Recognition: unknown
DataClaw: An Autonomous Data Agent with Instant Messaging Integration
Pith reviewed 2026-05-07 17:39 UTC · model grok-4.3
The pith
DataClaw lets users complete data tasks by typing natural language requests in instant messaging chats.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
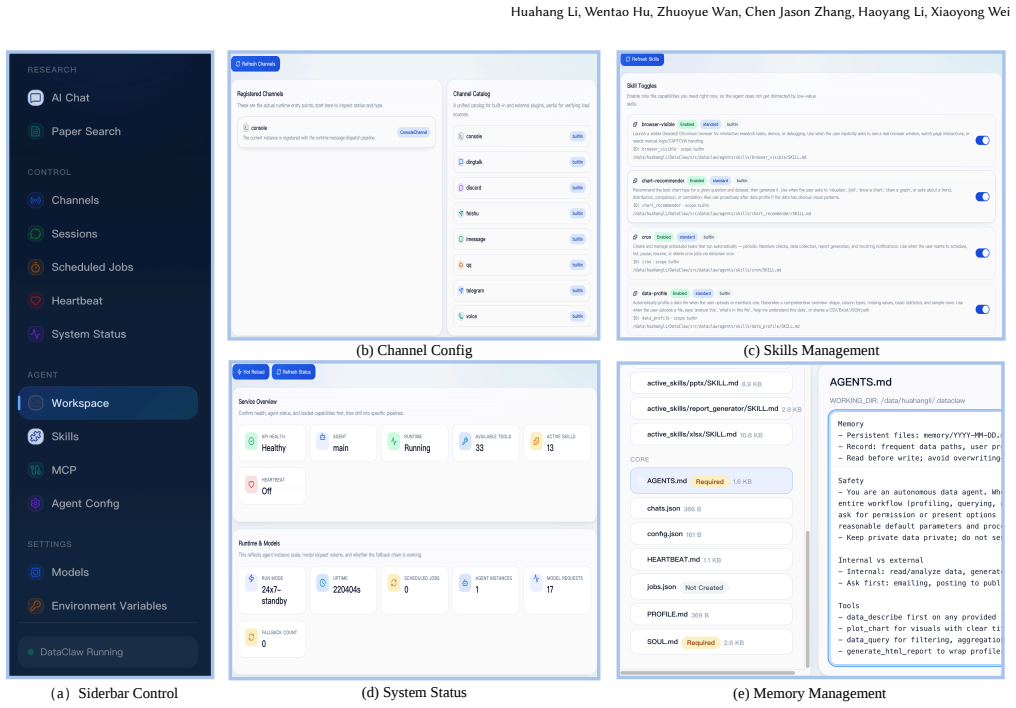
DataClaw is an autonomous data agent integrated into instant messaging platforms that, upon receiving a natural language request, uses a transparent ReAct reasoning engine, multi-tiered memory system, and pluggable skill architecture to plan and execute complete analytical pipelines, returning insights, charts, and reports directly into the chat.
What carries the argument
Transparent ReAct reasoning engine paired with multi-tiered memory for cross-session context and pluggable skills for on-the-fly extension of data operations.
If this is right
- Users finish data processing, querying, and visualization without switching applications.
- Non-technical users can obtain charts and reports through ordinary chat messages.
- New data operations can be added by plugging in additional skills without rebuilding the agent.
- Context from earlier messages stays available so later requests build on prior work.
Where Pith is reading between the lines
- The same chat-based approach could be ported to other collaboration tools to reach more users.
- Adding direct connections to common databases might let the agent handle larger or live datasets.
- Longer conversations could allow the memory system to learn recurring user patterns.
- Real deployments would show whether the current skill set covers the variety of daily data requests.
Load-bearing premise
The ReAct engine together with memory and skills will reliably turn natural language requests into correct, complete data pipelines without frequent errors or manual fixes.
What would settle it
User tests in which the agent repeatedly produces incorrect steps, incomplete pipelines, or results that require user corrections to become accurate.
Figures


read the original abstract
In daily life, there are many scenarios that people need to tackle data-related tasks, such as filling out forms, analyzing Excel files, and visualize data report. However, the tools available for these tasks often fragment, requiring users to switch between multiple applications and manually orchestrate steps like data processing, querying, and visualization. Moreover, these tools often assume a certain level of technical proficiency, creating barriers for non-technical users. To facilitate tacking daily data task, we present DataClaw, an autonomous data agent that integrates directly into familiar instant messaging (IM) platforms. By simply typing a natural language request in a chat interface, users enable DataClaw to autonomously plan and execute a complete analytical pipeline, delivering insights, charts, and reports directly back into the conversation. Under the hood, DataClaw is powered by a transparent ReAct reasoning engine, a multi-tiered memory system for cross session context preservation, and a pluggable skill architecture for on-the-fly extensibility. In this demonstration, attendees will interact with DataClaw via standard IM platforms to solve real-world data scenarios, experiencing how it serves as a highly capable personal data assistant.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents DataClaw, an autonomous data agent integrated with instant messaging platforms. Users can issue natural language requests in chat to trigger autonomous planning and execution of data analysis pipelines, including insights, charts, and reports delivered back in the conversation. The system is built on a ReAct reasoning engine, multi-tiered memory for context preservation, and a pluggable skill architecture for extensibility. The paper is framed as a demonstration allowing interaction via standard IM platforms.
Significance. The described system offers a practical approach to making data tasks accessible to non-technical users through familiar chat interfaces. The architectural choices—transparent ReAct engine, cross-session memory, and extensible skills—provide a clear blueprint for similar agents. However, without any empirical validation, user studies, or performance metrics, the significance remains primarily in the system design and potential for real-world deployment rather than in proven advancements.
minor comments (3)
- [Abstract] The sentence 'To facilitate tacking daily data task' contains a typo ('tacking' should be 'tackling') and grammatical issues; it should be revised for clarity.
- [Abstract] The phrase 'visualize data report' is awkward and should be 'visualizing data reports' or similar to match the parallel structure with 'filling out forms, analyzing Excel files'.
- [Abstract] The abstract mentions 'real-world data scenarios' but provides no specific examples or traces of interactions, which would help illustrate the system's capabilities.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation for minor revision. We address the key observation regarding empirical validation below, noting that the manuscript is explicitly positioned as a demonstration paper.
read point-by-point responses
-
Referee: However, without any empirical validation, user studies, or performance metrics, the significance remains primarily in the system design and potential for real-world deployment rather than in proven advancements.
Authors: We agree that the paper does not include user studies or quantitative performance metrics. This is intentional, as the manuscript is framed as a demonstration (see abstract: 'In this demonstration, attendees will interact with DataClaw via standard IM platforms to solve real-world data scenarios'). Demonstration papers in this venue typically emphasize architectural novelty, integration details, and practical usability over empirical benchmarks. The core contributions—the transparent ReAct engine, multi-tiered memory, and pluggable skill architecture—are presented as a blueprint for similar systems. We can add a brief 'Limitations and Future Work' subsection discussing potential evaluation approaches (e.g., task completion rates or user feedback) if the editor requests it. revision: partial
Circularity Check
No significant circularity: system demonstration paper with no derivations or predictions
full rationale
The paper describes an autonomous data agent architecture (ReAct engine, multi-tiered memory, pluggable skills) integrated with instant messaging for natural-language data tasks. No equations, derivations, fitted parameters, predictions, or first-principles results are present. Claims are purely descriptive of the implemented system and its demo usage; validity rests on architectural exposition and live interaction rather than any self-referential reduction or self-citation chain. No load-bearing steps exist that could reduce to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-based ReAct agents can reliably plan and execute multi-step data tasks without human intervention
invented entities (1)
-
DataClaw autonomous data agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Abhimanyu Dubey, Abhinav Jauhuri, Abhinav Pandey, Abhishek Kabilan, et al
-
[2]
The Llama 3 Herd of Models. (2024)
2024
-
[3]
Yuyu Luo, Xuedi Qin, Nan Tang, Guoliang Li, and Xinran Wang. 2018. DeepEye: Creating Good Data Visualizations by Keyword Search. InProceedings of the 2018 International Conference on Management of Data (SIGMOD). 1733–1736
2018
-
[4]
Avanika Narayan, Ines Chami, Laurel Orr, and Christopher Ré. 2022. Can foun- dation models wrangle your data?Proceedings of the VLDB Endowment16, 4 (2022)
2022
-
[5]
OpenAI. 2023. GPT-4 Technical Report.arXiv:2303.08774(2023)
work page internal anchor Pith review arXiv 2023
-
[6]
2026.OpenClaw: An Open-Source Autonomous AI Agent Framework
Peter Steinberger and OpenClaw Contributors. 2026.OpenClaw: An Open-Source Autonomous AI Agent Framework. https://github.com/openclaw/openclaw
2026
-
[7]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Ji-Rong Wen. 2024. A Survey on Large Language Model based Autonomous Agents.Frontiers of Computer Science(2024)
2024
-
[8]
Siqiao Xue and Danrui et. al. Qi. 2024. Demonstration of DB-GPT: Next Generation Data Interaction System Empowered by Large Language Models.Proc. VLDB Endow.17, 12 (Aug. 2024), 4365–4368
2024
-
[9]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InInternational Conference on Learning Representations (ICLR)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.