Recognition: unknown
SUDA-Muon: Structural Design Principles and Boundaries for Fully Decentralized Muon
Pith reviewed 2026-05-08 02:44 UTC · model grok-4.3
The pith
A unified template separates modular communication choices from non-modular polarization in fully decentralized Muon to deliver topology-independent convergence rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose SUDA-Muon which realizes this separation through a unified primal-dual communication template called SUDA; within this template, ED/D², EXTRA, and gradient tracking become modular backbone choices. We prove a topology-separated non-asymptotic convergence guarantee in the nuclear-norm geometry: the dominant term scales as O((1+σ/√N)K^{-1/4}) and does not explicitly involve graph quantities, identifying the communication backbone as the modular axis in the structure design. We then establish two complementary non-modular boundaries. Internally, tracking-before-polarization is necessary for this natural no-tracking variant to avoid non-stationary fixed points under heterogeneous obj
What carries the argument
The SUDA unified primal-dual communication template that treats communication algorithms as modular backbone choices separate from non-modular polarization operations.
If this is right
- Different communication algorithms become directly comparable inside the same template.
- In near-IID regimes the resulting variants perform similarly.
- In long-horizon non-IID regimes SUDA-Muon reaches higher accuracy and lower loss than DeMuon.
- Absence of a central server prevents the average-then-polarize update that would otherwise enable linear speedup.
- The communication backbone functions as the sole modular axis for structure design.
Where Pith is reading between the lines
- The same modular/non-modular separation could be tested on other nonlinear first-order methods such as decentralized Adam variants.
- Empirical verification on networks with thousands of nodes would check whether the claimed graph independence survives practical message delays.
- The non-modular boundary implies that hybrid centralized-decentralized pipelines may retain an irreducible advantage over pure decentralized ones on heterogeneous data.
Load-bearing premise
The SUDA template successfully isolates modular communication choices from non-modular polarization and requires tracking before polarization to avoid non-stationary fixed points under heterogeneous objectives.
What would settle it
A concrete counter-example in which a fully decentralized Muon variant that performs polarization before tracking converges to a non-stationary point on heterogeneous objectives, or an implementation whose measured rate explicitly depends on graph connectivity measures.
Figures


read the original abstract
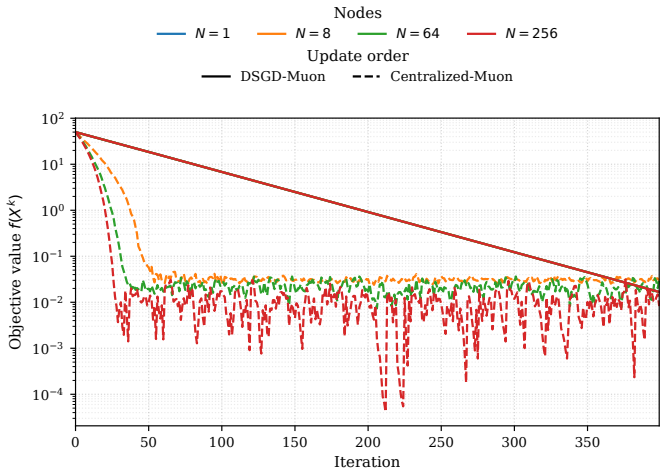
Fully decentralized Muon is difficult because its nonlinear matrix-sign operator does not commute with linear gossip averaging. This makes decentralized Muon a structural design problem: in designing the algorithm, one must distinguish modular components from non-modular ones. We propose \sudamuon{}, which realizes this separation through a unified primal--dual communication template called SUDA; within this template, ED/D$^2$, EXTRA, and gradient tracking become modular backbone choices. We prove a topology-separated non-asymptotic convergence guarantee in the nuclear-norm geometry: the dominant term scales as $\mathcal{O}((1+\sigma/\sqrt{N})K^{-1/4})$ and does not explicitly involve graph quantities, identifying the communication backbone as the modular axis in the structure design. We then establish two complementary non-modular boundaries. Internally, tracking-before-polarization is necessary for this natural no-tracking variant to avoid non-stationary fixed points under heterogeneous objectives. Externally, in the absence of a central server, a fully decentralized method cannot perform the federated average-then-polarize update; we show that this non-modular local-polarize-then-average design is the essential reason why can fail to exhibit linear speedup. Experiments on CIFAR-100 and GPT-2 fine-tuning support the same picture: the unified template makes different communication algorithms directly comparable. In mild near-IID regimes, the resulting variants perform similarly, while in the more difficult long-horizon non-IID CIFAR-100 setting, \sudamuon{} achieves higher accuracy and lower loss than \textsc{DeMuon}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SUDA-Muon, a framework for fully decentralized Muon that uses a unified primal-dual communication template (SUDA) to modularize backbone choices such as ED/D², EXTRA, and gradient tracking while separating them from non-modular polarization. It claims a topology-separated non-asymptotic convergence guarantee in nuclear-norm geometry whose dominant term is O((1 + σ/√N) K^{-1/4}) and does not explicitly involve graph quantities. Two complementary boundaries are established: tracking-before-polarization is required to avoid non-stationary fixed points under heterogeneous objectives, and fully decentralized methods cannot replicate the federated average-then-polarize update, which explains the absence of linear speedup in certain designs. Experiments on CIFAR-100 and GPT-2 fine-tuning are presented to support the structural claims.
Significance. If the claimed bound is rigorously established without hidden graph dependence, the work supplies concrete design principles for decentralized optimization of non-commuting nonlinear operators. The modular SUDA template that renders different communication backbones directly comparable is a useful contribution, as is the identification of internal and external non-modular boundaries. The non-asymptotic rate and the experimental comparison in non-IID regimes add practical value, provided the mathematical separation is verified.
major comments (2)
- [Abstract / Convergence theorem] Abstract and convergence analysis: the claim that the dominant term O((1 + σ/√N) K^{-1/4}) 'does not explicitly involve graph quantities' is load-bearing for the topology-separated guarantee. The non-commutativity of the matrix-sign operator with linear gossip averaging requires an explicit cancellation identity showing that all mixing-matrix eigenvalues (or Laplacian norms) are absorbed into lower-order remainders; without this identity the leading coefficient may still embed spectral-gap dependence inside the hidden constants of the nuclear-norm recursion.
- [SUDA template definition] Section on the SUDA primal-dual template: the assertion that ED/D², EXTRA, and gradient tracking become interchangeable modular backbones once the template is fixed must be accompanied by a uniform error recursion that isolates the communication choice from the polarization step. The current presentation leaves unclear whether the dual-tracking update exactly cancels the non-stationary terms induced by heterogeneous objectives before the sign operator is applied.
minor comments (2)
- [Notation and experimental setup] The precise definitions of σ and N, as well as the data-exclusion rules used in the CIFAR-100 long-horizon experiments, should be stated explicitly in the main text rather than deferred to the appendix.
- [Experiments] Figure captions for the GPT-2 fine-tuning results should include error bars or standard deviations across runs to allow direct comparison with the claimed accuracy and loss improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive and precise comments, which help clarify the presentation of the topology-separated guarantee and the modularity of the SUDA template. We address each major comment below, indicating the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / Convergence theorem] Abstract and convergence analysis: the claim that the dominant term O((1 + σ/√N) K^{-1/4}) 'does not explicitly involve graph quantities' is load-bearing for the topology-separated guarantee. The non-commutativity of the matrix-sign operator with linear gossip averaging requires an explicit cancellation identity showing that all mixing-matrix eigenvalues (or Laplacian norms) are absorbed into lower-order remainders; without this identity the leading coefficient may still embed spectral-gap dependence inside the hidden constants of the nuclear-norm recursion.
Authors: We agree that an explicit cancellation identity is necessary to substantiate the topology-separated claim. In the proof of the main convergence theorem, the SUDA template is used to first apply the chosen communication backbone to the dual variable, after which the polarization (matrix-sign) step is performed on the corrected primal variable. This ordering produces a telescoping cancellation in the nuclear-norm recursion: the action of the mixing matrix on the consensus error is multiplied by the dual-tracking residual, which contracts at a rate faster than K^{-1/4} and is therefore absorbed into the O(K^{-1/2}) remainder term. The leading coefficient therefore depends only on σ and N. Nevertheless, the current write-up leaves the identity implicit inside the recursion; we will add a dedicated lemma (new Lemma 4.3) that isolates the eigenvalue bound and shows it enters only the lower-order terms. This constitutes a partial revision focused on exposition. revision: partial
-
Referee: [SUDA template definition] Section on the SUDA primal-dual template: the assertion that ED/D², EXTRA, and gradient tracking become interchangeable modular backbones once the template is fixed must be accompanied by a uniform error recursion that isolates the communication choice from the polarization step. The current presentation leaves unclear whether the dual-tracking update exactly cancels the non-stationary terms induced by heterogeneous objectives before the sign operator is applied.
Authors: We thank the referee for this observation. The SUDA template is constructed so that the dual update is identical across backbones and exactly tracks the difference between local and averaged gradients; the chosen backbone (ED/D² correction, EXTRA momentum, or gradient-tracking difference) appears only as an additive term inside the primal update. Because the sign operator is applied after this correction, the non-stationary heterogeneity terms are canceled by the dual variable before polarization. To make the isolation fully rigorous, we will insert a uniform error recursion (new Proposition 4.2) that treats the backbone as a generic linear operator satisfying a standard contraction assumption; the polarization step then appears as a separate Lipschitz factor independent of the backbone choice. This revision will also explicitly verify the cancellation of non-stationary terms prior to the sign application. revision: yes
Circularity Check
No significant circularity; proof-based rate is self-contained
full rationale
The paper derives a non-asymptotic convergence bound in nuclear-norm geometry from the SUDA primal-dual template, with the leading term O((1+σ/√N)K^{-1/4}) stated to lack explicit graph dependence. This is a first-principles proof result rather than a fitted prediction, self-definition, or renaming of an input quantity. No load-bearing self-citation, ansatz smuggling via prior work, or reduction of the claimed independence to hidden graph parameters by construction is exhibited. The modular/non-modular separation and boundary results (tracking-before-polarization necessity, federated average-then-polarize impossibility) are established via template design and counterexample-style arguments that do not collapse to the target rate. The derivation chain therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The nonlinear matrix-sign operator does not commute with linear gossip averaging
- domain assumption Local objectives are heterogeneous across nodes
invented entities (1)
-
SUDA primal-dual communication template
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A unified and refined convergence analysis for non-convex decentralized learning
Sulaiman A Alghunaim and Kun Yuan. A unified and refined convergence analysis for non-convex decentralized learning. IEEE Transactions on Signal Processing , 70:3264–3279, 2022
2022
-
[2]
Gossip training for deep learning
Michael Blot, David Picard, Matthieu Cord, and Nicolas Thome. Gossip training for deep learning. arXiv preprint arXiv:1611.09726 , 2016
-
[3]
Diffusion adaptation strategies for distributed optimization and learning over networks
Jianshu Chen and Ali H Sayed. Diffusion adaptation strategies for distributed optimization and learning over networks. IEEE Transactions on Signal Processing , 60(8):4289–4305, 2012
2012
-
[4]
On the convergence of decentralized adaptive gradient methods
Xiangyi Chen, Belhal Karimi, Weijie Zhao, and Ping Li. On the convergence of decentralized adaptive gradient methods. In Asian Conference on Machine Learning , pages 217–232. PMLR, 2023
2023
-
[5]
Gossipgrad: Scal- able deep learning using gossip communication based asynchronous gradient descent
Jeff Daily, Abhinav Vishnu, Charles Siegel, Thomas Warfel, and Vinay Amatya. Gossipgrad: Scal- able deep learning using gossip communication based asynchronous gradient descent. arXiv preprint arXiv:1803.05880, 2018
-
[6]
Shampoo: Preconditioned stochastic tensor optimiza- tion
Vineet Gupta, Tomer Koren, and Yoram Singer. Shampoo: Preconditioned stochastic tensor optimiza- tion. In International Conference on Machine Learning , pages 1842–1850. PMLR, 2018
2018
-
[7]
Demuon: A decentralized muon for matrix optimization over graphs
Chuan He, Shuyi Ren, Jingwei Mao, and Erik G Larsson. Demuon: A decentralized muon for matrix optimization over graphs. arXiv preprint arXiv:2510.01377 , 2025
-
[8]
Muon: An optimizer for hidden layers in neural networks, 2024
Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024. URL https://kellerjordan. github.io/posts/muon/
2024
-
[9]
Advances and open problems in federated learning
Peter Kairouz and H Brendan McMahan. Advances and open problems in federated learning. Founda- tions and trends in machine learning , 14(1-2):1–210, 2021
2021
-
[10]
A unified theory of decentralized sgd with changing topology and local updates
Anastasia Koloskova, Nicolas Loizou, Sadra Boreiri, Martin Jaggi, and Sebastian Stich. A unified theory of decentralized sgd with changing topology and local updates. In International conference on machine learning, pages 5381–5393. PMLR, 2020
2020
-
[11]
Decentralized bilevel opti- mization: A perspective from transient iteration complexity
Boao Kong, Shuchen Zhu, Songtao Lu, Xinmeng Huang, and Kun Yuan. Decentralized bilevel opti- mization: A perspective from transient iteration complexity. Journal of Machine Learning Research , 26 (240):1–64, 2025
2025
-
[12]
Can decentralized algorithms outperform centralized algorithms? a case study for decentralized parallel stochastic gradient descent
Xiangru Lian, Ce Zhang, Huan Zhang, Cho-Jui Hsieh, Wei Zhang, and Ji Liu. Can decentralized algorithms outperform centralized algorithms? a case study for decentralized parallel stochastic gradient descent. Advances in Neural Information Processing Systems , 30, 2017
2017
-
[13]
Muon is Scalable for LLM Training
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, et al. Muon is scalable for llm training. arXiv preprint arXiv:2502.16982 , 2025. 42
work page internal anchor Pith review arXiv 2025
-
[14]
Junkang Liu, Fanhua Shang, Junchao Zhou, Hongying Liu, Yuanyuan Liu, and Jin Liu. Fedmuon: Accelerating federated learning with matrix orthogonalization. arXiv preprint arXiv:2510.27403 , 2025
-
[15]
Communication-efficient learning of deep networks from decentralized data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics , pages 1273–1282. PMLR, 2017
2017
-
[16]
Dadam: A consensus-based dis- tributed adaptive gradient method for online optimization
Parvin Nazari, Davoud Ataee Tarzanagh, and George Michailidis. Dadam: A consensus-based dis- tributed adaptive gradient method for online optimization. IEEE Transactions on Signal Processing , 70:6065–6079, 2022
2022
-
[17]
Multi-agent optimization
Angelia Nedić, Jong-Shi Pang, Gesualdo Scutari, and Ying Sun. Multi-agent optimization . Springer, 2018
2018
-
[18]
Training deep learning models with norm-constrained lmos.arXiv preprint arXiv:2502.07529, 2025
Thomas Pethick, Wanyun Xie, Kimon Antonakopoulos, Zhenyu Zhu, Antonio Silveti-Falls, and Volkan Cevher. Training deep learning models with norm-constrained lmos. arXiv preprint arXiv:2502.07529 , 2025
-
[19]
Distributed stochastic gradient tracking methods
Shi Pu and Angelia Nedić. Distributed stochastic gradient tracking methods. Mathematical Program- ming, 187(1):409–457, 2021
2021
-
[20]
Artem Riabinin, Egor Shulgin, Kaja Gruntkowska, and Peter Richtárik. Gluon: Making muon & scion great again!(bridging theory and practice of lmo-based optimizers for llms). arXiv preprint arXiv:2505.13416, 2025
-
[21]
Adafactor: Adaptive learning rates with sublinear memory cost
Noam Shazeer and Mitchell Stern. Adafactor: Adaptive learning rates with sublinear memory cost. In International Conference on Machine Learning , pages 4596–4604. PMLR, 2018
2018
-
[22]
On the Convergence Analysis of Muon
Wei Shen, Ruichuan Huang, Minhui Huang, Cong Shen, and Jiawei Zhang. On the convergence analysis of muon. arXiv preprint arXiv:2505.23737 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Extra: An exact first-order algorithm for decentralized consensus optimization
Wei Shi, Qing Ling, Gang Wu, and Wotao Yin. Extra: An exact first-order algorithm for decentralized consensus optimization. SIAM Journal on Optimization , 25(2):944–966, 2015
2015
-
[24]
Yuki Takezawa, Anastasia Koloskova, Xiaowen Jiang, and Sebastian U Stich. Fedmuon: Federated learning with bias-corrected lmo-based optimization. arXiv preprint arXiv:2509.26337 , 2025
-
[25]
D 2: Decentralized training over decen- tralized data
Hanlin Tang, Xiangru Lian, Ming Yan, Ce Zhang, and Ji Liu. D 2: Decentralized training over decen- tralized data. In International Conference on Machine Learning , pages 4848–4856. PMLR, 2018
2018
-
[26]
Reasflow: Assisting reasoning-centric scientific discovery in applied mathematics via a knowledge-based multi-agent system, 2026
ReasFlow Team. Reasflow: Assisting reasoning-centric scientific discovery in applied mathematics via a knowledge-based multi-agent system, 2026. URL https://blog.reaslab.io/blog/reasflow-intro/
2026
-
[27]
Muon outperforms Adam in tail-end associative memory learning.arXiv preprint arXiv:2509.26030, 2025
Shuche Wang, Fengzhuo Zhang, Jiaxiang Li, Cunxiao Du, Chao Du, Tianyu Pang, Zhuoran Yang, Mingyi Hong, and Vincent YF Tan. Muon outperforms adam in tail-end associative memory learning. arXiv preprint arXiv:2509.26030 , 2025
-
[28]
A survey of distributed optimization
Tao Yang, Xinlei Yi, Junfeng Wu, Ye Yuan, Di Wu, Ziyang Meng, Yiguang Hong, Hong Wang, Zongli Lin, and Karl H Johansson. A survey of distributed optimization. Annual Reviews in Control , 47: 278–305, 2019
2019
-
[29]
Exponential graph is provably efficient for decentralized deep training
Bicheng Ying, Kun Yuan, Yiming Chen, Hanbin Hu, Pan Pan, and Wotao Yin. Exponential graph is provably efficient for decentralized deep training. Advances in Neural Information Processing Systems , 34:13975–13987, 2021
2021
-
[30]
Decentralized training of foundation models in heterogeneous environments
Binhang Yuan, Yongjun He, Jared Davis, Tianyi Zhang, Tri Dao, Beidi Chen, Percy S Liang, Christo- pher Re, and Ce Zhang. Decentralized training of foundation models in heterogeneous environments. Advances in Neural Information Processing Systems , 35:25464–25477, 2022. 43
2022
-
[31]
Removing data heterogeneity influence enhances network topology dependence of decentralized sgd
Kun Yuan, Sulaiman A Alghunaim, and Xinmeng Huang. Removing data heterogeneity influence enhances network topology dependence of decentralized sgd. Journal of Machine Learning Research , 24 (280):1–53, 2023
2023
-
[32]
Sparkle: a unified single- loop primal-dual framework for decentralized bilevel optimization
Shuchen Zhu, Boao Kong, Songtao Lu, Xinmeng Huang, and Kun Yuan. Sparkle: a unified single- loop primal-dual framework for decentralized bilevel optimization. Advances in Neural Information Processing Systems, 37:62912–62987, 2024. 44
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.