Recognition: unknown
Don't Pause! Every prediction matters in a streaming video
Pith reviewed 2026-05-08 04:28 UTC · model grok-4.3
The pith
Streaming video models either spam predictions or become unresponsive when evaluated continuously rather than at fixed pauses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
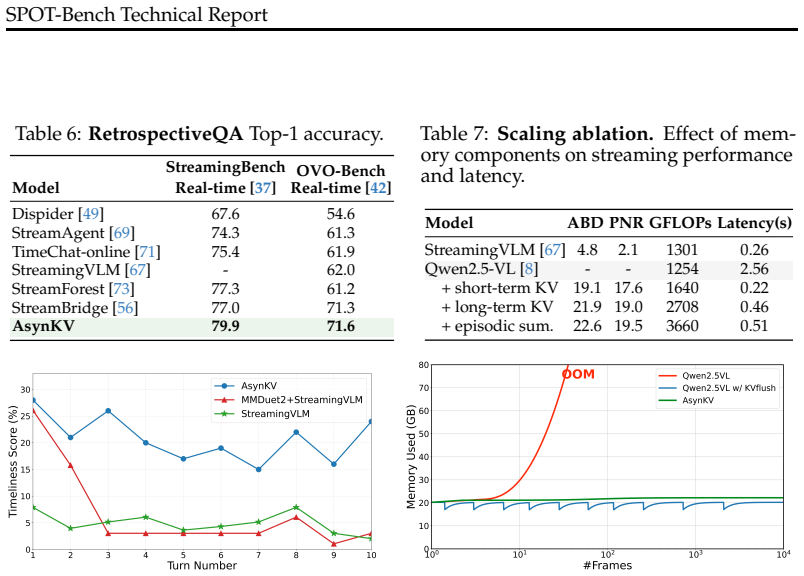
SPOT-Bench reveals that offline models detect events reliably but spam predictions unprompted, post-training for silence reduces spamming but induces unresponsiveness, and dead-time occupies half the video where compute does not affect response latency; AsynKV retains perception while improving streaming behavior by using long-short term memory scaled during dead-time and achieves SOTA on retrospective benchmarks.
What carries the argument
AsynKV's long-short term memory that scales compute only during dead-time periods to maintain event perception without raising response latency in continuous video streams.
If this is right
- Streaming evaluation must test continuous prediction rather than retrospective pauses to expose spamming or unresponsiveness.
- Dead-time periods allow extra computation without increasing observed latency, enabling more accurate perception at no cost to responsiveness.
- Training-free memory adaptations of offline models can outperform specialized streaming models on both streaming and retrospective tasks.
Where Pith is reading between the lines
- Real-world always-on assistants would gain from explicit detection of inactivity periods to allocate compute efficiently.
- The dead-time observation could apply to other sparse-event streaming domains such as audio or sensor streams.
- Integrating this memory mechanism with lightweight online updates might further reduce unresponsiveness over long sessions.
Load-bearing premise
The assumption that multi-turn proactive queries in SPOT-Bench and the Timeliness-F1 metric properly capture the requirements for always-on real-time video assistants.
What would settle it
Measuring whether AsynKV's responses in a live unpaused video stream match ground-truth event timings and avoid both false positives and missed detections at rates comparable to the benchmark results.
Figures








read the original abstract
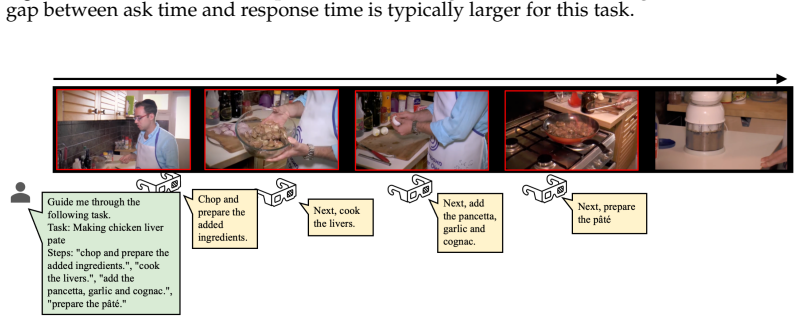
Streaming video models should respond the moment an event unfolds, not after the moment has passed. Yet existing online VideoQA benchmarks remain largely retrospective. They pause the video at fixed timestamps, pose questions about current or past events, and score models only at those moments. This protocol leaves streaming predictions untested. To close this gap, we introduce SPOT-Bench, featuring multi-turn proactive queries that evaluate general streaming perception and assistive capabilities required by an always-on, real-time assistant. SPOT-Bench comes with Timeliness-F1, a consolidated metric that measures streaming predictions by their temporal precision and balanced coverage across the entire video. Our benchmark reveals: (i) offline models detect events reliably but spam predictions unprompted; (ii) post-training for silence reduces spamming but induces unresponsiveness; (iii) half of the streaming video expects no response, which we term dead-time - compute spent here does not affect response latency. These findings motivate AsynKV, a training-free streaming adaptation of offline models, that retains their event perception while improving their streaming behavior. AsynKV features a long-short term memory, utilized efficiently by scaling compute during dead-time. It serves as a strong baseline on SPOT-Bench, outperforming existing streaming models, and achieves state-of-the-art on retrospective benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SPOT-Bench, a new benchmark for streaming video perception that uses multi-turn proactive queries instead of retrospective pauses, paired with the Timeliness-F1 metric that consolidates temporal precision and coverage across entire videos. It reports that offline models reliably detect events but spam unprompted predictions, that post-training for silence induces unresponsiveness, and that roughly half of streaming video is 'dead-time' where no response is expected. These observations motivate AsynKV, a training-free adaptation of offline models that employs long-short-term memory and scales compute during dead-time to improve streaming behavior while preserving perception; AsynKV is presented as a strong baseline on SPOT-Bench and SOTA on retrospective benchmarks.
Significance. If the benchmark and metric are shown to be faithful proxies for always-on real-time assistants, the work would usefully highlight practical gaps in current streaming evaluation and supply a simple, training-free baseline (AsynKV) that future methods could build upon. The explicit identification of dead-time as a compute-inefficiency factor and the provision of a new benchmark with a consolidated metric are concrete contributions that could steer the field toward more temporally aware video models.
major comments (1)
- Abstract: the central claims—that offline models spam predictions, silence training causes unresponsiveness, dead-time occupies ~50% of video, and AsynKV improves streaming while retaining perception—rest on SPOT-Bench's multi-turn proactive queries and Timeliness-F1 being valid proxies for always-on assistant requirements. The abstract supplies no evidence of validation via user studies, deployment logs, or correlation with downstream success metrics (e.g., user satisfaction or safety-critical latency), which is load-bearing for both the diagnostic findings and the claimed superiority of AsynKV.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for acknowledging the potential utility of SPOT-Bench and AsynKV. We address the major comment point by point below.
read point-by-point responses
-
Referee: Abstract: the central claims—that offline models spam predictions, silence training causes unresponsiveness, dead-time occupies ~50% of video, and AsynKV improves streaming while retaining perception—rest on SPOT-Bench's multi-turn proactive queries and Timeliness-F1 being valid proxies for always-on assistant requirements. The abstract supplies no evidence of validation via user studies, deployment logs, or correlation with downstream success metrics (e.g., user satisfaction or safety-critical latency), which is load-bearing for both the diagnostic findings and the claimed superiority of AsynKV.
Authors: We acknowledge that the manuscript does not include direct empirical validation such as user studies, deployment logs, or correlations with downstream metrics like user satisfaction. The SPOT-Bench design and Timeliness-F1 metric are motivated by the logical requirements of always-on streaming assistants—specifically, the need for proactive, timely responses to unfolding events without retrospective pauses or explicit per-step prompts. The multi-turn proactive queries simulate continuous interaction, while Timeliness-F1 penalizes both spamming (false positives) and unresponsiveness (misses) with temporal awareness, directly addressing streaming challenges not captured by retrospective benchmarks. The reported observations (spamming by offline models, unresponsiveness after silence training, ~50% dead-time) and AsynKV's improvements are presented as results obtained under this new protocol, with AsynKV also preserving or improving performance on standard retrospective tasks. We agree this leaves open the question of real-world correlation and view it as a limitation rather than invalidating the benchmark's diagnostic value. We will make a partial revision by clarifying these motivations and limitations in the abstract and adding a brief discussion in the conclusion on the need for future user studies. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces SPOT-Bench and Timeliness-F1 as a new benchmark and metric to address gaps in retrospective VideoQA protocols, with empirical observations on model behaviors (spamming, unresponsiveness, dead-time) motivating the training-free AsynKV adaptation. No equations, fitted parameters renamed as predictions, or self-citation chains reduce the central claims to inputs by construction. The benchmark definition, metric, and method are presented as independent contributions evaluated on both new and retrospective benchmarks, making the derivation self-contained.
Axiom & Free-Parameter Ledger
invented entities (1)
-
dead-time
no independent evidence
Reference graph
Works this paper leans on
-
[1]
https://openai.com/index/introducing-gpt-5/,
Introducing GPT-5 — openai.com. https://openai.com/index/introducing-gpt-5/,
-
[2]
https: //www.meta.com/en-gb/emerging-tech/orion/?srsltid=AfmBOorhkbv2mqgPPW5n7LkVP iEdYDNKz3o6Av9SgEp11JsSTNC4Z2Eq, 2025
Orion AI glasses: The future of AR glasses technology — Meta — meta.com. https: //www.meta.com/en-gb/emerging-tech/orion/?srsltid=AfmBOorhkbv2mqgPPW5n7LkVP iEdYDNKz3o6Av9SgEp11JsSTNC4Z2Eq, 2025. 1
2025
-
[3]
https://www.projectaria
Aria Gen 2, from Meta — Project Aria — projectaria.com. https://www.projectaria. com/, 2025. 1
2025
-
[4]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anad- kat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 4
work page internal anchor Pith review arXiv 2023
-
[5]
Ht-step: Aligning instructional articles with how-to videos.Ad- vances in Neural Information Processing Systems, 36:50310–50326, 2023
Triantafyllos Afouras, Effrosyni Mavroudi, Tushar Nagarajan, Huiyu Wang, and Lorenzo Torresani. Ht-step: Aligning instructional articles with how-to videos.Ad- vances in Neural Information Processing Systems, 36:50310–50326, 2023. 15
2023
-
[6]
Hierarq: Task-aware hier- archical q-former for enhanced video understanding
Shehreen Azad, Vibhav Vineet, and Yogesh Singh Rawat. Hierarq: Task-aware hier- archical q-former for enhanced video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8545–8556, 2025. 4
2025
-
[7]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631, 2025. 3, 5, 10, 11
work page internal anchor Pith review arXiv 2025
-
[8]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 3, 4, 5, 9, 10, 11, 12, 13
work page internal anchor Pith review arXiv 2025
-
[9]
Towards effective human-in-the-loop assistive ai agents
Filippos Bellos, Yayuan Li, Cary Shu, Ruey Day, Jeffrey Siskind, and Jason Corso. Towards effective human-in-the-loop assistive ai agents. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2513–2522, 2025. 1
2025
-
[10]
Aircraft accident report: Northwest airlines, inc., mcdonnell douglas dc-9–82, n312rc, detroit metropolitan wayne county airport, august 16, 1987, 1988
National Transportation Safety Board. Aircraft accident report: Northwest airlines, inc., mcdonnell douglas dc-9–82, n312rc, detroit metropolitan wayne county airport, august 16, 1987, 1988. 1 19 SPOT-Bench Technical Report
1987
-
[11]
Streaming videollms for real-time procedural video understanding
Dibyadip Chatterjee, Edoardo Remelli, Yale Song, Bugra Tekin, Abhay Mittal, Bharat Bhatnagar, Necati Cihan Camgoz, Shreyas Hampali, Eric Sauser, Shugao Ma, et al. Streaming videollms for real-time procedural video understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22586–22598, 2025. 2, 4
2025
-
[12]
Videollm-online: Online video large language model for streaming video
Joya Chen, Zhaoyang Lv, Shiwei Wu, Kevin Qinghong Lin, Chenan Song, Difei Gao, Jia-Wei Liu, Ziteng Gao, Dongxing Mao, and Mike Zheng Shou. Videollm-online: Online video large language model for streaming video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18407–18418, 2024. 2, 4, 7
2024
-
[13]
Livecc: Learning video llm with streaming speech transcription at scale
Joya Chen, Ziyun Zeng, Yiqi Lin, Wei Li, Zejun Ma, and Mike Zheng Shou. Livecc: Learning video llm with streaming speech transcription at scale. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29083–29095, 2025. 9
2025
-
[14]
arXiv preprint arXiv:2504.13180 , year=
Jang Hyun Cho, Andrea Madotto, Effrosyni Mavroudi, Triantafyllos Afouras, Tushar Nagarajan, Muhammad Maaz, Yale Song, Tengyu Ma, Shuming Hu, Suyog Jain, et al. Perceptionlm: Open-access data and models for detailed visual understanding.arXiv preprint arXiv:2504.13180, 2025. 3, 4, 10, 11
-
[15]
Arc- agi-2: A new challenge for frontier ai reasoning systems
Francois Chollet, Mike Knoop, Gregory Kamradt, Bryan Landers, and Henry Pinkard. Arc-agi-2: A new challenge for frontier ai reasoning systems.arXiv preprint arXiv:2505.11831, 2025. 15
-
[16]
Scaling egocentric vision: The epic-kitchens dataset
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, et al. Scaling egocentric vision: The epic-kitchens dataset. InProceedings of the European conference on computer vision (ECCV), pages 720–736, 2018. 3
2018
-
[17]
Online action detection
Roeland De Geest, Efstratios Gavves, Amir Ghodrati, Zhenyang Li, Cees Snoek, and Tinne Tuytelaars. Online action detection. InEuropean Conference on Computer Vision, pages 269–284. Springer, 2016. 3, 6, 8
2016
-
[18]
Shangzhe Di, Zhelun Yu, Guanghao Zhang, Haoyuan Li, Tao Zhong, Hao Cheng, Bolin Li, Wanggui He, Fangxun Shu, and Hao Jiang. Streaming video question-answering with in-context video kv-cache retrieval.arXiv preprint arXiv:2503.00540, 2025. 4, 9, 12
-
[19]
The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024. 4, 15
2024
-
[20]
Video-R1: Reinforcing Video Reasoning in MLLMs
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in mllms.arXiv preprint arXiv:2503.21776, 2025. 4
work page internal anchor Pith review arXiv 2025
-
[21]
Video-mme: The first- ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first- ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108–24118, 2025. 1
2025
-
[22]
Vispeak: Visual instruction feedback in streaming videos.CoRR, abs/2503.12769, 2025
Shenghao Fu, Qize Yang, Yuan-Ming Li, Yi-Xing Peng, Kun-Yu Lin, Xihan Wei, Jian- Fang Hu, Xiaohua Xie, and Wei-Shi Zheng. Vispeak: Visual instruction feedback in streaming videos.arXiv preprint arXiv:2503.12769, 2025. 9
-
[23]
Anticipative video transformer
Rohit Girdhar and Kristen Grauman. Anticipative video transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 13505–13515, 2021. 3
2021
-
[24]
Future transformer for long-term action anticipation
Dayoung Gong, Joonseok Lee, Manjin Kim, Seong Jong Ha, and Minsu Cho. Future transformer for long-term action anticipation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3052–3061, 2022. 3
2022
-
[25]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18995–19012, 2022. 6, 15 20 SPOT-Bench Technical Report
2022
-
[26]
Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 193...
2024
-
[27]
Ma-lmm: Memory-augmented large multimodal model for long-term video understanding
Bo He, Hengduo Li, Young Kyun Jang, Menglin Jia, Xuefei Cao, Ashish Shah, Abhinav Shrivastava, and Ser-Nam Lim. Ma-lmm: Memory-augmented large multimodal model for long-term video understanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13504–13514, 2024. 4
2024
-
[28]
Movienet: A holistic dataset for movie understanding
Qingqiu Huang, Yu Xiong, Anyi Rao, Jiaze Wang, and Dahua Lin. Movienet: A holistic dataset for movie understanding. InEuropean conference on computer vision, pages 709–727. Springer, 2020. 15
2020
-
[29]
Vinci: A real-time smart assistant based on egocentric vision-language model for portable devices.Proc
Yifei Huang, Jilan Xu, Baoqi Pei, Lijin Yang, Mingfang Zhang, Yuping He, Guo Chen, Xinyuan Chen, Yaohui Wang, Zheng Nie, Jinyao Liu, Dechen Lin, Fang Fang, Kunpeng Li, Chang Yuan, Yu Qiao, Yali Wang, and Limin Wang. Vinci: A real-time smart assistant based on egocentric vision-language model for portable devices.Proc. ACM Interact. Mob. Wearable Ubiquitou...
2025
-
[30]
Online video understanding: Ovbench and videochat-online
Zhenpeng Huang, Xinhao Li, Jiaqi Li, Jing Wang, Xiangyu Zeng, Cheng Liang, Tao Wu, Xi Chen, Liang Li, and Limin Wang. Online video understanding: Ovbench and videochat-online. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3328–3338, 2025. 2, 3, 7
2025
-
[31]
Vid2coach: Transforming how-to videos into task assistants
Mina Huh, Zihui Xue, Ujjaini Das, Kumar Ashutosh, Kristen Grauman, and Amy Pavel. Vid2coach: Transforming how-to videos into task assistants. InProceedings of the 38th Annual ACM Symposium on User Interface Software and T echnology, pages 1–24, 2025. 1
2025
-
[32]
Open- ended hierarchical streaming video understanding with vision language models
Hyolim Kang, Yunsu Park, Youngbeom Yoo, Yeeun Choi, and Seon Joo Kim. Open- ended hierarchical streaming video understanding with vision language models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 20715– 20725, 2025. 3
2025
-
[33]
Human action anticipation: A survey.arXiv preprint arXiv:2410.14045, 2024
Bolin Lai, Sam Toyer, Tushar Nagarajan, Rohit Girdhar, Shengxin Zha, James M Rehg, Kris Kitani, Kristen Grauman, Ruta Desai, and Miao Liu. Human action anticipation: A survey.arXiv preprint arXiv:2410.14045, 2024. 3
-
[34]
A hierarchical representation for future action prediction
Tian Lan, Tsung-Chuan Chen, and Silvio Savarese. A hierarchical representation for future action prediction. InEuropean conference on computer vision, pages 689–704. Springer, 2014. 3
2014
-
[35]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 1, 4
work page internal anchor Pith review arXiv 2024
-
[36]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models.arXiv preprint arXiv:2407.07895, 2024. 4
work page internal anchor Pith review arXiv 2024
-
[37]
Junming Lin, Zheng Fang, Chi Chen, Zihao Wan, Fuwen Luo, Peng Li, Yang Liu, and Maosong Sun. Streamingbench: Assessing the gap for mllms to achieve streaming video understanding.arXiv preprint arXiv:2411.03628, 2024. 2, 3, 4, 5, 7, 10, 13, 15
-
[38]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024. 4
2024
-
[39]
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video- chatgpt: Towards detailed video understanding via large vision and language models. arXiv preprint arXiv:2306.05424, 2023. 1, 4 21 SPOT-Bench Technical Report
work page internal anchor Pith review arXiv 2023
-
[40]
Egoschema: A diagnostic benchmark for very long-form video language understanding.Advances in Neural Information Processing Systems, 36:46212–46244, 2023
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long-form video language understanding.Advances in Neural Information Processing Systems, 36:46212–46244, 2023. 1
2023
-
[41]
LiveVLM: Efficient Online Video Understanding via Streaming-Oriented KV Cache and Retrieval
Zhenyu Ning, Guangda Liu, Qihao Jin, Wenchao Ding, Minyi Guo, and Jieru Zhao. Livevlm: Efficient online video understanding via streaming-oriented kv cache and retrieval.arXiv preprint arXiv:2505.15269, 2025. 2, 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Ovo-bench: How far is your video-llms from real-world online video understanding? InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18902–18913, 2025
Junbo Niu, Yifei Li, Ziyang Miao, Chunjiang Ge, Yuanhang Zhou, Qihao He, Xiaoyi Dong, Haodong Duan, Shuangrui Ding, Rui Qian, et al. Ovo-bench: How far is your video-llms from real-world online video understanding? InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18902–18913, 2025. 2, 3, 4, 5, 7, 10, 13, 15
2025
-
[43]
Action points: A representation for low-latency online human action recognition.Microsoft Research Cambridge, T ech
Sebastian Nowozin and Jamie Shotton. Action points: A representation for low-latency online human action recognition.Microsoft Research Cambridge, T ech. Rep. MSR-TR-2012- 68, 2012. 8
2012
-
[44]
Introducing swe-bench verified, 2024
OpenAI. Introducing swe-bench verified, 2024. 15
2024
-
[45]
Context-enhanced memory-refined transformer for online action detection
Zhanzhong Pang, Fadime Sener, and Angela Yao. Context-enhanced memory-refined transformer for online action detection. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8700–8710, 2025. 3, 8
2025
-
[46]
Parsing video events with goal inference and intent prediction
Mingtao Pei, Yunde Jia, and Song-Chun Zhu. Parsing video events with goal inference and intent prediction. In2011 international conference on computer vision, pages 487–494. IEEE, 2011. 3
2011
-
[47]
A new era of intelligence with gemini 3.Google
Sundar Pichai, Demis Hassabis, and Koray Kavukcuoglu. A new era of intelligence with gemini 3.Google. URL: https://blog.google/products-and-platforms/products/gemini/gemini-3/,
-
[48]
Streaming long video understanding with large language models.Advances in Neural Information Processing Systems, 37:119336–119360, 2024
Rui Qian, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Shuangrui Ding, Dahua Lin, and Jiaqi Wang. Streaming long video understanding with large language models.Advances in Neural Information Processing Systems, 37:119336–119360, 2024. 3
2024
-
[49]
Dispider: Enabling video llms with active real-time interaction via disentangled perception, decision, and reaction
Rui Qian, Shuangrui Ding, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Dahua Lin, and Jiaqi Wang. Dispider: Enabling video llms with active real-time interaction via disentangled perception, decision, and reaction. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24045–24055, 2025. 2, 4, 9, 13
2025
-
[50]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 4
2021
-
[51]
Temporal aggregate representations for long-range video understanding
Fadime Sener, Dipika Singhania, and Angela Yao. Temporal aggregate representations for long-range video understanding. InEuropean conference on computer vision, pages 154–171. Springer, 2020. 3
2020
-
[52]
Online detection of action start in untrimmed, streaming videos
Zheng Shou, Junting Pan, Jonathan Chan, Kazuyuki Miyazawa, Hassan Mansour, Anthony Vetro, Xavier Giro-i Nieto, and Shih-Fu Chang. Online detection of action start in untrimmed, streaming videos. InProceedings of the European conference on computer vision (ECCV), pages 534–551, 2018. 8
2018
-
[53]
Moviechat: From dense token to sparse memory for long video understanding
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, et al. Moviechat: From dense token to sparse memory for long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18221–18232, 2024. 4, 9
2024
-
[54]
Ego4d goal-step: Toward hierarchical understanding of procedural activities
Yale Song, Eugene Byrne, Tushar Nagarajan, Huiyu Wang, Miguel Martin, and Lorenzo Torresani. Ego4d goal-step: Toward hierarchical understanding of procedural activities. Advances in Neural Information Processing Systems, 36:38863–38886, 2023. 3, 15
2023
-
[55]
Guangzhi Sun, Yudong Yang, Jimin Zhuang, Changli Tang, Yixuan Li, Wei Li, Zejun Ma, and Chao Zhang. video-salmonn-o1: Reasoning-enhanced audio-visual large language model.arXiv preprint arXiv:2502.11775, 2025. 4 22 SPOT-Bench Technical Report
-
[56]
arXiv preprint arXiv:2505.05467 , year=
Haibo Wang, Bo Feng, Zhengfeng Lai, Mingze Xu, Shiyu Li, Weifeng Ge, Afshin Dehghan, Meng Cao, and Ping Huang. Streambridge: Turning your offline video large language model into a proactive streaming assistant.arXiv preprint arXiv:2505.05467,
-
[57]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 4
work page internal anchor Pith review arXiv 2024
-
[58]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025. 3, 10, 11
work page internal anchor Pith review arXiv 2025
-
[59]
Holoassist: an egocentric human interaction dataset for interactive ai assistants in the real world
Xin Wang, Taein Kwon, Mahdi Rad, Bowen Pan, Ishani Chakraborty, Sean Andrist, Dan Bohus, Ashley Feniello, Bugra Tekin, Felipe Vieira Frujeri, et al. Holoassist: an egocentric human interaction dataset for interactive ai assistants in the real world. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 20270– 20281, 2023. 15
2023
-
[60]
Yueqian Wang, Songxiang Liu, Disong Wang, Nuo Xu, Guanglu Wan, Huishuai Zhang, and Dongyan Zhao. Mmduet2: Enhancing proactive interaction of video mllms with multi-turn reinforcement learning.arXiv preprint arXiv:2512.06810, 2025. 3, 4, 9, 10
-
[61]
Yueqian Wang, Xiaojun Meng, Yifan Wang, Huishuai Zhang, and Dongyan Zhao. Proactivevideoqa: A comprehensive benchmark evaluating proactive interactions in video large language models.arXiv preprint arXiv:2507.09313, 2025. 3, 7
-
[62]
Omnimmi: A comprehensive multi-modal interaction benchmark in streaming video contexts
Yuxuan Wang, Yueqian Wang, Bo Chen, Tong Wu, Dongyan Zhao, and Zilong Zheng. Omnimmi: A comprehensive multi-modal interaction benchmark in streaming video contexts. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18925–18935, 2025. 2, 3, 7
2025
-
[63]
Videollm-mod: Efficient video- language streaming with mixture-of-depths vision computation.Advances in Neural Information Processing Systems, 37:109922–109947, 2024
Shiwei Wu, Joya Chen, Kevin Qinghong Lin, Qimeng Wang, Yan Gao, Qianli Xu, Tong Xu, Yao Hu, Enhong Chen, and Mike Zheng Shou. Videollm-mod: Efficient video- language streaming with mixture-of-depths vision computation.Advances in Neural Information Processing Systems, 37:109922–109947, 2024. 4
2024
-
[64]
Junbin Xiao, Nanxin Huang, Hao Qiu, Zhulin Tao, Xun Yang, Richang Hong, Meng Wang, and Angela Yao. Egoblind: Towards egocentric visual assistance for the blind people.arXiv preprint arXiv:2503.08221, 2025. 15
-
[65]
arXiv preprint arXiv:2501.13468 , year=
Haomiao Xiong, Zongxin Yang, Jiazuo Yu, Yunzhi Zhuge, Lu Zhang, Jiawen Zhu, and Huchuan Lu. Streaming video understanding and multi-round interaction with memory-enhanced knowledge.arXiv preprint arXiv:2501.13468, 2025. 7
-
[66]
Long short-term transformer for online action detection.Advances in Neural Information Processing Systems, 34:1086–1099, 2021
Mingze Xu, Yuanjun Xiong, Hao Chen, Xinyu Li, Wei Xia, Zhuowen Tu, and Stefano Soatto. Long short-term transformer for online action detection.Advances in Neural Information Processing Systems, 34:1086–1099, 2021. 3
2021
-
[67]
arXiv preprint arXiv:2510.09608 , year=
Ruyi Xu, Guangxuan Xiao, Yukang Chen, Liuning He, Kelly Peng, Yao Lu, and Song Han. Streamingvlm: Real-time understanding for infinite video streams.arXiv preprint arXiv:2510.09608, 2025. 3, 4, 9, 10, 12, 13
-
[68]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 4
work page internal anchor Pith review arXiv 2025
-
[69]
StreamAgent: Towards Anticipatory Agents for Streaming Video Understanding
Haolin Yang, Feilong Tang, Lingxiao Zhao, Xiang An, Ming Hu, Huifa Li, Xinlin Zhuang, Yifan Lu, Xiaofeng Zhang, Abdalla Swikir, et al. Streamagent: Towards anticipatory agents for streaming video understanding.arXiv preprint arXiv:2508.01875,
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
5, 9, 13 23 SPOT-Bench Technical Report
-
[71]
Yanlai Yang, Zhuokai Zhao, Satya Narayan Shukla, Aashu Singh, Shlok Kumar Mishra, Lizhu Zhang, and Mengye Ren. Streammem: Query-agnostic kv cache memory for streaming video understanding.arXiv preprint arXiv:2508.15717, 2025. 4
-
[72]
Linli Yao, Yicheng Li, Yuancheng Wei, Lei Li, Shuhuai Ren, Yuanxin Liu, Kun Ouyang, Lean Wang, Shicheng Li, Sida Li, et al. Timechat-online: 80% visual tokens are naturally redundant in streaming videos.arXiv preprint arXiv:2504.17343, 2025. 2, 4, 5, 9, 13
-
[73]
Every moment counts: Dense detailed labeling of actions in complex videos
Serena Yeung, Olga Russakovsky, Ning Jin, Mykhaylo Andriluka, Greg Mori, and Li Fei-Fei. Every moment counts: Dense detailed labeling of actions in complex videos. International Journal of Computer Vision, 126(2):375–389, 2018. 15
2018
-
[74]
arXiv preprint arXiv:2509.24871 , year=
Xiangyu Zeng, Kefan Qiu, Qingyu Zhang, Xinhao Li, Jing Wang, Jiaxin Li, Ziang Yan, Kun Tian, Meng Tian, Xinhai Zhao, et al. Streamforest: Efficient online video understanding with persistent event memory.arXiv preprint arXiv:2509.24871, 2025. 5, 13
-
[75]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023. 4
2023
-
[76]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, et al. Videollama 3: Frontier multimodal foundation models for image and video understanding.arXiv preprint arXiv:2501.13106, 2025. 3, 10, 11
work page internal anchor Pith review arXiv 2025
-
[77]
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding.arXiv preprint arXiv:2306.02858, 2023. 4
work page internal anchor Pith review arXiv 2023
-
[78]
Haoji Zhang, Yiqin Wang, Yansong Tang, Yong Liu, Jiashi Feng, Jifeng Dai, and Xiaojie Jin. Flash-vstream: Memory-based real-time understanding for long video streams. arXiv preprint arXiv:2406.08085, 2024. 2
-
[79]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713, 2024. 4
work page internal anchor Pith review arXiv 2024
-
[80]
no". - If it answers the same underlying fact, mark
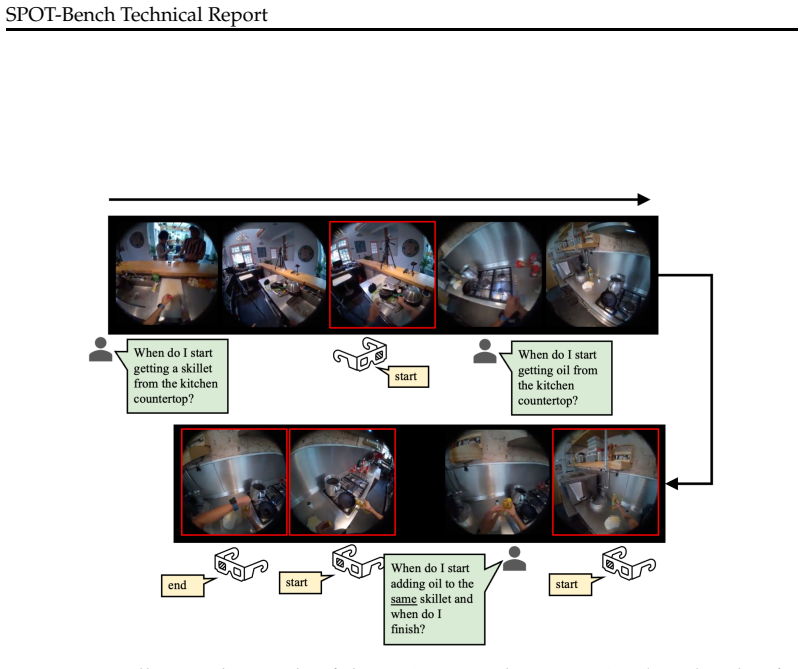
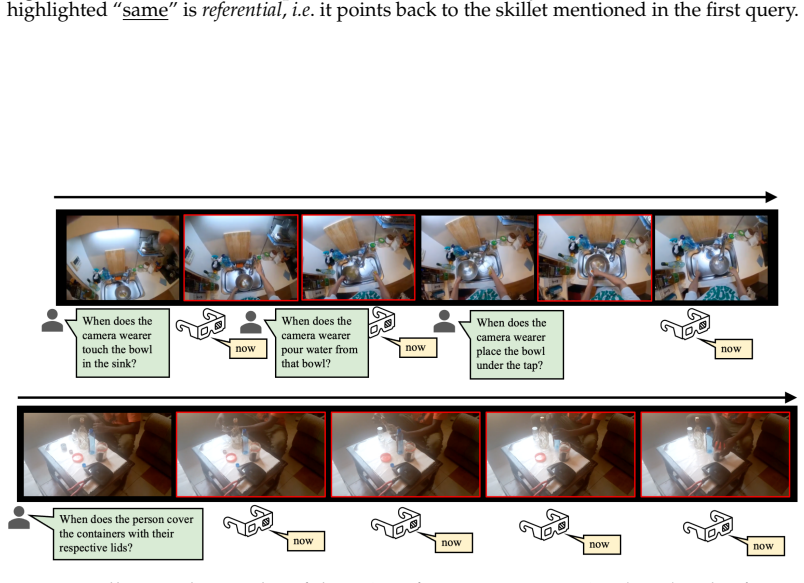
Qing Zhong, Guodong Ding, and Angela Yao. Onlinetas: An online baseline for temporal action segmentation.Advances in Neural Information Processing Systems, 37: 58984–59005, 2024. 6 24 SPOT-Bench Technical Report Figure 9:An illustrated example of the Action Boundary Detection (ABD) task.The highlighted “same” isreferential,i.e. it points back to the skill...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.