Recognition: unknown
Disagreement as Signals: Dual-view Calibration for Sequential Recommendation Denoising
Pith reviewed 2026-05-08 02:03 UTC · model grok-4.3
The pith
Disagreement between an LLM semantic prior and a model's learning posterior serves as a signal to iteratively denoise sequential user interaction histories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
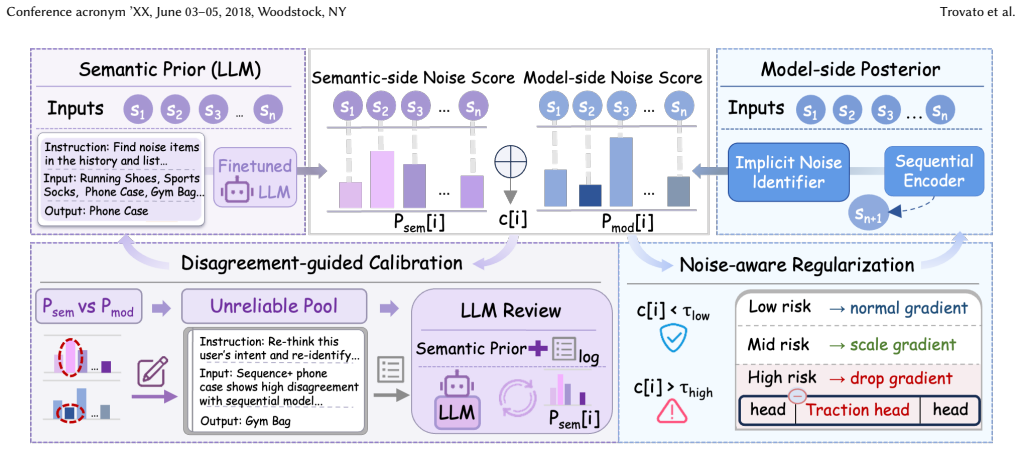
We propose DC4SR, which derives a semantic prior from an LLM fine-tuned on labeled historical interactions to estimate noise from a semantic perspective, pairs it with a model-side posterior inferred from the recommendation model's learning dynamics, and uses the disagreement between these two distributions to jointly refine semantic understanding and learning-aware representations; iterative updates achieve dynamic dual-view calibration that maintains alignment with evolving user interests.
What carries the argument
The dual-view calibration mechanism that treats disagreement between the LLM-derived semantic prior and the model-side posterior as the signal for iterative joint refinement of both noise estimates and representations.
If this is right
- DC4SR outperforms strong Transformer-based recommenders and existing LLM-based denoising methods on standard sequential recommendation benchmarks.
- The method shows enhanced robustness when noise levels change or when the model is observed at different points during training.
- Iterative dual-view updates produce representations that stay aligned with evolving user interests rather than locking onto outdated patterns.
- Dynamic calibration of both global semantic priors and local model posteriors is achieved without requiring additional clean-labeled data beyond the initial LLM fine-tuning.
Where Pith is reading between the lines
- If disagreement signals remain reliable across domains, the same calibration pattern could be tested on other noisy sequential tasks such as session-based search or next-action prediction.
- The approach implies that LLM knowledge can be kept useful in recommendation pipelines even when the underlying model is retrained frequently, by continuously correcting via model-side feedback.
- One open extension is whether the same dual-view logic applies when the semantic prior comes from a smaller language model or from non-textual item metadata instead of an LLM.
Load-bearing premise
The disagreement between the LLM semantic prior and the model posterior reliably flags actual noise without introducing systematic biases from the LLM fine-tuning step or the iterative refinement loop itself.
What would settle it
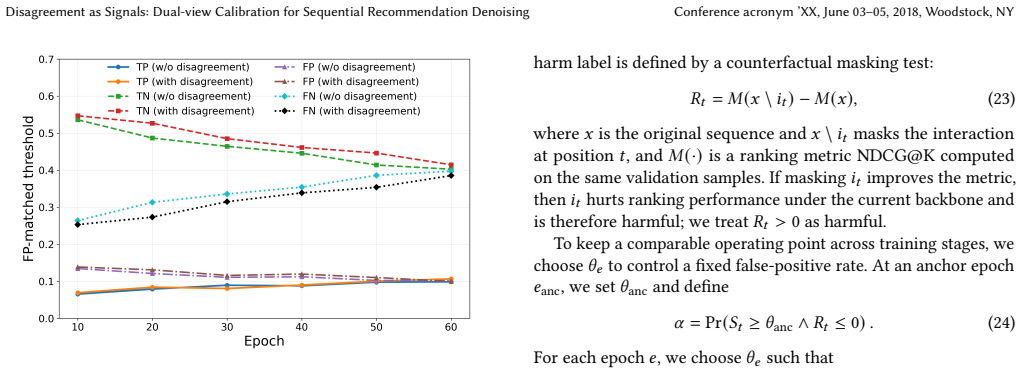
A controlled experiment on a dataset with known injected noise where DC4SR produces no measurable drop in recommendation error relative to a non-calibrated Transformer baseline across multiple training stages would falsify the central claim.
Figures

read the original abstract
Sequential recommendation seeks to model the evolution of user interests by capturing temporal user intent and item-level transition patterns. Transformer-based recommenders demonstrate a strong capacity for learning long-range and interpretable dependencies, yet remain vulnerable to behavioral noise that is misaligned with users' true preferences. Recent large language model (LLM)-based approaches attempt to denoise interaction histories through static semantic editing. Such methods neglect the learning dynamics of recommendation models and fail to account for the evolving nature of user interests. To address this limitation, we propose a Dual-view Calibration framework for Sequential Recommendation denoising (DC4SR). Specifically, we introduce a semantic prior, derived from an LLM fine-tuned via labeled historical interactions, to estimate the noise distribution from a semantic perspective. From the learning perspective, we further employ a model-side posterior that infers the noise distribution based on the model's learning dynamics. The disagreement between the two distributions is then leveraged to jointly refine semantic understanding and learning-aware model-side representations. Through iterative updates, dynamic dual-view calibration is achieved for both the global semantic prior and the model-side posterior, enabling consistent alignment with evolving user interests. Extensive experiments demonstrate that DC4SR consistently outperforms strong Transformer-based recommenders and LLM-based denoising methods, exhibiting enhanced robustness across training stages and noise conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DC4SR, a Dual-view Calibration framework for denoising in sequential recommendation. It constructs a semantic prior via an LLM fine-tuned on labeled historical interactions and a model-side posterior inferred from the recommendation model's learning dynamics. Disagreement between these two distributions is used as a signal to jointly refine both views through iterative updates, with the goal of better aligning to evolving user interests and removing noise. The paper claims that this yields consistent outperformance over strong Transformer-based recommenders and existing LLM-based denoising methods, along with improved robustness across training stages and noise levels.
Significance. If the central assumption holds and the empirical results are reproducible, the work could meaningfully advance noise handling in sequential recommenders by moving beyond static semantic editing to a dynamic calibration that incorporates both global semantics and model-specific learning trajectories. The explicit use of disagreement as a calibration signal is a distinctive idea that could generalize to other noisy sequential modeling settings.
major comments (2)
- [Abstract and §3] Abstract and §3 (framework description): the central claim that disagreement between the LLM-derived semantic prior and the model-side posterior reliably identifies noise for joint refinement is load-bearing, yet both views are derived from the same potentially noisy user-interaction histories. This creates a risk of correlated errors and bias reinforcement during iterative updates rather than recovery of a clean signal, especially for evolving interests; the manuscript does not provide a concrete test or analysis to rule out this circularity.
- [§4] §4 (experiments): the abstract asserts 'consistent outperformance' and 'enhanced robustness' with no accompanying quantitative metrics, ablation results, dataset statistics, or statistical significance tests. Without these details the empirical support for the framework's superiority cannot be assessed, rendering the primary claim unverifiable from the presented material.
minor comments (2)
- The notation distinguishing the semantic prior and model posterior would benefit from explicit mathematical definitions (e.g., probability distributions over items) to clarify how disagreement is quantified.
- Clarify whether the LLM fine-tuning uses the same interaction sequences as the recommendation model or additional external labels, as this directly affects the independence of the two views.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments on our manuscript. We address each major comment point by point below, providing our reasoning and indicating the revisions we will incorporate to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (framework description): the central claim that disagreement between the LLM-derived semantic prior and the model-side posterior reliably identifies noise for joint refinement is load-bearing, yet both views are derived from the same potentially noisy user-interaction histories. This creates a risk of correlated errors and bias reinforcement during iterative updates rather than recovery of a clean signal, especially for evolving interests; the manuscript does not provide a concrete test or analysis to rule out this circularity.
Authors: We appreciate the referee highlighting this critical concern about potential circularity. While both views originate from the same interaction histories, the semantic prior is derived from an LLM that incorporates extensive pre-trained knowledge from large-scale external corpora, enabling it to capture global semantic patterns that are not solely dependent on the local noisy sequences. In contrast, the model-side posterior is shaped by the recommendation model's specific optimization trajectory on the data. The iterative calibration uses their disagreement to surface inconsistencies indicative of noise, with updates alternating between the two views to prevent simple reinforcement. To directly address the absence of explicit validation, we will add a dedicated subsection in §3 providing a theoretical argument for the partial independence of the views (due to the LLM's external knowledge) and include new empirical analyses in §4.5: measuring distribution divergence across iterations on both real and synthetic noise-injected datasets, along with ablation on the calibration's effect when views are artificially correlated. These additions will be incorporated in the revision. revision: yes
-
Referee: [§4] §4 (experiments): the abstract asserts 'consistent outperformance' and 'enhanced robustness' with no accompanying quantitative metrics, ablation results, dataset statistics, or statistical significance tests. Without these details the empirical support for the framework's superiority cannot be assessed, rendering the primary claim unverifiable from the presented material.
Authors: We agree that the abstract's qualitative claims would be strengthened by including key quantitative highlights, and that §4 should make all supporting details immediately accessible. The current manuscript already reports performance metrics, comparisons against Transformer and LLM-based baselines, and robustness experiments across noise levels and training stages in §4. However, to fully resolve the verifiability issue, we will revise the abstract to include specific metrics (e.g., average relative gains in HR@10 and NDCG@10). We will also expand §4 with: (i) a dedicated table of dataset statistics, (ii) comprehensive ablation results for each component of DC4SR, and (iii) statistical significance tests (paired t-tests with p-values) for all main comparisons. These changes will be made in the revised version. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper proposes DC4SR as a dual-view calibration method that derives a semantic prior from an LLM fine-tuned on historical interactions and a model-side posterior from learning dynamics, then uses their disagreement for iterative joint refinement. No equations or steps in the provided description reduce any claimed prediction, calibration outcome, or performance gain to a fitted parameter, self-definition, or self-citation chain by construction. The framework builds on existing LLM fine-tuning and transformer components as independent inputs, with the central claims resting on the proposed disagreement signal and empirical experiments rather than tautological equivalence to the inputs. This is the most common honest finding for method papers that introduce new procedures without internal reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption An LLM fine-tuned on labeled historical interactions yields a reliable semantic prior for noise estimation
- domain assumption The recommendation model's learning dynamics can be used to infer a posterior noise distribution
invented entities (1)
-
disagreement between semantic prior and model posterior as calibration signal
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report.arXiv preprint arXiv:2309.16609(2023)
work page internal anchor Pith review arXiv 2023
-
[2]
Artun Boz, Wouter Zorgdrager, Zoe Kotti, Jesse Harte, Panos Louridas, Vassilios Karakoidas, Dietmar Jannach, and Marios Fragkoulis. 2025. Improving sequential recommendations with llms.ACM Transactions on Recommender Systems4, 2 (2025), 1–35
2025
-
[3]
Huiyuan Chen, Yusan Lin, Menghai Pan, Lan Wang, Chin-Chia Michael Yeh, Xiaoting Li, Yan Zheng, Fei Wang, and Hao Yang. 2022. Denoising self-attentive sequential recommendation. InProceedings of the 16th ACM conference on recom- mender systems. 92–101
2022
-
[4]
Jiawei Chen, Hande Dong, Xiang Wang, Fuli Feng, Meng Wang, and Xiangnan He. 2023. Bias and debias in recommender system: A survey and future directions. ACM Transactions on Information Systems41, 3 (2023), 1–39
2023
-
[5]
Yunjun Gao, Yuntao Du, Yujia Hu, Lu Chen, Xinjun Zhu, Ziquan Fang, and Baihua Zheng. 2022. Self-guided learning to denoise for robust recommendation. InProceedings of the 45th international ACM SIGIR conference on research and development in information retrieval. 1412–1422
2022
-
[6]
Yongqiang Han, Hao Wang, Kefan Wang, Likang Wu, Zhi Li, Wei Guo, Yong Liu, Defu Lian, and Enhong Chen. 2024. Efficient noise-decoupling for multi-behavior sequential recommendation. InProceedings of the ACM Web Conference 2024. 3297–3306
2024
-
[7]
Ruining He and Julian McAuley. 2016. Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering. Inproceedings of the 25th international conference on world wide web. 507–517
2016
-
[8]
Zhuangzhuang He, Yifan Wang, Yonghui Yang, Peijie Sun, Le Wu, Haoyue Bai, Jinqi Gong, Richang Hong, and Min Zhang. 2024. Double correction frame- work for denoising recommendation. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 1062–1072
2024
-
[9]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.ICLR1, 2 (2022), 3
2022
-
[10]
Jun Hu, Wenwen Xia, Xiaolu Zhang, Chilin Fu, Weichang Wu, Zhaoxin Huan, Ang Li, Zuoli Tang, and Jun Zhou. 2024. Enhancing sequential recommendation via llm-based semantic embedding learning. InCompanion Proceedings of the ACM Web Conference 2024. 103–111
2024
-
[11]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation.ACM computing surveys55, 12 (2023), 1–38
2023
-
[12]
Thorsten Joachims, Laura Granka, Bing Pan, Helene Hembrooke, Filip Radlinski, and Geri Gay. 2007. Evaluating the accuracy of implicit feedback from clicks and query reformulations in web search.ACM Transactions on Information Systems (TOIS)25, 2 (2007), 7–es
2007
-
[13]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
2018
-
[14]
Enkelejda Kasneci, Kathrin Seßler, Stefan Küchemann, Maria Bannert, Daryna Dementieva, Frank Fischer, Urs Gasser, Georg Groh, Stephan Günnemann, Eyke Hüllermeier, et al. 2023. ChatGPT for good? On opportunities and challenges of large language models for education.Learning and individual differences103 (2023), 102274
2023
-
[15]
Hyeyoung Ko, Suyeon Lee, Yoonseo Park, and Anna Choi. 2022. A survey of recommendation systems: recommendation models, techniques, and application fields.Electronics11, 1 (2022), 141
2022
-
[16]
Lei Li, Yongfeng Zhang, Dugang Liu, and Li Chen. 2024. Large language models for generative recommendation: A survey and visionary discussions. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 10146–10159
2024
-
[17]
Yujie Lin, Chenyang Wang, Zhumin Chen, Zhaochun Ren, Xin Xin, Qiang Yan, Maarten de Rijke, Xiuzhen Cheng, and Pengjie Ren. 2023. A self-correcting sequential recommender. InProceedings of the ACM Web Conference 2023. 1283– 1293
2023
-
[18]
Qidong Liu, Xiangyu Zhao, Yuhao Wang, Yejing Wang, Zijian Zhang, Yuqi Sun, Xiang Li, Maolin Wang, Pengyue Jia, Chong Chen, et al. 2025. Large Language Model Enhanced Recommender Systems: Methods, Applications and Trends. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 6096–6106
2025
-
[19]
Luis Martínez, Jorge Castro, and Raciel Yera. 2016. Managing natural noise in recommender systems. InInternational conference on theory and practice of natural computing. Springer, 3–17
2016
-
[20]
Michael P O’Mahony, Neil J Hurley, and Guénolé CM Silvestre. 2006. Detecting noise in recommender system databases. InProceedings of the 11th international conference on Intelligent user interfaces. 109–115
2006
-
[21]
J Ben Schafer, Joseph A Konstan, and John Riedl. 2001. E-commerce recommen- dation applications.Data mining and knowledge discovery5, 1 (2001), 115–153
2001
- [22]
-
[23]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[24]
InProceedings of the 28th ACM international conference on information and knowledge management
BERT4Rec: Sequential recommendation with bidirectional encoder rep- resentations from transformer. InProceedings of the 28th ACM international conference on information and knowledge management. 1441–1450
-
[25]
Yatong Sun, Bin Wang, Zhu Sun, and Xiaochun Yang. 2021. Does Every Data In- stance Matter? Enhancing Sequential Recommendation by Eliminating Unreliable Data.. InIJCAI. 1579–1585
2021
-
[26]
Yatong Sun, Xiaochun Yang, Zhu Sun, Yan Wang, Bin Wang, and Xinghua Qu
-
[27]
InProceedings of the AAAI Conference on Artificial Intelligence, Vol
LLM4RSR: Large Language Models as Data Correctors for Robust Sequential Recommendation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 12604–12612
-
[28]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971(2023)
work page internal anchor Pith review arXiv 2023
-
[29]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017). Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Trovato et al
2017
-
[30]
Bohao Wang, Feng Liu, Changwang Zhang, Jiawei Chen, Yudi Wu, Sheng Zhou, Xingyu Lou, Jun Wang, Yan Feng, Chun Chen, et al. 2025. Llm4dsr: Leveraging large language model for denoising sequential recommendation.ACM Transac- tions on Information Systems44, 1 (2025), 1–32
2025
-
[31]
Shoujin Wang, Liang Hu, Yan Wang, Longbing Cao, Quan Z Sheng, and Mehmet Orgun. 2019. Sequential Recommender Systems: Challenges, Progress and Prospects. InProceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence. International Joint Conferences on Artificial Intelligence Organization, 6332–6338
2019
-
[32]
Wenjie Wang, Fuli Feng, Xiangnan He, Liqiang Nie, and Tat-Seng Chua. 2021. Denoising implicit feedback for recommendation. InProceedings of the 14th ACM international conference on web search and data mining. 373–381
2021
-
[33]
Wenjie Wang, Fuli Feng, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua
-
[34]
InProceedings of the 44th international ACM SIGIR conference on research and development in information retrieval
Clicks can be cheating: Counterfactual recommendation for mitigating clickbait issue. InProceedings of the 44th international ACM SIGIR conference on research and development in information retrieval. 1288–1297
-
[35]
Yuxiang Wang, Xin Shi, and Xueqing Zhao. 2025. Mllm4rec: multimodal infor- mation enhancing llm for sequential recommendation.Journal of Intelligent Information Systems63, 3 (2025), 745–761
2025
-
[36]
Yu Wang, Xin Xin, Zaiqiao Meng, Joemon M Jose, Fuli Feng, and Xiangnan He. 2022. Learning robust recommenders through cross-model agreement. In Proceedings of the ACM web conference 2022. 2015–2025
2022
-
[37]
Zongwei Wang, Min Gao, Wentao Li, Junliang Yu, Linxin Guo, and Hongzhi Yin
-
[38]
InProceedings of the 29th ACM SIGKDD conference on knowledge discovery and data mining
Efficient bi-level optimization for recommendation denoising. InProceedings of the 29th ACM SIGKDD conference on knowledge discovery and data mining. 2502–2511
-
[39]
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, et al . 2024. A survey on large language models for recommendation.World Wide Web27, 5 (2024), 60
2024
-
[40]
Tongzhou Wu, Yuhao Wang, Maolin Wang, Chi Zhang, and Xiangyu Zhao. 2025. Empowering Denoising Sequential Recommendation with Large Language Model Embeddings. InProceedings of the 34th ACM International Conference on Informa- tion and Knowledge Management. 3427–3437
2025
-
[41]
Xu Xie, Fei Sun, Zhaoyang Liu, Shiwen Wu, Jinyang Gao, Jiandong Zhang, Bolin Ding, and Bin Cui. 2022. Contrastive learning for sequential recommendation. In 2022 IEEE 38th international conference on data engineering (ICDE). IEEE, 1259– 1273
2022
-
[42]
Chi Zhang, Rui Chen, Xiangyu Zhao, Qilong Han, and Li Li. 2023. Denoising and prompt-tuning for multi-behavior recommendation. InProceedings of the ACM web conference 2023. 1355–1363
2023
-
[43]
Chi Zhang, Yantong Du, Xiangyu Zhao, Qilong Han, Rui Chen, and Li Li. 2022. Hierarchical item inconsistency signal learning for sequence denoising in se- quential recommendation. InProceedings of the 31st ACM international conference on information & knowledge management. 2508–2518
2022
-
[44]
Chi Zhang, Qilong Han, Rui Chen, Xiangyu Zhao, Peng Tang, and Hongtao Song
-
[45]
In2024 IEEE 40th International Conference on Data Engineering (ICDE)
Ssdrec: Self-augmented sequence denoising for sequential recommendation. In2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 803– 815
-
[46]
Kaike Zhang, Qi Cao, Fei Sun, Yunfan Wu, Shuchang Tao, Huawei Shen, and Xueqi Cheng. 2025. Robust recommender system: a survey and future directions. Comput. Surveys58, 1 (2025), 1–38
2025
-
[47]
Yansen Zhang, Xiaokun Zhang, Ziqiang Cui, and Chen Ma. 2025. Shapley value- driven data pruning for recommender systems. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 3879–3888
2025
-
[48]
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A survey of large language models.arXiv preprint arXiv:2303.182231, 2 (2023)
work page internal anchor Pith review arXiv 2023
-
[49]
Kun Zhou, Hui Yu, Wayne Xin Zhao, and Ji-Rong Wen. 2022. Filter-enhanced MLP is all you need for sequential recommendation. InProceedings of the ACM web conference 2022. 2388–2399. A Reproducibility Details of Disagreement-guided Calibration We run calibration every 𝑅 epochs for a total of ⌊𝐸/𝑅⌋ rounds. For each queried sequence 𝑥∈ P , we refresh the sema...
2022
-
[50]
<title/text> | 2. <title/text> | ... | n. <title/text> Hard positions (1-indexed): <pos_1>, <pos_2>, ..., <pos_K> Evidence log (per hard position, last𝐿 traces): pos <pos_j>: (p_sem, p_mod, d) at recent rounds: <(.,.,.), ..., (.,.,.)> (Optional) pool summary: <text> output Suspicious items: { <title/text at pos>, <title/text at pos>, ... } If none: {} B A...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.