Recognition: unknown
MIPIC: Matryoshka Representation Learning via Self-Distilled Intra-Relational and Progressive Information Chaining
Pith reviewed 2026-05-08 03:31 UTC · model grok-4.3
The pith
MIPIC produces Matryoshka embeddings that remain competitive at any truncation size by aligning intra-layer relations through self-distillation and chaining semantics from deep to shallow layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
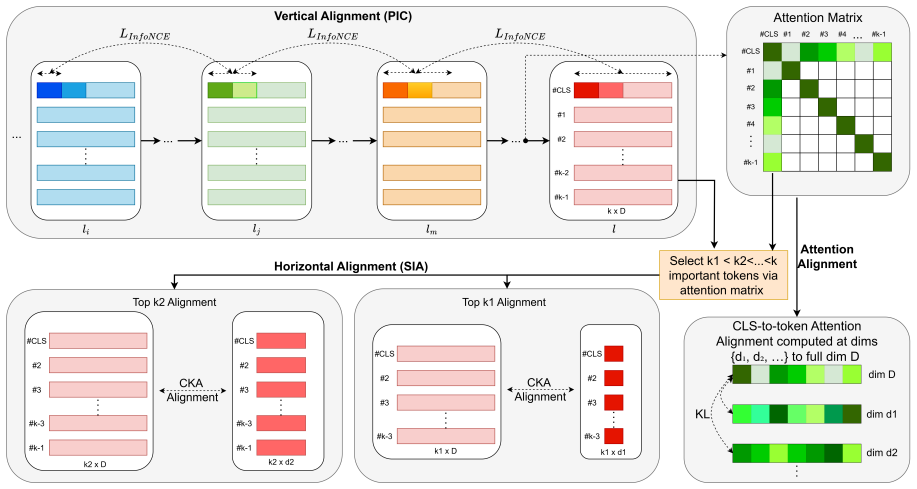
MIPIC is a unified training framework that produces structurally coherent and semantically compact Matryoshka representations by combining Self-Distilled Intra-Relational Alignment, which enforces token-level geometric and attention-driven consistency between full and truncated embeddings via top-k CKA self-distillation, with Progressive Information Chaining, which incrementally transfers mature task semantics from deeper layers to earlier layers.
What carries the argument
The dual mechanism of Self-Distilled Intra-Relational Alignment (SIA) that matches relations across embedding sizes with top-k CKA and Progressive Information Chaining (PIC) that scaffolds depth-wise semantic transfer.
If this is right
- A single trained model supplies usable representations at full, medium, and extreme low dimensions on sentence similarity, natural language inference, and classification tasks.
- Performance gains are largest in the lowest-dimensional regimes where prior Matryoshka methods lose more quality.
- The same framework applies without major retuning to models ranging from TinyBERT to Qwen3.
- Information is coordinated across both the embedding dimension axis and the model depth axis in one training run.
Where Pith is reading between the lines
- A model trained this way could let inference systems choose embedding size on the fly according to current compute limits while keeping output quality relatively stable.
- The focus on preserving relational geometry inside each layer may limit the semantic drift that usually appears when embeddings are compressed.
- The progressive chaining pattern could be tested on other transformer-based tasks such as retrieval or generation to see whether the same depth-to-shallow transfer improves nested representations there.
Load-bearing premise
That aligning intra-relational structures via top-k CKA self-distillation and incrementally chaining semantics from deeper to earlier layers will produce structurally coherent and semantically compact representations without introducing distortions or requiring heavy task-specific tuning.
What would settle it
Running the same STS, NLI, and classification benchmarks and finding that MIPIC low-dimensional truncations show no advantage or underperform standard Matryoshka training or fixed-size baselines would show the claimed benefits do not hold.
Figures
read the original abstract
Representation learning is fundamental to NLP, but building embeddings that work well at different computational budgets is challenging. Matryoshka Representation Learning (MRL) offers a flexible inference paradigm through nested embeddings; however, learning such structures requires explicit coordination of how information is arranged across embedding dimensionality and model depth. In this work, we propose MIPIC (Matryoshka Representation Learning via Self-Distilled Intra-Relational Alignment and Progressive Information Chaining), a unified training framework designed to produce structurally coherent and semantically compact Matryoshka representations. MIPIC promotes cross-dimensional structural consistency through Self-Distilled Intra-Relational Alignment (SIA), which aligns token-level geometric and attention-driven relations between full and truncated representations using top-k CKA self-distillation. Complementarily, it enables depth-wise semantic consolidation via Progressive Information Chaining (PIC), a scaffolded alignment strategy that incrementally transfers mature task semantics from deeper layers into earlier layers. Extensive experiments on STS, NLI, and classification benchmarks (spanning models from TinyBERT to BGEM3, Qwen3) demonstrate that MIPIC yields Matryoshka representations that are highly competitive across all capacities, with significant performance advantages observed under extreme low-dimensional.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce MIPIC, a unified training framework for Matryoshka Representation Learning. It uses Self-Distilled Intra-Relational Alignment (SIA) to align token-level geometric and attention-driven relations between full and truncated representations via top-k CKA self-distillation, and Progressive Information Chaining (PIC) to incrementally transfer task semantics from deeper to earlier layers. Experiments across STS, NLI, and classification benchmarks with models from TinyBERT to BGEM3 and Qwen3 show that MIPIC produces competitive Matryoshka representations at all capacities, with particular advantages in extreme low dimensions.
Significance. If the results hold under additional controls, MIPIC would advance efficient representation learning by enabling nested embeddings that maintain structural consistency and semantic content across dimensionalities and model depths, reducing the need for capacity-specific retraining in NLP. The cross-scale empirical evaluation on standard benchmarks is a positive aspect that supports potential practical utility.
major comments (1)
- [SIA method (Self-Distilled Intra-Relational Alignment)] SIA method (Self-Distilled Intra-Relational Alignment): The top-k truncation inside CKA self-distillation for aligning intra-relational structures assumes lower-ranked pairs are irrelevant or noisy. This assumption is least secure in the low-capacity regime central to the Matryoshka claims, as any lost relational variance cannot be recovered and may distort the geometry. No ablation of k versus full CKA, nor measurement of captured relational variance at target dimensions, is reported, which is load-bearing for the claim that SIA plus PIC yields coherent low-dimensional representations without distortions.
minor comments (2)
- [Abstract] The abstract states 'significant performance advantages' in extreme low-dimensional settings but provides no quantitative highlights or exact dimensions tested; adding brief numbers would improve clarity.
- [PIC description] Notation for 'truncated representations' and 'mature task semantics' in the PIC description could be formalized with equations or pseudocode to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address the major comment on the SIA method point by point below and outline the revisions we will make.
read point-by-point responses
-
Referee: SIA method (Self-Distilled Intra-Relational Alignment): The top-k truncation inside CKA self-distillation for aligning intra-relational structures assumes lower-ranked pairs are irrelevant or noisy. This assumption is least secure in the low-capacity regime central to the Matryoshka claims, as any lost relational variance cannot be recovered and may distort the geometry. No ablation of k versus full CKA, nor measurement of captured relational variance at target dimensions, is reported, which is load-bearing for the claim that SIA plus PIC yields coherent low-dimensional representations without distortions.
Authors: We appreciate the referee's observation regarding the assumptions underlying the top-k truncation in our SIA method. The motivation for using top-k CKA is to emphasize the most prominent intra-relational structures between the full and truncated representations, as lower-ranked pairs often correspond to weaker correlations that may introduce noise during self-distillation, especially in high-dimensional spaces. This is particularly relevant for maintaining efficiency in Matryoshka setups. However, we acknowledge that without explicit ablations, the impact on low-dimensional regimes remains to be fully quantified. To address this, we will include in the revised manuscript: (1) an ablation comparing top-k CKA (with our chosen k) against full CKA self-distillation across various model sizes and dimensions, and (2) measurements of the relational variance captured, such as the proportion of CKA similarity retained or the Frobenius norm of the difference in relation matrices at target low dimensions (e.g., 8D, 16D). These additions will provide direct evidence supporting the coherence of the learned representations. We believe this will substantiate our claims without altering the core methodology. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents MIPIC as an empirical training framework combining Self-Distilled Intra-Relational Alignment (SIA) via top-k CKA self-distillation and Progressive Information Chaining (PIC) for depth-wise semantic transfer. These are introduced as practical alignment strategies to produce nested Matryoshka embeddings, with claims supported by benchmark experiments across models and tasks rather than any closed mathematical derivation. No equations, self-citations, fitted parameters renamed as predictions, or ansatzes that reduce the central claims to their own inputs by construction appear in the abstract or description. The approach remains self-contained as a proposed procedure whose validity rests on external empirical validation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL: " 'urlintro :=
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year eprint doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRINGS urlintro eprinturl eprintpr...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Nguyen Hoang Anh, Quyen Tran, Thanh Xuan Nguyen, Nguyen Thi Ngoc Diep, Linh Ngo Van, Thien Huu Nguyen, and Trung Le. 2025. Mutual-pairing data augmentation for fewshot continual relation extraction. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Vo...
2025
-
[4]
Francesco Barbieri, Jose Camacho-Collados, Luis Espinosa Anke, and Leonardo Neves. 2020. https://doi.org/10.18653/v1/2020.findings-emnlp.148 T weet E val: Unified benchmark and comparative evaluation for tweet classification . In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1644--1650, Online. Association for Computational ...
-
[5]
Parishad BehnamGhader, Vaibhav Adlakha, Marius Mosbach, Dzmitry Bahdanau, Nicolas Chapados, and Siva Reddy. 2024. https://openreview.net/forum?id=IW1PR7vEBf LLM2V ec: Large language models are secretly powerful text encoders . In First Conference on Language Modeling
2024
- [6]
- [7]
-
[8]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. http://arxiv.org/abs/1810.04805 Bert: Pre-training of deep bidirectional transformers for language understanding
work page internal anchor Pith review arXiv 2019
- [9]
- [10]
-
[11]
Nam Le Hai, Linh Ngo Van, and Sang Dinh. 2026. Mozila: Continual event detection through the lens of multi-objective optimization and language model head preservation. Computational Linguistics, pages 1--44
2026
-
[12]
Hardoon, Sandor Szedmak, and John Shawe-Taylor
David R. Hardoon, Sandor Szedmak, and John Shawe-Taylor. 2004. https://doi.org/10.1162/0899766042321814 Canonical correlation analysis: An overview with application to learning methods . Neural Computation, 16(12):2639--2664
- [13]
-
[14]
Nguyen Manh Hieu, Vu Lam Anh, Hung Pham Van, Nam Le Hai, Diep Thi-Ngoc Nguyen, Linh Ngo Van, and Thien Huu Nguyen. 2025. Magix: A multi-granular adaptive graph intelligence framework for enhancing cross-lingual rag. In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 5202--5219
2025
- [15]
-
[16]
Ganesh Jawahar, Beno \^i t Sagot, and Djam \'e Seddah. 2019. https://doi.org/10.18653/v1/P19-1356 What does BERT learn about the structure of language? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3651--3657, Florence, Italy. Association for Computational Linguistics
-
[17]
Tushar Khot, Ashish Sabharwal, and Peter Clark. 2018. SciTail : A textual entailment dataset from science question answering. In AAAI
2018
-
[18]
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. 2019. http://arxiv.org/abs/1905.00414 Similarity of neural network representations revisited
work page Pith review arXiv 2019
-
[19]
Aditya Kusupati, Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha, Vivek Ramanujan, William Howard-Snyder, Kaifeng Chen, Sham Kakade, Prateek Jain, and Ali Farhadi. 2022. https://proceedings.neurips.cc/paper_files/paper/2022/file/c32319f4868da7613d78af9993100e42-Paper-Conference.pdf Matryoshka representation learning . In Advances in Neural ...
2022
- [20]
-
[21]
Anh Duc Le, Nam Le Hai, Thanh Xuan Nguyen, Linh Ngo Van, Nguyen Thi Ngoc Diep, Sang Dinh, and Thien Huu Nguyen. 2025. Enhancing discriminative representation in similar relation clusters for few-shot continual relation extraction. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics:...
2025
-
[22]
Xianming LI, Zongxi Li, Jing Li, Haoran Xie, and Qing Li. 2025. https://openreview.net/forum?id=plgLA2YBLH ESE : Espresso sentence embeddings . In The Thirteenth International Conference on Learning Representations
2025
-
[23]
Ziyue Li and Tianyi Zhou. 2025. https://openreview.net/forum?id=eFGQ97z5Cd Your mixture-of-experts LLM is secretly an embedding model for free . In The Thirteenth International Conference on Learning Representations
2025
-
[24]
and Gardner, Matt and Belinkov, Yonatan and Peters, Matthew E
Nelson F. Liu, Matt Gardner, Yonatan Belinkov, Matthew E. Peters, and Noah A. Smith. 2019. https://doi.org/10.18653/v1/N19-1112 Linguistic knowledge and transferability of contextual representations . In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1...
-
[25]
Marco Marelli, Luisa Bentivogli, Marco Baroni, Raffaella Bernardi, Stefano Menini, and Roberto Zamparelli. 2014. https://doi.org/10.3115/v1/S14-2001 S em E val-2014 task 1: Evaluation of compositional distributional semantic models on full sentences through semantic relatedness and textual entailment . In Proceedings of the 8th International Workshop on S...
-
[26]
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. http://arxiv.org/abs/1310.4546 Distributed representations of words and phrases and their compositionality
work page Pith review arXiv 2013
- [27]
-
[28]
Tien - Phat Nguyen, Vu Minh Ngo, Tung Nguyen, Linh Ngo Van, Duc Anh Nguyen, Dinh Viet Sang, and Trung Le. 2025 a . XTRA: cross-lingual topic modeling with topic and representation alignments. In Findings of the Association for Computational Linguistics: EMNLP , pages 5561--5575. Association for Computational Linguistics
2025
-
[29]
Toan Ngoc Nguyen, Nam Le Hai, Nguyen Doan Hieu, Dai An Nguyen, Linh Ngo Van, Thien Huu Nguyen, and Sang Dinh. 2025 b . Improving vietnamese-english cross-lingual retrieval for legal and general domains. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies...
2025
-
[30]
Truong Nguyen, Phi Van Dat, Ngan Nguyen, Linh Ngo Van, Trung Le, and Thanh Hong Nguyen. 2026. CTPD: cross tokenizer preference distillation. In Fortieth AAAI Conference on Artificial Intelligence, Thirty-Eighth Conference on Innovative Applications of Artificial Intelligence, Sixteenth Symposium on Educational Advances in Artificial Intelligence, AAAI , p...
2026
-
[31]
Sosuke Nishikawa, Ryokan Ri, Ikuya Yamada, Yoshimasa Tsuruoka, and Isao Echizen. 2022. https://doi.org/10.18653/v1/2022.naacl-main.284 EASE : Entity-aware contrastive learning of sentence embedding . In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3870...
-
[32]
Jeffrey Pennington, Richard Socher, and Christopher Manning. 2014. https://doi.org/10.3115/v1/D14-1162 G lo V e: Global vectors for word representation . In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing ( EMNLP ) , pages 1532--1543, Doha, Qatar. Association for Computational Linguistics
-
[33]
Deep contextualized word representations
Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. https://doi.org/10.18653/v1/N18-1202 Deep contextualized word representations . In Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (...
-
[34]
Thanh Duc Pham, Nam Le Hai, Linh Ngo Van, Nguyen Thi Ngoc Diep, Sang Dinh, and Thien Huu Nguyen. 2025. Mitigating non-representative prototypes and representation bias in few-shot continual relation extraction. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10791--10809
2025
-
[35]
Nguyen Tien Phat, Ngo Vu Minh, Linh Ngo Van, Nguyen Thi Ngoc Diep, and Thien Huu Nguyen. 2026. Gloctm: Cross-lingual topic modeling via a global context space. In Fortieth AAAI Conference on Artificial Intelligence, Thirty-Eighth Conference on Innovative Applications of Artificial Intelligence, Sixteenth Symposium on Educational Advances in Artificial Int...
2026
-
[36]
Mohammad Taher Pilehvar and Jose Camacho-Collados. 2019. https://doi.org/10.18653/v1/N19-1128 W i C : the word-in-context dataset for evaluating context-sensitive meaning representations . In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and S...
-
[37]
Nils Reimers and Iryna Gurevych. 2019. http://arxiv.org/abs/1908.10084 Sentence-bert: Sentence embeddings using siamese bert-networks
work page internal anchor Pith review arXiv 2019
- [38]
-
[39]
Minh-Phuc Truong, Hai An Vu, Tu Vu, Nguyen Thi Ngoc Diep, Linh Ngo Van, Thien Huu Nguyen, and Trung Le. 2025. Emo: Embedding model distillation via intra-model relation and optimal transport alignments. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 7605--7617
2025
-
[40]
Hai An Vu, Minh-Phuc Truong, Tu Vu, and Linh Ngo. 2026. Mol: Mixture of layers in cross-tokenizer embedding model distillation. Knowledge-Based Systems, 343:116001
2026
-
[41]
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2018. https://doi.org/10.18653/v1/W18-5446 GLUE : A multi-task benchmark and analysis platform for natural language understanding . In Proceedings of the 2018 EMNLP Workshop B lackbox NLP : Analyzing and Interpreting Neural Networks for NLP , pages 353--355, Brussels, Be...
- [42]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.