Recognition: unknown
Factual and Edit-Sensitive Graph-to-Sequence Generation via Graph-Aware Adaptive Noising
Pith reviewed 2026-05-08 03:46 UTC · model grok-4.3
The pith
A diffusion language model aligns graph components to text tokens and uses adaptive noising based on per-token errors to improve factual grounding and edit sensitivity in graph-to-sequence generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that conditioning a diffusion process on an input graph and applying an adaptive noising strategy, which aligns graph entities and relations with sequence tokens while modulating noise via per-token denoising error, preserves graph structure during iterative refinement. This produces text with stronger factual consistency and greater responsiveness to input edits, allowing localized rather than global updates. The same mechanism extends beyond text graphs to tasks such as molecule captioning.
What carries the argument
Graph-aware adaptive noising, which aligns graph entities and relations to sequence tokens and modulates per-token noise levels according to denoising error signals to preserve structure during iterative text generation.
If this is right
- Outperforms competitive diffusion baselines on the same data splits for graph-to-sequence tasks using both surface-form and embedding-based metrics.
- Surpasses fine-tuned autoregressive baselines of significantly larger scale.
- Matches results from zero-shot large language model baselines that are substantially bigger.
- Extends to molecule captioning, demonstrating generality for scientific graph-to-sequence tasks.
- Enables localized text updates that correspond to specific changes in the input graph.
Where Pith is reading between the lines
- The error-driven noise adjustment could apply to other conditional generation settings that involve structured inputs such as tables or trees.
- It suggests a route to more efficient factual generation that reduces reliance on scaling autoregressive model size.
- Further tests on graphs with high density or nested relations would check whether the token alignment remains effective.
- The alignment and modulation steps might combine with other iterative refinement methods to increase controllability in language models.
Load-bearing premise
Mapping graph elements directly to text tokens and using each token's denoising error to adjust noise will keep the graph facts aligned in the output while permitting localized changes under edits, without creating new factual mismatches or lowering overall text quality.
What would settle it
An evaluation on edited input graphs where the generated text either fails to match the graph facts more closely than baselines or shows global rather than localized revisions would indicate that the adaptive noising does not achieve the claimed structure preservation and edit sensitivity.
Figures






read the original abstract
Fine-tuned autoregressive models for graph-to-sequence generation (G2S) often struggle with factual grounding and edit sensitivity. To tackle these issues, we propose a non-autoregressive diffusion framework that generates text by iterative refinement conditioned on an input graph, named as Diffusion Language Model for Graphs (DLM4G). By aligning graph components (entities/relations) with their corresponding sequence tokens, DLM4G employs an adaptive noising strategy. The proposed strategy uses per-token denoising error as a signal to adaptively modulate noise on entity and relation tokens, improving preservation of graph structure and enabling localized updates under graph edits. Evaluated on three datasets, DLM4G consistently outperforms competitive G2S diffusion baselines trained on identical splits across both surface-form and embedding-based metrics. DLM4G further exceeds fine-tuned autoregressive baselines up to 12x larger (e.g., T5-Large) and is competitive with zero-shot LLM transfer baselines up to 127x larger. Relative to the strongest fine-tuned PLM baseline, DLM4G improves factual grounding (FGT@0.5) by +5.16% and edit sensitivity (ESR) by +7.9%; compared to the best diffusion baseline, it yields gains of +3.75% in FGT@0.5 and +23.6% in ESR. We additionally demonstrate applicability beyond textual graphs through experiments on molecule captioning, indicating the method's generality for scientific G2S generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DLM4G, a non-autoregressive diffusion framework for graph-to-sequence generation. It aligns graph entities and relations with sequence tokens and introduces graph-aware adaptive noising that modulates per-token noise levels according to denoising error signals. The central empirical claim is consistent outperformance over fine-tuned PLM and diffusion baselines on three datasets (with reported gains of +5.16% FGT@0.5 and +7.9% ESR vs. the strongest PLM baseline, and +3.75% FGT@0.5 and +23.6% ESR vs. the best diffusion baseline), plus competitiveness with much larger autoregressive models and extension to molecule captioning.
Significance. If the adaptive noising mechanism is shown to be free of training-inference mismatch and the reported gains are statistically robust, the work would advance non-autoregressive structured generation by directly targeting factual grounding and edit sensitivity—two persistent weaknesses of autoregressive G2S models. The diffusion approach with graph-component alignment offers a principled alternative to standard denoising, and the molecule-captioning results indicate generality beyond textual graphs. Explicit credit is due for the controlled comparison against identically trained diffusion baselines and for releasing the method's applicability to scientific domains.
major comments (2)
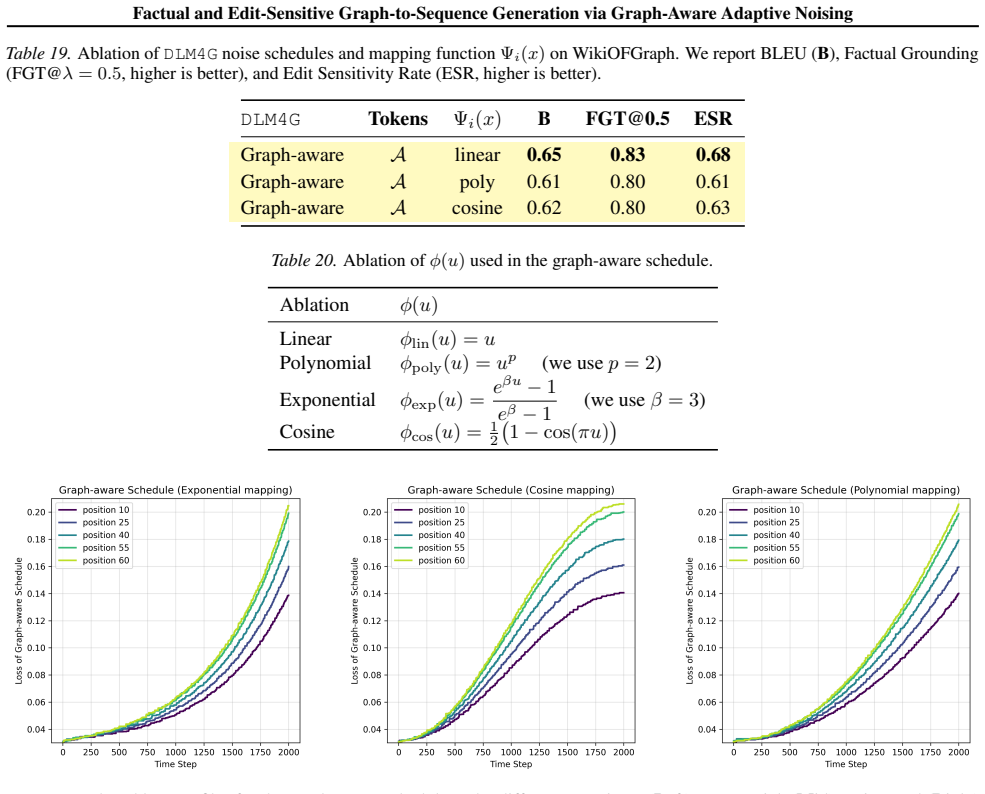
- [§3.2] §3.2 (Graph-Aware Adaptive Noising): The description of how per-token denoising error is used to modulate the noise schedule does not specify the computation order. If the error is obtained from the denoiser after noise addition, an extra forward pass or oracle approximation is required; neither is stated, leaving open a circular dependency or distribution shift that would undermine the claimed preservation of graph structure and localized edit updates. This mechanism is load-bearing for the FGT@0.5 and ESR gains.
- [§4] §4 (Experiments): No statistical significance tests, variance across random seeds, or ablation isolating the adaptive noising component (vs. base diffusion architecture or conditioning) are reported. Without these, the specific percentage improvements cannot be confidently attributed to the proposed strategy rather than unablated factors.
minor comments (3)
- [§2] Define FGT@0.5 and ESR explicitly in the main text (including how they are computed from generated text and reference graphs) rather than deferring to the appendix.
- [Table 1] Table 1 and §4.1: Include parameter counts for all baselines to support the '12x larger' and '127x larger' claims; current presentation leaves the size comparison imprecise.
- [Figure 2] Figure 2 (qualitative examples): Add error annotations or side-by-side edit traces to make the claimed localized update behavior visually verifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the significance of our work. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and analyses.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Graph-Aware Adaptive Noising): The description of how per-token denoising error is used to modulate the noise schedule does not specify the computation order. If the error is obtained from the denoiser after noise addition, an extra forward pass or oracle approximation is required; neither is stated, leaving open a circular dependency or distribution shift that would undermine the claimed preservation of graph structure and localized edit updates. This mechanism is load-bearing for the FGT@0.5 and ESR gains.
Authors: We agree that §3.2 would benefit from greater precision on computation order. In the DLM4G implementation the per-token denoising error is obtained from a single forward pass of the denoiser on the current noisy sequence before the adaptive modulation is applied; the resulting error signal then determines the per-token noise level for the subsequent diffusion step. This ordering eliminates circularity and avoids an oracle or extra pass. We will revise the section to state the procedure explicitly, add pseudocode, and clarify that the error signal is computed consistently with the training distribution to prevent the distribution shift concern. revision: yes
-
Referee: [§4] §4 (Experiments): No statistical significance tests, variance across random seeds, or ablation isolating the adaptive noising component (vs. base diffusion architecture or conditioning) are reported. Without these, the specific percentage improvements cannot be confidently attributed to the proposed strategy rather than unablated factors.
Authors: We acknowledge that the current experimental section lacks statistical significance testing, seed-wise variance, and an explicit ablation of the adaptive noising component. In the revision we will report means and standard deviations over three independent random seeds for all main results, include paired t-tests (or Wilcoxon tests where appropriate) for the reported FGT@0.5 and ESR gains, and add an ablation that compares the full DLM4G model against an otherwise identical diffusion baseline with fixed (non-adaptive) noise scheduling. These additions will allow readers to attribute improvements more confidently to the graph-aware adaptive mechanism. revision: yes
Circularity Check
No significant circularity; claims rest on external empirical comparisons
full rationale
The paper proposes DLM4G as a diffusion framework for graph-to-sequence generation using graph-aware adaptive noising based on per-token denoising error. Its central claims consist of reported performance gains (e.g., +5.16% FGT@0.5 and +7.9% ESR vs. strongest PLM baseline) obtained via direct comparisons to external baselines on three datasets plus molecule captioning. No equations, derivations, or quantities are presented that reduce by construction to fitted inputs or self-citations; the method description does not contain self-definitional steps, fitted-input predictions, or load-bearing uniqueness theorems. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- noise modulation parameters
axioms (1)
- domain assumption Diffusion models can be conditioned on graph structures to generate coherent sequences via iterative refinement
invented entities (1)
-
Graph-Aware Adaptive Noising
no independent evidence
Reference graph
Works this paper leans on
-
[1]
BERT: Pre- training of Deep Bidirectional Transformers for Language Understanding
URL https://aclanthology.org/2021. naacl-main.278/. Banerjee, S. and Lavie, A. Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. InProceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, pp. 65–72, Ann Arbor, MI, 2005. Association for Computati...
-
[2]
doi: 10.18653/v1/2021.emnlp-main.83
Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.83. URL https:// aclanthology.org/2021.emnlp-main.83/. Edwards, C., Lai, T., Ros, K., Honke, G., Cho, K., and Ji, H. Translation between molecules and natural lan- guage. In Goldberg, Y ., Kozareva, Z., and Zhang, Y . (eds.),Proceedings of the 2022 Conference on Em- pirical Method...
-
[3]
Association for Computational Linguistics. doi: 10.18653/v1/2022.emnlp-main.26. URL https:// aclanthology.org/2022.emnlp-main.26/. Fatemi, B., Halcrow, J., and Perozzi, B. Talk like a graph: Encoding graphs for large language models. InThe Twelfth International Conference on Learning Represen- tations, 2024. URL https://openreview.net/ forum?id=IuXR1CCrSi...
-
[4]
Gong, S., Li, M., Feng, J., Wu, Z., and Kong, L
URL https://openreview.net/forum? id=w1FUXt3ujK. Gong, S., Li, M., Feng, J., Wu, Z., and Kong, L. Dif- fuseq: Sequence to sequence text generation with dif- fusion models. InThe Eleventh International Confer- ence on Learning Representations, 2023. URL https: //openreview.net/forum?id=jQj-_rLVXsj. Gong, S., Agarwal, S., Zhang, Y ., Ye, J., Zheng, L., Li, ...
2023
-
[5]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., and et
URL https://openreview.net/forum? id=j1tSLYKwg8. Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., and et. al. The llama 3 herd of models, 2024. URL https://arxiv.org/abs/ 2407.21783. Guo, Q., Jin, Z., Qiu, X., Zhang, W., Wipf, D., and Zhang, Z. CycleGT: Unsupervised graph-to-text and text-to- graph generation via c...
-
[6]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
URL https://aclanthology.org/2022. emnlp-main.321/. Ho, J., Jain, A., and Abbeel, P. Denoising diffusion proba- bilistic models. InProceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Red Hook, NY , USA, 2020. Curran Associates Inc. ISBN 9781713829546. Hu, V ., Wu, D., Asano, Y ., Mettes, P., Fernando, B., O...
-
[7]
URL https://openreview.net/forum? id=xAqcJ9XoTf. Iso, H., Uehara, Y ., Ishigaki, T., Noji, H., Aramaki, E., Kobayashi, I., Miyao, Y ., Okazaki, N., and Takamura, H. Learning to select, track, and generate for data-to- text. In Korhonen, A., Traum, D., and Màrquez, L. (eds.), 10 Factual and Edit-Sensitive Graph-to-Sequence Generation via Graph-Aware Adapti...
-
[8]
URL https://aclanthology.org/2020. coling-main.217/. Kasner, Z. and Dusek, O. Neural pipeline for zero-shot data-to-text generation. In Muresan, S., Nakov, P., and Villavicencio, A. (eds.),Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3914–3932, Dublin, Ireland, May 2022. Association f...
-
[10]
URL https://aclanthology.org/2021. naacl-main.405/. Liu, P., Ren, Y ., Tao, J., and Ren, Z. Git-mol: A multi- modal large language model for molecular science with graph, image, and text.Computers in Biology and Medicine, 171:108073, 2024. ISSN 0010-4825. doi: https://doi.org/10.1016/j.compbiomed.2024.108073. URL https://www.sciencedirect.com/ science/art...
-
[11]
URL https://aclanthology.org/2020. acl-main.167/. Mousavi, A., Zhan, X., Bai, H., Shi, P., Rekatsinas, T., Han, B., Li, Y ., Pound, J., Susskind, J. M., Schluter, N., Ilyas, I. F., and Jaitly, N. Construction of paired knowledge graph - text datasets informed by cyclic evaluation. In Calzolari, N., Kan, M.-Y ., Hoste, V ., Lenci, A., Sakti, S., and Xue, N...
-
[12]
Authorship Attribution for Neural Text Generation.Proceedings of EMNLP 2020, pp
URL https://aclanthology.org/2021. nlp4convai-1.20/. Schmitt, M., Sharifzadeh, S., Tresp, V ., and Schütze, H. An unsupervised joint system for text generation from knowledge graphs and semantic parsing. In Web- ber, B., Cohn, T., He, Y ., and Liu, Y . (eds.),Proceed- ings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP),...
-
[13]
URL https://aclanthology.org/2020. emnlp-main.577/. Schmitt, M., Ribeiro, L. F. R., Dufter, P., Gurevych, I., and Schütze, H. Modeling graph structure via relative po- sition for text generation from knowledge graphs. In Panchenko, A., Malliaros, F. D., Logacheva, V ., Jana, A., Ustalov, D., and Jansen, P. (eds.),Proceedings of the Fifteenth Workshop on G...
-
[14]
URL https://aclanthology.org/2021. textgraphs-1.2/. Skianis, K., Nikolentzos, G., and Vazirgiannis, M. Graph reasoning with large language models via pseudo-code prompting, 2024. URL https://arxiv.org/abs/ 2409.17906. Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., and Ganguli, S. Deep unsupervised learning using nonequi- librium thermodynamics. In Ba...
-
[15]
URL https://proceedings.neurips. cc/paper_files/paper/2017/file/ 3f5ee243547dee91fbd053c1c4a845aa-Paper. pdf. Vejvar, M. and Fujimoto, Y . ASPIRO: Any-shot struc- tured parsing-error-induced ReprOmpting for consistent data-to-text generation. In Bouamor, H., Pino, J., and Bali, K. (eds.),Findings of the Association for Computa- tional Linguistics: EMNLP 2...
-
[16]
URL https://aclanthology.org/2023. findings-emnlp.229/. Venkatraman, S., Jain, M., Scimeca, L., Kim, M., Sendera, M., Hasan, M., Rowe, L., Mittal, S., Lemos, P., Bengio, E., Adam, A., Rector-Brooks, J., Bengio, Y ., Berseth, G., and Malkin, N. Amortizing intractable inference in diffusion models for vision, language, and control, 2025. URLhttps://arxiv.or...
-
[17]
International Joint Conferences on Artificial Intel- ligence Organization, 8 2021. doi: 10.24963/ijcai.2021/
-
[18]
URL https://doi.org/10.24963/ijcai. 2021/630. Survey Track. Wang, S., Zhang, C., and Zhang, N. Mgsa: Multi-granularity graph structure attention for knowledge graph-to-text gen- eration, 2024a. URL https://arxiv.org/abs/ 2409.10294. Wang, X., Zheng, Z., Ye, F., Xue, D., Huang, S., and Gu, Q. Diffusion language models are versatile protein learners. InProc...
-
[19]
URL https://aclanthology.org/2024. emnlp-main.823/. Wei, J., Tay, Y ., Bommasani, R., Raffel, C., Zoph, B., Borgeaud, S., Yogatama, D., Bosma, M., Zhou, D., Met- zler, D., Chi, E. H., Hashimoto, T., Vinyals, O., Liang, P., Dean, J., and Fedus, W. Emergent abilities of large language models.Transactions on Machine Learning Research, 2022. ISSN 2835-8856. U...
-
[20]
URL https://openreview.net/forum? id=SkeHuCVFDr. Zhao, T., Zhao, R., and Eskenazi, M. Learning discourse- level diversity for neural dialog models using condi- tional variational autoencoders. In Barzilay, R. and Kan, M.-Y . (eds.),Proceedings of the 55th Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 654–66...
-
[21]
Consistency Term (LCons): The first term is the negative log-likelihood of the continuous latent, which is minimized via the MSE loss on the means:−logp cont(z0 |S,z 1,c)→ L Consistency = gΦ(S)− M θ(z1,1,c) 2
-
[22]
Rounding Term (LRound): This second term is the dedicated loss for the discrete data likelihood: LRound =−log ˜pΦ(S| z0) A.1.3. FINALEND-TO-ENDOBJECTIVE Combining all components: Lvlb ∝ TX t=2 z0 − Mθ(zt, t,c) 2 | {z } Denoising + gΦ(S)− M θ(z1,1,c) 2 | {z } Consistency −log ˜pΦ(S|z 0)| {z } Rounding .(22) Dropping constant terms, the simplified end-to-en...
2023
-
[23]
Alan Turing was born in London
enabled true sequence-to-sequence conditioning in continuous space. Related frameworks also target time-series (CSDI (Tashiro et al., 2021)) and speech (WaveGrad (Chen et al., 2021b)). Distinct from prior G2S and diffusion-LM work, DLM4G integrates classifier-free diffusion with explicit KG conditioning, treating the graph itself as the control variable. ...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.