Recognition: unknown
2nd of the 5th PVUW MeViS-Audio Track: ASR-SaSaSa2VA
Pith reviewed 2026-05-08 04:47 UTC · model grok-4.3
The pith
Audio cues are converted to text descriptions via ASR for use with pre-trained video segmentation models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
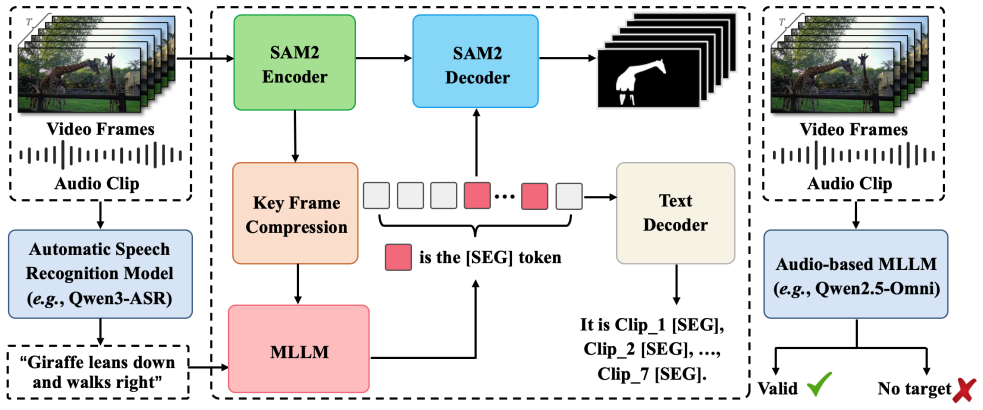
The central claim is that converting audio inputs into textual motion descriptions through automatic speech recognition, then feeding those descriptions into pre-trained text-based referring video segmentation models such as SaSaSa2VA, combined with a no-target expression detection module using a fine-tuned audio MLLM, produces accurate pixel-level object segmentations while remaining resource-efficient and robust to irrelevant audio.
What carries the argument
The ASR-to-text conversion pipeline that turns audio into motion descriptions, which are then processed by a pre-trained text-based referring video segmentation model (e.g., SaSaSa2VA) together with a no-target detection filter.
If this is right
- The method avoids the computational cost and data requirements of end-to-end audio-visual fusion models.
- The no-target detection module prevents erroneous segmentations when audio does not refer to any object.
- Strong performance can be achieved by combining separate pre-trained components rather than training a single joint model.
- Temporal alignment between audio and video is handled implicitly through the text descriptions.
Where Pith is reading between the lines
- Similar transcription-based decoupling could allow text models to serve other audio-conditioned visual tasks without full retraining.
- Improvements in ASR accuracy would directly raise segmentation quality without any change to the visual model.
- The approach questions whether tightly fused multimodal models are required when a modular text bridge suffices.
Load-bearing premise
Automatic speech recognition will reliably produce accurate enough motion descriptions that the downstream text-based segmentation model can use to locate the correct objects.
What would settle it
A set of test videos in which the ASR output contains clear errors in describing the motion or target, yet the audio itself unambiguously refers to a visible object, leading to segmentation failures.
Figures
read the original abstract
Audio-based video object segmentation aims to locate and segment objects in videos conditioned on audio cues, requiring precise understanding of both appearance and motion. Recent audio-driven video segmentation methods extend MLLMs by fusing audio and visual features for end-to-end localization. Despite their promise, these approaches are computationally intensive, struggle with aligning temporal audio cues to dynamic video content, and depend on large paired audio-video datasets. To address these challenges, we present ASR-SaSaSa2VA, a resource-efficient framework for audio-guided video segmentation. The key idea is to convert audio inputs into textual motion descriptions via automatic speech recognition (ASR) models and then leverage pre-trained text-based referring video segmentation models (e.g., SaSaSa2VA) for pixel-level predictions. To further enhance robustness, we incorporate a no-target expression detection module, implemented by a fine-tuned audio-based MLLM, which filters out audio clips that do not refer to any target object. This design allows the system to exploit strong pre-trained models while effectively handling ambiguous or irrelevant audio inputs. Our approach achieves a final score of 80.7 in the 5th PVUW Challenge (MeViS-v2-Audio track), earning the second-place ranking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ASR-SaSaSa2VA, a framework for audio-based video object segmentation. Audio is transcribed to motion descriptions using ASR, which are then fed to a pre-trained text-based referring segmentation model (SaSaSa2VA) to generate pixel-level masks. A no-target detection module based on a fine-tuned audio MLLM filters out audio that does not refer to any object. The system achieves a score of 80.7 on the MeViS-v2-Audio track of the 5th PVUW Challenge, ranking second.
Significance. If the reported performance holds, the work illustrates a practical, resource-efficient alternative to end-to-end audio-visual models by composing existing pre-trained components. This modular design avoids the need for large paired audio-video datasets and heavy computation, which could be valuable for deploying audio-guided segmentation in real-world applications. The competitive ranking provides empirical validation within the challenge setting.
minor comments (3)
- [Abstract] The description of the no-target expression detection module is brief; specifying the base MLLM used for fine-tuning and the dataset for fine-tuning would aid reproducibility.
- [The framework description] No implementation details such as the specific ASR model (e.g., Whisper variant) or inference settings are provided, which limits the ability to replicate the 80.7 score.
- [Results section] The paper would benefit from a brief comparison to other participating methods or to a simple baseline to contextualize the 80.7 score.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the practical value of our modular approach, and recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity in empirical competition report
full rationale
The paper is a short descriptive systems report of a competition entry with no mathematical derivation chain, equations, fitted parameters, or generalization claims. It describes an ASR-to-text pipeline feeding a pre-trained referring segmentation model plus a no-target filter, then reports the empirical outcome (80.7 score, second place) on the MeViS-v2-Audio track. No step reduces by construction to its own inputs, no self-citation is load-bearing for any premise, and the result is externally falsifiable via the public challenge evaluation. This is a standard honest non-finding for an applied engineering report.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhang- wei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, 4 Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test- time scaling.arXiv preprint arXiv:2412.05271, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[2]
Torr, and Song Bai
Henghui Ding, Chang Liu, Shuting He, Xudong Jiang, Philip H.S. Torr, and Song Bai. Mose: A new dataset for video object segmentation in complex scenes. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision (ICCV), pages 20224–20234, 2023. 1
2023
-
[3]
Mevis: A multi-modal dataset for referring motion expres- sion video segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Henghui Ding, Chang Liu, Shuting He, Kaining Ying, Xudong Jiang, Chen Change Loy, and Yu-Gang Jiang. Mevis: A multi-modal dataset for referring motion expres- sion video segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 2
2025
-
[4]
Henghui Ding, Kaining Ying, Chang Liu, Shuting He, Xudong Jiang, Yu-Gang Jiang, Philip HS Torr, and Song Bai. MOSEv2: A more challenging dataset for video object segmentation in complex scenes.arXiv preprint arXiv:2508.05630, 2025. 1
-
[5]
Audio-visual instance segmenta- tion
Ruohao Guo, Xianghua Ying, Yaru Chen, Dantong Niu, Guangyao Li, Liao Qu, Yanyu Qi, Jinxing Zhou, Bowei Xing, Wenzhen Yue, et al. Audio-visual instance segmenta- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 13550–13560,
-
[6]
A survey on vision transformer
Kai Han, Yunhe Wang, Hanting Chen, Xinghao Chen, Jianyuan Guo, Zhenhua Liu, Yehui Tang, An Xiao, Chun- jing Xu, Yixing Xu, et al. A survey on vision transformer. IEEE transactions on pattern analysis and machine intelli- gence, 45(1):87–110, 2022. 1
2022
-
[7]
The 1st solution for 7th lsvos rvos track: Sasasa2va.arXiv preprint arXiv:2509.16972, 2025
Quanzhu Niu, Dengxian Gong, Shihao Chen, Tao Zhang, Yikang Zhou, Haobo Yuan, Lu Qi, Xiangtai Li, and Shun- ping Ji. The 1st solution for 7th lsvos rvos track: Sasasa2va. arXiv preprint arXiv:2509.16972, 2025. 1, 2, 3
-
[8]
PVUW Challenge.https: //pvuw.github.io/, 2026
PVUW Challenge Organizers. PVUW Challenge.https: //pvuw.github.io/, 2026. 1
2026
-
[9]
Dynamic contrastive distillation for image-text retrieval.IEEE Transactions on Multimedia, pages 1–13, 2023
Jun Rao, Liang Ding, Shuhan Qi, Meng Fang, Yang Liu, Li Shen, and Dacheng Tao. Dynamic contrastive distillation for image-text retrieval.IEEE Transactions on Multimedia, pages 1–13, 2023. 1
2023
-
[10]
Xian Shi, Xiong Wang, Zhifang Guo, Yongqi Wang, Pei Zhang, Xinyu Zhang, Zishan Guo, Hongkun Hao, Yu Xi, Baosong Yang, et al. Qwen3-asr technical report.arXiv preprint arXiv:2601.21337, 2026. 2
work page internal anchor Pith review arXiv 2026
-
[11]
Vidseg: Training-free video semantic seg- mentation based on diffusion models
Qian Wang, Abdelrahman Eldesokey, Mohit Mendiratta, Fangneng Zhan, Adam Kortylewski, Christian Theobalt, and Peter Wonka. Vidseg: Training-free video semantic seg- mentation based on diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22985–22994, 2025. 1
2025
-
[12]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[13]
A survey on multimodal large language models.National Science Review, 11(12): nwae403, 2024
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models.National Science Review, 11(12): nwae403, 2024. 1
2024
-
[14]
arXiv preprint arXiv:2501.04001 , year=
Haobo Yuan, Xiangtai Li, Tao Zhang, Yueyi Sun, Zilong Huang, Shilin Xu, Shunping Ji, Yunhai Tong, Lu Qi, Ji- ashi Feng, et al. Sa2va: Marrying sam2 with llava for dense grounded understanding of images and videos.arXiv preprint arXiv:2501.04001, 2025. 1, 3 5
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.