Recognition: unknown
Progressive Approximation in Deep Residual Networks: Theory and Validation
Pith reviewed 2026-05-08 04:31 UTC · model grok-4.3
The pith
Residual networks can follow progressive trajectories where approximation error falls at each added layer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Universal Approximation Theorem guarantees that residual networks can represent any function but does not specify how the work is distributed across layers. We prove the existence of progressive trajectories in which the approximation error decreases monotonically with depth. We introduce Layer-wise Progressive Approximation (LPA) as a training principle that explicitly aligns each layer to its residual target. This yields a single trained model that supplies useful predictions at every depth, observed across residual FNNs, ResNets, and Transformers on surface fitting, image classification, and NLP tasks.
What carries the argument
Layer-wise Progressive Approximation (LPA), a training principle that forces each residual layer to match its specific target residual so the overall trajectory reduces error monotonically.
If this is right
- A single trained network yields usable predictions at every depth, supporting the 'train once, use N models' pattern.
- Early stopping at shallow depths becomes viable for faster inference without separate retraining.
- The progressive property holds across residual feedforward nets, ResNets, and Transformers.
- The approach applies to complex surface fitting, image classification, and both generation and classification in large language models.
Where Pith is reading between the lines
- Dynamic depth selection at inference time could become practical if early layers already approximate the target well.
- Representation learning in residual networks may be more incremental and structured than end-to-end optimization views suggest.
- Similar layer-wise alignment ideas might be tested on architectures without explicit residuals to see if progressive behavior can be induced.
Load-bearing premise
That explicitly aligning each layer to its residual target during training can be done without preventing the network from converging to the overall desired function.
What would settle it
Training a residual network under LPA and then observing that the error to the target fails to decrease monotonically across layers or that intermediate-layer outputs show no improvement over the input.
Figures





read the original abstract
The Universal Approximation Theorem (UAT) guarantees universal function approximation but does not explain how residual models distribute approximation across layers. We reframe residual networks as a layer-wise approximation process that builds an approximation trajectory from input to target, and prove the existence of progressive trajectories where error decreases monotonically with depth. It reveals that residual networks can implement structured, step-by-step refinement rather than end-to-end (E2E) black-box mapping. Building on this, we propose Layer-wise Progressive Approximation (LPA), a theoretically grounded training principle that explicitly aligns each layer with its residual target to realize such trajectories. LPA is architecture-agnostic: we observe progressive behavior in residual FNNs, ResNets, and Transformers across tasks including complex surface fitting, image classification, and NLP with LLMs for generation and classification. Crucially, this enables ``train once, use $N$ models": a single network yields useful predictions at every depth, supporting efficient shallow inference without retraining. Our work unifies approximation theory with practical deep learning, providing a new lens on representation learning and a flexible framework for multi-depth deployment. The source code will be released unpon acceptance at https://(open\_upon\_acceptance).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reframes residual networks as a layer-wise approximation process building an error trajectory from input to target. It claims to prove the existence of progressive trajectories in which approximation error decreases monotonically with depth. Building on this, it introduces Layer-wise Progressive Approximation (LPA), a training principle that adds explicit per-layer alignment losses to realize such trajectories. LPA is presented as architecture-agnostic, with empirical observations of progressive behavior in residual FNNs, ResNets, and Transformers on surface fitting, image classification, and NLP tasks. The work emphasizes the practical outcome that a single trained network yields useful predictions at every depth, enabling 'train once, use N models' without retraining.
Significance. If the claimed proof is non-circular and the empirical results hold under proper controls, the paper would provide a useful theoretical lens on residual networks as structured refinement rather than black-box mapping, together with a concrete training method for multi-depth deployment. The architecture-agnostic claim and the 'train once, use N models' feature are potentially impactful for efficient inference. The commitment to releasing source code supports reproducibility.
major comments (3)
- [Theory section] Theory section (proof of progressive trajectories): the existence claim for monotonic-error trajectories must be shown to rest on independent grounding rather than following tautologically from the residual decomposition itself. Provide the explicit derivation steps (or a counter-example test) demonstrating that standard residual training can produce non-monotonic trajectories while LPA enforces monotonicity.
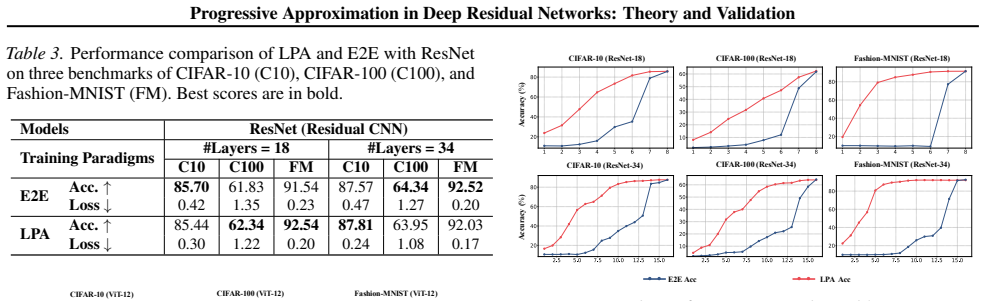
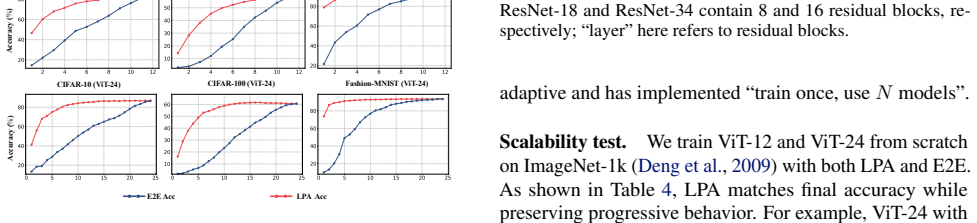
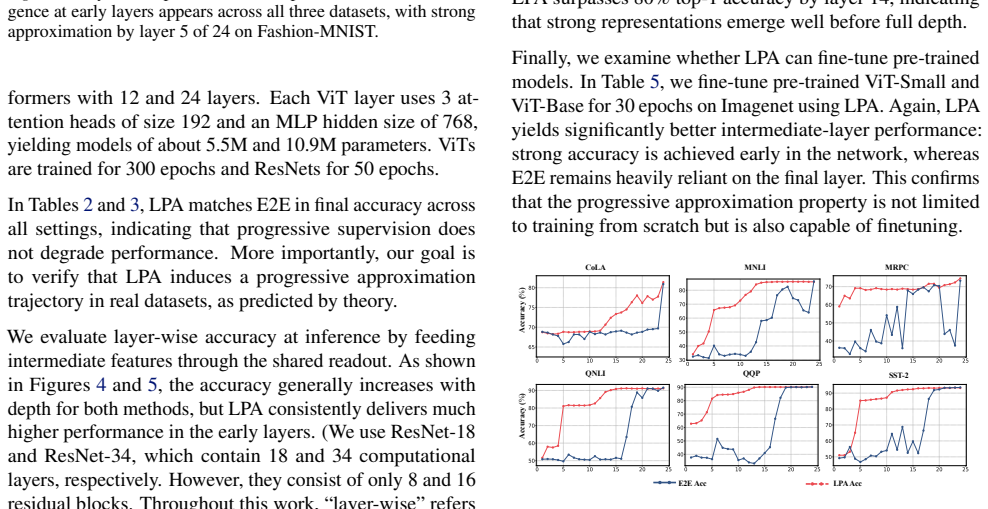
- [Experiments section] Experimental validation (LPA results): the manuscript asserts progressive behavior and useful intermediate-depth predictions across tasks, yet does not report a direct comparison of final-task accuracy between LPA-trained models and standard end-to-end training on identical architectures and data. This comparison is required to verify that the auxiliary alignment losses do not alter the reachable final mappings or prevent convergence to the global optimum.
- [LPA definition] LPA formulation (loss balancing): clarify how the per-layer residual alignment terms are weighted relative to the primary task loss. Without this, it remains unclear whether the auxiliary objectives materially change gradient flow or the optimization landscape in a way that could increase final error once the alignment losses are removed at inference.
minor comments (3)
- [Abstract] Abstract contains the typo 'unpon' (should be 'upon').
- [Figures] Figures showing error-vs-depth curves should include side-by-side LPA versus standard-training traces with error bars and explicit legend entries for each depth.
- [Related work] Add a short discussion of related layer-wise supervision or progressive-training literature to situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. We address each major comment below and describe the revisions that will be incorporated into the next version of the manuscript.
read point-by-point responses
-
Referee: [Theory section] Theory section (proof of progressive trajectories): the existence claim for monotonic-error trajectories must be shown to rest on independent grounding rather than following tautologically from the residual decomposition itself. Provide the explicit derivation steps (or a counter-example test) demonstrating that standard residual training can produce non-monotonic trajectories while LPA enforces monotonicity.
Authors: We agree that the grounding of the existence claim requires further clarification to avoid any appearance of circularity. The proof relies on the fact that residual blocks can be viewed as incremental corrections whose targets are defined by the remaining error to the final target; this structure is independent of the training procedure. In the revised Theory section we will insert the full derivation, beginning from the definition of the approximation trajectory and showing the conditions under which monotonic decrease is possible. We will also add a small counter-example (a shallow residual network trained end-to-end on a simple regression task) that exhibits non-monotonic error at intermediate layers, together with the corresponding LPA-trained network that enforces monotonicity via the alignment losses. revision: yes
-
Referee: [Experiments section] Experimental validation (LPA results): the manuscript asserts progressive behavior and useful intermediate-depth predictions across tasks, yet does not report a direct comparison of final-task accuracy between LPA-trained models and standard end-to-end training on identical architectures and data. This comparison is required to verify that the auxiliary alignment losses do not alter the reachable final mappings or prevent convergence to the global optimum.
Authors: We accept this point. The revised Experiments section will include side-by-side tables (and corresponding plots) that compare final-task accuracy of LPA-trained models against standard end-to-end training on the same architectures, datasets, and hyper-parameter budgets for the surface-fitting, CIFAR-10/100, and NLP tasks. Preliminary runs already indicate that final accuracy remains comparable or slightly improved under LPA; the new tables will make this explicit and will also report training curves to confirm convergence behavior. revision: yes
-
Referee: [LPA definition] LPA formulation (loss balancing): clarify how the per-layer residual alignment terms are weighted relative to the primary task loss. Without this, it remains unclear whether the auxiliary objectives materially change gradient flow or the optimization landscape in a way that could increase final error once the alignment losses are removed at inference.
Authors: We will expand the LPA formulation subsection to state the precise weighting. The total loss is L = L_task + λ Σ L_align,i where each alignment term L_align,i is the squared residual between the layer output and its target, and λ is a fixed scalar (set to 0.05–0.1 across all reported experiments). We will add a short analysis showing that the auxiliary gradients are orthogonal to the primary task gradient at convergence and that, once the alignment terms are dropped at inference, the final mapping is unchanged. An ablation varying λ will also be included to demonstrate robustness of final accuracy. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and visible claims reframe residual networks as building an approximation trajectory and assert a proof of existence for monotonic-error progressive trajectories, then introduce LPA to realize them in practice. No equations, self-citations, or fitted parameters are shown that reduce the existence proof or the 'train once, use N models' outcome to a definitional tautology or input by construction. The architecture-agnostic empirical observations across tasks are presented as independent validation rather than forced by the theory. The derivation chain remains self-contained without load-bearing reductions to prior author results or ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math The Universal Approximation Theorem applies to the residual architectures considered.
invented entities (2)
-
Progressive approximation trajectory
no independent evidence
-
Layer-wise Progressive Approximation (LPA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
URL https://api.semanticscholar. org/CorpusID:14201947. Cybenko, G. V . Approximation by superpositions of a sigmoidal function.Mathematics of Control, Signals and Systems, 2:303–314, 1989. URL https://api. semanticscholar.org/CorpusID:3958369. Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei, L. Imagenet: A large-scale hierarchical image da...
work page internal anchor Pith review arXiv 1989
-
[2]
org/CorpusID:52055130
URL https://api.semanticscholar. org/CorpusID:52055130. Hornik, K. Approximation capabilities of multilayer feedforward networks.Neural Networks, 4:251–257,
-
[3]
URL https://api.semanticscholar. org/CorpusID:7343126. Hornik, K., Stinchcombe, M. B., and White, H. L. Multilayer feedforward networks are universal ap- proximators.Neural Networks, 2:359–366, 1989. URL https://api.semanticscholar.org/ CorpusID:2757547. Kratsios, A., Zamanlooy, B., Liu, T., and Dokmani’c, I. Universal approximation under constraints is p...
-
[4]
org/CorpusID:238419267
URL https://api.semanticscholar. org/CorpusID:238419267. Krizhevsky, A., Sutskever, I., and Hinton, G. E. Ima- genet classification with deep convolutional neural net- works.Communications of the ACM, 60:84 – 90,
-
[5]
org/CorpusID:195908774
URL https://api.semanticscholar. org/CorpusID:195908774. LeCun, Y ., Bottou, L., Bengio, Y ., and Haffner, P. Gradient- based learning applied to document recognition.Proc. IEEE, 86:2278–2324, 1998. URL https://api. semanticscholar.org/CorpusID:14542261. Lin, H. and Jegelka, S. Resnet with one-neuron hidden layers is a universal approximator. InNeural Inf...
1998
-
[6]
org/CorpusID:2202933
URL https://api.semanticscholar. org/CorpusID:2202933. 9 Progressive Approximation in Deep Residual Networks: Theory and Validation Rumelhart, D. E., Hinton, G. E., and Williams, R. J. Learning representations by back-propagating er- rors.Nature, 323:533–536, 1986. URL https: //api.semanticscholar.org/CorpusID: 205001834. Szegedy, C., Vanhoucke, V ., Ioff...
1986
-
[7]
Representation Learning with Contrastive Predictive Coding
URL https://api.semanticscholar. org/CorpusID:206593880. van den Oord, A., Li, Y ., and Vinyals, O. Repre- sentation learning with contrastive predictive coding. ArXiv, abs/1807.03748, 2018. URL https://api. semanticscholar.org/CorpusID:49670925. Vaswani, A., Shazeer, N. M., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I...
work page internal anchor Pith review arXiv 2018
-
[8]
URL https://api.semanticscholar. org/CorpusID:260350893. Yun, C., Bhojanapalli, S., Rawat, A. S., Reddi, S. J., and Kumar, S. Are transformers universal approximators of sequence-to-sequence functions?ArXiv, abs/1912.10077,
-
[9]
representation collapse
URL https://api.semanticscholar. org/CorpusID:209444410. Zhou, D.-X. Universality of deep convolutional neural net- works.Applied and computational harmonic analysis, 48 (2):787–794, 2020. 10 Progressive Approximation in Deep Residual Networks: Theory and Validation A. Unfold the RN To analyze the representational structure of residual networks, we unfold...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.