidence the central claim that asynchrony yields pure efficiency gains (rather than changed evolution trajectories) remains unsupported.
minor comments (2)
- [Abstract] Abstract: The statement that the design 'also applies to ACE and Meta-Harness' is not supported by any reported results or implementation details for those workloads.
- The manuscript would benefit from explicit statements of the experimental controls (random seeds, prompt templates, baseline GEPA implementation details) and statistical significance tests for the throughput figures.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the conceptual distinction between language-space and weight-space staleness as well as the potential practical value of the framework. We address the two major comments point by point below. Both comments correctly identify gaps in the current empirical validation; we therefore plan revisions that directly supply the requested head-to-head quality metrics and policy ablations.
read point-by-point responses
-
Referee: §5 (Experiments): The reported 3.5× and 4.9× throughput improvements on GEPA workloads supply no head-to-head quality metrics (final agent success rate, proposal acceptance rate, or downstream task performance) comparing asynchronous FlashEvolve to synchronous GEPA, leaving open whether the speedup preserves evolution dynamics or arises from altered search behavior due to the staleness policies.
Authors: We agree that the absence of direct quality comparisons leaves open the possibility that throughput gains arise partly from altered search trajectories. The manuscript focuses on proposal throughput because that is the primary engineering bottleneck addressed, yet we recognize that quality preservation must be demonstrated rather than assumed. In the revised version we will add side-by-side results on the GEPA workloads that report final agent success rates, proposal acceptance rates, and downstream task performance for both the asynchronous FlashEvolve configuration and the synchronous GEPA baseline. These additions will allow readers to assess whether the staleness policies preserve evolution dynamics. revision: yes
-
Referee: §4 (Method, Staleness Policies): The description of versioned update/discard/patch policies for stale artifacts lacks any ablation or direct measurement demonstrating that these policies avoid systematic bias relative to synchronous execution; without such evidence the central claim that asynchrony yields pure efficiency gains (rather than changed evolution trajectories) remains unsupported.
Authors: The policies are motivated by the inspectable and repairable character of language artifacts, which in principle permits version-aware decisions that keep asynchronous execution semantically aligned with synchronous execution. Nevertheless, the referee is correct that the manuscript provides no ablation or quantitative measurement of bias. We will add an ablation study in the revision that runs the same GEPA workloads under each policy (update, discard, patch) and under the synchronous baseline, reporting metrics such as proposal acceptance rate, divergence in accepted proposal content, and final agent performance. This will supply the missing empirical support for the claim that efficiency gains are obtained without systematic change to evolution trajectories. revision: yes
Circularity Check
No circularity: empirical framework with independent throughput measurements
full rationale
The paper presents FlashEvolve as an engineering system for asynchronous stage orchestration in LLM agent evolution, with central claims resting on direct empirical measurements of proposal throughput (3.5× local vLLM, 4.9× API) versus synchronous GEPA baselines. No equations, derivations, fitted parameters, or first-principles predictions appear in the provided text. Staleness policies are motivated by the inspectability of language artifacts (contrasted with RL weights) but are not derived from or equivalent to any self-referential inputs; they are design choices validated by the throughput results. The extension to ACE and Meta-Harness is stated as applicability rather than a derived result. This leaves the derivation chain self-contained against external benchmarks, with no load-bearing self-citation or renaming of known results.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FlashEvolve replaces synchronized stage execution with asynchronous workers and queues... staleness-aware policies... Reflective Async inspects and updates stale items by adding a new reflection worker stage.
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
On GEPA workloads, FlashEvolve improves proposal throughput by 3.5× on local vLLM and 4.9× on API serving
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Nemo rl: A scalable and efficient post-training library.https://github.com/NVIDIA-NeMo/ RL, 2025. GitHub repository
work page 2025
-
[2]
L. A. Agrawal, S. Tan, D. Soylu, N. Ziems, R. Khare, K. Opsahl-Ong, A. Singhvi, H. Shandilya, M. J. Ryan, M. Jiang, et al. Gepa: Reflective prompt evolution can outperform reinforcement learning.arXiv preprint arXiv:2507.19457, 2025
work page internal anchor Pith review arXiv 2025
-
[3]
H. Assumpção, D. Ferreira, L. Campos, and F. Murai. Codeevolve: An open source evolutionary coding agent for algorithm discovery and optimization.arXiv preprint arXiv:2510.14150, 2025
- [4]
- [5]
-
[6]
H.-a. Gao, J. Geng, W. Hua, M. Hu, X. Juan, H. Liu, S. Liu, J. Qiu, X. Qi, Y . Wu, et al. A survey of self-evolving agents: On path to artificial super intelligence.arXiv preprint arXiv:2507.21046, 1, 2025
work page internal anchor Pith review arXiv 2025
-
[7]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Z. Hu, H. Ouyang, C. Chen, Z. Pan, Y . Guan, Z. Yu, Z. Wang, S. Swanson, and Y . Ding. Jigsawrl: Assembling rl pipelines for efficient llm post-training, 2026. URLhttps://arxiv. org/abs/2604.23838
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
A. Jaech, A. Kalai, A. Lerer, A. Richardson, A. El-Kishky, A. Low, A. Helyar, A. Madry, A. Beutel, A. Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [11]
-
[12]
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
work page 2023
- [13]
-
[14]
Y . Lee, R. Nair, Q. Zhang, K. Lee, O. Khattab, and C. Finn. Meta-harness: End-to-end optimization of model harnesses.arXiv preprint arXiv:2603.28052, 2026
work page internal anchor Pith review arXiv 2026
-
[15]
H. Li, R. He, Q. Zhang, C. Ji, Q. Mang, X. Chen, L. A. Agrawal, W.-L. Liao, E. Yang, A. Cheung, et al. Combee: Scaling prompt learning for self-improving language model agents.arXiv preprint arXiv:2604.04247, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [16]
-
[17]
L. Loukas, M. Fergadiotis, I. Chalkidis, E. Spyropoulou, P. Malakasiotis, I. Androutsopoulos, and G. Paliouras. Finer: Financial numeric entity recognition for xbrl tagging. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4419–4431, 2022. 10
work page 2022
- [18]
- [19]
-
[20]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
A. Novikov, N. V˜u, M. Eisenberger, E. Dupont, P.-S. Huang, A. Z. Wagner, S. Shirobokov, B. Kozlovskii, F. J. Ruiz, A. Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [21]
-
[22]
arXiv preprint arXiv:2509.25140 , year=
S. Ouyang, J. Yan, I. Hsu, Y . Chen, K. Jiang, Z. Wang, R. Han, L. T. Le, S. Daruki, X. Tang, et al. Reasoningbank: Scaling agent self-evolving with reasoning memory.arXiv preprint arXiv:2509.25140, 2025
-
[23]
Generalizing verifiable instruction following.arXiv preprint arXiv:2507.02833,
V . Pyatkin, S. Malik, V . Graf, H. Ivison, S. Huang, P. Dasigi, N. Lambert, and H. Hajishirzi. Generalizing verifiable instruction following.arXiv preprint arXiv:2507.02833, 2025
-
[24]
arXiv preprint arXiv:2510.12633 , year=
G. Sheng, Y . Tong, B. Wan, W. Zhang, C. Jia, X. Wu, Y . Wu, X. Li, C. Zhang, Y . Peng, et al. Laminar: A scalable asynchronous rl post-training framework.arXiv preprint arXiv:2510.12633, 2025
- [25]
- [26]
-
[27]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
- [28]
- [29]
-
[30]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Z. Yang, P. Qi, S. Zhang, Y . Bengio, W. Cohen, R. Salakhutdinov, and C. D. Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2369–2380, 2018
work page 2018
-
[32]
TextGrad: Automatic "Differentiation" via Text
M. Yuksekgonul, F. Bianchi, J. Boen, S. Liu, Z. Huang, C. Guestrin, and J. Zou. Textgrad: Automatic" differentiation" via text.arXiv preprint arXiv:2406.07496, 2024
work page internal anchor Pith review arXiv 2024
-
[33]
arXiv preprint arXiv:2512.18746 , year=
G. Zhang, H. Ren, C. Zhan, Z. Zhou, J. Wang, H. Zhu, W. Zhou, and S. Yan. Memevolve: Meta-evolution of agent memory systems.arXiv preprint arXiv:2512.18746, 2025
-
[34]
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Q. Zhang, C. Hu, S. Upasani, B. Ma, F. Hong, V . Kamanuru, J. Rainton, C. Wu, M. Ji, H. Li, et al. Agentic context engineering: Evolving contexts for self-improving language models. arXiv preprint arXiv:2510.04618, 2025
work page internal anchor Pith review arXiv 2025
- [35]
-
[36]
Y . Zhao, A. Gu, R. Varma, L. Luo, C.-C. Huang, M. Xu, L. Wright, H. Shojanazeri, M. Ott, S. Shleifer, et al. Pytorch fsdp: experiences on scaling fully sharded data parallel.arXiv preprint arXiv:2304.11277, 2023
work page internal anchor Pith review arXiv 2023
- [37]
-
[38]
Y . Zhong, Z. Zhang, X. Song, H. Hu, C. Jin, B. Wu, N. Chen, Y . Chen, Y . Zhou, C. Wan, et al. Streamrl: Scalable, heterogeneous, and elastic rl for llms with disaggregated stream generation. arXiv preprint arXiv:2504.15930, 2025. 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.