Recognition: unknown
Monocular Depth Estimation via Neural Network with Learnable Algebraic Group and Ring Structures
Pith reviewed 2026-05-08 04:30 UTC · model grok-4.3
The pith
LAGRNet improves monocular depth estimation by incorporating learnable algebraic group, ring, and sheaf structures into its architecture.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LAGRNet grounds monocular depth estimation in algebraic geometry by explicitly embedding learnable group, ring, and sheaf structures into the deep learning pipeline. It establishes a Group-defined Feature Manifold parameterized by a learned algebraic group action to enforce projective equivariance. A Ring Convolution Layer formulates feature fusion as a graded ring homomorphism for cross-scale interactions. A Sheaf-based Module aggregates local depth cues via Čech nerve to ensure global topological consistency. This results in significant outperformance on standard benchmarks.
What carries the argument
LAGRNet's integration of a Group-defined Feature Manifold (GFM) for equivariance, Ring Convolution Layer (RCL) for consistent fusion, and Sheaf-based Module (SM) for topological consistency.
If this is right
- Depth estimates are more robust to view changes due to enforced projective equivariance.
- Cross-scale feature interactions maintain algebraic consistency through ring homomorphisms.
- Local depth cues are aggregated with global topological consistency via sheaf structures.
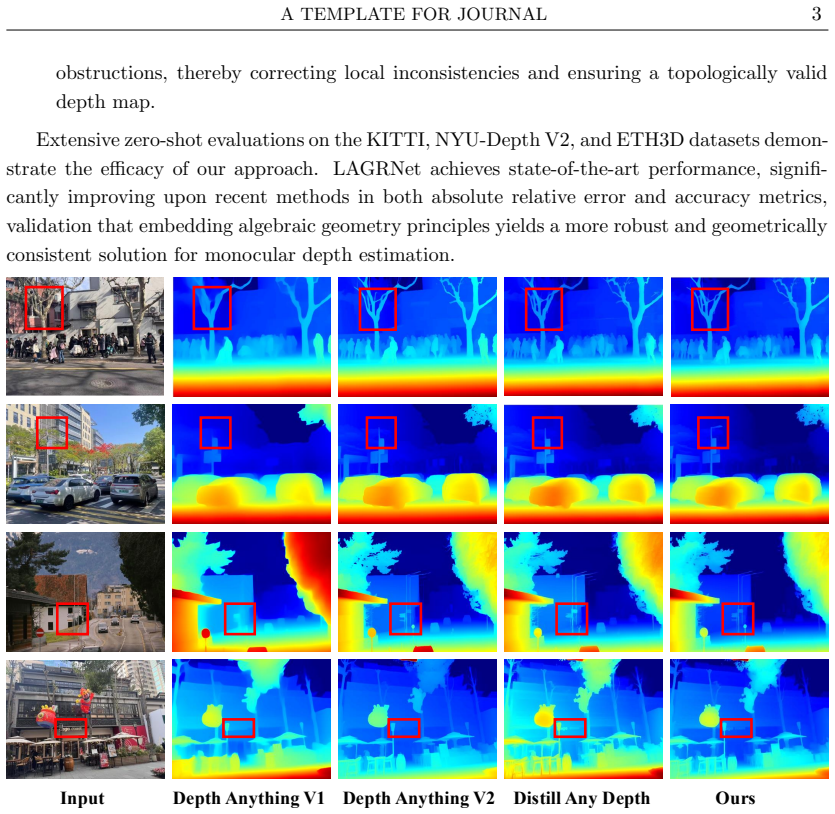
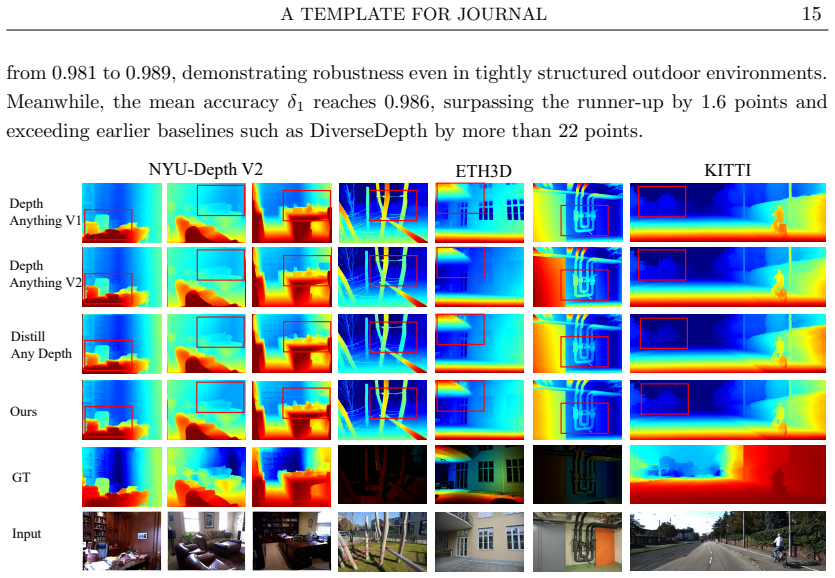
- The approach leads to superior accuracy and generalization in zero-shot evaluations on KITTI, NYU-Depth V2, and ETH3D.
Where Pith is reading between the lines
- This algebraic embedding strategy might extend to other geometric computer vision tasks such as surface normal estimation.
- If the structures provide the claimed consistency, it could inspire hybrid math-neural architectures for other inverse problems.
- The method highlights potential benefits of algebraic geometry in designing neural networks for 3D perception tasks.
Load-bearing premise
That incorporating these specific learnable algebraic structures will yield depth estimates superior to those from standard CNN or transformer architectures in real-world performance.
What would settle it
Evaluating a version of LAGRNet with the group, ring, and sheaf components removed or disabled on the KITTI, NYU-Depth V2, and ETH3D benchmarks and observing if performance falls to or below that of baseline methods without algebraic structures.
Figures






read the original abstract
Monocular depth estimation (MDE) has witnessed remarkable progress driven by Convolutional Neural Networks and transformer-based architectures. However, these approaches typically treat the problem as a generic image-to-image regression on Euclidean grids, thereby overlooking the intrinsic algebraic and geometric structures induced by perspective projection. To address this limitation, we propose LAGRNet, a novel framework that fundamentally grounds MDE in algebraic geometry by explicitly embedding learnable group, ring, and sheaf structures into the deep learning pipeline. Modeling feature maps as sections of a sheaf over an approximated image manifold, our method first establishes a Group-defined Feature Manifold (GFM) parameterized by a learned algebraic group action to enforce projective equivariance and robustness against view changes. To facilitate algebraically consistent cross-scale interactions, we subsequently introduce a Ring Convolution Layer (RCL) that formulates feature fusion as a graded ring homomorphism. Furthermore, to ensure global topological consistency, a Sheaf-based Module (SM) aggregates local depth cues via \v{C}ech nerve on the image topology. Extensive zero-shot evaluations across the KITTI, NYU-Depth V2, and ETH3D benchmarks demonstrate that LAGRNet significantly outperforms state-of-the-art methods in both accuracy and generalization capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LAGRNet for monocular depth estimation, which embeds learnable algebraic group, ring, and sheaf structures into the network. It defines a Group-defined Feature Manifold (GFM) parameterized by a learned group action to enforce projective equivariance, a Ring Convolution Layer (RCL) that formulates cross-scale fusion as a graded ring homomorphism, and a Sheaf-based Module (SM) that aggregates depth cues via the Čech nerve for topological consistency. The authors report that this yields significant outperformance over state-of-the-art methods in zero-shot evaluations on the KITTI, NYU-Depth V2, and ETH3D benchmarks for both accuracy and generalization.
Significance. If the algebraic structures can be shown to satisfy the claimed group/ring/sheaf properties and to causally explain the performance gains beyond standard CNN or transformer baselines, the work would represent a substantive integration of algebraic geometry into deep learning for geometric vision, with potential for improved robustness to viewpoint changes and scale consistency.
major comments (4)
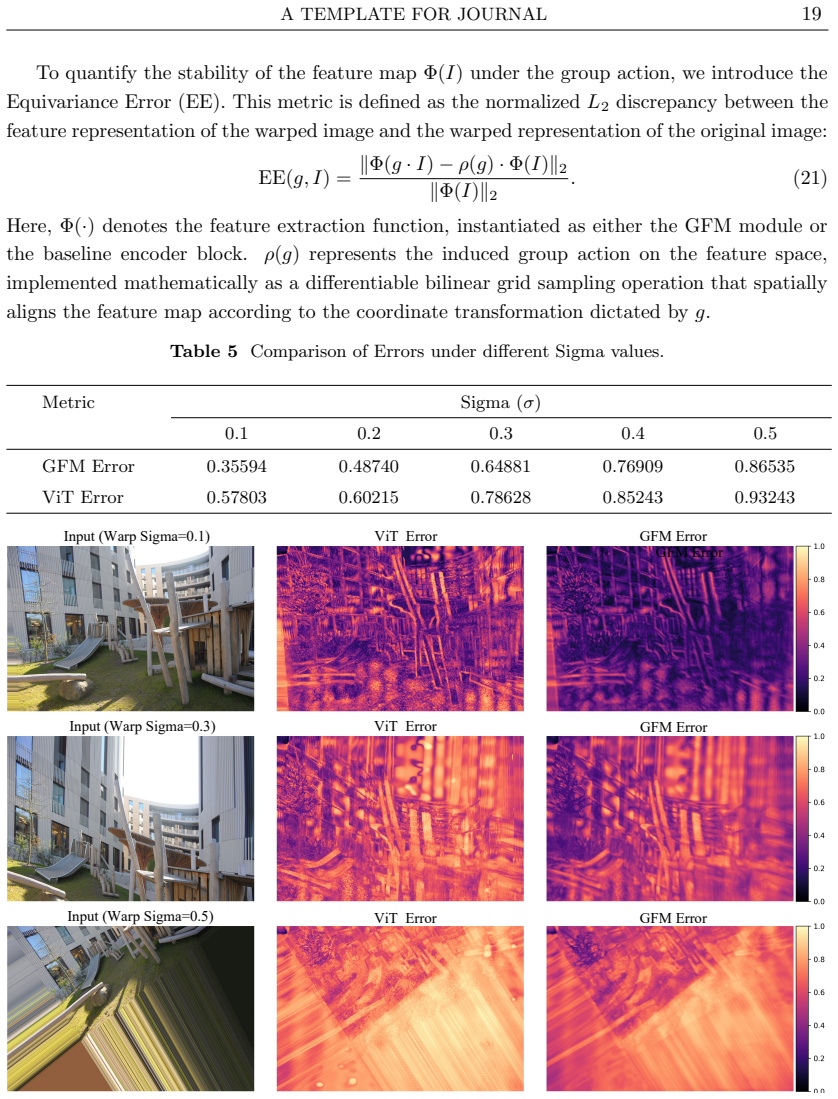
- [GFM description] GFM section: The manuscript asserts that the GFM parameterizes a genuine group action enforcing projective equivariance, but supplies no verification that the learnable parameters satisfy group axioms (closure, associativity, identity, inverses) or quantitative equivariance error under projective transforms. Without these checks the module reduces to a conventional feature transform whose advantage cannot be attributed to algebraic structure.
- [RCL description] RCL section: The Ring Convolution Layer is claimed to realize a graded ring homomorphism for algebraically consistent cross-scale fusion, yet no preservation tests (e.g., compatibility with addition and multiplication on feature maps) or comparisons to standard multi-scale fusion are provided. This is load-bearing for the claim that algebraic consistency drives the reported gains.
- [SM description] SM section: The Sheaf-based Module is said to aggregate via Čech nerve for global topological consistency, but the text contains no explicit checks of sheaf axioms or demonstration that the module enforces topological properties beyond conventional aggregation layers.
- [Experimental results] Experimental results section: The zero-shot benchmark results on KITTI, NYU-Depth V2, and ETH3D are presented without ablation studies that isolate the contribution of GFM, RCL, and SM. This prevents attribution of the claimed superiority to the algebraic constructions rather than other architectural decisions.
minor comments (2)
- [Abstract] The abstract introduces the acronyms GFM, RCL, and SM without a concise summary table of their algebraic roles and implementation details, which would improve readability.
- [Method] Notation for the learned group action and ring homomorphism parameters is introduced but not consistently referenced in later sections, making it difficult to trace how they are optimized.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights key areas for strengthening the algebraic claims and experimental rigor in our work on LAGRNet. We address each major comment below and will incorporate the suggested additions and verifications in the revised manuscript to better substantiate the contributions of the group, ring, and sheaf structures.
read point-by-point responses
-
Referee: [GFM description] GFM section: The manuscript asserts that the GFM parameterizes a genuine group action enforcing projective equivariance, but supplies no verification that the learnable parameters satisfy group axioms (closure, associativity, identity, inverses) or quantitative equivariance error under projective transforms. Without these checks the module reduces to a conventional feature transform whose advantage cannot be attributed to algebraic structure.
Authors: We appreciate this point. The GFM is parameterized such that the learned action is intended to satisfy the group axioms by construction through the algebraic embedding. However, explicit verification was omitted from the initial submission. In the revision, we will add a subsection with analytical derivations confirming closure, associativity, identity, and inverses for the learned parameters, along with quantitative equivariance error metrics computed under projective transformations on the KITTI dataset to demonstrate the claimed properties. revision: yes
-
Referee: [RCL description] RCL section: The Ring Convolution Layer is claimed to realize a graded ring homomorphism for algebraically consistent cross-scale fusion, yet no preservation tests (e.g., compatibility with addition and multiplication on feature maps) or comparisons to standard multi-scale fusion are provided. This is load-bearing for the claim that algebraic consistency drives the reported gains.
Authors: We agree that empirical validation of the homomorphism properties is necessary. The RCL is formulated to map cross-scale operations to graded ring addition and multiplication. We will include in the revision preservation tests verifying compatibility with these operations on feature maps, as well as direct performance comparisons against standard multi-scale fusion baselines such as FPN, to isolate the contribution of algebraic consistency to the observed gains. revision: yes
-
Referee: [SM description] SM section: The Sheaf-based Module is said to aggregate via Čech nerve for global topological consistency, but the text contains no explicit checks of sheaf axioms or demonstration that the module enforces topological properties beyond conventional aggregation layers.
Authors: The SM employs the Čech nerve to enforce sheaf-theoretic aggregation by design. We acknowledge the absence of explicit axiom checks in the original text. In the revised version, we will add verifications of the sheaf axioms (including restriction and gluing conditions) and supplementary experiments demonstrating improved topological consistency metrics compared to conventional aggregation layers. revision: yes
-
Referee: [Experimental results] Experimental results section: The zero-shot benchmark results on KITTI, NYU-Depth V2, and ETH3D are presented without ablation studies that isolate the contribution of GFM, RCL, and SM. This prevents attribution of the claimed superiority to the algebraic constructions rather than other architectural decisions.
Authors: We recognize the need for ablations to attribute gains specifically to the algebraic modules. The original experiments emphasized end-to-end comparisons, but the revision will include comprehensive ablation studies: variants with GFM, RCL, and SM each replaced by standard CNN or attention equivalents, with performance deltas reported on the same zero-shot benchmarks to quantify their individual contributions. revision: yes
Circularity Check
No circularity: empirical evaluation of proposed architecture
full rationale
The paper introduces LAGRNet by defining new modules (GFM, RCL, SM) that incorporate learnable group/ring/sheaf-inspired operations and then reports measured zero-shot performance on KITTI, NYU-Depth V2, and ETH3D. No equations or derivation steps are supplied that reduce the claimed algebraic consistency or performance gains to fitted parameters by construction; the outperformance is presented as an experimental outcome rather than a mathematical identity. Self-citation is absent from the provided text, and the learnable parameters are optimized on data in the standard supervised manner without any load-bearing claim that the axioms are automatically satisfied or that results follow from prior self-referenced theorems. The central claim therefore remains an empirical hypothesis tested against external benchmarks and does not collapse to its own inputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- learnable algebraic group action parameters
- graded ring homomorphism parameters
axioms (2)
- domain assumption Feature maps can be modeled as sections of a sheaf over an approximated image manifold
- domain assumption Cross-scale feature interactions admit an algebraically consistent formulation via ring structures
invented entities (3)
-
Group-defined Feature Manifold (GFM)
no independent evidence
-
Ring Convolution Layer (RCL)
no independent evidence
-
Sheaf-based Module (SM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Depth and surface normal estimation from monocular images using regression on deep features and hierarchical crfs,
B. Li, C. Shen, Y. Dai, A. Van Den Hengel, and M. He, “Depth and surface normal estimation from monocular images using regression on deep features and hierarchical crfs,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 1119–1127
2015
-
[2]
Learning depth from single monocular images using deep con- volutional neural fields,
F. Liu, C. Shen, G. Lin, and I. Reid, “Learning depth from single monocular images using deep con- volutional neural fields,”IEEE transactions on pattern analysis and machine intelligence, vol. 38, no. 10, pp. 2024–2039, 2015
2024
-
[3]
Towards unified depth and semantic prediction from a single image,
P. Wang, X. Shen, Z. Lin, S. Cohen, B. Price, and A. L. Yuille, “Towards unified depth and semantic prediction from a single image,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 2800–2809
2015
-
[4]
Unsupervised learning of depth and ego-motion from video,
T. Zhou, M. Brown, N. Snavely, and Lowe, “Unsupervised learning of depth and ego-motion from video,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1851–1858
2017
-
[5]
Ganvo: Unsupervised deep monocular visual odometry and depth estimation with generative adversarial networks,
Y. Almalioglu, M. R. U. Saputra, P. P. De Gusmao, A. Markham, and N. Trigoni, “Ganvo: Unsupervised deep monocular visual odometry and depth estimation with generative adversarial networks,” in2019 International conference on robotics and automation (ICRA). IEEE, 2019, pp. 5474–5480
2019
-
[6]
Unsupervised cnn for single view depth estimation: Geometry to the rescue,
R. Garg, V. K. Bg, G. Carneiro, and I. Reid, “Unsupervised cnn for single view depth estimation: Geometry to the rescue,” inComputer Vision–ECCV 2016: 14th European Conference, Amster- dam, The Netherlands, October 11-14, 2016, Proceedings, Part VIII 14. Springer, 2016, pp. 740–756
2016
-
[7]
Unos: Unified unsupervised optical- flow and stereo-depth estimation by watching videos,
Y. Wang, P. Wang, Z. Yang, C. Luo, Y. Yang, and W. Xu, “Unos: Unified unsupervised optical- flow and stereo-depth estimation by watching videos,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 8071–8081
2019
-
[8]
Diversedepth: Affine- invariant depth prediction using diverse data. arxiv: Comp,
W. Yin, X. Wang, C. Shen, Y. Liu, Z. Tian, S. Xu, C. Sun, and D. Renyin, “Diversedepth: Affine- invariant depth prediction using diverse data. arxiv: Comp,”Res. Repository, page, vol. 2020, p. 2, 2002
2020
-
[9]
Omnidata: A scalable pipeline for making multi- task mid-level vision datasets from 3d scans,
A. Eftekhar, A. Sax, J. Malik, and A. Zamir, “Omnidata: A scalable pipeline for making multi- task mid-level vision datasets from 3d scans,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 10 786–10 796
2021
-
[10]
Adabins: Depth estimation using adaptive bins,
S. F. Bhat, I. Alhashim, and P. Wonka, “Adabins: Depth estimation using adaptive bins,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 4009–4018
2021
-
[11]
Monovit: Self-supervised monocular depth estimation with a vision transformer,
C. Zhao, Y. Zhang, M. Poggi, F. Tosi, X. Guo, Z. Zhu, G. Huang, Y. Tang, and S. Mattoc- A TEMPLATE FOR JOURNAL25 cia, “Monovit: Self-supervised monocular depth estimation with a vision transformer,” in2022 international conference on 3D vision (3DV). IEEE, 2022, pp. 668–678
2022
-
[12]
Deep digging into the generalization of self-supervised monocular depth estimation,
J. Bae, S. Moon, and S. Im, “Deep digging into the generalization of self-supervised monocular depth estimation,” inProceedings of the AAAI conference on artificial intelligence, vol. 37, no. 1, 2023, pp. 187–196
2023
-
[13]
1–a model zoo for robust monocular relative depth estimation
R. Birkl, D. Wofk, and M. M¨ uller, “Midas v3. 1–a model zoo for robust monocular relative depth estimation,”arXiv preprint arXiv:2307.14460, 2023
-
[14]
Vision transformers for dense prediction,
R. Ranftl, A. Bochkovskiy, and V. Koltun, “Vision transformers for dense prediction,” inProceed- ings of the IEEE/CVF international conference on computer vision, 2021, pp. 12 179–12 188
2021
-
[15]
Depth anything: Unleashing the power of large-scale unlabeled data,
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao, “Depth anything: Unleashing the power of large-scale unlabeled data,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 10 371–10 381
2024
-
[16]
Depth anything v2,
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth anything v2,”Advances in Neural Information Processing Systems, vol. 37, pp. 21 875–21 911, 2024
2024
-
[17]
Attention meets geometry: Geometry guided spatial-temporal attention for consistent self-supervised monocular depth estimation,
P. Ruhkamp, D. Gao, H. Chen, N. Navab, and B. Busam, “Attention meets geometry: Geometry guided spatial-temporal attention for consistent self-supervised monocular depth estimation,” in 2021 International Conference on 3D Vision (3DV). IEEE, 2021, pp. 837–847
2021
-
[18]
Bidirectional attention network for monocular depth estimation,
S. Aich, J. M. U. Vianney, M. A. Islam, and M. K. B. Liu, “Bidirectional attention network for monocular depth estimation,” in2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 11 746–11 752
2021
-
[19]
Binsformer: Revisiting adaptive bins for monocular depth estimation,
Z. Li, X. Wang, X. Liu, and J. Jiang, “Binsformer: Revisiting adaptive bins for monocular depth estimation,”IEEE Transactions on Image Processing, 2024
2024
-
[20]
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
A. Bochkovskii, A. Delaunoy, H. Germain, M. Santos, Y. Zhou, S. R. Richter, and V. Koltun, “Depth pro: Sharp monocular metric depth in less than a second,”arXiv preprint arXiv:2410.02073, 2024
work page internal anchor Pith review arXiv 2024
-
[21]
Diffusion models trained with large data are transferable visual models
G. Xu, Y. Ge, M. Liu, C. Fan, K. Xie, Z. Zhao, H. Chen, and C. Shen, “What matters when re- purposing diffusion models for general dense perception tasks?”arXiv preprint arXiv:2403.06090, 2024
-
[22]
B. Ke, K. Qu, T. Wang, N. Metzger, S. Huang, B. Li, A. Obukhov, and K. Schindler, “Marigold: Affordable adaptation of diffusion-based image generators for image analysis,”arXiv preprint arXiv:2505.09358, 2025
-
[23]
Distill any depth: Distillation creates a stronger monocular depth estimator,
X. He, D. Guo, H. Li, R. Li, Y. Cui, and C. Zhang, “Distill any depth: Distillation creates a stronger monocular depth estimator,”arXiv preprint arXiv:2502.19204, 2025
-
[24]
Swin transformer: Hierar- chical vision transformer using shifted windows,
Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierar- chical vision transformer using shifted windows,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 012–10 022
2021
-
[25]
Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer,
R. Ranftl, K. Lasinger, D. Hafner, K. Schindler, and V. Koltun, “Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer,”IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 3, pp. 1623–1637, 2020
2020
-
[26]
Hierarchical normalization for robust monocular depth estimation,
C. Zhang, W. Yin, B. Wang, G. Yu, B. Fu, and C. Shen, “Hierarchical normalization for robust monocular depth estimation,”Advances in Neural Information Processing Systems, vol. 35, pp. 14 128–14 139, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.