Recognition: unknown
TCOD: Exploring Temporal Curriculum in On-Policy Distillation for Multi-turn Autonomous Agents
Pith reviewed 2026-05-08 04:36 UTC · model grok-4.3
The pith
A temporal curriculum that gradually increases trajectory length stabilizes on-policy distillation for multi-turn agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
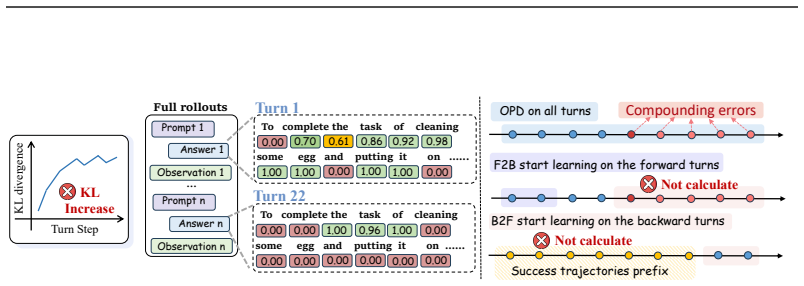
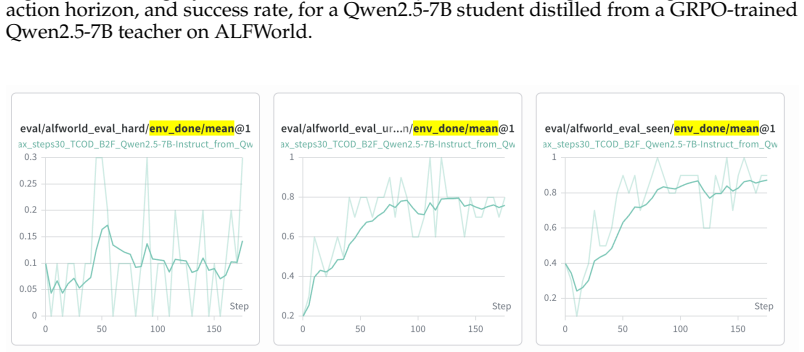
Vanilla on-policy distillation exhibits Trajectory-Level KL Instability in multi-turn environments because inter-turn error compounding drives the student outside the teacher's reliable distribution; the temporal curriculum that starts with short trajectories and progressively expands their depth directly counters this compounding, yielding lower and more stable KL throughout training together with higher agent success rates.
What carries the argument
The temporal curriculum schedule that controls and expands the maximum trajectory depth presented to the student during distillation.
If this is right
- KL divergence stays lower and more stable for the entire training run instead of escalating.
- Final agent success rates rise substantially compared with standard on-policy distillation.
- The distilled student can outperform the original teacher on some tasks.
- The student succeeds on instances where the teacher itself fails.
Where Pith is reading between the lines
- The same progressive-length schedule could be tested with other distillation or reinforcement objectives that suffer from compounding error.
- Curriculum control of horizon length may become a standard ingredient when distilling long-horizon agents rather than an optional add-on.
- If the mechanism is error compounding, similar instability should appear in any multi-step imitation or RL setting that uses on-policy sampling without depth limits.
Load-bearing premise
The observed KL escalation is caused mainly by inter-turn error compounding and that lengthening trajectories via curriculum will fix it without introducing new instabilities.
What would settle it
Running the same student-teacher pairs on the same benchmarks with the curriculum schedule but still observing rising KL divergence and no gain in success rate.
Figures







read the original abstract
On-policy distillation (OPD) has shown strong potential for transferring reasoning ability from frontier or domain-specific models to smaller students. While effective on static single-turn tasks, its behavior in multi-turn agent settings remains underexplored. In this work, we identify a key limitation of vanilla OPD in such settings, which we term Trajectory-Level KL Instability. Specifically, we observe that KL divergence increases together with a drop in success rate, and even after convergence, the KL remains high, leading to unstable training. This instability arises from inter-turn error compounding: as errors accumulate, the student is driven beyond the teacher's effective support, rendering the supervision signal unreliable. To address this, we propose TCOD (Temporal Curriculum On-Policy Distillation), a simple yet effective framework that controls the trajectory depth exposed to the student and progressively expands it from short to long with a curriculum schedule. Experimental results across four student-teacher pairs on three multi-turn agent benchmarks (ALFWorld, WebShop, ScienceWorld) show that TCOD mitigates KL escalation and enhances KL stability throughout training, improving agent performance by up to 18 points over vanilla OPD. Further evaluations show that TCOD can even surpass the teacher's performance and generalize to tasks on which the teacher fails. Our code is available at https://github.com/kokolerk/TCOD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
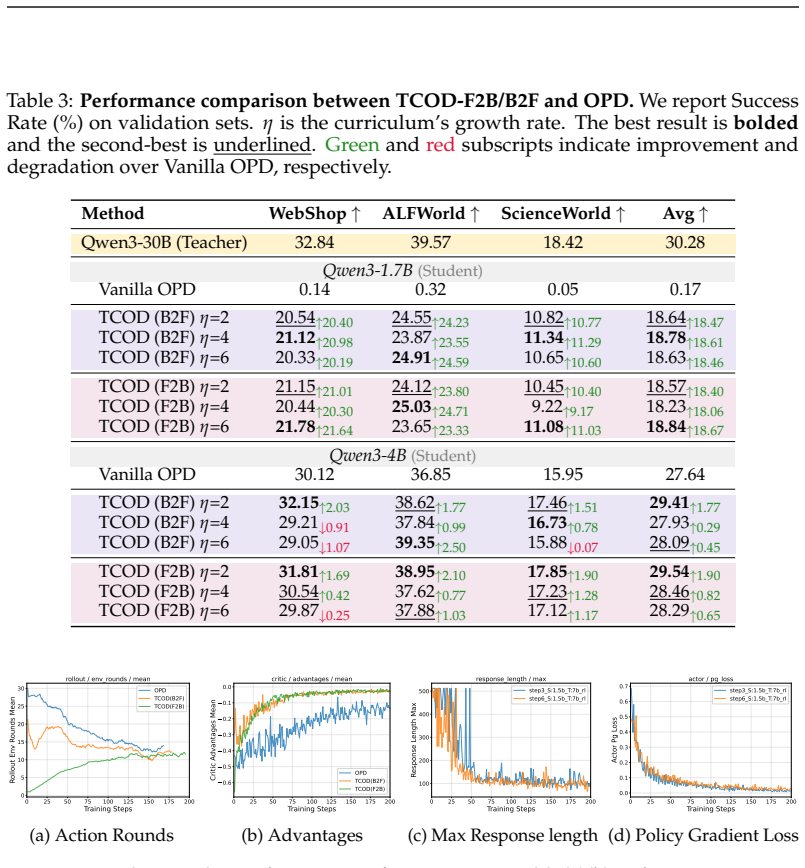
Summary. The paper identifies Trajectory-Level KL Instability in vanilla on-policy distillation (OPD) for multi-turn autonomous agents, attributing it to inter-turn error compounding that drives the student outside the teacher's support. It proposes TCOD, which applies a temporal curriculum to progressively expand the depth of trajectories used for distillation from short to long according to a schedule. Experiments across four student-teacher pairs on ALFWorld, WebShop, and ScienceWorld benchmarks report that TCOD improves KL stability, yields up to 18-point gains over vanilla OPD, and enables the student to surpass the teacher on some tasks while generalizing to cases where the teacher fails.
Significance. If the reported gains and stability improvements hold under rigorous controls, the work supplies a practical, low-overhead technique for stabilizing on-policy distillation in sequential settings. The curriculum mechanism directly targets the identified compounding issue and could transfer to other multi-turn distillation or RL pipelines; the observation that students can exceed teachers on long trajectories is a useful empirical signal about teacher suboptimality.
major comments (2)
- [§4.2, Table 2] §4.2 and Table 2: the claim that TCOD 'mitigates KL escalation' requires explicit comparison of per-turn KL trajectories (not just final values) against vanilla OPD; without these curves or a statistical test on the slope of KL growth, the causal link to the curriculum schedule remains under-supported for the central stability claim.
- [§3.3] §3.3: the curriculum expansion schedule is listed as a free parameter; the paper should report sensitivity analysis over at least three different schedules (linear, exponential, task-adaptive) to show that the performance gains are not an artifact of a single tuned schedule.
minor comments (2)
- The abstract states 'up to 18 points' but the main text should include per-benchmark, per-pair deltas with standard errors and the exact number of seeds used.
- Figure 3 (KL stability plots) would benefit from shaded standard-error bands and a direct overlay of the vanilla OPD baseline on the same axes for immediate visual comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive evaluation of our work on TCOD for stabilizing on-policy distillation in multi-turn autonomous agents. We address each major comment below and will revise the manuscript accordingly to strengthen the evidence for our claims.
read point-by-point responses
-
Referee: [§4.2, Table 2] §4.2 and Table 2: the claim that TCOD 'mitigates KL escalation' requires explicit comparison of per-turn KL trajectories (not just final values) against vanilla OPD; without these curves or a statistical test on the slope of KL growth, the causal link to the curriculum schedule remains under-supported for the central stability claim.
Authors: We agree that per-turn KL trajectories and a statistical analysis of growth slopes would provide stronger support for the stability claim. The current manuscript reports final KL values in Table 2 along with success rates, but to directly address this point we will add new figures in the revised version showing the evolution of per-turn KL divergence over training steps for TCOD versus vanilla OPD on all three benchmarks. We will also include a linear regression analysis on the slopes of KL growth to quantify the reduction in escalation, thereby better linking the observed stability to the temporal curriculum mechanism. revision: yes
-
Referee: [§3.3] §3.3: the curriculum expansion schedule is listed as a free parameter; the paper should report sensitivity analysis over at least three different schedules (linear, exponential, task-adaptive) to show that the performance gains are not an artifact of a single tuned schedule.
Authors: We acknowledge that the expansion schedule is a hyperparameter in TCOD. While the main experiments use a linear schedule for its simplicity and progressive nature, we will incorporate sensitivity analysis in the revised manuscript. Specifically, we will evaluate and report results for linear, exponential, and task-adaptive schedules (where adaptation is based on per-task success thresholds) on the ALFWorld and WebShop benchmarks, demonstrating that the performance improvements remain consistent across these variants and are not tied to a single choice. revision: yes
Circularity Check
No significant circularity
full rationale
The paper identifies Trajectory-Level KL Instability as an empirical observation in vanilla OPD, attributes it to inter-turn error compounding, and introduces TCOD as a curriculum schedule that progressively expands trajectory depth. No equations, fitted parameters, or derivations are shown that reduce the claimed KL stability gains or performance improvements (up to 18 points) to a quantity defined by the method itself. The results are presented as experimental outcomes on ALFWorld, WebShop, and ScienceWorld benchmarks, with independent validation that the student can exceed the teacher on some tasks. No self-citation chains, ansatzes, or uniqueness theorems are invoked as load-bearing for the core mechanism. The derivation chain consists of observation plus empirical intervention and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- curriculum expansion schedule
axioms (1)
- domain assumption Inter-turn error compounding is the primary driver of Trajectory-Level KL Instability in vanilla on-policy distillation for multi-turn agents
Forward citations
Cited by 1 Pith paper
-
SOD: Step-wise On-policy Distillation for Small Language Model Agents
SOD reweights on-policy distillation strength step-by-step using divergence to stabilize tool use in small language model agents, yielding up to 20.86% gains and 26.13% on AIME 2025 for a 0.6B model.
Reference graph
Works this paper leans on
-
[1]
Group-in-Group Policy Optimization for LLM Agent Training
GitHub repository. Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for llm agent training.arXiv preprint arXiv:2505.10978,
work page internal anchor Pith review arXiv
-
[2]
Zhaoyan Gong, Zhiqiang Liu, Songze Li, Xiaoke Guo, Yuanxiang Liu, Xinle Deng, Zhizhen Liu, Lei Liang, Huajun Chen, and Wen Zhang. Temp-r1: A unified autonomous agent for complex temporal kgqa via reverse curriculum reinforcement learning.arXiv preprint arXiv:2601.18296,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Stable On-Policy Distillation through Adaptive Target Reformulation
GitHub repository. Ijun Jang, Jewon Yeom, Juan Yeo, Hyunggu Lim, and Taesup Kim. Stable on-policy distilla- tion through adaptive target reformulation.arXiv preprint arXiv:2601.07155,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Entropy-aware on-policy distillation of language models
Woogyeol Jin, Taywon Min, Yongjin Yang, Swanand Ravindra Kadhe, Yi Zhou, Dennis Wei, Nathalie Baracaldo, and Kimin Lee. Entropy-aware on-policy distillation of language models.arXiv preprint arXiv:2603.07079,
-
[5]
arXiv preprint arXiv:2603.11137 , year =
Jongwoo Ko, Sara Abdali, Young Jin Kim, Tianyi Chen, and Pashmina Cameron. Scaling reasoning efficiently via relaxed on-policy distillation.arXiv preprint arXiv:2603.11137,
-
[6]
Niklas Lauffer, Xiang Deng, Srivatsa Kundurthy, Brad Kenstler, and Jeff Da. Imita- tion learning for multi-turn lm agents via on-policy expert corrections.arXiv preprint arXiv:2512.14895,
-
[7]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, et al. Skillsbench: Benchmarking how well agent skills work across diverse tasks.arXiv preprint arXiv:2602.12670,
work page internal anchor Pith review arXiv
-
[8]
https://thinkingmachines.ai/blog/ on-policy-distillation/
doi: 10.64434/tml.20251026. https://thinkingmachines.ai/blog/on- policy-distillation. Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868,
-
[9]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Flo- rencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review arXiv
-
[10]
Xuchen Pan, Yanxi Chen, Yushuo Chen, Yuchang Sun, Daoyuan Chen, Wenhao Zhang, Yuexiang Xie, Yilun Huang, Yilei Zhang, Dawei Gao, Weijie Shi, Yaliang Li, Bolin Ding, and Jingren Zhou. Trinity-rft: A general-purpose and unified framework for reinforcement fine-tuning of large language models.arXiv preprint arXiv:2505.17826,
-
[11]
arXiv preprint arXiv:2602.04942 , year =
Emiliano Penaloza, Dheeraj Vattikonda, Nicolas Gontier, Alexandre Lacoste, Laurent Char- lin, and Massimo Caccia. Privileged information distillation for language models.arXiv preprint arXiv:2602.04942,
-
[12]
Efficient Reinforcement Finetuning via Adaptive Curriculum Learning.ArXiv, abs/2504.05520, 2025
Taiwei Shi, Yiyang Wu, Linxin Song, Tianyi Zhou, and Jieyu Zhao. Efficient reinforcement finetuning via adaptive curriculum learning.arXiv preprint arXiv:2504.05520,
-
[13]
11 Weijie Shi, Yanxi Chen, Zexi Li, Xuchen Pan, Yuchang Sun, Jiajie Xu, Xiaofang Zhou, and Yaliang Li. r3 l: Reflect-then-retry reinforcement learning with language-guided exploration, pivotal credit, and positive amplification.arXiv preprint arXiv:2601.03715,
-
[14]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre C ˆot´e, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interac- tive learning.arXiv preprint arXiv:2010.03768,
work page internal anchor Pith review arXiv 2010
-
[15]
Jiaqi Wang, Kevin Qinghong Lin, James Cheng, and Mike Zheng Shou. Think or not? selective reasoning via reinforcement learning for vision-language models.arXiv preprint arXiv:2505.16854, 2025a. Ruiyi Wang and Prithviraj Ammanabrolu. A practitioner’s guide to multi-turn agentic reinforcement learning.arXiv preprint arXiv:2510.01132,
-
[16]
Science- world: Is your agent smarter than a 5th grader? InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp
Ruoyao Wang, Peter Jansen, Marc-Alexandre Cˆot´e, and Prithviraj Ammanabrolu. Science- world: Is your agent smarter than a 5th grader? InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 11279–11298,
2022
-
[17]
OpenClaw-RL: Train Any Agent Simply by Talking
Yinjie Wang, Xuyang Chen, Xiaolong Jin, Mengdi Wang, and Ling Yang. Openclaw-rl: Train any agent simply by talking.arXiv preprint arXiv:2603.10165,
-
[18]
Zhenting Wang, Guofeng Cui, Yu-Jhe Li, Kun Wan, and Wentian Zhao. Dump: Auto- mated distribution-level curriculum learning for rl-based llm post-training.arXiv preprint arXiv:2504.09710, 2025b. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Hu...
-
[19]
On-Policy Context Distillation for Language Models
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022a. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in lan...
work page internal anchor Pith review arXiv
-
[20]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734,
work page internal anchor Pith review arXiv
-
[21]
For a 3B student, training under both a strong 30B teacher and a 7B RL teacher leads to similar outcomes: the KL divergence decreases steadily and the success rate improves at comparable rates, indicating that increasing teacher strength beyond a certain point does not yield additional benefits. In contrast, when the student capacity matches the teacher m...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.