Recognition: unknown
FDIM: A Feature-distance-based Generic Video Quality Metric for Versatile Codecs
Pith reviewed 2026-05-08 04:49 UTC · model grok-4.3
The pith
FDIM measures video quality through distances in a hybrid space of deep multi-scale features and hand-crafted features, producing scores that align with human ratings across codecs never seen during training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FDIM employs a hybrid architecture that integrates deep and hand-crafted features. The deep feature component learns multi-scale representations to capture distortions ranging from structural and textural fidelity degradation to high-level semantic deviations, while the hand-crafted feature component provides stable complementary cues to improve overall generalization. We trained FDIM on a large-scale subjective quality assessment dataset consisting of over 16k video sequences encoded by traditional block-based hybrid video codecs and end-to-end perceptually optimized neural video codecs. Extensive experiments on ten SDR/HDR VQA datasets containing diverse, previously unseen codecs show that
What carries the argument
Hybrid feature-distance calculation that combines multi-scale deep representations with hand-crafted descriptors to quantify perceptual differences between a reference video and its compressed version.
If this is right
- The same trained model can be applied directly to evaluate quality for any new neural video codec without retraining or fine-tuning.
- FDIM produces usable scores for both standard dynamic range and high dynamic range video without separate versions of the metric.
- Codec developers can use FDIM scores to guide optimization loops and benchmark competing algorithms on equal footing.
- The method reduces the frequency of large-scale subjective tests when exploring new compression techniques or content types.
Where Pith is reading between the lines
- If the hybrid distance remains stable, FDIM could be embedded inside encoders to adjust parameters on the fly for better perceptual results.
- The same distance-based idea might transfer to quality assessment for still images or volumetric content by swapping in appropriate feature extractors.
- Real-world streaming systems that switch between multiple codecs could adopt FDIM to monitor delivered quality uniformly.
- Further tests on generative compression methods that produce artifacts outside the current training distribution would clarify the limits of the generalization.
Load-bearing premise
The specific deep and hand-crafted features chosen and the distances learned from the training videos will continue to match human perception when applied to entirely new codec designs and video contents.
What would settle it
Apply FDIM to videos encoded by a newly developed neural codec architecture absent from both the training set and the ten evaluation datasets, collect fresh subjective ratings from human viewers, and check whether the correlation between FDIM scores and those ratings falls substantially below the levels reported on the original test sets.
Figures





read the original abstract
Video technology is advancing toward Ultra High Definition (UHD) and High Dynamic Range (HDR), which intensifies the need for higher compression efficiency for these high-specification videos. Beyond advances in traditional codecs, neural video codecs (NVCs) have attracted significant research attention and have evolved rapidly over the past few years. The coding artifacts of NVCs often exhibit content-varying and generative characteristics, which differ from those of conventional codecs and are challenging for traditional video quality assessment (VQA) methods to capture. Therefore, VQA metrics are required to generalize across different codecs, content types, and dynamic ranges to better support video codec research and evaluation. In this paper, we propose FDIM, a feature-distance-based generic video quality metric for both traditional and neural video codecs across SDR and HDR formats. FDIM employs a hybrid architecture that integrates deep and hand-crafted features. The deep feature component learns multi-scale representations to capture distortions ranging from structural and textural fidelity degradation to high-level semantic deviations, while the hand-crafted feature component provides stable complementary cues to improve overall generalization. We trained FDIM on a large-scale subjective quality assessment dataset (DCVQA) consisting of over 16k video sequences encoded by traditional block-based hybrid video codecs and end-to-end perceptually optimized neural video codecs. Extensive experiments on ten SDR/HDR VQA datasets containing diverse, previously unseen codecs demonstrate that FDIM achieves strong generalization and high correlation with subjective assessment. The source code for FDIM and the DCVQA validation set will be released at https://github.com/MCL-ZJU/FDIM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FDIM, a hybrid feature-distance-based video quality metric for traditional and neural video codecs across SDR and HDR. It combines multi-scale deep features (capturing structural, textural, and semantic distortions) with hand-crafted features for complementary cues, trained supervised on the large DCVQA dataset (>16k sequences from block-based and end-to-end neural codecs). Extensive tests on ten held-out SDR/HDR VQA datasets with previously unseen codecs are reported to show strong generalization and high correlation with subjective scores; code and DCVQA validation set will be released.
Significance. If the reported generalization holds under scrutiny, FDIM would address a timely need for versatile VQA tools that handle generative artifacts from neural codecs alongside conventional ones. The hybrid architecture, scale of the DCVQA training set, and planned public release of code plus validation data are concrete strengths that support reproducibility and further research in codec evaluation.
major comments (2)
- [§4] §4 (Experiments and Results): The central generalization claim relies on performance across ten held-out datasets, yet the manuscript provides no ablation isolating the contribution of the hand-crafted feature component versus deep features alone (or versus a pure deep baseline). Without these controls it remains unclear whether the hybrid design is load-bearing for the reported gains on unseen codecs.
- [§3.2] §3.2 (Hybrid Feature Fusion): The fusion mechanism for deep and hand-crafted distances is described at a high level but lacks explicit equations or pseudocode for the weighting scheme and training objective. This makes it difficult to assess whether the reported robustness stems from the architecture or from post-hoc tuning on DCVQA subjective scores.
minor comments (4)
- [Abstract] Abstract: Key quantitative results (e.g., average PLCC/SROCC across the ten datasets) are omitted; adding the headline numbers would immediately strengthen the summary of the generalization claim.
- [§2] §2 (Related Work): Several recent neural codec VQA papers are cited, but the discussion does not explicitly contrast FDIM's feature-distance approach with recent no-reference or full-reference neural metrics; a short comparative table would improve context.
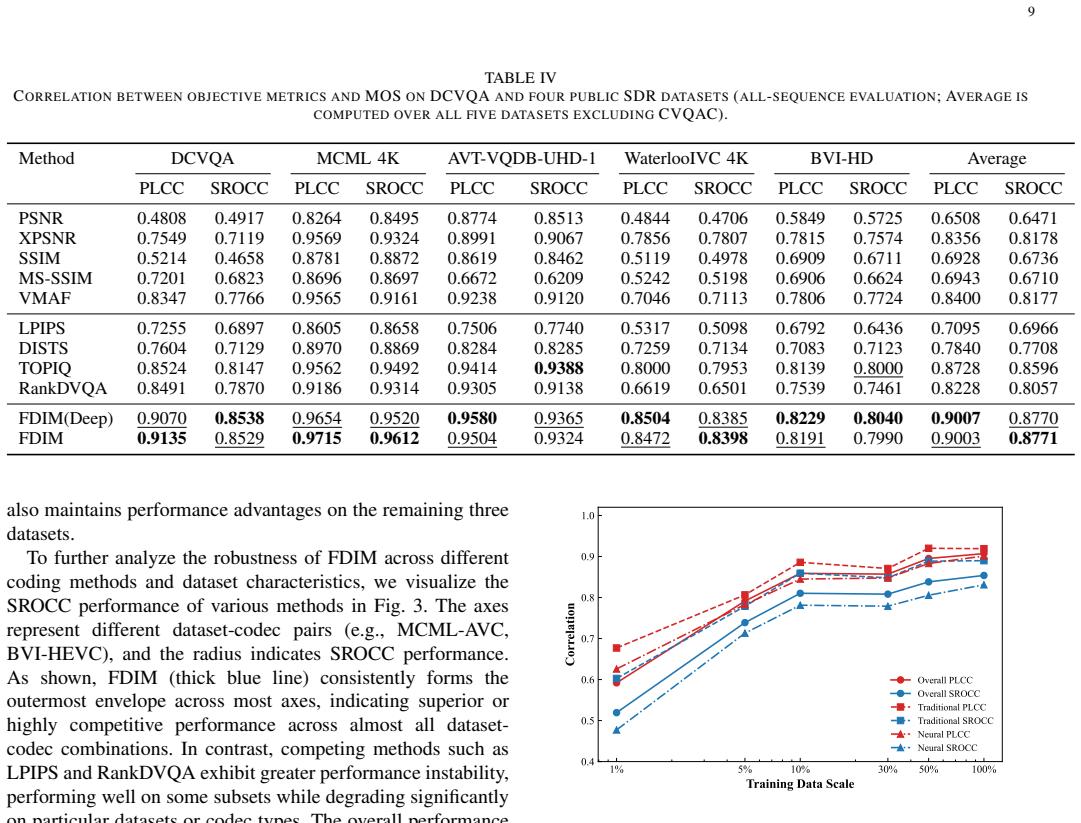
- [Figure 3] Figure 3 and Table 4: Axis labels and legend entries are too small for readability in print; increasing font size and adding error bars or confidence intervals on correlation plots would aid interpretation.
- [§5] §5 (Conclusion): The limitations paragraph mentions content dependence but does not discuss potential failure modes on extreme HDR content or very low-bitrate neural codecs; expanding this would be useful.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the timely need for versatile VQA metrics, and the recommendation of minor revision. We address each major comment below and will update the manuscript accordingly to strengthen clarity and evidence.
read point-by-point responses
-
Referee: [§4] §4 (Experiments and Results): The central generalization claim relies on performance across ten held-out datasets, yet the manuscript provides no ablation isolating the contribution of the hand-crafted feature component versus deep features alone (or versus a pure deep baseline). Without these controls it remains unclear whether the hybrid design is load-bearing for the reported gains on unseen codecs.
Authors: We agree that an explicit ablation would strengthen the evidence for the hybrid design. The original manuscript reported the full FDIM performance on the ten held-out datasets but did not include component-wise ablations. In the revised version we will add a new ablation subsection (in §4) that compares (i) the complete hybrid FDIM, (ii) a deep-features-only variant, and (iii) a hand-crafted-features-only baseline, all trained and evaluated under identical conditions on the same held-out sets. This will directly quantify the incremental benefit of the hybrid fusion for generalization across unseen codecs. revision: yes
-
Referee: [§3.2] §3.2 (Hybrid Feature Fusion): The fusion mechanism for deep and hand-crafted distances is described at a high level but lacks explicit equations or pseudocode for the weighting scheme and training objective. This makes it difficult to assess whether the reported robustness stems from the architecture or from post-hoc tuning on DCVQA subjective scores.
Authors: We acknowledge that the description in §3.2 was kept at a high level. In the revised manuscript we will expand this section with (a) explicit equations defining the per-scale deep-feature distances, the hand-crafted distance terms, and the learned fusion weights; (b) the composite training objective (including the regression loss and any regularization terms); and (c) pseudocode for the end-to-end training and inference pipeline. These additions will make the architecture and training procedure fully reproducible and will clarify that the weighting is learned jointly rather than tuned post-hoc. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents FDIM as a supervised hybrid feature-distance metric trained on the DCVQA subjective dataset and evaluated for generalization on ten held-out SDR/HDR datasets with unseen codecs. No derivation chain, equations, or first-principles claims are advanced that reduce by construction to the training inputs or prior self-citations. The performance claims rest on empirical cross-dataset correlations rather than any self-definitional, fitted-prediction, or uniqueness-imported tautology. This is the expected non-circular outcome for a data-driven VQA metric paper.
Axiom & Free-Parameter Ledger
free parameters (2)
- deep feature extractor parameters
- hybrid fusion weights
axioms (1)
- domain assumption Distances in learned deep feature spaces and hand-crafted feature spaces correlate monotonically with human-perceived video quality degradation.
Reference graph
Works this paper leans on
-
[1]
Overview of the high efficiency video coding (HEVC) standard,
G. J. Sullivan, J.-R. Ohm, W. Han, and T. Wiegand, “Overview of the high efficiency video coding (HEVC) standard,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 22, no. 12, pp. 1649– 1668, 2012
2012
-
[2]
Overview of the versatile video coding (VVC) standard and its applications,
B. Bross, Y .-K. Wang, Y . Ye, S. Liu, J. Chen, G. J. Sullivan, and J.- R. Ohm, “Overview of the versatile video coding (VVC) standard and its applications,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 10, pp. 3736–3764, 2021
2021
-
[3]
Algorithm description for neural network-based video coding (nnvc- 6.0),
“Algorithm description for neural network-based video coding (nnvc- 6.0),” Joint Video Experts Team (JVET) of ITU-T SG16 WP3 and ISO/IEC JTC1/SC 29 AE2019-v2, 2023
2023
-
[4]
DVC: An end-to-end deep video compression framework,
G. Lu, W. Ouyang, D. Xu, X. Zhang, C. Cai, and Z. Gao, “DVC: An end-to-end deep video compression framework,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 11 006–11 015
2019
-
[5]
FVC: A new framework towards deep video compression in feature space,
Z. Hu, W. Xu, J. Hu, S. Liu, W. Yang, and W. Lin, “FVC: A new framework towards deep video compression in feature space,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 1502–1511
2021
-
[6]
AlphaVC: High-performance and efficient learned video compression,
Y . Shi, Y . Ge, J. Wang, and J. Mao, “AlphaVC: High-performance and efficient learned video compression,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 616–631
2022
-
[7]
Towards practical real-time neural video compression,
Z. Jia, B. Li, J. Li, W. Xie, L. Qi, H. Li, and Y . Lu, “Towards practical real-time neural video compression,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 12 543–12 552
2025
-
[8]
Deep hierarchies in the primate visual cortex: What can we learn for computer vision?
N. Kruger, P. Janssen, S. Kalkan, M. Lappe, A. Leonardis, J. Piater, A. J. Rodriguez-Sanchez, and L. Wiskott, “Deep hierarchies in the primate visual cortex: What can we learn for computer vision?”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 8, pp. 1847–1871, 2013
2013
-
[9]
Image quality assessment: From error visibility to structural similarity,
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: From error visibility to structural similarity,”IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600–612, 2004
2004
-
[10]
Image information and visual quality,
H. R. Sheikh and A. C. Bovik, “Image information and visual quality,” IEEE Transactions on Image Processing, vol. 15, no. 2, pp. 430–444, 2006
2006
-
[11]
FSIM: A feature similarity index for image quality assessment,
L. Zhang, L. Zhang, X. Mou, and D. Zhang, “FSIM: A feature similarity index for image quality assessment,”IEEE Transactions on Image Processing, vol. 20, no. 8, pp. 2378–2386, 2011
2011
-
[12]
The perception-distortion tradeoff,
Y . Blau and T. Michaeli, “The perception-distortion tradeoff,” inPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018
2018
-
[13]
Deep convolutional neural models for picture-quality prediction: Challenges and solutions to data-driven image quality assessment,
J. Kim, H. Zeng, D. Ghadiyaram, S. Lee, L. Zhang, and A. C. Bovik, “Deep convolutional neural models for picture-quality prediction: Challenges and solutions to data-driven image quality assessment,”IEEE Signal Processing Magazine, vol. 34, no. 6, pp. 130–141, 2017
2017
-
[14]
Deep video quality assessor: From spatio-temporal visual sensitivity to a convolutional neural aggregation network,
W. Kim, J. Kim, S. Ahn, J. Kim, and S. Lee, “Deep video quality assessor: From spatio-temporal visual sensitivity to a convolutional neural aggregation network,” inEuropean Conference on Computer Vision, 2018, pp. 219–234
2018
-
[15]
Perceptual quality assessment of internet videos,
J. Xu, J. Li, X. Zhou, W. Zhou, B. Wang, and Z. Chen, “Perceptual quality assessment of internet videos,” inProceedings of the ACM International Conference on Multimedia, 2020, pp. 1248–1257
2020
-
[16]
Attentions help CNNs see better: Attention-based hybrid image quality assessment network,
S. Laoet al., “Attentions help CNNs see better: Attention-based hybrid image quality assessment network,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2022, pp. 1140–1149
2022
-
[17]
StarVQA: Space- time attention for video quality assessment,
F. Xing, Y .-G. Wang, H. Wang, L. Li, and G. Zhu, “StarVQA: Space- time attention for video quality assessment,” in2022 IEEE International Conference on Image Processing (ICIP). IEEE, 2022, pp. 2326–2330
2022
-
[18]
DisCoVQA: Temporal distortion-content transformers for video quality assessment,
H. Wu, C. Chen, L. Liao, J. Hou, W. Sun, Q. Yan, and W. Lin, “DisCoVQA: Temporal distortion-content transformers for video quality assessment,” 2022
2022
-
[19]
TOPIQ: A top-down approach from semantics to distortions for image quality assessment,
J. Chenet al., “TOPIQ: A top-down approach from semantics to distortions for image quality assessment,”IEEE Transactions on Image Processing, vol. 33, pp. 2404–2418, 2024
2024
-
[20]
A study of subjective and objective quality assessment of HDR videos,
Z. Shang, J. P. Ebenezer, A. K. Venkataramanan, Y . Wu, H. Wei, S. Sethuraman, and A. C. Bovik, “A study of subjective and objective quality assessment of HDR videos,”IEEE Trans. Image Process., vol. 33, pp. 42–57, 2024
2024
-
[21]
R. K. Mantiuk, D. Hammou, and P. Hanji, “Hdr-vdp-3: A multi-metric for predicting image differences, quality and contrast distortions in high dynamic range and regular content,” 2023. [Online]. Available: https://arxiv.org/abs/2304.13625
-
[22]
ColorVideoVDP: A visual difference predictor for image, video and display distortions,
R. K. Mantiuket al., “ColorVideoVDP: A visual difference predictor for image, video and display distortions,”ACM Transactions on Graphics, vol. 40, no. 4, 2021
2021
-
[23]
Pu21: A novel perceptually uniform encoding for adapting existing quality metrics for hdr,
R. K. Mantiuk and M. Azimi, “Pu21: A novel perceptually uniform encoding for adapting existing quality metrics for hdr,” in2021 Picture Coding Symposium (PCS), 2021, pp. 1–5
2021
-
[24]
Mean squared error: Love it or leave it? A new look at signal fidelity measures,
Z. Wang and A. C. Bovik, “Mean squared error: Love it or leave it? A new look at signal fidelity measures,”IEEE Signal Processing Magazine, vol. 26, no. 1, pp. 98–117, 2009
2009
-
[25]
Multiscale structural similarity for image quality assessment,
Z. Wang, E. P. Simoncelli, and A. C. Bovik, “Multiscale structural similarity for image quality assessment,” inProceedings of the 37th Asilomar Conference on Signals, Systems and Computers, vol. 2, 2003, pp. 1398–1402
2003
-
[26]
A new standardized method for objectively measuring video quality,
M. H. Pinson and S. Wolf, “A new standardized method for objectively measuring video quality,”IEEE Transactions on Broadcasting, vol. 50, no. 3, pp. 312–322, 2004. 13
2004
-
[27]
Motion tuned spatio-temporal quality assessment of natural videos,
K. Seshadrinathan and A. C. Bovik, “Motion tuned spatio-temporal quality assessment of natural videos,”IEEE Transactions on Image Processing, vol. 19, no. 2, pp. 335–350, 2010
2010
-
[28]
Toward a practical perceptual video quality metric,
Z. Li, A. Aaron, I. Katsavounidis, A. Moorthy, and M. Manohara, “Toward a practical perceptual video quality metric,” Netflix Technology Blog, 2016
2016
-
[29]
Spatiotemporal feature integra- tion and model fusion for full reference video quality assessment,
C. G. Bampis, Z. Li, and A. C. Bovik, “Spatiotemporal feature integra- tion and model fusion for full reference video quality assessment,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 29, no. 8, pp. 2256–2270, 2019
2019
-
[30]
Enhancing VMAF through new feature integration and model combi- nation,
F. Zhang, A. Katsenou, C. Bampis, L. Krasula, Z. Li, and D. Bull, “Enhancing VMAF through new feature integration and model combi- nation,” in2021 Picture Coding Symposium (PCS), 2021, pp. 1–5
2021
-
[31]
High frame rate video quality assessment using VMAF and entropic differences,
P. C. Madhusudana, N. Birkbeck, Y . Wang, B. Adsumilli, and A. C. Bovik, “High frame rate video quality assessment using VMAF and entropic differences,” in2021 Picture Coding Symposium (PCS), 2021, pp. 1–5
2021
-
[32]
Perceptual video quality prediction emphasizing chroma distortions,
L.-H. Chen, C. G. Bampis, Z. Li, J. Sole, and A. C. Bovik, “Perceptual video quality prediction emphasizing chroma distortions,”IEEE Trans- actions on Image Processing, vol. 30, pp. 1408–1422, 2021
2021
-
[33]
One transform to compute them all: Efficient fusion-based full-reference video quality assessment,
A. K. Venkataramanan, C. Stejerean, I. Katsavounidis, and A. C. Bovik, “One transform to compute them all: Efficient fusion-based full-reference video quality assessment,”IEEE Transactions on Image Processing, vol. 33, pp. 509–524, 2024
2024
-
[34]
Quality assessment of in-the-wild videos,
D. Li, T. Jiang, and M. Jiang, “Quality assessment of in-the-wild videos,” inProceedings of the ACM International Conference on Multimedia, 2019, pp. 2351–2359
2019
-
[35]
dipiq: Blind image quality assessment by learning-to-rank discriminable image pairs,
K. Ma, W. Liu, T. Liu, Z. Wang, and D. Tao, “dipiq: Blind image quality assessment by learning-to-rank discriminable image pairs,”IEEE Transactions on Image Processing, vol. 26, no. 8, p. 3951–3964, 2017
2017
-
[36]
RankDVQA: Deep VQA based on ranking-inspired hybrid training,
C. Feng, D. Danier, F. Zhang, and D. Bull, “RankDVQA: Deep VQA based on ranking-inspired hybrid training,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 1648–1658
2024
-
[37]
Conviqt: Contrastive video quality estimator,
P. C. Madhusudana, N. Birkbeck, Y . Wang, B. Adsumilli, and A. C. Bovik, “Conviqt: Contrastive video quality estimator,”IEEE Transac- tions on Image Processing, vol. 32, pp. 5138–5152, 2023
2023
-
[38]
arXiv preprint arXiv:2312.17090 (2023)
H. Wu, Z. Zhang, W. Zhang, C. Chen, C. Li, L. Liao, A. Wang, E. Zhang, W. Sun, Q. Yan, X. Min, G. Zhai, and W. Lin, “Q-Align: Teaching lmms for visual scoring via discrete text-defined levels,”arXiv preprint arXiv:2312.17090, 2023, equal Contribution by Wu, Haoning and Zhang, Zicheng. Corresponding Authors: Zhai, Guangtao and Lin, Weisi
-
[39]
Lmm-vqa: Advancing video quality assessment with large multimodal models,
Q. Ge, W. Sun, Y . Zhang, Y . Li, Z. Ji, F. Sun, S. Jui, X. Min, and G. Zhai, “Lmm-vqa: Advancing video quality assessment with large multimodal models,” 2024. [Online]. Available: https://arxiv.org/abs/2408.14008
-
[40]
Overview of intelligent video coding: from model-based to learning- based approaches,
S. Ma, J. Gao, R. Wang, J. Chang, Q. Mao, Z. Huang, and C. Jia, “Overview of intelligent video coding: from model-based to learning- based approaches,”Visual Intelligence, vol. 1, no. 1, p. 15, 2023
2023
-
[41]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 586–595
2018
-
[42]
Full reference video quality assessment for machine learning- based video codecs,
A. Majeedi, B. Naderi, Y . Hosseinkashi, J. Cho, R. A. Martinez, and R. Cutler, “Full reference video quality assessment for machine learning- based video codecs,” 2023
2023
-
[43]
Evaluating video quality metrics for neural and traditional codecs using 4k/uhd-1 videos,
B. Herb, R. R. R. Rao, S. G ¨oring, and A. Raake, “Evaluating video quality metrics for neural and traditional codecs using 4k/uhd-1 videos,” inProc. Picture Coding Symposium (PCS), 2025
2025
-
[44]
A technical overview of A V1,
J. Han, B. Li, D. Mukherjee, C.-H. Chiang, A. Grange, C. Chen, H. Su, S. Parker, S. Deng, U. Joshi, Y . Chen, Y . Wang, P. Wilkins, Y . Xu, and J. Bankoski, “A technical overview of A V1,”Proceedings of the IEEE, vol. 109, no. 9, pp. 1435–1462, 2021
2021
-
[45]
Overview of the versatile video coding (VVC) standard and its applications,
B. Bross, Y . Wang, Y . Ye, S. Liu, J. Chen, G. J. Sullivan, and J. Ohm, “Overview of the versatile video coding (VVC) standard and its applications,”IEEE Trans. Circuits Syst. Video Technol., vol. 31, no. 10, pp. 3736–3764, 2021
2021
-
[46]
Neural video compression with feature modulation,
J. Li, B. Li, and Y . Lu, “Neural video compression with feature modulation,” in2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 26 099–26 108
2024
-
[47]
Subjective visual quality assessment for high-fidelity learning-based image compression,
M. Jenadeleh, J. Sneyers, P. Jia, S. Mohammadi, J. Ascenso, and D. Saupe, “Subjective visual quality assessment for high-fidelity learning-based image compression,” inProc. QoMEX, 2025
2025
-
[48]
Jpeg ai: The first international standard for image coding based on an end-to-end learning-based approach,
E. Alshina, J. Ascenso, and T. Ebrahimi, “Jpeg ai: The first international standard for image coding based on an end-to-end learning-based approach,”IEEE MultiMedia, vol. 31, no. 4, pp. 60–69, 2024
2024
-
[49]
A funque approach to the quality assessment of compressed hdr videos,
A. K. Venkataramanan, C. Stejerean, I. Katsavounidis, and A. C. Bovik, “A funque approach to the quality assessment of compressed hdr videos,” in2024 Picture Coding Symposium (PCS), 2024, pp. 1–5
2024
-
[50]
Adapting pretrained networks for image quality assessment on high dynamic range displays,
A. Chubarau, H. Yoo, T. Akhavan, and J. Clark, “Adapting pretrained networks for image quality assessment on high dynamic range displays,” 2024
2024
-
[51]
HIDRO-VQA: High dynamic range oracle for video quality assessment,
S. Saini, A. Saha, and A. C. Bovik, “HIDRO-VQA: High dynamic range oracle for video quality assessment,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) Work- shops, January 2024, pp. 469–479
2024
-
[52]
Compressedvqa-hdr: Generalized full-reference and no-reference qual- ity assessment models for compressed high dynamic range videos,
W. Sun, L. Cao, K. Fu, D. Zhu, J. Jia, M. Hu, X. Min, and G. Zhai, “Compressedvqa-hdr: Generalized full-reference and no-reference qual- ity assessment models for compressed high dynamic range videos,” in 2025 IEEE International Conference on Multimedia and Expo Work- shops (ICMEW), 2025, pp. 1–6
2025
-
[53]
HDR-VDP-2: A calibrated visual metric for visibility and quality predictions in all luminance conditions,
R. Mantiuk, K. J. Kim, A. G. Rempel, and W. Heidrich, “HDR-VDP-2: A calibrated visual metric for visibility and quality predictions in all luminance conditions,”ACM Transactions on Graphics, vol. 30, no. 4, pp. 1–14, 2011
2011
-
[54]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778
2016
-
[55]
Imagenet large scale visual recognition challenge,
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernsteinet al., “Imagenet large scale visual recognition challenge,”International journal of computer vision, vol. 115, no. 3, pp. 211–252, 2015
2015
-
[56]
Deformable convolutional networks,
J. Dai, H. Qi, Y . Xiong, Y . Li, G. Zhang, H. Hu, and Y . Wei, “Deformable convolutional networks,” inProceedings of the IEEE International Conference on Computer Vision, 2017, pp. 764–773
2017
-
[57]
Seven challenges in image quality assessment: Past, present, and future research,
D. M. Chandler, “Seven challenges in image quality assessment: Past, present, and future research,”ISRN Signal Processing, vol. 2013, pp. 1–53, 2013
2013
-
[58]
CBAM: Convolutional block attention module,
S. Woo, J. Park, J.-Y . Lee, and I. S. Kweon, “CBAM: Convolutional block attention module,” inEuropean Conference on Computer Vision, 2018, pp. 3–19
2018
-
[59]
Call for technical proposals for the avs objective video quality assess- ment standard,
“Call for technical proposals for the avs objective video quality assess- ment standard,” A VS N3856, 2024
2024
-
[60]
Consumer Digital Video Library,
Institute for Telecommunication Sciences, “Consumer Digital Video Library,” https://www.cdvl.org/
-
[61]
Xiph Video Codec Test Media,
Xiph.Org Foundation, “Xiph Video Codec Test Media,” https://media. xiph.org/
-
[62]
IVP Subjective Quality Video Database,
Chinese University of Hong Kong, “IVP Subjective Quality Video Database,” https://ivp.ee.cuhk.edu.hk/research/database/subjective/index. shtml
-
[63]
Towards perceptually optimized end-to-end adaptive video streaming,
C. Bampis, Z. Li, I. Katsavounidis, T.-Y . Huang, C. Ekanadham, and A. Bovik, “Towards perceptually optimized end-to-end adaptive video streaming,” 2018
2018
-
[64]
Gamingvideoset: A dataset for gaming video streaming applications,
N. Barman, S. Zadtootaghaj, S. Schmidt, M. G. Martini, and S. M ¨oller, “Gamingvideoset: A dataset for gaming video streaming applications,” in2018 16th Annual Workshop on Network and Systems Support for Games (NetGames), 2018, pp. 1–6
2018
-
[65]
Update on a perceptually optimized learning-based video codec for cvqm
“Update on a perceptually optimized learning-based video codec for cvqm.” ISO/IEC JTC 1/SC 29/AG 5 m69717, 2024
2024
-
[66]
Generative adversarial networks,
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial networks,” 2014
2014
-
[67]
A statistical evaluation of recent full reference image quality assessment algorithms,
H. R. Sheikh, M. F. Sabir, and A. C. Bovik, “A statistical evaluation of recent full reference image quality assessment algorithms,”IEEE Trans. Image Process., vol. 15, no. 11, pp. 3440–3451, 2006
2006
-
[68]
Image quality assess- ment: Unifying structure and texture similarity,
K. Ding, K. Ma, S. Wang, and E. P. Simoncelli, “Image quality assess- ment: Unifying structure and texture similarity,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 5, pp. 2567– 2581, 2022
2022
-
[69]
VTM and HM common test conditions and evaluation procedures for HDR/WCG video
A. Segall, E. Franc ¸ois, W. Husak, S. Iwamura, and D. Rusanovskyy, “VTM and HM common test conditions and evaluation procedures for HDR/WCG video.” Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29 JVET-AC2011, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.