Recognition: unknown
SMoES: Soft Modality-Guided Expert Specialization in MoE-VLMs
Pith reviewed 2026-05-08 04:36 UTC · model grok-4.3
The pith
Dynamic soft modality scores align expert routing to layer-dependent fusion in MoE-VLMs
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
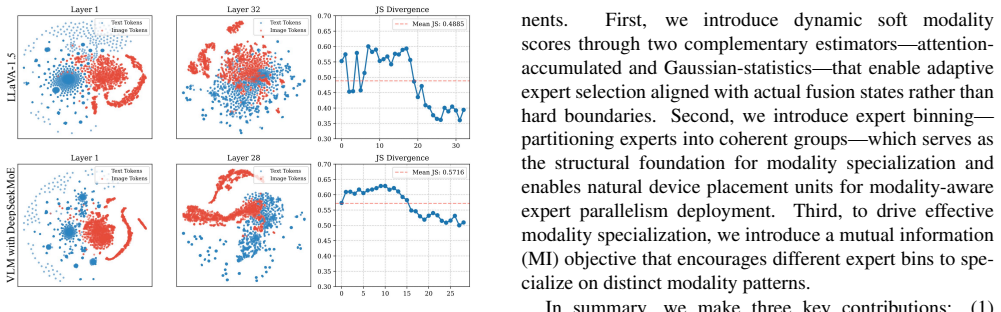
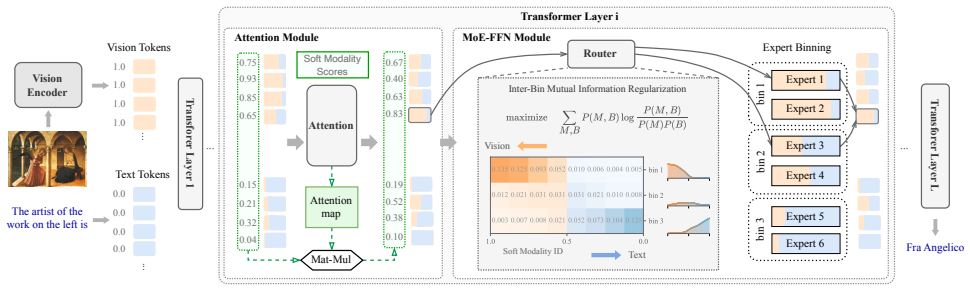
SMoES computes layer-specific soft modality scores from either attention weights or Gaussian statistics, bins experts for expert-parallel hardware, and applies mutual information regularization across bins to encourage modality-aware specialization that respects observed fusion patterns in MoE-VLMs.
What carries the argument
Dynamic soft modality scores paired with inter-bin mutual information regularization that steer expert assignment toward modality coherence
If this is right
- Average gains of 0.9 percent on multimodal tasks and 4.2 percent on language-only tasks across the sixteen benchmarks.
- Reduction of expert-parallel communication overhead by 56.1 percent.
- Throughput increase of 12.3 percent under realistic deployment conditions.
Where Pith is reading between the lines
- The same scoring and regularization pattern could be tested in non-VLM multimodal models that use expert parallelism.
- Layer-wise analysis of the learned scores might expose which depths benefit most from modality guidance.
- SMoES could be combined with learned router parameters to explore hybrid static-dynamic routing.
Load-bearing premise
The soft modality scores and mutual information regularization will produce stable expert specialization that matches real layer-wise fusion patterns without instability or negative transfer.
What would settle it
Replace SMoES routing with a standard modality-agnostic router in the same four VLMs, rerun the sixteen benchmarks, and observe zero or negative change in the reported accuracy, communication, and throughput metrics.
Figures







read the original abstract
Mixture-of-Experts (MoE) has become a prevalent backbone for large vision-language models (VLMs), yet how modality-specific signals should guide expert routing remains under-explored. Existing routing strategies are either hand-crafted or modality-agnostic, relying on idealized priors that ignore the layer-dependent modality fusion patterns in MoE-VLMs and provide little guidance for expert specialization. We propose Soft Modality-guided Expert Specialization (SMoES), which consists of dynamic soft modality scores that capture layer-dependent fusion patterns, an expert binning mechanism aligned with expert-parallel deployment, and an inter-bin mutual information regularization that encourages coherent modality specialization. Our method leverages attention-based or Gaussian-statistics modality scores to optimize mutual information regularization. Experiments across four MoE-based VLMs and 16 benchmarks demonstrate improvement on both effectiveness and efficiency: 0.9% and 4.2% average gain on multimodal and language-only tasks, 56.1% reduction in EP communication overhead, and 12.3% throughput improvement under realistic deployment. These results validate that aligning routing with modality-aware expert specialization unlocks MoE-VLM capacity and efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Soft Modality-guided Expert Specialization (SMoES) for Mixture-of-Experts vision-language models. It introduces dynamic soft modality scores (via attention or Gaussian statistics) to capture layer-dependent fusion patterns, an expert binning mechanism aligned with expert-parallel deployment, and inter-bin mutual information regularization to promote coherent modality specialization. Experiments on four MoE-VLMs across 16 benchmarks report average gains of 0.9% on multimodal tasks and 4.2% on language-only tasks, plus efficiency gains of 56.1% reduced EP communication overhead and 12.3% higher throughput.
Significance. If the empirical results hold under rigorous validation, the work would be moderately significant for the MoE-VLM community. It directly targets an under-explored gap—modality-aware routing that respects layer-dependent fusion—rather than relying on hand-crafted or modality-agnostic strategies. The combination of soft scores, deployment-aligned binning, and MI regularization is a coherent empirical proposal, and the multi-model, multi-benchmark evaluation (four VLMs, 16 tasks) provides a reasonable breadth for assessing practical impact on both accuracy and efficiency. Strengths include the explicit linkage to expert-parallel deployment constraints and the focus on avoiding negative transfer via regularization.
major comments (2)
- [Abstract] Abstract: The headline performance claims (0.9% multimodal and 4.2% language-only average gains, 56.1% EP overhead reduction, 12.3% throughput improvement) are presented without any description of the baselines, number of runs, variance, statistical significance testing, or ablation studies. This absence makes it impossible to determine whether the reported deltas are robust or attributable to the proposed components rather than implementation details or hyperparameter tuning.
- [Method / Experiments] The central assumption that dynamic soft modality scores plus inter-bin MI regularization produce stable, layer-aware expert specialization without negative transfer or routing instability is load-bearing for the efficiency and effectiveness claims, yet no analysis of routing entropy, expert utilization histograms, or failure cases under this regularization is referenced.
minor comments (2)
- [Abstract] The abstract would be clearer if it named the four specific MoE-VLMs and the 16 benchmarks (or at least their categories) rather than leaving them as aggregates.
- [Abstract] Notation for the soft modality scores and the mutual-information term should be introduced with explicit equations even in the abstract to avoid ambiguity between attention-based and Gaussian-statistics variants.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and have revised the manuscript to improve the presentation of empirical results and add supporting analysis on routing behavior.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline performance claims (0.9% multimodal and 4.2% language-only average gains, 56.1% EP overhead reduction, 12.3% throughput improvement) are presented without any description of the baselines, number of runs, variance, statistical significance testing, or ablation studies. This absence makes it impossible to determine whether the reported deltas are robust or attributable to the proposed components rather than implementation details or hyperparameter tuning.
Authors: We agree that the abstract would benefit from additional context to allow readers to assess the robustness of the reported gains. In the revised manuscript, we have updated the abstract to note that results are averaged over three independent runs, with standard deviations and full baseline comparisons (including standard MoE routing and modality-agnostic variants) provided in Section 4 and Table 1. Ablation studies isolating each component are detailed in Section 4.3, and statistical significance is assessed via paired t-tests as described in the experimental protocol. These changes preserve abstract conciseness while directing readers to the supporting evidence. revision: yes
-
Referee: [Method / Experiments] The central assumption that dynamic soft modality scores plus inter-bin MI regularization produce stable, layer-aware expert specialization without negative transfer or routing instability is load-bearing for the efficiency and effectiveness claims, yet no analysis of routing entropy, expert utilization histograms, or failure cases under this regularization is referenced.
Authors: We acknowledge the value of explicit validation for routing stability. The original manuscript contains ablations on the MI regularization and modality scoring mechanisms in Section 4.3, demonstrating performance improvements without degradation. However, we did not include dedicated analysis of routing entropy or utilization histograms. In the revision, we have added a new subsection (Section 4.4) with layer-wise routing entropy plots, modality-specific expert utilization histograms, and a brief discussion of observed edge cases (e.g., high-variance layers). These additions confirm stable specialization and absence of negative transfer under the proposed regularization. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents SMoES as an empirical proposal: dynamic soft modality scores (attention-based or Gaussian-statistics), expert binning for EP deployment, and inter-bin MI regularization to encourage specialization. The headline gains (0.9%/4.2% task improvements, 56.1% EP overhead reduction, 12.3% throughput) are reported from experiments across four VLMs and 16 benchmarks. No equations, derivations, or self-citations are shown that reduce these outcomes to quantities defined by the method's own fitted parameters or prior author results. The mechanism is described as a practical routing alignment without load-bearing self-referential steps or renaming of known patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Inclusion AI, Biao Gong, Cheng Zou, Chuanyang Zheng, Chunluan Zhou, Canxiang Yan, Chunxiang Jin, Chunjie Shen, Dandan Zheng, Fudong Wang, et al. Ming-omni: A unified multimodal model for perception and generation. arXiv preprint arXiv:2506.09344, 2025. 2
-
[2]
Vlmo: Unified vision-language pre-training with mixture-of-modality-experts.Advances in neural information processing systems, 35:32897–32912,
Hangbo Bao, Wenhui Wang, Li Dong, Qiang Liu, Owais Khan Mohammed, Kriti Aggarwal, Subhojit Som, Songhao Piao, and Furu Wei. Vlmo: Unified vision-language pre-training with mixture-of-modality-experts.Advances in neural information processing systems, 35:32897–32912,
-
[3]
Chaoxiang Cai, Longrong Yang, Kaibing Chen, Fan Yang, and Xi Li. Long-tailed distribution-aware router for mixture- of-experts in large vision-language model.arXiv preprint arXiv:2507.01351, 2025. 3
-
[4]
Eve: Efficient vision- language pre-training with masked prediction and modality- aware moe
Junyi Chen, Longteng Guo, Jia Sun, Shuai Shao, Zehuan Yuan, Liang Lin, and Dongyu Zhang. Eve: Efficient vision- language pre-training with masked prediction and modality- aware moe. InProceedings of the AAAI Conference on Arti- ficial Intelligence, pages 1110–1119, 2024. 3
2024
-
[5]
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InEuropean Conference on Computer Vision, pages 19–35. Springer, 2024. 2
2024
-
[6]
Shaoxiang Chen, Zequn Jie, and Lin Ma. Llava-mole: Sparse mixture of lora experts for mitigating data con- flicts in instruction finetuning mllms.arXiv preprint arXiv:2401.16160, 2024. 2
-
[7]
Zitian Chen, Mingyu Ding, Yikang Shen, Wei Zhan, Masayoshi Tomizuka, Erik Learned-Miller, and Chuang Gan. An efficient general-purpose modular vision model via multi-task heterogeneous training.arXiv preprint arXiv:2306.17165, 2023. 2
-
[8]
Mod-squad: Designing mixtures of experts as modular multi-task learners
Zitian Chen, Yikang Shen, Mingyu Ding, Zhenfang Chen, Hengshuang Zhao, Erik G Learned-Miller, and Chuang Gan. Mod-squad: Designing mixtures of experts as modular multi-task learners. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 11828–11837, 2023. 2
2023
-
[9]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review arXiv
-
[10]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Train- ing verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021. 5
work page internal anchor Pith review arXiv 2021
-
[11]
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
Damai Dai, Chengqi Deng, Chenggang Zhao, RX Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Yu Wu, et al. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models.arXiv preprint arXiv:2401.06066, 2024. 1, 5
work page internal anchor Pith review arXiv 2024
-
[12]
Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christo- pher R ´e. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022. 2
2022
-
[13]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[14]
Switch transformers: Scaling to trillion parameter models with sim- ple and efficient sparsity.Journal of Machine Learning Re- search, 23(120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with sim- ple and efficient sparsity.Journal of Machine Learning Re- search, 23(120):1–39, 2022. 1, 2, 3
2022
-
[15]
Jinyuan Feng, Chaopeng Wei, Tenghai Qiu, Tianyi Hu, and Zhiqiang Pu. Comoe: Contrastive representation for mixture-of-experts in parameter-efficient fine-tuning.arXiv preprint arXiv:2505.17553, 2025. 2
-
[16]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation bench- mark for multimodal large language models.arXiv preprint arXiv:2306.13394, 2023. 5
work page internal anchor Pith review arXiv 2023
-
[17]
Making the v in vqa matter: Elevating the role of image understanding in visual question answer- ing
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Ba- tra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answer- ing. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913, 2017. 5
2017
-
[18]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1. 5-vl technical report.arXiv preprint arXiv:2505.07062, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[19]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633– 638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633– 638, 2025. 1
2025
-
[20]
Shwai He, Weilin Cai, Jiayi Huang, and Ang Li. Capacity- aware inference: Mitigating the straggler effect in mixture of experts.arXiv preprint arXiv:2503.05066, 2025. 3
work page internal anchor Pith review arXiv 2025
-
[21]
Mea- suring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Mea- suring massive multitask language understanding. InInter- national Conference on Learning Representations, 2021. 5
2021
-
[22]
Glm-4.1 v-thinking: Towards versatile multi- modal reasoning with scalable reinforcement learning.arXiv e-prints, pages arXiv–2507, 2025
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guob- ing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Li- hang Pan, et al. Glm-4.1 v-thinking: Towards versatile multi- modal reasoning with scalable reinforcement learning.arXiv e-prints, pages arXiv–2507, 2025. 1, 2
2025
-
[23]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 6700–6709, 2019. 5
2019
-
[24]
Chat-univi: Unified visual representation em- powers large language models with image and video un- derstanding
Peng Jin, Ryuichi Takanobu, Wancai Zhang, Xiaochun Cao, and Li Yuan. Chat-univi: Unified visual representation em- powers large language models with image and video un- derstanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13700– 13710, 2024. 2
2024
-
[25]
Linglin Jing, Yuting Gao, Zhigang Wang, Wang Lan, Yi- wen Tang, Wenhai Wang, Kaipeng Zhang, and Qingpei Guo. Evomoe: Expert evolution in mixture of experts for multimodal large language models.arXiv preprint arXiv:2505.23830, 2025. 2
-
[26]
Beyond distillation: Task-level mixture-of-experts for efficient inference
Sneha Kudugunta, Yanping Huang, Ankur Bapna, Maxim Krikun, Dmitry Lepikhin, Minh-Thang Luong, and Orhan Firat. Beyond distillation: Task-level mixture-of-experts for efficient inference.arXiv preprint arXiv:2110.03742, 2021. 1
-
[27]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding.arXiv preprint arXiv:2006.16668, 2020. 1, 2
work page internal anchor Pith review arXiv 2006
-
[28]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InThe 2023 Conference on Empir- ical Methods in Natural Language Processing, 2023. 5
2023
-
[29]
Uni- moe: Scaling unified multimodal llms with mixture of ex- perts.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Yunxin Li, Shenyuan Jiang, Baotian Hu, Longyue Wang, Wanqi Zhong, Wenhan Luo, Lin Ma, and Min Zhang. Uni- moe: Scaling unified multimodal llms with mixture of ex- perts.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 2
2025
-
[30]
Mixture-of- transformers: A sparse and scalable architecture for multi- modal foundation models.Transactions on Machine Learn- ing Research, 2025
Weixin Liang, LILI YU, Liang Luo, Srini Iyer, Ning Dong, Chunting Zhou, Gargi Ghosh, Mike Lewis, Wen tau Yih, Luke Zettlemoyer, and Xi Victoria Lin. Mixture-of- transformers: A sparse and scalable architecture for multi- modal foundation models.Transactions on Machine Learn- ing Research, 2025. 2
2025
-
[31]
arXiv preprint arXiv:2401.15947 , year=
Bin Lin, Zhenyu Tang, Yang Ye, Jiaxi Cui, Bin Zhu, Peng Jin, Jinfa Huang, Junwu Zhang, Yatian Pang, Munan Ning, et al. Moe-llava: Mixture of experts for large vision- language models.arXiv preprint arXiv:2401.15947, 2024. 2
-
[32]
TruthfulQA: Measuring How Models Mimic Human Falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods.arXiv preprint arXiv:2109.07958, 2021. 5
work page internal anchor Pith review arXiv 2021
-
[33]
Moma: Efficient early-fusion pre-training with mixture of modality-aware experts
Xi Victoria Lin, Akshat Shrivastava, Liang Luo, Srinivasan Iyer, Mike Lewis, Gargi Ghosh, Luke Zettlemoyer, and Ar- men Aghajanyan. Moma: Efficient early-fusion pre-training with mixture of modality-aware experts.arXiv preprint arXiv:2407.21770, 2024. 2
-
[34]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437, 2024. 2
work page internal anchor Pith review arXiv 2024
-
[35]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024. 1, 5
2024
-
[36]
Muon is Scalable for LLM Training
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, et al. Muon is scalable for llm training.arXiv preprint arXiv:2502.16982, 2025. 5, 1
work page internal anchor Pith review arXiv 2025
-
[37]
Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vi- sion, pages 216–233
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vi- sion, pages 216–233. Springer, 2024. 5
2024
-
[38]
Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in Neural Information Processing Systems, 35:2507–2521,
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in Neural Information Processing Systems, 35:2507–2521,
-
[39]
Mono-internvl: Pushing the boundaries of monolithic multimodal large lan- guage models with endogenous visual pre-training
Gen Luo, Xue Yang, Wenhan Dou, Zhaokai Wang, Jiawen Liu, Jifeng Dai, Yu Qiao, and Xizhou Zhu. Mono-internvl: Pushing the boundaries of monolithic multimodal large lan- guage models with endogenous visual pre-training. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 24960–24971, 2025. 2, 5, 6, 3
2025
-
[40]
Deepstack: Deeply stacking visual tokens is surprisingly simple and ef- fective for lmms.Advances in Neural Information Process- ing Systems, 37:23464–23487, 2024
Lingchen Meng, Jianwei Yang, Rui Tian, Xiyang Dai, Zux- uan Wu, Jianfeng Gao, and Yu-Gang Jiang. Deepstack: Deeply stacking visual tokens is surprisingly simple and ef- fective for lmms.Advances in Neural Information Process- ing Systems, 37:23464–23487, 2024. 2
2024
-
[41]
Smith, Pang Wei Koh, Aman- preet Singh, and Hannaneh Hajishirzi
Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Evan Pete Walsh, Oyvind Tafjord, Nathan Lambert, Yuling Gu, Shane Arora, Akshita Bhagia, Dustin Schwenk, David Wadden, Alexander Wettig, Binyuan Hui, Tim Dettmers, Douwe Kiela, Ali Farhadi, Noah A. Smith, Pang Wei Koh, Aman- preet Singh, and Hannaneh Hajish...
2025
-
[42]
Multimodal contrastive learn- ing with limoe: the language-image mixture of experts.Ad- vances in Neural Information Processing Systems, 35:9564– 9576, 2022
Basil Mustafa, Carlos Riquelme, Joan Puigcerver, Rodolphe Jenatton, and Neil Houlsby. Multimodal contrastive learn- ing with limoe: the language-image mixture of experts.Ad- vances in Neural Information Processing Systems, 35:9564– 9576, 2022. 1, 3, 5
2022
-
[43]
From sparse to soft mixtures of experts
Joan Puigcerver, Carlos Riquelme Ruiz, Basil Mustafa, and Neil Houlsby. From sparse to soft mixtures of experts. In The Twelfth International Conference on Learning Represen- tations, 2024. 2
2024
-
[44]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 5, 1
2021
-
[45]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outra- geously large neural networks: The sparsely-gated mixture- of-experts layer.arXiv preprint arXiv:1701.06538, 2017. 1, 2, 3
work page internal anchor Pith review arXiv 2017
-
[46]
Mome: Mixture of multimodal experts for gen- eralist multimodal large language models.Advances in neu- ral information processing systems, 37:42048–42070, 2024
Leyang Shen, Gongwei Chen, Rui Shao, Weili Guan, and Liqiang Nie. Mome: Mixture of multimodal experts for gen- eralist multimodal large language models.Advances in neu- ral information processing systems, 37:42048–42070, 2024. 2
2024
-
[47]
Scaling vision-language models with sparse mixture of experts
Sheng Shen, Zhewei Yao, Chunyuan Li, Trevor Darrell, Kurt Keutzer, and Yuxiong He. Scaling vision-language models with sparse mixture of experts. InThe 2023 Conference on Empirical Methods in Natural Language Processing, 2023. 2
2023
-
[48]
Moduleformer: Mod- ularity emerges from mixture-of-experts.arXiv preprint arXiv:2306.04640, 2023
Yikang Shen, Zheyu Zhang, Tianyou Cao, Shawn Tan, Zhenfang Chen, and Chuang Gan. Moduleformer: Mod- ularity emerges from mixture-of-experts.arXiv preprint arXiv:2306.04640, 2023. 2
-
[49]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8317–8326, 2019. 5
2019
-
[50]
Yehui Tang, Xiaosong Li, Fangcheng Liu, Wei Guo, Hang Zhou, Yaoyuan Wang, Kai Han, Xianzhi Yu, Jinpeng Li, Hui Zang, et al. Pangu pro moe: Mixture of grouped experts for efficient sparsity.arXiv preprint arXiv:2505.21411, 2025. 3
-
[51]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chen- zhuang Du, Chu Wei, et al. Kimi-vl technical report.arXiv preprint arXiv:2504.07491, 2025. 1, 2
work page internal anchor Pith review arXiv 2025
-
[52]
Bin Wang, Bojun Wang, Changyi Wan, Guanzhe Huang, Hanpeng Hu, Haonan Jia, Hao Nie, Mingliang Li, Nuo Chen, Siyu Chen, et al. Step-3 is large yet affordable: Model- system co-design for cost-effective decoding.arXiv preprint arXiv:2507.19427, 2025. 2
-
[53]
Dianyi Wang, Siyuan Wang, Zejun Li, Yikun Wang, Yi- tong Li, Duyu Tang, Xiaoyu Shen, Xuanjing Huang, and Zhongyu Wei. Moiie: Mixture of intra-and inter-modality experts for large vision language models.arXiv preprint arXiv:2508.09779, 2025. 1, 2, 5, 6, 3
-
[54]
Shaoyu Wang, Guangrong He, Geon-Woo Kim, Yanqi Zhou, and Seo Jin Park. Toward cost-efficient serving of mixture-of-experts with asynchrony.arXiv preprint arXiv:2505.08944, 2025. 3
-
[55]
Image as a foreign language: Beit pretraining for vision and vision- language tasks
Wenhui Wang, Hangbo Bao, Li Dong, Johan Bjorck, Zhil- iang Peng, Qiang Liu, Kriti Aggarwal, Owais Khan Mo- hammed, Saksham Singhal, Subhojit Som, et al. Image as a foreign language: Beit pretraining for vision and vision- language tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19175– 19186, 2023. 1, 2
2023
-
[56]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025. 1, 2
work page internal anchor Pith review arXiv 2025
-
[57]
Note on a method for calculating cor- rected sums of squares and products.Technometrics, 4(3): 419–420, 1962
Barry Payne Welford. Note on a method for calculating cor- rected sums of squares and products.Technometrics, 4(3): 419–420, 1962. 4
1962
-
[58]
Haoyuan Wu, Haoxing Chen, Xiaodong Chen, Zhanchao Zhou, Tieyuan Chen, Yihong Zhuang, Guoshan Lu, Zenan Huang, Junbo Zhao, Lin Liu, et al. Grove moe: Towards ef- ficient and superior moe llms with adjugate experts.arXiv preprint arXiv:2508.07785, 2025. 3
-
[59]
Mixture of loRA experts
Xun Wu, Shaohan Huang, and Furu Wei. Mixture of loRA experts. InThe Twelfth International Conference on Learn- ing Representations, 2024. 2
2024
-
[60]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, et al. Deepseek-vl2: Mixture-of- experts vision-language models for advanced multimodal understanding.arXiv preprint arXiv:2412.10302, 2024. 1, 2
work page internal anchor Pith review arXiv 2024
-
[61]
Guoyang Xia, Yifeng Ding, Fengfa Li, Lei Ren, Wei Chen, Fangxiang Feng, and Xiaojie Wang. Smar: Soft modality- aware routing strategy for moe-based multimodal large language models preserving language capabilities.arXiv preprint arXiv:2506.06406, 2025. 3, 5, 6
-
[62]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 5, 1
work page internal anchor Pith review arXiv 2025
-
[63]
Longrong Yang, Dong Shen, Chaoxiang Cai, Fan Yang, Tingting Gao, Di Zhang, and Xi Li. Solving token gradi- ent conflict in mixture-of-experts for large vision-language model.arXiv preprint arXiv:2406.19905, 2024. 3
-
[64]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for ex- pert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for ex- pert agi. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9556– 9567, 2024. 5
2024
-
[65]
HellaSwag: Can a Machine Really Finish Your Sentence?
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence?arXiv preprint arXiv:1905.07830, 2019. 5
work page internal anchor Pith review arXiv 1905
-
[66]
Ef- ficientmoe: Optimizing mixture-of-experts model training with adaptive load balance.IEEE Transactions on Parallel and Distributed Systems, 2025
Yan Zeng, Chengchuang Huang, Yipeng Mei, Lifu Zhang, Teng Su, Wei Ye, Wenqi Shi, and Shengnan Wang. Ef- ficientmoe: Optimizing mixture-of-experts model training with adaptive load balance.IEEE Transactions on Parallel and Distributed Systems, 2025. 3
2025
-
[67]
Learn to be efficient: Build structured sparsity in large lan- guage models.Advances in Neural Information Processing Systems, 37:101969–101991, 2024
Haizhong Zheng, Xiaoyan Bai, Xueshen Liu, Zhuo- qing Morley Mao, Beidi Chen, Fan Lai, and Atul Prakash. Learn to be efficient: Build structured sparsity in large lan- guage models.Advances in Neural Information Processing Systems, 37:101969–101991, 2024. 2
2024
-
[68]
Mixture-of-experts with expert choice routing.Ad- vances in Neural Information Processing Systems, 35:7103– 7114, 2022
Yanqi Zhou, Tao Lei, Hanxiao Liu, Nan Du, Yanping Huang, Vincent Zhao, Andrew M Dai, Quoc V Le, James Laudon, et al. Mixture-of-experts with expert choice routing.Ad- vances in Neural Information Processing Systems, 35:7103– 7114, 2022. 2 Soft Modality-Guided Expert Specialization in MoE-VLMs Supplementary Material
2022
-
[69]
Detailed Experimental Setup 1.1. Vision Encoder and Projector All VLM configurations use the same vision encoder and projector so that backbone and routing changes are the only variables: Vision Encoder:CLIP ViT-L/14 [44] with 336×336 in- put resolution, producing 576 visual tokens for every im- age.Projector:A two-layer MLP with GELU activation that maps...
2048
-
[70]
Main results on Moonlight-MoE and Qwen3- MoE In addition to the primary evaluation on DeepSeekMoE and OLMoE reported in Tab
Supplementary Results 2.1. Main results on Moonlight-MoE and Qwen3- MoE In addition to the primary evaluation on DeepSeekMoE and OLMoE reported in Tab. 1, we provide the detailed per- formance on Moonlight-MoE and Qwen3-MoE in Tab. S4. The results demonstrate that SMoES consistently outper- forms various routing baselines across these backbones, ex- hibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.