Recognition: no theorem link
Towards Localizing Conversation Partners using Head Motion
Pith reviewed 2026-05-15 06:43 UTC · model grok-4.3
The pith
Head motion from smartglasses IMUs localizes acoustic zones of interest for conversation partners.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
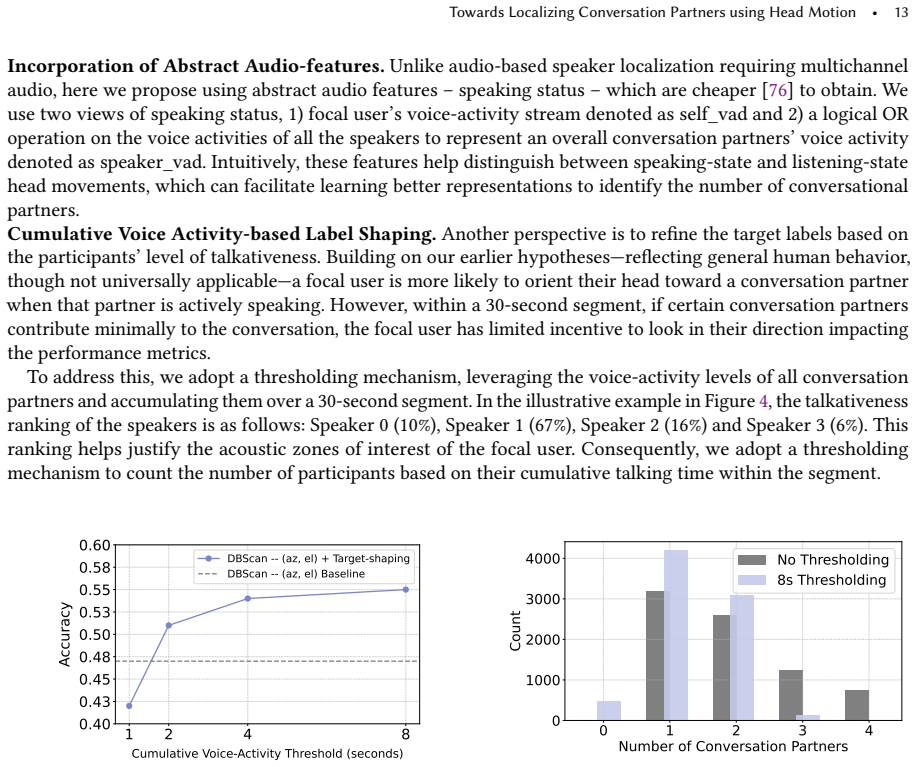
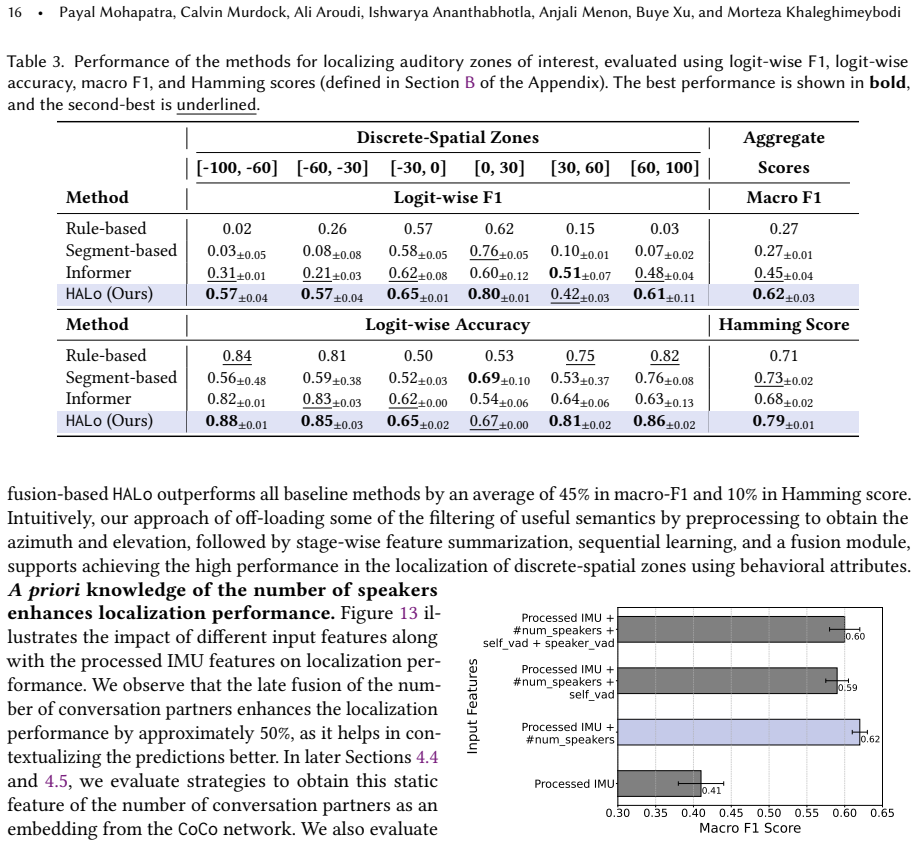
HALo processes IMU time series from smartglasses to predict acoustic zones of interest that correspond to conversation partner locations; supplying it with a prior estimate of partner count produces a 21 percent performance lift over baseline methods, while the companion CoCo classifier recovers that partner count from IMU data at 0.74 accuracy and a 35 percent gain over rule-based and generic time-series baselines.
What carries the argument
HALo, the head-orientation-based acoustic zone localization network that converts smartglasses IMU signals into estimates of user listening directions.
If this is right
- Enables non-invasive inference of listening directions that does not depend on microphone arrays for direction-of-arrival estimation.
- Delivers a 35 percent improvement in classifying the number of conversation partners over rule-based and generic time-series baselines.
- Supports end-to-end speech enhancement pipelines that maintain performance when multiple background speakers are present.
- Provides feature-extraction and inference steps suitable for real-time wearable deployment.
Where Pith is reading between the lines
- The stability observed over extended sessions suggests the approach could support continuous, day-long use without frequent recalibration.
- Integration with other wearable signals might extend reliable zone prediction beyond seated, controlled conversations.
- The same motion patterns could be repurposed for related attention tasks such as selective audio focus in meetings or classrooms.
Load-bearing premise
Head movements tracked by IMUs accurately reflect the directions users intend to listen toward, and an accurate prior count of conversation partners is available.
What would settle it
Controlled recordings in which users' measured head angles during conversation deviate from their self-reported listening directions, or in which supplying an incorrect partner count removes the reported accuracy gains.
Figures


















read the original abstract
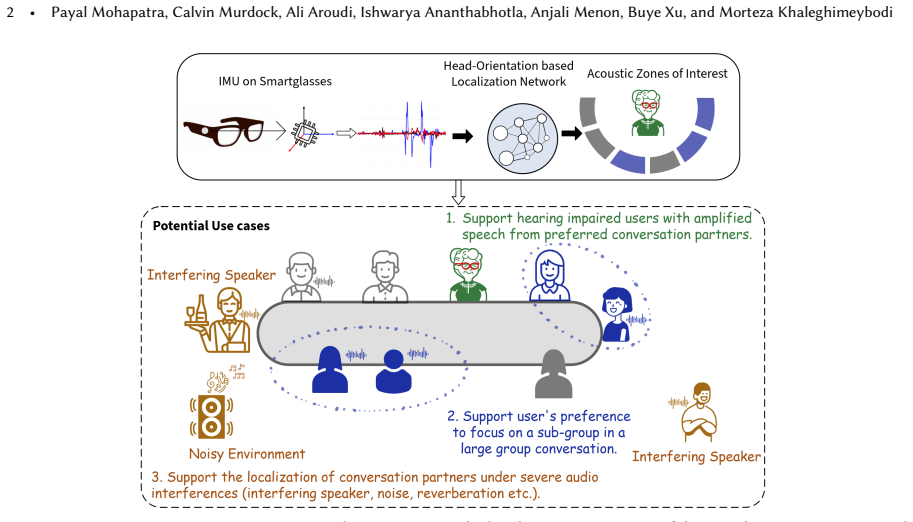
Many individuals struggle to understand conversation partners in noisy settings, particularly amid background speakers or due to hearing impairments. Emerging wearables like smartglasses offer a transformative opportunity to enhance speech from conversation partners. Crucial to this is identifying the direction in which the user wants to listen, which we refer to as the user's acoustic zones of interest. While current spatial audio-based methods can resolve the direction of vocal input, they are agnostic to listening preferences and have limited functionality in noisy settings with interfering speakers. To address this, behavioral cues are needed to actively infer a user's acoustic zones of interest. We explore the effectiveness of head-orienting behavior, captured by Inertial Measurement Units (IMUs) on smartglasses, as a modality for localizing these zones in seated conversations. We introduce HALo, a head-orientation-based acoustic zone localization network that leverages smartglasses' IMUs to non-invasively infer auditory zones of interest corresponding to conversation partner locations. By integrating an a priori estimate of the number of conversation partners, our approach yields a 21% performance improvement over existing methods. We complement this with CoCo, which classifies the number of conversation partners using only IMU data, achieving 0.74 accuracy and a 35% gain over rule-based and generic time-series baselines. We discuss practical considerations for feature extraction and inference and provide qualitative analyses over extended sessions. We also demonstrate a minimal end-to-end speech enhancement system, showing that head-orientation-based localization offers clear advantages in extremely noisy settings with multiple conversation partners.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HALo, an IMU-based neural network on smartglasses that localizes users' acoustic zones of interest during seated conversations by modeling head-orientation behavior. It reports a 21% performance gain when an a priori estimate of the number of conversation partners is supplied. A companion classifier CoCo predicts the partner count from IMU data alone at 0.74 accuracy (35% above rule-based and generic time-series baselines). The work includes qualitative analysis over long sessions and a minimal end-to-end speech-enhancement demonstration.
Significance. If the empirical claims are substantiated, the approach offers a practical, non-invasive way to steer spatial audio on commodity wearables toward conversation partners in noisy multi-speaker settings, directly addressing a common pain point for hearing-impaired users. The reliance on head motion rather than acoustic source localization is a useful complementary signal, and the provision of both localization and partner-count modules is a coherent pipeline contribution.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation: the headline 21% improvement for HALo is stated to result from 'integrating an a priori estimate of the number of conversation partners,' yet the manuscript presents CoCo (0.74 accuracy) separately. No ablation is reported that substitutes CoCo's predictions for the oracle count inside HALo, so it is impossible to determine the end-to-end gain achievable when only IMU data are available.
- [Experimental Setup] Experimental Setup: the manuscript provides no information on dataset size, number of participants, recording conditions, exact baseline implementations, or the statistical tests used to support the 21% and 35% figures. These omissions prevent assessment of whether the reported gains are robust or merely artifacts of small or unrepresentative data.
minor comments (2)
- [Method] Notation for acoustic zones of interest is introduced without a clear diagram relating IMU axes to angular zones; a figure would improve readability.
- [Method] The description of feature extraction for CoCo and HALo could be expanded with pseudocode or explicit window lengths to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each of the major comments below and indicate the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: Abstract and Evaluation: the headline 21% improvement for HALo is stated to result from 'integrating an a priori estimate of the number of conversation partners,' yet the manuscript presents CoCo (0.74 accuracy) separately. No ablation is reported that substitutes CoCo's predictions for the oracle count inside HALo, so it is impossible to determine the end-to-end gain achievable when only IMU data are available.
Authors: We agree with this observation. The 21% improvement highlights the value of providing the partner count as input to HALo, while CoCo serves as a standalone classifier for estimating this count from IMU data. To address the lack of end-to-end evaluation, we will add an ablation study in the revised manuscript that uses CoCo's predictions as input to HALo and reports the resulting localization performance. This will clarify the practical gains when relying solely on IMU data. revision: yes
-
Referee: Experimental Setup: the manuscript provides no information on dataset size, number of participants, recording conditions, exact baseline implementations, or the statistical tests used to support the 21% and 35% figures. These omissions prevent assessment of whether the reported gains are robust or merely artifacts of small or unrepresentative data.
Authors: We apologize for these omissions in the description of the experimental setup. In the revised version, we will expand the Experimental Setup section to include details on the dataset size, number of participants, recording conditions (e.g., seated conversations in controlled environments), the precise implementations of the rule-based and time-series baselines, and the statistical tests (such as significance testing for the reported percentage improvements) used to validate the results. This will allow readers to better assess the robustness of our findings. revision: yes
Circularity Check
No significant circularity; derivation relies on external a priori input and new IMU measurements
full rationale
The paper presents HALo as integrating an external a priori estimate of conversation partner count to obtain the reported 21% gain, while separately introducing CoCo as an IMU-based classifier achieving 0.74 accuracy. No equation or step reduces a prediction to a fitted parameter by construction, no self-citation chain bears the central claim, and no uniqueness theorem or ansatz is smuggled in. The approach is benchmarked against rule-based and time-series baselines using new sensor data, satisfying the default non-circularity expectation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Head orientation captured by IMUs on smartglasses indicates the user's acoustic zones of interest in seated conversations
Reference graph
Works this paper leans on
-
[1]
Mustafa Al-Yassary, Kelly Billiaert, Gregory S Antonarakis, and Stavros Kiliaridis. 2021. Evaluation of head posture using an inertial measurement unit.Scientific reports11, 1 (2021), 19911
work page 2021
-
[2]
Xavier Alameda-Pineda, Jacopo Staiano, Ramanathan Subramanian, Ligia Batrinca, Elisa Ricci, Bruno Lepri, Oswald Lanz, and Nicu Sebe. 2015. Salsa: A novel dataset for multimodal group behavior analysis.IEEE transactions on pattern analysis and machine intelligence38, 8 (2015), 1707–1720
work page 2015
-
[3]
Sileye O Ba and Jean-Marc Odobez. 2008. Recognizing visual focus of attention from head pose in natural meetings.IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics)39, 1 (2008), 16–33
work page 2008
-
[4]
Shanmukha Srinivas Battula, Hassan Taherian, Ashutosh Pandey, Daniel Wong, Buye Xu, and DeLiang Wang. 2025. Robust Frame-level Speaker Localization in Reverberant and Noisy Environments by Exploiting Phase Difference Losses. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
work page 2025
-
[5]
Igor Bisio, Chiara Garibotto, Mehrnaz Hamedani, Fabio Lavagetto, Angelo Schenone, Andrea Sciarrone, and Muhammad Shahid. 2024. Towards Sensorized Glasses: A Smart Wearable System for Head Movement Monitoring. In2024 9th International Conference on Smart and Sustainable Technologies (SpliTech). IEEE, 1–6
work page 2024
-
[6]
JM Bland. 1986. Statistical methods for assessing agreement between two methods of clinical measurement.Lancet(1986)
work page 1986
-
[7]
W Owen Brimijoin, David McShefferty, and Michael A Akeroyd. 2010. Auditory and visual orienting responses in listeners with and without hearing-impairment.The Journal of the Acoustical Society of America127, 6 (2010), 3678–3688
work page 2010
-
[8]
Carlos Busso, Sergi Hernanz, Chi-Wei Chu, Soon-il Kwon, Sung Lee, Panayiotis G Georgiou, Isaac Cohen, and Shrikanth Narayanan. 2005. Smart room: Participant and speaker localization and identification. InProceedings.(ICASSP’05). IEEE International Conference on Acoustics, Speech, and Signal Processing, 2005., Vol. 2. IEEE, ii–1117
work page 2005
-
[9]
Laura Cabrera-Quiros, Andrew Demetriou, Ekin Gedik, Leander van der Meij, and Hayley Hung. 2018. The MatchNMingle dataset: a novel multi-sensor resource for the analysis of social interactions and group dynamics in-the-wild during free-standing conversations and speed dates. IEEE Transactions on Affective Computing12, 1 (2018), 113–130
work page 2018
-
[10]
Ciro Cattuto, Wouter Van den Broeck, Alain Barrat, Vittoria Colizza, Jean-François Pinton, and Alessandro Vespignani. 2010. Dynamics of person-to-person interactions from distributed RFID sensor networks.PloS one5, 7 (2010), e11596
work page 2010
-
[11]
Ishan Chatterjee, Maruchi Kim, Vivek Jayaram, Shyamnath Gollakota, Ira Kemelmacher, Shwetak Patel, and Steven M Seitz. 2022. ClearBuds: wireless binaural earbuds for learning-based speech enhancement. InProceedings of the 20th Annual International Conference on Mobile Systems, Applications and Services. 384–396
work page 2022
-
[12]
Tuochao Chen, Malek Itani, Sefik Emre Eskimez, Takuya Yoshioka, and Shyamnath Gollakota. 2024. Hearable devices with sound bubbles. Nature Electronics(2024), 1–12
work page 2024
-
[13]
Jong-Suk Choi, Munsang Kim, and Hyun-Don Kim. 2006. Probabilistic speaker localization in noisy environments by audio-visual integration. In2006 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 4704–4709
work page 2006
-
[14]
Jessica Dawson and Tom Foulsham. 2022. Your turn to speak? Audiovisual social attention in the lab and in the wild.Visual Cognition30, 1-2 (2022), 116–134
work page 2022
-
[15]
Hoang Do, Harvey F Silverman, and Ying Yu. 2007. A real-time SRP-PHAT source location implementation using stochastic region contraction (SRC) on a large-aperture microphone array. In2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP’07, Vol. 1. IEEE, I–121
work page 2007
-
[16]
Xuan Dong and Donald S Williamson. 2019. A classification-aided framework for non-intrusive speech quality assessment. In2019 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (W ASPAA). IEEE, 100–104
work page 2019
-
[17]
Jacob Donley, Vladimir Tourbabin, Jung-Suk Lee, Mark Broyles, Hao Jiang, Jie Shen, Maja Pantic, Vamsi Krishna Ithapu, and Ravish Mehra. 2021. Easycom: An augmented reality dataset to support algorithms for easy communication in noisy environments.arXiv preprint arXiv:2107.04174 (2021). Towards Localizing Conversation Partners using Head Motion•25
-
[18]
Starkey Duncan. 1972. Some signals and rules for taking speaking turns in conversations.Journal of personality and social psychology23, 2 (1972), 283
work page 1972
-
[19]
Jakob Engel, Kiran Somasundaram, Michael Goesele, Albert Sun, Alexander Gamino, Andrew Turner, Arjang Talattof, Arnie Yuan, Bilal Souti, Brighid Meredith, et al. 2023. Project aria: A new tool for egocentric multi-modal ai research.arXiv preprint arXiv:2308.13561(2023)
work page internal anchor Pith review arXiv 2023
-
[20]
Martin Ester, Hans-Peter Kriegel, Jörg Sander, Xiaowei Xu, et al . 1996. A density-based algorithm for discovering clusters in large spatial databases with noise. Inkdd, Vol. 96. 226–231
work page 1996
-
[21]
Rebecca C Felsheim, Andreas Brendel, Patrick A Naylor, and Walter Kellermann. 2021. Head orientation estimation from multiple microphone arrays. In2020 28th European Signal Processing Conference (EUSIPCO). IEEE, 491–495
work page 2021
-
[22]
Tiantian Feng, Ju Lin, Yiteng Huang, Weipeng He, Kaustubh Kalgaonkar, Niko Moritz, Li Wan, Xin Lei, Ming Sun, and Frank Seide. 2025. Directional source separation for robust speech recognition on smart glasses. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
work page 2025
-
[23]
Andrea Ferlini, Alessandro Montanari, Cecilia Mascolo, and Robert Harle. 2019. Head motion tracking through in-ear wearables. InProceedings of the 1st International Workshop on Earable Computing. 8–13
work page 2019
-
[24]
Siska Fitrianie and Iulia Lefter. 2023. On Head Motion for Recognizing Aggression and Negative Affect during Speaking and Listening. In Proceedings of the 25th International Conference on Multimodal Interaction. 455–464
work page 2023
-
[25]
Gerald Friedland, Chuohao Yeo, and Hayley Hung. 2009. Visual speaker localization aided by acoustic models. InProceedings of the 17th ACM international conference on Multimedia. 195–202
work page 2009
-
[26]
Alexandra Frischen, Andrew P Bayliss, and Steven P Tipper. 2007. Gaze cueing of attention: visual attention, social cognition, and individual differences.Psychological bulletin133, 4 (2007), 694
work page 2007
-
[27]
David Gaddy and Dan Klein. 2020. Digital Voicing of Silent Speech. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (Eds.). Association for Computational Linguistics, Online, 5521–5530. https://doi.org/10.18653/v1/2020.emnlp-main.445
-
[28]
Stuart Gatehouse and William Noble. 2004. The speech, spatial and qualities of hearing scale (SSQ).International journal of audiology43, 2 (2004), 85–99
work page 2004
-
[29]
Linfei Ge, Qian Zhang, Jin Zhang, and Huangxun Chen. 2023. Ehtrack: Earphone-based head tracking via only acoustic signals.IEEE Internet of Things Journal(2023)
work page 2023
-
[30]
Ekin Gedik and Hayley Hung. 2018. Detecting conversing groups using social dynamics from wearable acceleration: Group size awareness. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies2, 4 (2018), 1–24
work page 2018
-
[31]
Gerard E Grossman, R John Leigh, Larry A Abel, Douglas J Lanska, and SE Thurston. 1988. Frequency and velocity of rotational head perturbations during locomotion.Experimental brain research70 (1988), 470–476
work page 1988
-
[32]
Uri Hadar. 1991. Speech-related body movement in aphasia: period analysis of upper arms and head movement.Brain and Language41, 3 (1991), 339–366
work page 1991
-
[33]
Peter Hausamann, Christian B Sinnott, Martin Daumer, and Paul R MacNeilage. 2021. Evaluation of the Intel RealSense T265 for tracking natural human head motion.Scientific reports11, 1 (2021), 12486
work page 2021
-
[34]
Maartje ME Hendrikse, Gerard Llorach, Volker Hohmann, and Giso Grimm. 2019. Movement and gaze behavior in virtual audiovisual listening environments resembling everyday life.Trends in Hearing23 (2019), 2331216519872362
work page 2019
- [35]
-
[36]
Ĺuboš Hládek, Bernd Porr, Graham Naylor, Thomas Lunner, and W Owen Brimijoin. 2019. On the interaction of head and gaze control with acoustic beam width of a simulated beamformer in a two-talker scenario.Trends in Hearing23 (2019), 2331216519876795
work page 2019
-
[37]
Osamu Hoshuyama, Akihiko Sugiyama, and Akihiro Hirano. 2002. A robust adaptive beamformer for microphone arrays with a blocking matrix using constrained adaptive filters.IEEE Transactions on signal processing47, 10 (2002), 2677–2684
work page 2002
-
[38]
Gongping Huang, Jesper R Jensen, Jingdong Chen, Jacob Benesty, Mads G Christensen, Akihiko Sugiyama, Gary Elko, and Tomas Gaensler
-
[39]
InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Advances in microphone array processing and multichannel speech enhancement. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
work page 2025
-
[40]
Hayley Hung, Gwenn Englebienne, and Jeroen Kools. 2013. Classifying social actions with a single accelerometer. InProceedings of the 2013 ACM international joint conference on Pervasive and ubiquitous computing. 207–210
work page 2013
-
[41]
Apple Inc. 2016. Apple AirPods. https://www.apple.com/airpods/ Accessed: 2024-12-16
work page 2016
-
[42]
Yan-Bin Jia. 2019. Quaternions.Com S477 (2019), 577
work page 2019
-
[43]
Hao Jiang and Vamsi Krishna Ithapu. 2021. Egocentric pose estimation from human vision span. In2021 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 10986–10994
work page 2021
-
[44]
Hao Jiang, Calvin Murdock, and Vamsi Krishna Ithapu. 2022. Egocentric deep multi-channel audio-visual active speaker localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10544–10552
work page 2022
-
[45]
Charles Knapp and Glifford Carter. 2003. The generalized correlation method for estimation of time delay.IEEE transactions on acoustics, speech, and signal processing24, 4 (2003), 320–327. 26•Payal Mohapatra, Calvin Murdock, Ali Aroudi, Ishwarya Ananthabhotla, Anjali Menon, Buye Xu, and Morteza Khaleghimeybodi
work page 2003
-
[46]
Manon Kok, Jeroen D. Hol, and Thomas B. Schön. 2017. Using inertial sensors for position and orientation estimation.Foundations and Trends in Signal Processing11, 1–2 (2017), 1–153. https://doi.org/10.1561/2000000094
-
[47]
Angkana Lertpoompunya, Erol J Ozmeral, Nathan C Higgins, and David A Eddins. 2024. Head-orienting behaviors during simultaneous speech detection and localization.Frontiers in Psychology15 (2024), 1425972
work page 2024
-
[48]
Yin Li, Alireza Fathi, and James M Rehg. 2013. Learning to predict gaze in egocentric video. InProceedings of the IEEE international conference on computer vision. 3216–3223
work page 2013
-
[49]
2007.Speech enhancement: theory and practice
Philipos C Loizou. 2007.Speech enhancement: theory and practice. CRC press
work page 2007
-
[50]
Hao Lu and W Owen Brimijoin. 2022. Sound source selection based on head movements in natural group conversation.Trends in Hearing26 (2022), 23312165221097789
work page 2022
-
[51]
Hao Lu, Martin F McKinney, Tao Zhang, and Andrew J Oxenham. 2021. Investigating age, hearing loss, and background noise effects on speaker-targeted head and eye movements in three-way conversations.The Journal of the Acoustical Society of America149, 3 (2021), 1889–1900
work page 2021
-
[52]
A Lundström, F Lundström, LML Lebret, and CFA Moorrees. 1995. Natural head position and natural head orientation: basic considerations in cephalometric analysis and research.European Journal of Orthodontics17, 2 (1995), 111–120
work page 1995
-
[53]
Naoya Maruyama, Yasuhiro Hiraguri, Keiji Kawai, and Mari Ueda. 2020. Assessing the ease of conversation in multi-group conversation spaces: Effect of background music volume on acoustic comfort in a café.Building Acoustics27, 2 (2020), 137–153
work page 2020
-
[54]
Aleksandar Matic, Venet Osmani, and Oscar Mayora-Ibarra. 2012. Analysis of social interactions through mobile phones.Mobile Networks and Applications17 (2012), 808–819
work page 2012
-
[55]
Akemi Matsuo, Taku Itami, and Jun Yoneyama. 2024. 360°Sound Localization Support System for Deaf and Hard-of-Hearing People Using Smartglasses Equipped with Two Microphone. In2024 IEEE/SICE International Symposium on System Integration (SII). IEEE, 295–300
work page 2024
-
[56]
Evelyn Z McClave. 2000. Linguistic functions of head movements in the context of speech.Journal of pragmatics32, 7 (2000), 855–878
work page 2000
-
[57]
Ronan McGarrigle, Sarah Knight, Lyndon Rakusen, Jason Geller, and Sven Mattys. 2021. Older adults show a more sustained pattern of effortful listening than young adults.Psychology and aging36, 4 (2021), 504
work page 2021
-
[58]
William H McKellin, Kimary Shahin, Murray Hodgson, Janet Jamieson, and Kathleen Pichora-Fuller. 2007. Pragmatics of conversation and communication in noisy settings.Journal of Pragmatics39, 12 (2007), 2159–2184
work page 2007
-
[59]
Ravish Mehra, Owen Brimijoin, Philip Robinson, and Thomas Lunner. 2020. Potential of augmented reality platforms to improve individual hearing aids and to support more ecologically valid research.Ear and hearing41 (2020), 140S–146S
work page 2020
-
[60]
Johannes Meyer, Adrian Frank, Thomas Schlebusch, and Enkelejda Kasneci. 2022. U-har: A convolutional approach to human activity recognition combining head and eye movements for context-aware smart glasses.Proceedings of the ACM on Human-Computer Interaction6, ETRA (2022), 1–19
work page 2022
- [61]
-
[62]
Daniel Asher Mitchell, Boaz Rafaely, Anurag Kumar, and Vladimir Tourbabin. 2025. Improved direction of arrival estimations with a wearable microphone array for dynamic environments by reliability weighting.EURASIP Journal on Advances in Signal Processing2025, 1 (2025), 42
work page 2025
-
[63]
II MLKDD. [n. d.]. Multi-label Classification. ([n. d.])
- [64]
-
[65]
Payal Mohapatra, Akash Pandey, Sinan Keten, Wei Chen, and Qi Zhu. 2023. Person identification with wearable sensing using missing feature encoding and multi-stage modality fusion. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–2
work page 2023
- [66]
- [67]
-
[68]
Vimal Mollyn, Riku Arakawa, Mayank Goel, Chris Harrison, and Karan Ahuja. 2023. Imuposer: Full-body pose estimation using imus in phones, watches, and earbuds. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–12
work page 2023
-
[69]
Sounak Mondal, Zhibo Yang, Seoyoung Ahn, Dimitris Samaras, Gregory Zelinsky, and Minh Hoai. 2023. Gazeformer: Scalable, effective and fast prediction of goal-directed human attention. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1441–1450
work page 2023
-
[70]
Alastair H Moore, Jan Mark de Haan, Michael Syskind Pedersen, Patrick A Naylor, Mike Brookes, and Jesper Jensen. 2019. Personalized signal-independent beamforming for binaural hearing aids.The Journal of the Acoustical Society of America145, 5 (2019), 2971–2981
work page 2019
-
[71]
Louis-Philippe Morency and Trevor Darrell. 2006. Head gesture recognition in intelligent interfaces: the role of context in improving recognition. InProceedings of the 11th international conference on Intelligent user interfaces. 32–38
work page 2006
-
[72]
Calvin Murdock, Ishwarya Ananthabhotla, Hao Lu, and Vamsi Krishna Ithapu. 2024. Self-Motion As Supervision For Egocentric Audiovisual Localization. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 7835–7839
work page 2024
-
[73]
Gergely Nagymáté and Rita M Kiss. 2018. Application of OptiTrack motion capture systems in human movement analysis: A systematic literature review.Recent Innovations in Mechatronics5, 1 (2018), 1–9. Towards Localizing Conversation Partners using Head Motion•27
work page 2018
-
[74]
OptiTrack. 2024. OptiTrack - Motion Capture Systems. https://optitrack.com/
work page 2024
- [75]
-
[76]
Karl Pearson and Francis Galton. 1895. VII. Note on regression and inheritance in the case of two parents.Proceedings of the Royal Society of London 58, 347-352 (1895), 240–242. https://doi.org/10.1098/rspl.1895.0041 arXiv:https://royalsocietypublishing.org/doi/pdf/10.1098/rspl.1895.0041
-
[77]
Michael Price, James Glass, and Anantha P Chandrakasan. 2017. A low-power speech recognizer and voice activity detector using deep neural networks.IEEE Journal of Solid-State Circuits53, 1 (2017), 66–75
work page 2017
-
[78]
Qiwu Qin and Yian Zhu. 2025. Robust Audio–Visual Speaker Localization in Noisy Aircraft Cabins for Inflight Medical Assistance.Sensors25, 18 (2025), 5827
work page 2025
-
[79]
Jesse Read, Bernhard Pfahringer, Geoff Holmes, and Eibe Frank. 2011. Classifier chains for multi-label classification.Machine learning85 (2011), 333–359
work page 2011
-
[80]
Rutger Rienks, Ronald Poppe, and Dirk Heylen. 2005. Differences in head orientation between speakers and listeners in multi-party conversations. International Journal HCS(2005)
work page 2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.