Recognition: unknown
Grounding Before Generalizing: How AI Differs from Humans in Causal Transfer
Pith reviewed 2026-05-08 03:35 UTC · model grok-4.3
The pith
Current AI models require environmental grounding before transferring causal structures, unlike humans who apply abstract knowledge immediately.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
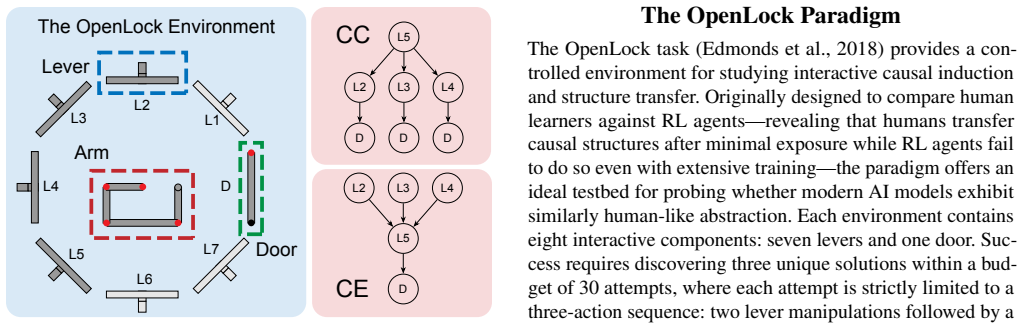
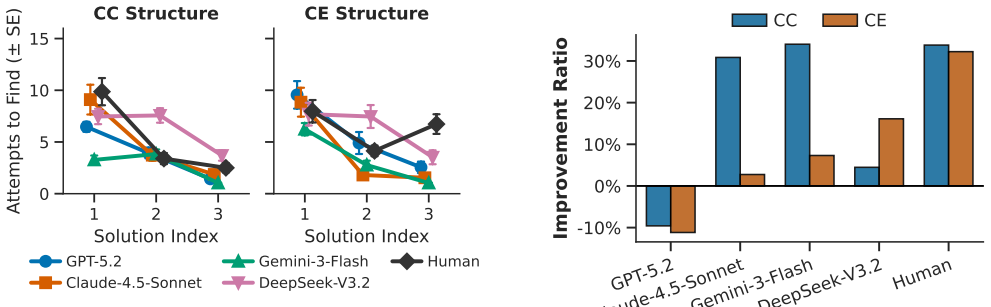
In sequential discovery tasks requiring identification of Common Cause and Common Effect structures, state-of-the-art LLMs and VLMs exhibit delayed or absent transfer across novel contexts. Successful models first require environmental-specific mapping, termed environmental grounding, before efficiency improves, whereas humans demonstrate immediate transfer based on prior structural knowledge. Text-only conditions allow models to match or exceed human discovery rates, but adding visual information degrades overall performance, and models show systematic CC/CE asymmetries absent in humans, pointing to heuristic biases instead of neutral causal abstraction.
What carries the argument
Environmental grounding, the requirement for initial environment-specific mapping before efficiency gains in causal structure transfer emerge, in contrast to decontextualized causal schemas that enable immediate cross-context application.
If this is right
- Models will continue to require extra steps for causal transfer in new contexts, leading to inefficiency in dynamic tasks.
- Adding visual information will often reduce rather than enhance causal discovery and transfer performance.
- Models will exhibit direction-specific biases in causal reasoning that humans avoid.
- Large-scale pretraining without new mechanisms will not produce human-like decontextualized causal schemas.
Where Pith is reading between the lines
- Architectures that explicitly separate causal abstraction from environmental details may reduce the observed grounding requirement.
- This difference could constrain AI use in rapidly changing real-world settings such as adaptive planning or hypothesis testing.
- Targeted training that rewards immediate structural transfer might close the gap, but would require new benchmarks beyond current scaling approaches.
Load-bearing premise
The OpenLock paradigm validly measures abstract causal structure transfer in equivalent ways for both humans and current AI models without introducing biases that favor one over the other.
What would settle it
If AI models achieve immediate transfer efficiency matching human levels on the first solution attempt in novel OpenLock environments without any prior environment-specific mapping, the claim of grounding-dependent transfer as a fundamental limitation would be falsified.
Figures

read the original abstract
Extracting abstract causal structures and applying them to novel situations is a hallmark of human intelligence. While Large Language Models (LLMs) and Vision Language Models (VLMs) have shown strong performance on a wide range of reasoning tasks, their capacity for interactive causal learning -- inducing latent structures through sequential exploration and transferring them across contexts -- remains uncharacterized. Human learners accomplish such transfer after minimal exposure, whereas classical Reinforcement Learning (RL) agents fail catastrophically. Whether state-of-the-art Artificial Intelligence (AI) models possess human-like mechanisms for abstract causal structure transfer is an open question. Using the OpenLock paradigm requiring sequential discovery of Common Cause (CC) and Common Effect (CE) structures, here we show that models exhibit fundamentally delayed or absent transfer: even successful models require initial environmental-specific mapping -- what we term environmental grounding -- before efficiency gains emerge, whereas humans leverage prior structural knowledge from the very first solution attempt. In the text-only condition, models matched or exceeded human discovery efficiency. In contrast, visual information -- in both the image-only and text-and-image conditions -- overall degraded rather than enhanced performance, revealing a broad reliance on symbolic processing rather than integrated multimodal reasoning. Models further exhibited systematic CC/CE asymmetries absent in humans, suggesting heuristic biases rather than direction-neutral causal abstraction. These findings reveal that large-scale statistical learning does not produce the decontextualized causal schemas underpinning human analogical reasoning, establishing grounding-dependent transfer as a fundamental limitation of current LLMs and VLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically compares human and AI (LLM/VLM) performance on the OpenLock paradigm for discovering and transferring common-cause (CC) and common-effect (CE) causal structures. It reports that models require an initial 'environmental grounding' phase of context-specific mapping before transfer efficiency improves, unlike humans who apply decontextualized abstract schemas from the first trial. Text-only model conditions match or exceed human discovery efficiency, while visual inputs (image-only or text+image) degrade performance overall; models also exhibit CC/CE asymmetries absent in humans. The authors conclude that large-scale statistical learning does not produce human-like decontextualized causal schemas, establishing grounding-dependent transfer as a core limitation of current models.
Significance. If the core empirical patterns hold after addressing methodological gaps and input-equivalence concerns, the work would usefully document a concrete difference in causal transfer between humans and current AI systems. The direct use of a human-validated interactive paradigm enables a head-to-head comparison that is rarer than purely benchmark-based evaluations, and the dissociation between text-only success and multimodal degradation offers a testable observation about symbolic versus integrated reasoning in large models. These points could inform targeted improvements in grounding or causal abstraction mechanisms.
major comments (3)
- [Methods] Methods section: The manuscript provides insufficient detail on the specific models tested (including versions and sizes), exact prompting formats and few-shot examples, number of independent runs or trials, participant/model sample sizes, and statistical procedures (error bars, significance tests, multiple-comparison corrections). These omissions are load-bearing because the central claims rest on quantitative performance differences and asymmetries whose reliability cannot be evaluated without them.
- [Results/Discussion] Results/Discussion: The interpretation that models lack decontextualized causal schemas (and therefore require environmental grounding) assumes the OpenLock task measures equivalent processes in embodied humans and non-embodied models. The text-only condition matching human efficiency is consistent with an alternative account in which models must first solve an input-mapping problem that humans bypass via physical interaction; this alternative is not ruled out by the reported data and directly affects the strength of the 'fundamental limitation' conclusion.
- [Discussion] Discussion: The reported CC/CE asymmetries are presented as evidence of heuristic biases rather than direction-neutral abstraction. However, the manuscript does not report effect sizes, consistency across individual models, or controls for training-data linguistic biases in causal language; without these, it is unclear whether the asymmetries are robust or task-specific artifacts.
minor comments (2)
- [Abstract/Introduction] Abstract and introduction: The term 'environmental grounding' is introduced as a post-hoc label; a brief operational definition or reference to prior usage would improve clarity for readers unfamiliar with the paradigm.
- [Figures] Figure legends: Legends should explicitly list the three input conditions (text-only, image-only, text+image) and indicate which panels correspond to discovery versus transfer phases.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important areas for clarification and strengthening. We have revised the manuscript to provide full methodological details and to explicitly discuss alternative interpretations of the results. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: [Methods] Methods section: The manuscript provides insufficient detail on the specific models tested (including versions and sizes), exact prompting formats and few-shot examples, number of independent runs or trials, participant/model sample sizes, and statistical procedures (error bars, significance tests, multiple-comparison corrections). These omissions are load-bearing because the central claims rest on quantitative performance differences and asymmetries whose reliability cannot be evaluated without them.
Authors: We agree that these details are essential for evaluating the claims. In the revised manuscript we have expanded the Methods section to specify: exact model versions and sizes (GPT-4o, Claude-3-Opus, LLaVA-1.6-34B, etc.), complete prompting templates with any few-shot examples, number of independent runs (10 per model-condition pair), human sample size (N=24), and statistical procedures including SEM error bars, two-tailed t-tests, and Bonferroni corrections for multiple comparisons. These additions enable full reproducibility and direct assessment of the reported differences and asymmetries. revision: yes
-
Referee: [Results/Discussion] Results/Discussion: The interpretation that models lack decontextualized causal schemas (and therefore require environmental grounding) assumes the OpenLock task measures equivalent processes in embodied humans and non-embodied models. The text-only condition matching human efficiency is consistent with an alternative account in which models must first solve an input-mapping problem that humans bypass via physical interaction; this alternative is not ruled out by the reported data and directly affects the strength of the 'fundamental limitation' conclusion.
Authors: We acknowledge the force of this alternative account. The revised Discussion now includes an explicit paragraph considering the possibility that text-only performance reflects an input-mapping stage rather than absence of abstract schemas. However, even in the text condition the task requires sequential intervention and outcome observation to induce latent structure, which goes beyond passive mapping. We retain the grounding-dependent transfer claim as a descriptive characterization of the observed behavior while softening the 'fundamental limitation' language to 'a core difference in transfer dynamics' and noting that further experiments would be needed to fully adjudicate the mapping versus schema accounts. revision: partial
-
Referee: [Discussion] Discussion: The reported CC/CE asymmetries are presented as evidence of heuristic biases rather than direction-neutral abstraction. However, the manuscript does not report effect sizes, consistency across individual models, or controls for training-data linguistic biases in causal language; without these, it is unclear whether the asymmetries are robust or task-specific artifacts.
Authors: We have added the requested analyses to the revised Results and Discussion. Effect sizes (Cohen’s d) for the CC/CE asymmetry are now reported for each condition. Per-model breakdowns show the asymmetry is consistent across the tested LLMs and VLMs. We also include a control analysis using neutral causal phrasing that preserves the asymmetry, reducing the likelihood that it is solely an artifact of training-data linguistic biases. These additions support the interpretation of heuristic biases while acknowledging remaining uncertainty about the precise source. revision: yes
Circularity Check
No circularity: purely empirical observations without derivation or fitted predictions
full rationale
The paper conducts an empirical comparison of LLMs, VLMs, and humans on the OpenLock causal transfer task, reporting performance metrics across text, image, and combined conditions. No equations, parameter fitting, or predictive derivations appear; results are presented as direct observations of discovery efficiency, CC/CE asymmetries, and grounding effects. Claims rest on experimental data rather than any self-referential chain or renamed inputs, satisfying the self-contained criterion with no load-bearing reductions to prior definitions or citations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption OpenLock paradigm measures abstract causal structure transfer equivalently for humans and AI
Reference graph
Works this paper leans on
-
[1]
Anadkat, S., et al. (2023). Gpt-4 technical report.arXiv preprint arXiv:2303.08774(cit. on p. 1). Anthropic. (2024). Claude 3 model card.Anthropic Technical Report(cit. on p. 1)
work page internal anchor Pith review arXiv 2023
-
[2]
Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. (2020). Language models are few-shot learners. Proceedings of Advances in Neural Information Processing Systems (NeurIPS)(cit. on p. 1)
2020
-
[3]
-C., & Lu, H
Edmonds, M., Kubricht, J., Summers, C., Zhu, Y ., Rothrock, B., Zhu, S. -C., & Lu, H. (2018). Human casual transfer: Challenges for deep reinforcement learning.Annual Meeting of the Cognitive Science Society (CogSci)(cit. on pp. 1–4)
2018
-
[4]
Edmonds, M., Ma, X., Qi, S., Zhu, Y ., Lu, H., & Zhu, S.-C. (2020). Theory-based causal transfer: Integrating instance- level induction and abstract-level structure learning.Pro- ceedings of AAAI Conference on Artificial Intelligence (AAAI)(cit. on p. 1)
2020
-
[5]
Edmonds, M., Qi, S., Zhu, Y ., Kubricht, J., Zhu, S.-C., & Lu, H. (2019). Decomposing human causal learning: Bottom- up associative learning and top-down schema reasoning. Annual Meeting of the Cognitive Science Society (CogSci) (cit. on p. 1). Gemini Team. (2023). Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805(cit. on p. 1)
work page internal anchor Pith review arXiv 2019
-
[6]
Gentner, D. (1983). Structure-mapping: A theoretical frame- work for analogy.Cognitive Science,7(2), 155–170 (cit. on p. 5)
1983
-
[7]
L., & Holyoak, K
Gick, M. L., & Holyoak, K. J. (1983). Schema induction and analogical transfer.Cognitive Psychology,15(1), 1–38 (cit. on p. 5)
1983
-
[8]
L., & Tenenbaum, J
Griffiths, T. L., & Tenenbaum, J. B. (2005). Structure and strength in causal induction.Cognitive Psychology,51(4), 334–384 (cit. on p. 1)
2005
-
[9]
L., & Tenenbaum, J
Griffiths, T. L., & Tenenbaum, J. B. (2009). Theory-based causal induction.Psychological Review,116(4), 661 (cit. on p. 1)
2009
-
[10]
J., & Cheng, P
Holyoak, K. J., & Cheng, P. W. (2011). Causal learning and inference as a rational process: The new synthesis.Annual Review of Psychology,62(1), 135–163 (cit. on p. 1)
2011
-
[11]
J., Lee, H
Holyoak, K. J., Lee, H. S., & Lu, H. (2010). Analogical and category-based inference: A theoretical integration with bayesian causal models.Journal of Experimental Psychol- ogy: General,139(4), 702 (cit. on p. 1)
2010
-
[12]
J., & Thagard, P
Holyoak, K. J., & Thagard, P. (1996).Mental leaps: Analogy in creative thought. MIT press. (Cit. on pp. 1, 5)
1996
-
[13]
Blin, K., Gonzalez Adauto, F., Kleiman-Weiner, M., Sachan, M., et al. (2023). Cladder: Assessing causal reasoning in language models.Proceedings of Advances in Neural Infor- mation Processing Systems (NeurIPS)(cit. on p. 1)
2023
-
[14]
T., & Schölkopf, B
Diab, M. T., & Schölkopf, B. (2024). Can large language models infer causation from correlation?Proceedings of In- ternational Conference on Learning Representations (ICLR) (cit. on p. 1)
2024
-
[15]
Kiciman, E., Ness, R., Sharma, A., & Tan, C. (2023). Causal reasoning and large language models: Opening a new fron- tier for causality.Transactions on Machine Learning Re- search(cit. on p. 1)
2023
-
[16]
M., Ullman, T
Lake, B. M., Ullman, T. D., Tenenbaum, J. B., & Gershman, S. J. (2017). Building machines that learn and think like people.Behavioral and Brain Sciences,40(cit. on p. 1)
2017
-
[17]
Zhang, B., Lin, C., Dong, C., et al. (2025). Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556(cit. on p. 1)
work page internal anchor Pith review arXiv 2025
-
[18]
L., Liljeholm, M., Cheng, P
Lu, H., Yuille, A. L., Liljeholm, M., Cheng, P. W., & Holyoak, K. J. (2008). Bayesian generic priors for causal learning. Psychological Review,115(4), 955 (cit. on p. 1)
2008
-
[19]
Min, S., Lyu, X., Holtzman, A., Artetxe, M., Lewis, M., Ha- jishirzi, H., & Zettlemoyer, L. (2022). Rethinking the role of demonstrations: What makes in-context learning work? EMNLP(cit. on p. 5)
2022
-
[20]
Nakkiran, P., Neyshabur, B., & Sedghi, H. (2020). The deep bootstrap framework: Good online learners are good offline generalizers.Proceedings of International Conference on Learning Representations (ICLR)(cit. on p. 6)
2020
-
[21]
Ohlsson, S. (1992). Information-processing explanations of insight and related phenomena.Advances in the Psychology of Thinking, 1–44 (cit. on p. 6). OpenAI. (2023). Gpt-4v(ision) system card.OpenAI Technical Report(cit. on p. 1)
1992
-
[22]
Shams, L., & Seitz, A. R. (2008). Benefits of multisensory learning.Trends in Cognitive Sciences,12(11), 411–417 (cit. on p. 6)
2008
-
[23]
Lan, X., Gong, J., Ouyang, T., Meng, F., et al. (2025). Towards large reasoning models: A survey of reinforced reasoning with large language models.arXiv preprint arXiv:2501.09686(cit. on p. 1)
work page internal anchor Pith review arXiv 2025
-
[24]
Zhang, C., Song, J., Li, S., Liang, Y ., Ma, Y ., Wang, W., Zhu, Y ., & Zhu, S.-C. (2026). Proposing and solving olympiad geometry with guided tree search.Nature Machine Intelli- gence,8, 84–95 (cit. on p. 1)
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.