Recognition: unknown
FedSLoP: Memory-Efficient Federated Learning with Low-Rank Gradient Projection
Pith reviewed 2026-05-08 04:26 UTC · model grok-4.3
The pith
FedSLoP projects client gradients onto random low-rank subspaces to shrink communication and memory use in federated learning while still converging at the standard O(1/√NT) rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
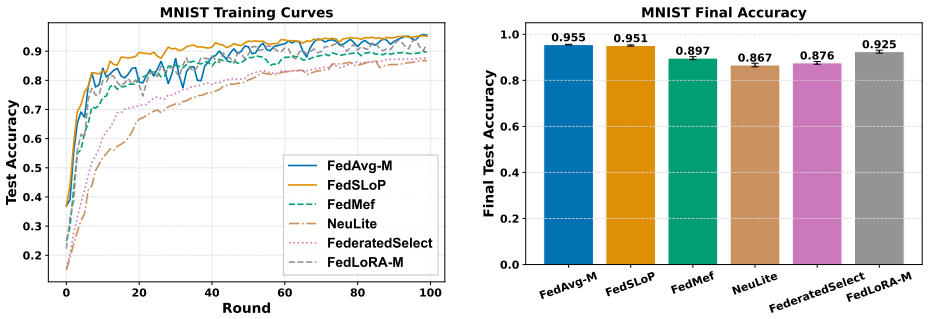
FedSLoP combines stochastic low-rank subspace projections of gradients with federated averaging, reducing the dimension of communicated and stored updates while preserving optimization progress. Under standard smoothness and bounded-variance assumptions, the algorithm converges to a first-order stationary point at rate O(1/√NT). On heterogeneous partitions of MNIST, it cuts communication volume and client memory relative to FedAvg while delivering competitive or superior accuracy.
What carries the argument
Stochastic low-rank subspace projections applied to gradients, which reduce the dimension of each update before communication and storage while attempting to retain enough direction for continued descent.
Load-bearing premise
The random low-rank projections keep enough of the original gradient signal that convergence speed and final accuracy remain intact even when clients hold different data distributions.
What would settle it
An experiment on strongly heterogeneous data in which FedSLoP reaches a stationary point whose loss is materially higher than the point reached by full-gradient FedAvg under identical step sizes and rounds.
Figures


read the original abstract
Federated learning enables a population of clients to collaboratively train machine learning models without exchanging their raw data, but standard algorithms such as FedAvg suffer from slow convergence and high communication and memory costs in heterogeneous, resource-constrained environments. We introduce FedSLoP, a federated optimization algorithm that combines stochastic low-rank subspace projections of gradients, thereby reducing the dimension of communicated and stored updates while preserving optimization progress. On the theoretical side, we develop a detailed nonconvex convergence analysis under standard smoothness and bounded-variance assumptions, showing that FedSLoP is guaranteed to converge to a first-order stationary point at a rate of $O(1/\sqrt{NT})$. On the empirical side, we conduct extensive experiments on federated MNIST classification with heterogeneous data partitions, showing that FedSLoP substantially reduces communication volume and client-side memory while achieving competitive or better accuracy compared with FedAvg and representative sparse or low-rank baselines. Together, our results demonstrate that random subspace momentum methods such as FedSLoP provide a principled and effective approach to communication- and memory-efficient federated learning. Codes are available at: https://github.com/pkumelon/FedSLoP.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FedSLoP, a federated optimization method that applies stochastic low-rank subspace projections to client gradients. This reduces the dimension of communicated updates and client-side memory while aiming to preserve descent progress. The central theoretical claim is a non-convex convergence guarantee to a first-order stationary point at rate O(1/√NT) under standard smoothness and bounded-variance assumptions. Empirically, the method is evaluated on heterogeneous federated MNIST classification, where it reports competitive or superior accuracy relative to FedAvg and other sparse/low-rank baselines while lowering communication volume.
Significance. If the convergence analysis holds and the empirical gains generalize beyond MNIST, FedSLoP would provide a practical, memory- and communication-efficient alternative for federated learning under resource constraints. The combination of random subspace projections with momentum-style updates is a natural extension of recent low-rank optimization ideas to the federated setting; reproducible code is provided, which strengthens verifiability.
major comments (2)
- [§4, Theorem 1] §4 (Convergence Analysis), Theorem 1 and surrounding lemmas: the proof invokes standard smoothness and bounded variance but does not explicitly bound the additional residual term arising from the random low-rank projection of each client's local gradient. Under client heterogeneity the angle between the local gradient and the chosen subspace can vary arbitrarily; without a heterogeneity-dependent bound on this residual (or a demonstration that it averages to zero across clients), the telescoping sum may accumulate an extra positive term that prevents the claimed O(1/√NT) rate from holding.
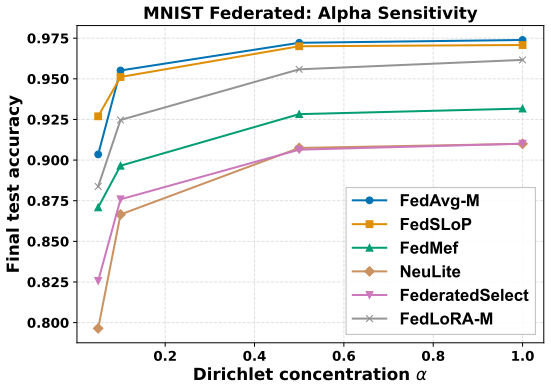
- [§5, Table 1] §5 (Experiments), Table 1 and Figure 2: results are reported on a single dataset (federated MNIST) with one heterogeneity partition. No error bars, multiple random seeds, or additional datasets (e.g., CIFAR-10 or FEMNIST) are shown, so it is impossible to assess whether the observed accuracy gains and communication savings are robust or merely an artifact of the chosen task.
minor comments (2)
- [§3] Notation for the projection matrix P_t and the subspace dimension r is introduced without a clear statement of how r is chosen relative to model dimension d or how it is redrawn each round.
- [Abstract] The abstract states 'extensive experiments' yet the experimental section contains only MNIST; this mismatch should be corrected or the claim softened.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the convergence analysis and experimental evaluation. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4, Theorem 1] §4 (Convergence Analysis), Theorem 1 and surrounding lemmas: the proof invokes standard smoothness and bounded variance but does not explicitly bound the additional residual term arising from the random low-rank projection of each client's local gradient. Under client heterogeneity the angle between the local gradient and the chosen subspace can vary arbitrarily; without a heterogeneity-dependent bound on this residual (or a demonstration that it averages to zero across clients), the telescoping sum may accumulate an extra positive term that prevents the claimed O(1/√NT) rate from holding.
Authors: We thank the referee for identifying this gap. The current proof sketch absorbs the projection error into the bounded-variance term but does not explicitly derive a heterogeneity-aware bound on the residual. In the revised manuscript we will add a new lemma that bounds the expected squared residual of the random low-rank projection. Because the subspace is drawn independently and uniformly at each client, the projection operator is unbiased in expectation (E[P] = (r/d)I for rank-r projection in dimension d), allowing the cross term to vanish when taking expectation over both clients and projections. The remaining variance contribution is controlled by a factor (1 - r/d) times the smoothness constant, which appears as a multiplicative constant in the final bound. Consequently the O(1/√NT) rate is recovered (with a larger but explicit constant). We will update Theorem 1, the surrounding lemmas, and the proof in §4 accordingly. revision: yes
-
Referee: [§5, Table 1] §5 (Experiments), Table 1 and Figure 2: results are reported on a single dataset (federated MNIST) with one heterogeneity partition. No error bars, multiple random seeds, or additional datasets (e.g., CIFAR-10 or FEMNIST) are shown, so it is impossible to assess whether the observed accuracy gains and communication savings are robust or merely an artifact of the chosen task.
Authors: We agree that the current empirical evaluation is limited. In the revised version we will expand §5 to include federated CIFAR-10 and FEMNIST under multiple heterogeneity regimes (Dirichlet partitions with α ∈ {0.1, 0.5, 1.0}). All reported accuracies will be means ± standard deviation over five independent random seeds. Communication-volume and memory metrics will be shown with the same error bars. New tables and figures will be added to present these results, allowing a clearer assessment of robustness. revision: yes
Circularity Check
No circularity: convergence analysis derives from stated assumptions without reduction to inputs
full rationale
The paper presents FedSLoP as an algorithm that applies stochastic low-rank projections to gradients within a federated setting. Its convergence claim is derived from a standard nonconvex analysis under explicitly listed assumptions (smoothness and bounded variance), yielding the O(1/√NT) rate via telescoping sums and standard lemmas; no equation in the provided text defines the rate in terms of the projection operator itself or renames a fitted quantity as a prediction. Experiments are reported as separate empirical validation on heterogeneous MNIST partitions. No self-citation chains, ansatzes imported from prior author work, or self-definitional steps appear in the abstract or described derivation. The analysis is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The objective function is smooth and stochastic gradients have bounded variance
Reference graph
Works this paper leans on
-
[1]
Qsgd: Communication- efficient sgd via gradient quantization and encoding.Advances in neural information processing systems, 30, 2017
Dan Alistarh, Demjan Grubic, Jerry Li, Ryota Tomioka, and Milan Vojnovic. Qsgd: Communication- efficient sgd via gradient quantization and encoding.Advances in neural information processing systems, 30, 2017
2017
-
[2]
Qsparse-local-SGD: Distributed SGD with quantization, sparsification, and local computations.IEEE Journal on Selected Areas in Information Theory, 1(1):217–226, 2020
Debraj Basu, Deepesh Data, Can Karakus, and Suhas N Diggavi. Qsparse-local-SGD: Distributed SGD with quantization, sparsification, and local computations.IEEE Journal on Selected Areas in Information Theory, 1(1):217–226, 2020
2020
-
[3]
On biased compression for distributed learning.Journal of Machine Learning Research, 24(276):1–50, 2023
Aleksandr Beznosikov, Samuel Horváth, Peter Richtárik, and Mher Safaryan. On biased compression for distributed learning.Journal of Machine Learning Research, 24(276):1–50, 2023
2023
-
[4]
Zachary Charles, Kallista Bonawitz, Stanislav Chiknavaryan, Brendan McMahan, et al. Federated select: A primitive for communication-and memory-efficient federated learning.arXiv preprint arXiv:2208.09432, 2022
-
[5]
Ziheng Cheng, Xinmeng Huang, Pengfei Wu, and Kun Yuan. Momentum benefits non-iid federated learning simply and provably.arXiv preprint arXiv:2306.16504, 2023
-
[6]
Locodl: Communication-efficient distributed learning with local training and compression
Laurent Condat, Artavazd Maranjyan, and Peter Richtárik. Locodl: Communication-efficient distributed learning with local training and compression. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025, 2025
2025
-
[7]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek-AI, Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, Hao Yang, Haowei Zhang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Li, Hui Qu, J. L. Cai, Jian L...
work page internal anchor Pith review arXiv 2024
-
[8]
Leveraging federated learning and edge computing for recommendation systems within cloud computing networks
Yuan Feng, Yaqian Qi, Hanzhe Li, Xiangxiang Wang, and Jingxiao Tian. Leveraging federated learning and edge computing for recommendation systems within cloud computing networks. InThird International Symposium on Computer Applications and Information Systems (ISCAIS 2024), volume 13210, pages 279–287. SPIE, 2024
2024
-
[9]
Adjacent leader decentralized stochastic gradient descent
Haoze He, Jing Wang, and Anna Choromanska. Adjacent leader decentralized stochastic gradient descent. InECAI 2024: 27th European Conference on Artificial Intelligence, 19–24 October 2024, Santiago de Compostela, Spain–Including 13th Conference on Prestigious Applications of Intelligent Systems (PAIS 2024), pages 2492–2499. SAGE Publications Pvt. Ltd 1 Oli...
2024
-
[10]
Yutong He, Xinmeng Huang, Yiming Chen, Wotao Yin, and Kun Yuan. Lower bounds and accelerated algorithms in distributed stochastic optimization with communication compression.arXiv preprint arXiv:2305.07612, 2023
-
[11]
Unbiased compression saves communication in distributed optimization: When and how much?Advances in Neural Information Processing Systems, 36:47991– 48020, 2023
Yutong He, Xinmeng Huang, and Kun Yuan. Unbiased compression saves communication in distributed optimization: When and how much?Advances in Neural Information Processing Systems, 36:47991– 48020, 2023
2023
-
[12]
Subspace optimization for large language models with convergence guarantees
Yutong He, Pengrui Li, Yipeng Hu, Chuyan Chen, and Kun Yuan. Subspace optimization for large language models with convergence guarantees. InInternational Conference on Machine Learning, pages 22468–22522. PMLR, 2025
2025
-
[13]
Samuel Horváth, Dmitry Kovalev, Konstantin Mishchenko, Sebastian Stich, and Peter Richtárik. Stochastic distributed learning with gradient quantization and variance reduction.arXiv preprint arXiv:1904.05115, 2019
-
[14]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022
2022
-
[15]
Fedmef: Towards memory-efficient federated dynamic pruning
Hong Huang, Weiming Zhuang, Chen Chen, and Lingjuan Lyu. Fedmef: Towards memory-efficient federated dynamic pruning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27548–27557, 2024
2024
-
[16]
Widening the network mitigates the impact of data heterogeneity on FedAvg
Like Jian and Dong Liu. Widening the network mitigates the impact of data heterogeneity on FedAvg. InForty-second International Conference on Machine Learning, 2025
2025
-
[17]
SCAFFOLD: Stochastic controlled averaging for federated learning
Sai Praneeth Karimireddy, Satyen Kale, Mehryar Mohri, Sashank Reddi, Sebastian Stich, and Ananda Theertha Suresh. SCAFFOLD: Stochastic controlled averaging for federated learning. In International conference on machine learning, pages 5132–5143. PMLR, 2020. 25
2020
-
[18]
Error feedback fixes signsgd and other gradient compression schemes
Sai Praneeth Karimireddy, Quentin Rebjock, Sebastian Stich, and Martin Jaggi. Error feedback fixes signsgd and other gradient compression schemes. InInternational conference on machine learning, pages 3252–3261. PMLR, 2019
2019
-
[19]
On the convergence of FedAvg on non-IID data
Xiang Li, Kaixuan Huang, Wenhao Yang, Shusen Wang, and Zhihua Zhang. On the convergence of FedAvg on non-IID data. In8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020, 2020
2020
-
[20]
Asynchronous decentralized parallel stochastic gradient descent
Xiangru Lian, Wei Zhang, Ce Zhang, and Ji Liu. Asynchronous decentralized parallel stochastic gradient descent. InInternational conference on machine learning, pages 3043–3052. PMLR, 2018
2018
-
[21]
Junkang Liu, Fanhua Shang, Junchao Zhou, Hongying Liu, Yuanyuan Liu, and Jin Liu. Fedmuon: Accelerating federated learning with matrix orthogonalization.arXiv preprint arXiv:2510.27403, 2025
-
[22]
Communication-efficient learning of deep networks from decentralized data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. InArtificial intelligence and statistics, pages 1273–1282. Pmlr, 2017
2017
-
[23]
A geometric convergence theory for the preconditioned steepest descent iteration.SIAM Journal on Numerical Analysis, 50(6):3188–3207, 2012
Klaus Neymeyr. A geometric convergence theory for the preconditioned steepest descent iteration.SIAM Journal on Numerical Analysis, 50(6):3188–3207, 2012
2012
-
[24]
Error compensated distributed sgd can be accelerated
Xun Qian, Peter Richtárik, and Tong Zhang. Error compensated distributed sgd can be accelerated. Advances in Neural Information Processing Systems, 34:30401–30413, 2021
2021
-
[25]
A unified linear speedup analysis of federated averaging and nesterov FedAvg.Journal of artificial intelligence research, 78:1143– 1200, 2023
Zhaonan Qu, Kaixiang Lin, Zhaojian Li, Jiayu Zhou, and Zhengyuan Zhou. A unified linear speedup analysis of federated averaging and nesterov FedAvg.Journal of artificial intelligence research, 78:1143– 1200, 2023
2023
-
[26]
A comparative evaluation of fedavg and per-fedavg algorithms for dirichlet distributed heterogeneous data
Hamza Reguieg, Mohammed El Hanjri, Mohamed El Kamili, and Abdellatif Kobbane. A comparative evaluation of fedavg and per-fedavg algorithms for dirichlet distributed heterogeneous data. In2023 10th International Conference on Wireless Networks and Mobile Communications (WINCOM), pages 1–6. IEEE, 2023
2023
-
[27]
A stochastic approximation method.The Annals of Mathematical Statistics, pages 400–407, 1951
Herbert Robbins and Sutton Monro. A stochastic approximation method.The Annals of Mathematical Statistics, pages 400–407, 1951
1951
-
[28]
Sparsified sgd with memory.Advances in neural information processing systems, 31, 2018
Sebastian U Stich, Jean-Baptiste Cordonnier, and Martin Jaggi. Sparsified sgd with memory.Advances in neural information processing systems, 31, 2018
2018
-
[29]
arXiv preprint arXiv:1909.05350 , author =
Sebastian U. Stich and Sai Praneeth Karimireddy. The error-feedback framework: Better rates for SGD with delayed gradients and compressed communication.arXiv preprint arXiv:1909.05350, 2019
-
[30]
A non-parametric view of FedAvg and FedProx: Beyond stationary points.Journal of Machine Learning Research, 24(203):1–48, 2023
Lili Su, Jiaming Xu, and Pengkun Yang. A non-parametric view of FedAvg and FedProx: Beyond stationary points.Journal of Machine Learning Research, 24(203):1–48, 2023
2023
-
[31]
Yuki Takezawa and Sebastian U. Stich. Scalable decentralized learning with teleportation. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
2025
-
[32]
OpenReview.net, 2025
2025
-
[33]
D2: Decentralizedtrainingoverdecentralized data
HanlinTang, XiangruLian, MingYan, CeZhang, andJiLiu. D2: Decentralizedtrainingoverdecentralized data. InInternational Conference on Machine Learning, pages 4848–4856. PMLR, 2018
2018
-
[34]
DoubleSqueeze: Parallel stochastic gradient descent with double-pass error-compensated compression
Hanlin Tang, Chen Yu, Xiangru Lian, Tong Zhang, and Ji Liu. DoubleSqueeze: Parallel stochastic gradient descent with double-pass error-compensated compression. InInternational Conference on Machine Learning, pages 6155–6165. PMLR, 2019
2019
-
[35]
Reasflow: Assisting reasoning-centric scientific discovery in applied mathematics via a knowledge-based multi-agent system, 2026
ReasFlow Team. Reasflow: Assisting reasoning-centric scientific discovery in applied mathematics via a knowledge-based multi-agent system, 2026. 26
2026
-
[36]
FedDR – randomized douglas-rachford splitting algorithms for nonconvex federated composite optimization
Quoc Tran Dinh, Nhan H Pham, Dzung Phan, and Lam Nguyen. FedDR – randomized douglas-rachford splitting algorithms for nonconvex federated composite optimization. InAdvances in Neural Information Processing Systems, volume 34, pages 30326–30338, 2021
2021
-
[37]
Anastasiia Usmanova, Franccois Portet, Philippe Lalanda, and German Vega. A distillation-based approach integrating continual learning and federated learning for pervasive services.arXiv preprint arXiv:2109.04197, 2021
-
[38]
Powersgd: Practical low-rank gradient compression for distributed optimization.Advances in Neural Information Processing Systems, 32, 2019
Thijs Vogels, Sai Praneeth Karimireddy, and Martin Jaggi. Powersgd: Practical low-rank gradient compression for distributed optimization.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[39]
Yingchao Wang and Wenqi Niu. Federated progressive self-distillation with logits calibration for personalized iiot edge intelligence.arXiv preprint arXiv:2412.00410, 2024
-
[40]
Neulite: Memory-efficient federated learning via elastic progressive training.arXiv e-prints, pages arXiv–2408, 2024
Yebo Wu, Li Li, Chunlin Tian, Dubing Chen, and Chengzhong Xu. Neulite: Memory-efficient federated learning via elastic progressive training.arXiv e-prints, pages arXiv–2408, 2024
2024
-
[41]
Towards bias correction of FedAvg over nonuniform and time-varying communications
Ming Xiang, Stratis Ioannidis, Edmund Yeh, Carlee Joe-Wong, and Lili Su. Towards bias correction of FedAvg over nonuniform and time-varying communications. In2023 62nd IEEE Conference on Decision and Control (CDC), pages 6719–6724. IEEE, 2023
2023
-
[42]
Khan, and Soummya Kar
Ran Xin, Usman A. Khan, and Soummya Kar. An improved convergence analysis for decentralized online stochastic non-convex optimization.IEEE Transactions on Signal Processing, 69:1842–1858, 2021
2021
-
[43]
Achieving linear speedup with partial worker participation in non-IID federated learning
Haibo Yang, Minghong Fang, and Jia Liu. Achieving linear speedup with partial worker participation in non-IID federated learning. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021, 2021
2021
-
[44]
Heterogeneous federated learning.arXiv preprint arXiv:2008.06767, 2020
Fuxun Yu, Weishan Zhang, Zhuwei Qin, Zirui Xu, Di Wang, Chenchen Liu, Zhi Tian, and Xiang Chen. Heterogeneous federated learning.arXiv preprint arXiv:2008.06767, 2020
-
[45]
Federated composite optimization
Honglin Yuan, Manzil Zaheer, and Sashank Reddi. Federated composite optimization. InInternational Conference on Machine Learning, pages 12253–12266. PMLR, 2021
2021
-
[46]
Alghunaim, and Xinmeng Huang
Kun Yuan, Sulaiman A. Alghunaim, and Xinmeng Huang. Removing data heterogeneity influence enhances network topology dependence of decentralized SGD.Journal of Machine Learning Research, 24(280):1–53, 2023
2023
-
[47]
CC-FedAvg: Computationally customized federated averaging.IEEE Internet of Things Journal, 11(3):4826–4841, 2023
Hao Zhang, Tingting Wu, Siyao Cheng, and Jie Liu. CC-FedAvg: Computationally customized federated averaging.IEEE Internet of Things Journal, 11(3):4826–4841, 2023
2023
-
[48]
Non-convex composite federated learning with heterogeneous data.Automatica, 183:112695, 2026
Jiaojiao Zhang, Jiang Hu, and Mikael Johansson. Non-convex composite federated learning with heterogeneous data.Automatica, 183:112695, 2026
2026
-
[49]
Jiaojiao Zhang, Yuqi Xu, and Kun Yuan. An efficient subspace algorithm for federated learning on heterogeneous data.arXiv preprint arXiv:2509.05213, 2025
-
[50]
FedCanon: Non-convex composite federated learning with efficient proximal operation on heterogeneous data.IEEE Transactions on Signal Processing, 74:215–229, 2025
Yuan Zhou, Jiachen Zhong, Xinli Shi, Guanghui Wen, and Xinghuo Yu. FedCanon: Non-convex composite federated learning with efficient proximal operation on heterogeneous data.IEEE Transactions on Signal Processing, 74:215–229, 2025. 27
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.