Recognition: unknown
Reducing Redundancy in Retrieval-Augmented Generation through Chunk Filtering
Pith reviewed 2026-05-08 03:52 UTC · model grok-4.3
The pith
Named-entity filtering reduces RAG vector index size by 25 to 36 percent while keeping retrieval quality close to baseline levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
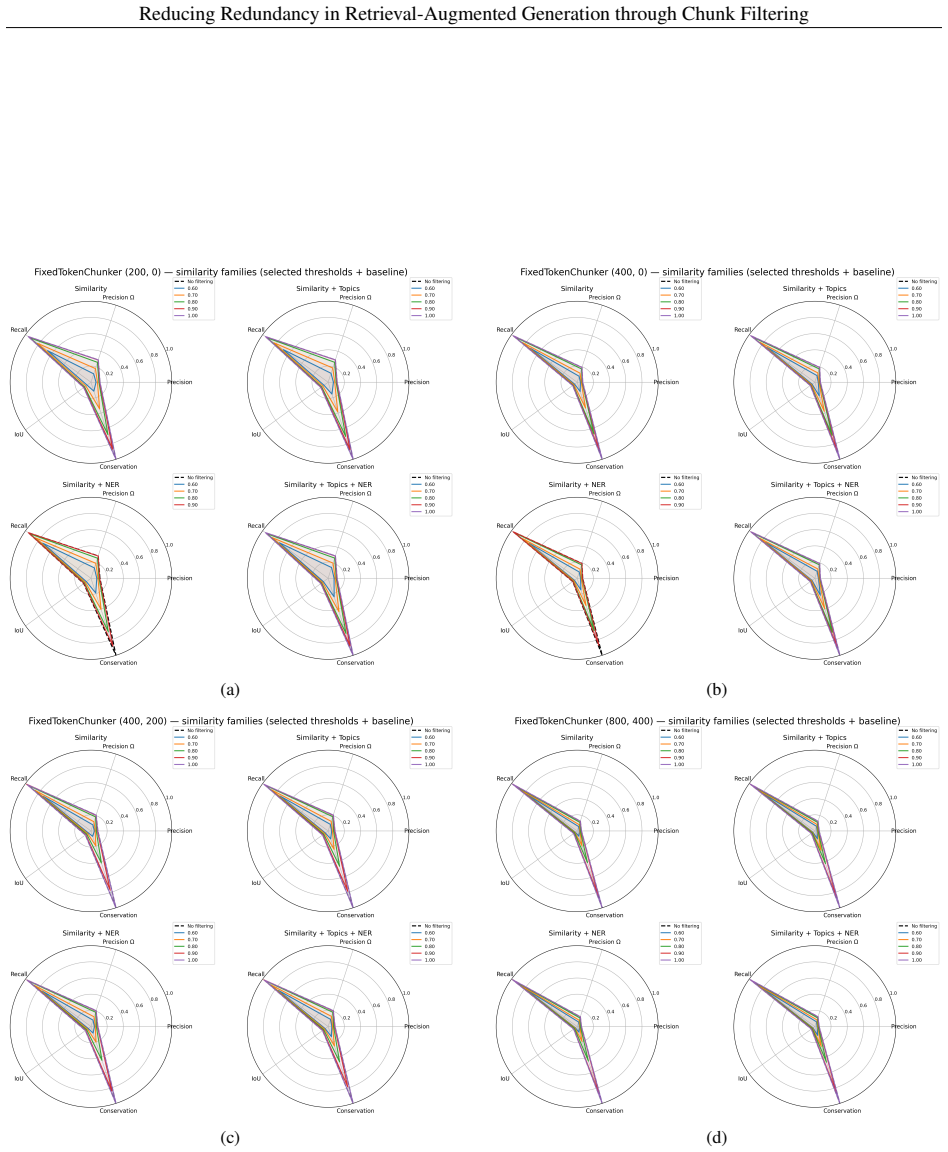
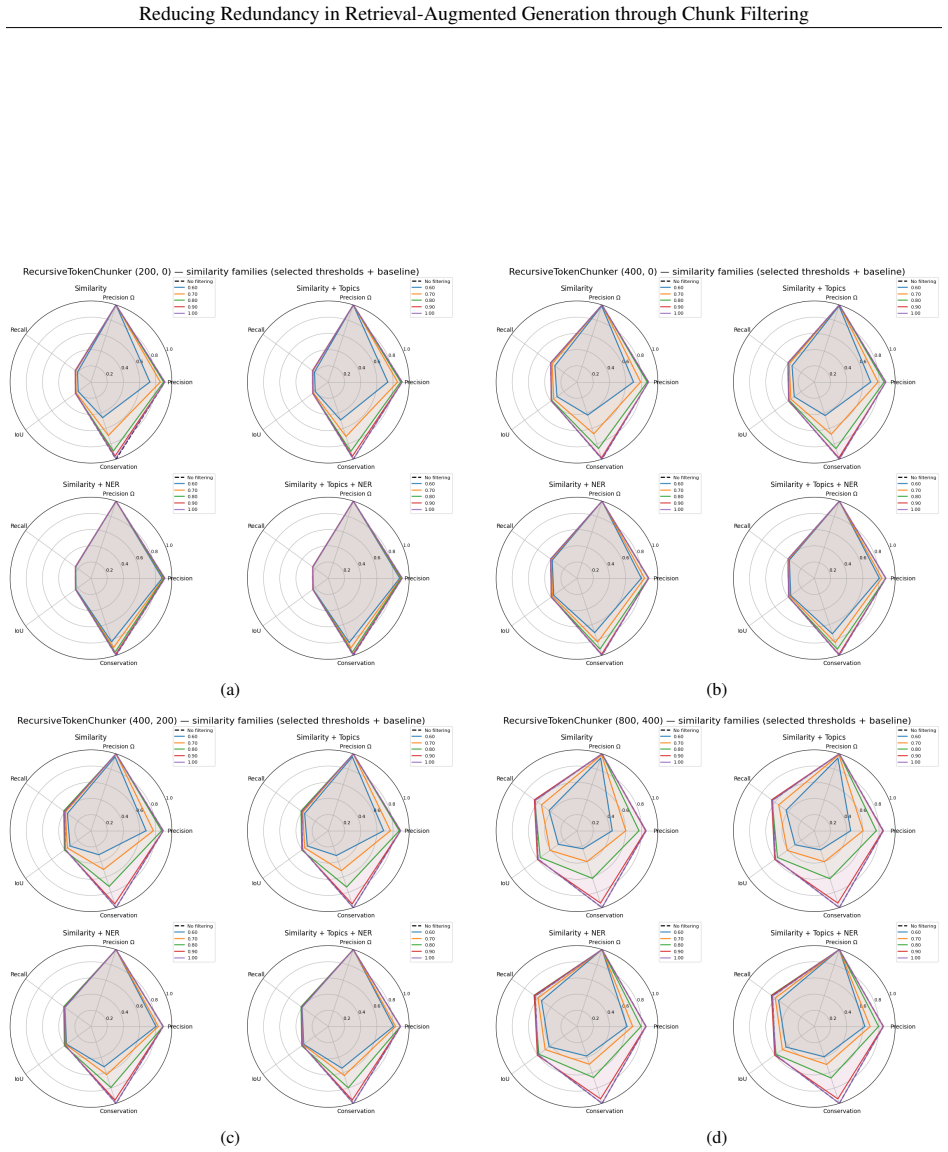
Standard RAG chunking methods create excessive redundancy that increases storage costs and slows retrieval. By applying named-entity-based filtering to remove overlapping chunks, the size of the vector index can be reduced by approximately 25% to 36% while retrieval performance, measured by token-based precision, recall, and intersection-over-union metrics, remains close to the unfiltered baseline. Experiments conducted on multiple corpora confirm that this lightweight filtering preserves high retrieval quality, indicating that redundancy introduced during chunking can be effectively reduced through targeted post-processing.
What carries the argument
Named-entity-based chunk filtering, which removes redundant chunks by identifying overlaps through distinct named entities while preserving retrieval coverage.
If this is right
- The vector index requires less storage space.
- Retrieval operations complete more quickly due to the smaller index.
- Retrieval quality measured by the token metrics stays high enough to support RAG answer generation.
- Such filtering can be implemented as a lightweight post-processing step after standard chunking.
- Efficiency gains apply directly to retrieval-oriented components in RAG pipelines.
Where Pith is reading between the lines
- Combining entity-based filtering with semantic deduplication could produce even larger index reductions.
- This approach might help RAG systems scale to much larger document collections without proportional infrastructure costs.
- End-to-end testing on generated answers would strengthen evidence that the observed metric stability translates to better practical performance.
Load-bearing premise
Token-based precision, recall, and intersection-over-union metrics sufficiently capture the retrieval quality required for effective downstream answer generation in RAG pipelines.
What would settle it
A direct end-to-end test comparing answer accuracy on a question-answering benchmark when the RAG generator uses the filtered index versus the full unfiltered index.
Figures



















read the original abstract
Standard Retrieval-Augmented Generation (RAG) chunking methods often create excessive redundancy, increasing storage costs and slowing retrieval. This study explores chunk filtering strategies, such as semantic, topic-based, and named-entity-based methods in order to reduce the indexed corpus while preserving retrieval quality. Experiments are conducted on multiple corpora. Retrieval performance is evaluated using a token-based framework based on precision, recall, and intersection-over-union metrics. Results indicate that entity-based filtering can reduce vector index size by approximately 25% to 36% while maintaining high retrieval quality close to the baseline. These findings suggest that redundancy introduced during chunking can be effectively reduced through lightweight filtering, improving the efficiency of retrieval-oriented components in RAG pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript explores chunk filtering strategies (semantic, topic-based, and named-entity-based) to reduce redundancy created by standard RAG chunking methods. It claims that entity-based filtering reduces vector index size by 25-36% across multiple corpora while preserving retrieval quality close to the unfiltered baseline, with quality assessed exclusively via token-based precision, recall, and intersection-over-union metrics.
Significance. If the central empirical result holds under more rigorous validation, the work would provide a practical, lightweight method for lowering storage and retrieval costs in RAG pipelines without substantial quality loss. The reported concrete size reductions and multi-corpus experiments constitute a modest but useful contribution to efficiency-oriented retrieval research.
major comments (1)
- [Results / Evaluation] The evaluation framework (described in the results section) measures retrieval quality solely through token-overlap precision, recall, and IoU against the original chunks. These surface metrics do not test whether the retained chunks enable the downstream generator to produce answers of equivalent factual accuracy or completeness, which is the relevant quality criterion for RAG pipelines. This gap directly limits support for the claim that retrieval quality remains 'close to the baseline' in practical RAG use.
minor comments (2)
- [Abstract] The abstract states that experiments were conducted on 'multiple corpora' and reports approximate size reductions, but supplies no details on corpus identities, exact filtering implementations, baseline definitions, or statistical significance tests. Adding these specifics would improve reproducibility.
- [Experimental Setup] The manuscript would benefit from an explicit comparison of the proposed filters against simpler baselines (e.g., random chunk removal at the same reduction rate) to isolate the benefit of entity-based selection.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address the major comment on the evaluation framework below.
read point-by-point responses
-
Referee: [Results / Evaluation] The evaluation framework (described in the results section) measures retrieval quality solely through token-overlap precision, recall, and IoU against the original chunks. These surface metrics do not test whether the retained chunks enable the downstream generator to produce answers of equivalent factual accuracy or completeness, which is the relevant quality criterion for RAG pipelines. This gap directly limits support for the claim that retrieval quality remains 'close to the baseline' in practical RAG use.
Authors: We appreciate this observation and agree that token-overlap metrics provide only an indirect proxy for retrieval quality in RAG systems. Our evaluation was designed to measure information preservation at the chunk level by quantifying overlap with the original unfiltered corpus, which directly addresses the paper's focus on reducing redundancy introduced by standard chunking. However, we acknowledge that this does not fully capture end-to-end effects on generated answer accuracy or completeness. In the revised manuscript, we will add experiments that evaluate the filtered indices within a complete RAG pipeline using standard QA benchmarks to measure factual correctness and completeness of generated responses. revision: yes
Circularity Check
No circularity: empirical measurements of index size and token-overlap metrics
full rationale
The paper presents an empirical study of chunk filtering methods (semantic, topic-based, entity-based) applied to RAG corpora. It directly measures vector index size reduction and evaluates retrieval quality via token-based precision, recall, and IoU against baseline chunks. No equations, fitted parameters, self-referential definitions, or load-bearing self-citations appear in the derivation chain; results are reported from explicit experiments on multiple corpora without any reduction of outputs to inputs by construction. The central claim rests on observable measurements rather than any closed logical loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Token-based precision, recall, and IoU metrics are adequate proxies for retrieval quality in RAG systems.
Reference graph
Works this paper leans on
-
[1]
https : / / www
Anthropic.Introducing Contextual Retrieval. https : / / www . anthropic . com / news / contextual - retrieval. Accessed: 2025. 2024
2025
-
[2]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
Akari Asai et al. “Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection”. In:The Twelfth International Conference on Learning Representations. 2024.URL: https : / / openreview . net / forum?id=hSyW5go0v8
2024
-
[3]
Latent dirichlet allocation
David M. Blei, Andrew Y . Ng, and Michael I. Jordan. “Latent dirichlet allocation”. In:J. Mach. Learn. Res. 3.null (Mar. 2003), pp. 993–1022.ISSN: 1532-4435
2003
-
[4]
Improving language models by retrieving from trillions of tokens.Preprint arXiv:2112.04426,
Sebastian Borgeaud et al. “Improving language models by retrieving from trillions of tokens”. In:CoRR abs/2112.04426 (2021). arXiv:2112.04426.URL:https://arxiv.org/abs/2112.04426
-
[5]
On the resemblance and containment of documents
Andrei Z. Broder. “On the resemblance and containment of documents”. In:Compression and Complexity of Sequences. 1997
1997
-
[6]
Identifying and filtering near-duplicate documents
Andrei Z. Broder et al. “Identifying and filtering near-duplicate documents”. In:Combinatorial Pattern Matching. 2000
2000
-
[7]
Jianlv Chen et al.M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. arXiv:2402.03216 [cs]. Dec. 2025.DOI: 10.48550/arXiv.2402.03216. URL:http://arxiv.org/abs/2402.03216(visited on 12/18/2025)
work page internal anchor Pith review doi:10.48550/arxiv.2402.03216 2025
-
[8]
Finqa: A dataset of numerical reasoning over financial data
Zhiyu Chen et al.ConvFinQA: Exploring the Chain of Numerical Reasoning in Conversational Finance Question Answering. arXiv:2210.03849 [cs]. Oct. 2022.DOI: 10.48550/arXiv.2210.03849 .URL: http://arxiv. org/abs/2210.03849(visited on 12/17/2025)
-
[9]
original-date: 2022-10-05T17:58:44Z
chroma-core/chroma. original-date: 2022-10-05T17:58:44Z. Dec. 2025.URL: https://github.com/chroma- core/chroma(visited on 12/18/2025)
2022
-
[10]
Enhancing chat language models by scaling high-quality instructional conversations
Ning Ding et al.Enhancing Chat Language Models by Scaling High-quality Instructional Conversations. arXiv:2305.14233 [cs]. May 2023.DOI: 10.48550/arXiv.2305.14233 .URL: http://arxiv.org/abs/ 2305.14233(visited on 12/17/2025)
-
[11]
Michael Dinzinger et al.WebFAQ: A Multilingual Collection of Natural Q&A Datasets for Dense Retrieval. arXiv:2502.20936 [cs]. Feb. 2025.DOI: 10.48550/arXiv.2502.20936 .URL: http://arxiv.org/abs/ 2502.20936(visited on 12/17/2025)
-
[12]
Precise Zero-Shot Dense Retrieval without Relevance Labels
Luyu Gao et al. “Precise Zero-Shot Dense Retrieval without Relevance Labels”. In:Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Ed. by Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki. Toronto, Canada: Association for Computational Linguistics, July 2023, pp. 1762–1777.DOI: 10.18653/v1/2...
-
[13]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao et al.Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv:2312.10997 [cs]. Mar. 2024.DOI: 10.48550/arXiv.2312.10997.URL: http://arxiv.org/abs/2312.10997 (visited on 12/16/2025)
work page Pith review doi:10.48550/arxiv.2312.10997.url: 2024
-
[14]
BERTopic: Neural topic modeling with a class-based TF-IDF procedure
Maarten Grootendorst.BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv:2203.05794 [cs]. Mar. 2022.DOI: 10 . 48550 / arXiv . 2203 . 05794.URL: http : / / arxiv . org / abs/2203.05794(visited on 12/16/2025)
work page internal anchor Pith review arXiv 2022
-
[15]
doi:10.48550/arXiv.2002.08909 , abstract =
Kelvin Guu et al. “REALM: Retrieval-Augmented Language Model Pre-Training”. In:CoRRabs/2002.08909 (2020). arXiv:2002.08909.URL:https://arxiv.org/abs/2002.08909
-
[16]
Michael Günther et al.Late Chunking: Contextual Chunk Embeddings Using Long-Context Embedding Models
- [17]
-
[18]
Stephen E Toulmin.The uses of argument
Matthew Honnibal et al. “spaCy: Industrial-strength Natural Language Processing in Python”. In: (2020).DOI: 10.5281/zenodo.1212303
-
[19]
Leveraging passage retrieval with generative models for open domain question answering
Gautier Izacard and Edouard Grave. “Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering”. In:Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. Ed. by Paola Merlo, Jorg Tiedemann, and Reut Tsarfaty. Online: Association for Computational Linguistics, A...
-
[20]
arXiv preprint arXiv:2004.04906 , year=
Vladimir Karpukhin et al.Dense Passage Retrieval for Open-Domain Question Answering. arXiv:2004.04906 [cs]. Sept. 2020.DOI: 10.48550/arXiv.2004.04906.URL: http://arxiv.org/abs/2004.04906 (visited on 12/16/2025)
-
[21]
Deduplicating Training Data Makes Language Models Better
Katherine Lee et al. “Deduplicating Training Data Makes Language Models Better”. In:Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Ed. by Smaranda Muresan, Preslav Nakov, and Aline Villavicencio. Dublin, Ireland: Association for Computational Linguistics, May 2022, pp. 8424–8445.DOI: 10.186...
-
[22]
Ullman.Mining of Massive Datasets
Jure Leskovec, Anand Rajaraman, and Jeffrey D. Ullman.Mining of Massive Datasets. 3rd ed. 2020
2020
-
[23]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis et al.Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv:2005.11401 [cs]. Apr. 2021.DOI: 10.48550/arXiv.2005.11401.URL: http://arxiv.org/abs/2005.11401 (visited on 12/15/2025)
work page internal anchor Pith review doi:10.48550/arxiv.2005.11401.url: 2005
-
[24]
Pointer Sentinel Mixture Models
Stephen Merity et al.Pointer Sentinel Mixture Models. arXiv:1609.07843 [cs]. Sept. 2016.DOI: 10.48550/ arXiv.1609.07843.URL:http://arxiv.org/abs/1609.07843(visited on 12/17/2025)
work page internal anchor Pith review arXiv 2016
-
[25]
arXiv preprint arXiv:2202.12837 , year=
Sewon Min et al. “Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?” In:ArXiv abs/2202.12837 (2022).URL:https://api.semanticscholar.org/CorpusID:247155069
-
[26]
pmc/open_access · Datasets at Hugging Face. Aug. 2023.URL: https://huggingface.co/datasets/pmc/ open_access(visited on 12/17/2025)
2023
-
[27]
June 2021.URL: https : / / huggingface
rajpurkar/squad · Datasets at Hugging Face. June 2021.URL: https : / / huggingface . co / datasets / rajpurkar/squad(visited on 12/17/2025)
2021
-
[28]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych.Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv:1908.10084 [cs]. Aug. 2019.DOI: 10.48550/arXiv.1908.10084 .URL: http://arxiv.org/abs/ 1908.10084(visited on 12/16/2025)
work page internal anchor Pith review doi:10.48550/arxiv.1908.10084 1908
-
[29]
Nikolaus Salvatore, Hao Wang, and Qiong Zhang.Lost in the Middle: An Emergent Property from Information Retrieval Demands in LLMs. arXiv:2510.10276 [cs]. Oct. 2025.DOI: 10.48550/arXiv.2510.10276 .URL: http://arxiv.org/abs/2510.10276(visited on 12/16/2025)
- [30]
-
[31]
en-US.URL: https://bidenwhitehouse.archives.gov/state-of-the-union- 2024/(visited on 12/17/2025)
State of the Union 2024. en-US.URL: https://bidenwhitehouse.archives.gov/state-of-the-union- 2024/(visited on 12/17/2025)
2024
-
[32]
Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval
Lee Xiong et al. “Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval”. In: International Conference on Learning Representations. 2021.URL: https://openreview.net/forum?id= zeFrfgyZln
2021
-
[33]
Yue Yu et al.RankRAG: Unifying Context Ranking with Retrieval-Augmented Generation in LLMs. 2024. arXiv: 2407.02485 [cs.CL].URL:https://arxiv.org/abs/2407.02485. 17 Reducing Redundancy in Retrieval-Augmented Generation through Chunk Filtering Complete Experimental Figures (a) (b) (c) (d) Figure 4: RecursiveTokenChunker and similarity-based filtres for Chr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.