Recognition: unknown
Exact Mining of Dense Patterns via Direct Evaluation of Local Interval Frequency Using a Sliding Window
Pith reviewed 2026-05-07 17:23 UTC · model grok-4.3
The pith
The Apriori-window algorithm mines dense patterns exactly by evaluating local frequency directly inside each position of a sliding window, removing any need for gap constraint parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Apriori-window directly computes the local frequency of candidate itemsets at every offset of a sliding window over a transaction sequence. Anti-monotonicity supplies safe pruning of the candidate lattice, and stride-skip reduces the number of full window scans while preserving completeness. Because frequency is measured inside the window itself rather than through global gaps, the algorithm returns both the dense itemsets and their exact dense intervals without introducing a tunable gap parameter or trading off identification accuracy against interval accuracy.
What carries the argument
Apriori-window algorithm, which performs direct local-frequency evaluation inside sliding windows together with anti-monotonicity pruning of the search space and stride-skip reduction of window evaluations.
If this is right
- Dense patterns and their supporting intervals can be recovered simultaneously with high accuracy on both tasks without any gap-parameter search.
- Anti-monotonicity guarantees that no locally dense itemset is missed while the search space is reduced.
- Stride-skip yields fewer window scans yet still enumerates every qualifying interval.
- The method scales to larger synthetic data while existing gap-based approaches cannot jointly optimize pattern and interval quality.
Where Pith is reading between the lines
- The same sliding-window frequency check could be extended to online streaming settings where new transactions arrive continuously.
- Precise dense intervals might improve downstream tasks such as localized association-rule mining or anomaly flagging within time series.
- Because no gap parameter is required, the approach removes a common source of overfitting when the same method is applied across multiple datasets.
Load-bearing premise
Evaluating frequency inside each sliding window and pruning with anti-monotonicity recovers exactly the same dense patterns and intervals that exhaustive search over every possible interval would produce, without omissions or boundary artifacts.
What would settle it
On a small synthetic sequence whose dense intervals are known in advance, run both Apriori-window and a brute-force enumeration of every possible interval and itemset; any mismatch in the reported dense patterns or their intervals would falsify the claim of exactness.
Figures

read the original abstract
Accurately extracting patterns that appear frequently only within specific time intervals, together with their dense intervals, is important in many applications such as understanding seasonal demand and detecting anomalous behavior.Frequent itemset mining evaluates support over the entire dataset and therefore cannot detect locally dense patterns. Existing methods for dense pattern mining with interval output estimate dense intervals through occurrence-gap constraints; however, since the gap constraint parameter governs both pattern identification accuracy and interval detection accuracy simultaneously, finding a parameter setting that achieves high accuracy for both objectives is difficult.In this paper, we propose Apriori-window, an exact algorithm that resolves this structural limitation. The proposed method directly evaluates local frequency within a sliding window and thus requires no gap constraint parameter, and it efficiently enumerates dense intervals through anti-monotonicity-based pruning of the search space and stride-skip reduction of the number of window scans. Experiments on three real-world datasets demonstrate that existing methods struggle to simultaneously achieve high accuracy in both pattern identification and dense interval detection, and scalability experiments on synthetic data confirm the practical applicability of the proposed method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Apriori-window, an exact algorithm for mining dense patterns together with their dense intervals in timestamped transactional data. It directly computes local frequency support inside a sliding window (eliminating any gap-constraint parameter), applies anti-monotonicity pruning to the itemset lattice, and uses stride-skip to reduce the number of distinct window positions that must be scanned. The authors assert that these optimizations preserve exact equivalence to exhaustive enumeration of all possible intervals, and they report that the method simultaneously achieves higher pattern-identification and interval-detection accuracy than gap-based baselines on three real-world datasets while scaling on synthetic data.
Significance. If the exactness claim is rigorously established, the work removes a long-standing structural trade-off in dense-interval mining: the same parameter no longer has to govern both pattern discovery accuracy and interval boundary accuracy. A parameter-free, exact method would be directly useful for applications that require reliable localization of seasonal or anomalous behavior. The experimental contrast with existing methods also supplies concrete evidence that the prior gap-constraint approach is practically limited.
major comments (2)
- [§3] §3 (algorithm description, stride-skip subsection): the manuscript asserts that stride-skip together with anti-monotonicity pruning yields exactly the same set of maximal dense intervals as exhaustive enumeration over every possible interval. No lemma, invariant, or proof sketch is supplied showing that a locally dense interval whose endpoints fall between stride positions is never omitted or reported with incorrect boundaries. Because the title and abstract rest on the claim of exactness, this omission is load-bearing.
- [§3.1] §3.1 (sliding-window frequency evaluation): boundary effects are not addressed. It is not shown that every interval that is dense only when considered in isolation (i.e., not fully contained inside any single evaluated window) is still discovered, nor how partial overlaps at window edges are handled without introducing false positives or negatives. The central exactness guarantee therefore remains unverified.
minor comments (1)
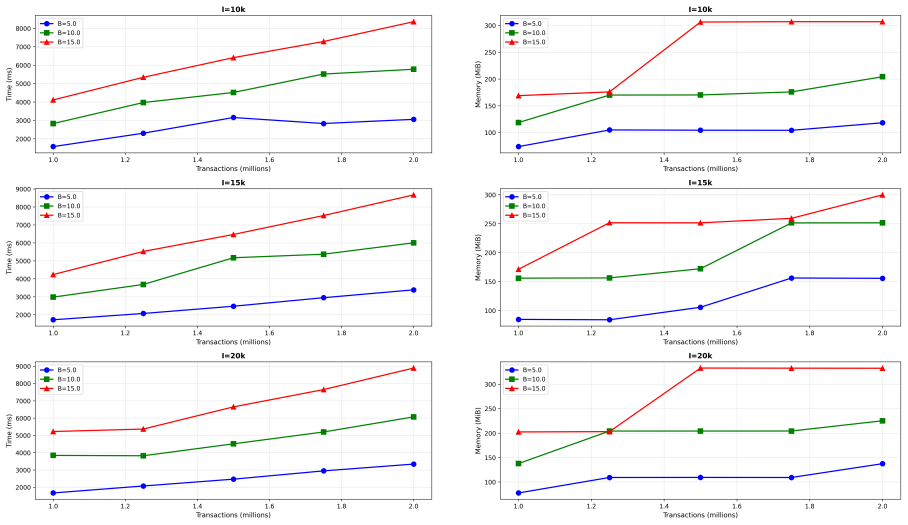
- [§5] The experimental section should report the concrete window-size values chosen for each dataset and any sensitivity analysis performed; without this information the reproducibility of the accuracy claims is limited.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The two major comments correctly identify that the exactness claims central to the title, abstract, and contribution require stronger formal support than the current descriptive arguments provide. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3] §3 (algorithm description, stride-skip subsection): the manuscript asserts that stride-skip together with anti-monotonicity pruning yields exactly the same set of maximal dense intervals as exhaustive enumeration over every possible interval. No lemma, invariant, or proof sketch is supplied showing that a locally dense interval whose endpoints fall between stride positions is never omitted or reported with incorrect boundaries. Because the title and abstract rest on the claim of exactness, this omission is load-bearing.
Authors: We agree that an explicit lemma is necessary. The stride-skip rule is derived from the anti-monotonicity of local support: once a window position yields no dense extensions for an itemset, subsequent positions within the stride can be safely skipped without missing any maximal dense interval whose support remains above threshold. In the revision we will insert a formal lemma in §3 stating that for any dense interval [l,r] there exists at least one evaluated stride window that fully contains [l,r] or whose adjacent checked positions correctly delimit the boundaries, preserving exact equivalence to exhaustive enumeration. The proof will rely on the monotonicity of the support function over sliding windows. revision: yes
-
Referee: [§3.1] §3.1 (sliding-window frequency evaluation): boundary effects are not addressed. It is not shown that every interval that is dense only when considered in isolation (i.e., not fully contained inside any single evaluated window) is still discovered, nor how partial overlaps at window edges are handled without introducing false positives or negatives. The central exactness guarantee therefore remains unverified.
Authors: We acknowledge the gap in the presentation. The algorithm evaluates support inside each window and reports an interval as dense only when the itemset meets the threshold throughout a contiguous sequence of windows; maximal intervals are then extracted by merging adjacent dense segments. Partial overlaps are resolved by extending only when support remains dense across the overlap, which the anti-monotonicity pruning prevents from creating false positives. Nevertheless, the manuscript does not explicitly prove that no dense interval is lost at window boundaries. In the revision we will add a short subsection in §3.1 with a boundary-handling invariant and a small worked example demonstrating that isolated dense intervals are captured by the nearest evaluated windows without false discoveries or omissions. revision: yes
Circularity Check
No significant circularity; direct algorithmic replacement for gap-constrained mining
full rationale
The paper presents Apriori-window as an exact algorithm that replaces gap-constraint parameters with direct sliding-window frequency evaluation, using standard anti-monotonicity for pruning and stride-skip for efficiency. No fitted parameters, self-definitional loops, or load-bearing self-citations appear in the derivation chain. The exactness claim rests on the direct evaluation being equivalent to exhaustive interval checking by construction of the sliding-window approach, with optimizations asserted to preserve this without reducing to inputs. Anti-monotonicity is an independent property of frequency measures, not smuggled via citation or ansatz. This is a self-contained algorithmic proposal against the exhaustive-search benchmark, with no evidence of any enumerated circular pattern.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Anti-monotonicity of support: if a pattern is not locally frequent in a window, none of its supersets can be.
Reference graph
Works this paper leans on
-
[1]
Fast algorithms for mining association rules,
R. Agrawal and R. Srikant, “Fast algorithms for mining association rules,” inProc. VLDB, 1994, pp. 487–499
1994
-
[2]
New algorithms for fast discovery of association rules,
M. J. Zaki, S. Parthasarathy, M. Ogihara, and W. Li, “New algorithms for fast discovery of association rules,” inProc. KDD, 1997, pp. 283–296
1997
-
[3]
Mining frequent patterns without candidate generation,
J. Han, J. Pei, and Y. Yin, “Mining frequent patterns without candidate generation,” ACM SIGMOD Record, vol. 29, no. 2, pp. 1–12, 2000. 18
2000
-
[4]
A survey of itemset mining,
P. Fournier-Viger, J. C.-W. Lin, B. Vo, T. T. Chi, J. Zhang, and H. B. Le, “A survey of itemset mining,”WIREs Data Mining Knowl. Discov., vol. 7, no. 4, e1207, 2017
2017
-
[5]
Pattern mining: Current challenges and opportunities,
P. Fournier-Viger, W. Gan, Y. Wu, M. Nouioua, W. Song, T. Truong, and H. Duong, “Pattern mining: Current challenges and opportunities,” inProc. DASFAA Work- shops, LNCS 13248, 2022, pp. 34–49
2022
-
[6]
Frequent itemset mining: A 25 years review,
J. M. Luna, P. Fournier-Viger, and S. Ventura, “Frequent itemset mining: A 25 years review,”WIREs Data Mining Knowl. Discov., vol. 9, no. 6, e1329, 2019
2019
-
[7]
Mining association rules with multiple minimum supports,
B. Liu, W. Hsu, and Y. Ma, “Mining association rules with multiple minimum supports,” inProc. KDD, 1999, pp. 337–341
1999
-
[8]
Efficient tree structures for high utility pattern mining in incremental databases,
C. F. Ahmed, S. K. Tanbeer, B.-S. Jeong, and Y.-K. Lee, “Efficient tree structures for high utility pattern mining in incremental databases,”IEEE Trans. Knowl. Data Eng., vol. 21, no. 12, pp. 1708–1721, 2009
2009
-
[9]
A survey of high utility itemset mining,
P. Fournier-Viger, J. C.-W. Lin, T. Truong-Chi, and R. Nkambou, “A survey of high utility itemset mining,” inHigh-Utility Pattern Mining, Springer, 2019, pp. 1–45
2019
-
[10]
Association rules mining with auto- encoders,
T. Berteloot, R. Khoury, and A. Durand, “Association rules mining with auto- encoders,” inProc. IDEAL, LNCS, Springer, 2025
2025
-
[11]
Learning se- mantic association rules from internet of things data,
E. Karabulut, R. Pellicer-Valero, V. Degeler, and P. Fournier-Viger, “Learning se- mantic association rules from internet of things data,” arXiv:2412.03417, 2024
-
[12]
Differentiable pattern set mining,
J. Fischer and J. Vreeken, “Differentiable pattern set mining,” inProc. KDD, 2021, pp. 383–392
2021
-
[13]
Probabilistic and reinforced mining of as- sociation rules,
S. Ghosh, A. Chakraborty, and S. Dey, “Probabilistic and reinforced mining of as- sociation rules,” arXiv:2506.18155, 2025
-
[14]
Deep learning-based sequential pattern mining for progressive database,
A. Jamshed, B. Mallick, and P. Kumar, “Deep learning-based sequential pattern mining for progressive database,”Soft Computing, vol. 24, no. 22, pp. 17233–17246, 2020
2020
-
[15]
A novel deep learning model for high-utility item set mining in transactional data,
M. K. Porwal and N. Porwal, “A novel deep learning model for high-utility item set mining in transactional data,” inIntelligent Systems (ICMIB 2025), LNNS vol. 1623, Springer, 2026, pp. 267–280
2025
-
[16]
A new framework for metaheuristic-based frequent itemset mining,
Y. Djenouri, D. Djenouri, A. Belhadi, P. Fournier-Viger, and J. C.-W. Lin, “A new framework for metaheuristic-based frequent itemset mining,”Applied Intelligence, vol. 48, pp. 4775–4791, 2018
2018
-
[17]
A survey of evolutionary com- putation for association rule mining,
A. Telikani, A. H. Gandomi, and A. Shahbahrami, “A survey of evolutionary com- putation for association rule mining,”Information Sciences, vol. 524, pp. 318–352, 2020
2020
-
[18]
Discovering transitional patterns and their significant milestones in transaction databases,
Q. Wan and A. An, “Discovering transitional patterns and their significant milestones in transaction databases,”IEEE Trans. Knowl. Data Eng., vol. 21, no. 12, pp. 1692– 1707, 2009. 19
2009
-
[19]
Mining general temporal association rules for items with different exhibition periods,
C.-Y. Chang, M.-S. Chen, and C.-H. Lee, “Mining general temporal association rules for items with different exhibition periods,” inProc. ICDM, 2002, pp. 59–66
2002
-
[20]
Progressive partition miner: An efficient algorithm for mining general temporal association rules,
C.-H. Lee, M.-S. Chen, and C.-R. Lin, “Progressive partition miner: An efficient algorithm for mining general temporal association rules,”IEEE Trans. Knowl. Data Eng., vol. 15, no. 4, pp. 1004–1017, 2003
2003
-
[21]
Bursty and hierarchical structure in streams,
J. Kleinberg, “Bursty and hierarchical structure in streams,”Data Mining and Knowledge Discovery, vol. 7, no. 4, pp. 373–397, 2003
2003
-
[22]
BurstSketch: Finding bursts in data streams,
Z. Yang, Y. Gong, Q. He, Y. Zhang, and T. Yang, “BurstSketch: Finding bursts in data streams,” inProc. ACM SIGMOD, 2021, pp. 2375–2383
2021
-
[23]
Discovering periodic- frequent patterns in transactional databases,
S. K. Tanbeer, C. F. Ahmed, B.-S. Jeong, and Y.-K. Lee, “Discovering periodic- frequent patterns in transactional databases,” inProc. PAKDD, 2009, pp. 242–253
2009
-
[24]
Efficient discovery of periodic- frequent patterns in very large databases,
R. U. Kiran, M. Kitsuregawa, and P. K. Reddy, “Efficient discovery of periodic- frequent patterns in very large databases,”J. Systems and Software, vol. 112, pp. 110–121, 2016
2016
-
[25]
Discovering periodic high utility itemsets in a discrete sequence,
P. Fournier-Vigeret al., “Discovering periodic high utility itemsets in a discrete sequence,” inHigh-Utility Pattern Mining, Studies in Big Data vol. 51, Springer, 2021, pp. 157–181
2021
-
[26]
Mining top-K periodic-frequent pat- tern from transactional databases without support threshold,
K. Amphawan, P. Lenca, and A. Surarerks, “Mining top-K periodic-frequent pat- tern from transactional databases without support threshold,” inProc. IAIT, 2009, pp. 18–29
2009
-
[27]
An efficient bit-based approach for mining skyline periodic itemset patterns,
J.-Y. Chen, Y.-C. Chen, and S.-Y. Lee, “An efficient bit-based approach for mining skyline periodic itemset patterns,”Electronics, vol. 12, no. 23, 4874, 2023
2023
-
[28]
Discov- ering partial periodic-frequent patterns in a transactional database,
R. U. Kiran, J. Venkatesh, M. Toyoda, M. Kitsuregawa, and P. K. Reddy, “Discov- ering partial periodic-frequent patterns in a transactional database,”J. Systems and Software, vol. 125, pp. 170–182, 2017
2017
-
[29]
A survey on temporal databases and data mining,
V. Radhakrishna, P. Kumar, and V. Janaki, “A survey on temporal databases and data mining,” inProc. ICEMIS, 2015, pp. 1–6
2015
-
[30]
Efficient mining of emerging patterns: Discovering trends and differences,
G. Dong and J. Li, “Efficient mining of emerging patterns: Discovering trends and differences,” inProc. KDD, 1999, pp. 43–52
1999
-
[31]
Association rule mining considering local frequent patterns with temporal intervals,
K.-C. Yin, Y.-L. Hsieh, D.-L. Yang, and M.-C. Hung, “Association rule mining considering local frequent patterns with temporal intervals,”Applied Mathematics & Information Sciences, vol. 8, no. 4, pp. 1879–1890, 2014
2014
-
[32]
Time aware mining of itemsets,
B. Saleh and F. Masseglia, “Time aware mining of itemsets,” inProc. TIME, 2008, pp. 93–97
2008
-
[33]
Discovering frequent behaviors: Time is an essential element of the context,
B. Saleh and F. Masseglia, “Discovering frequent behaviors: Time is an essential element of the context,”Knowledge and Information Systems, vol. 28, no. 2, pp. 311– 331, 2011. 20
2011
-
[34]
Finding locally and period- ically frequent sets and periodic association rules,
A. K. Mahanta, F. A. Mazarbhuiya, and H. K. Baruah, “Finding locally and period- ically frequent sets and periodic association rules,” inProc. PReMI, 2005, pp. 576– 582
2005
-
[35]
Mining local periodic patterns in a discrete sequence,
P. Fournier-Viger, P. Yang, R. U. Kiran, S. Ventura, and J. M. Luna, “Mining local periodic patterns in a discrete sequence,”Information Sciences, vol. 544, pp. 519– 548, 2021
2021
-
[36]
Discovering recurring patterns in time series,
R. U. Kiran, H. Shang, M. Toyoda, and M. Kitsuregawa, “Discovering recurring patterns in time series,” inProc. EDBT, 2015, pp. 97–108
2015
-
[37]
Sliding-window filtering: An efficient algo- rithm for incremental mining,
C.-H. Lee, C.-R. Lin, and M.-S. Chen, “Sliding-window filtering: An efficient algo- rithm for incremental mining,” inProc. CIKM, 2001, pp. 263–270
2001
-
[38]
DSTree: A tree structure for the mining of frequent sets from data streams,
C. K.-S. Leung and Q. I. Khan, “DSTree: A tree structure for the mining of frequent sets from data streams,” inProc. ICDM, 2006, pp. 928–932
2006
-
[39]
A survey of methods for time series change point detection,
S. Aminikhanghahi and D. J. Cook, “A survey of methods for time series change point detection,”Knowledge and Information Systems, vol. 51, no. 2, pp. 339–367, 2017
2017
-
[40]
The SPMF open-source data mining library version 2,
P. Fournier-Viger, J. C.-W. Lin, A. Gomariz, T. Gueniche, A. Soltani, Z. Deng, and H. T. Lam, “The SPMF open-source data mining library version 2,” inProc. ECML-PKDD, 2016, pp. 36–40
2016
-
[41]
Algorithms for frequent itemset mining: A literature review,
C.-H. Chee, J. Jaafar, I. A. Aziz, M. H. Hasan, and W. Yeoh, “Algorithms for frequent itemset mining: A literature review,”Artificial Intelligence Review, vol. 52, pp. 2603–2621, 2019. A Synthetic Data Generation for the Scalability Ex- periment Synthetic data were generated to evaluate the scalability of the proposed method. For background transaction ge...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.