Recognition: unknown
AutoGUI-v2: A Comprehensive Multi-Modal GUI Functionality Understanding Benchmark
Pith reviewed 2026-05-08 04:28 UTC · model grok-4.3
The pith
AutoGUI-v2 shows that vision-language models still lack deep comprehension of GUI interaction logic and outcome prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
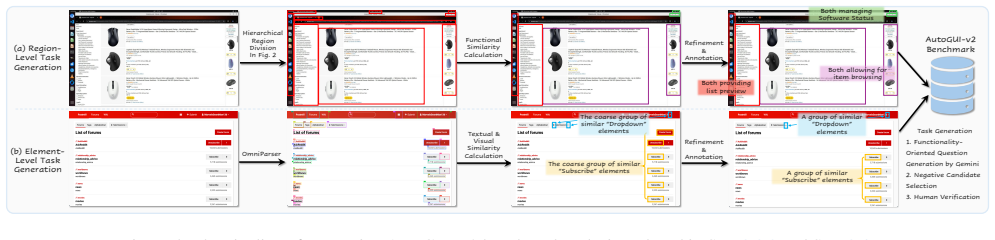
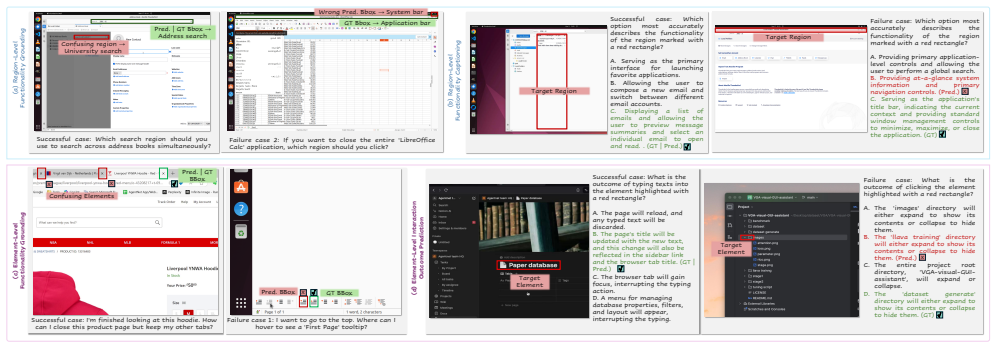
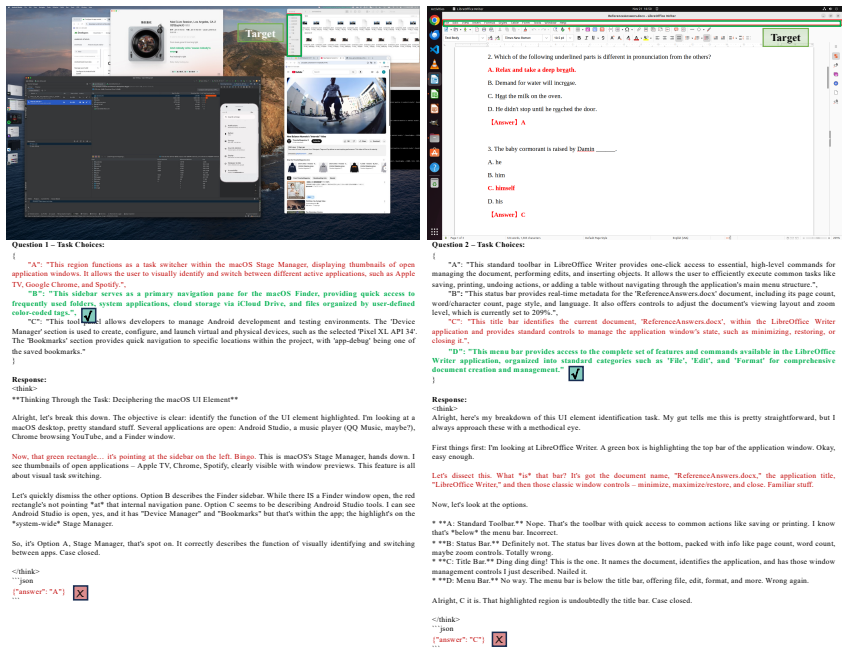
AutoGUI-v2 is constructed through a VLM-human collaborative pipeline that recursively parses multi-platform screenshots into hierarchical functional regions, thereby generating tasks that probe region- and element-level semantics, grounding accuracy, and dynamic state prediction. The resulting 2,753 tasks reveal that open-source models fine-tuned on agent data perform strongly on functional grounding while commercial models lead on functionality captioning, but every tested model fails when required to reason about the interaction logic of uncommon actions.
What carries the argument
The VLM-human collaborative pipeline that recursively parses screenshots into hierarchical functional regions to generate diverse evaluation tasks for semantics, grounding, and state prediction.
If this is right
- GUI agent training must shift emphasis from perceptual matching toward explicit modeling of interaction consequences.
- Benchmarks limited to static grounding or end-to-end task completion will understate remaining limitations in agent capability.
- Progress toward digital autonomy requires systematic measurement of predictive state reasoning across diverse and uncommon actions.
Where Pith is reading between the lines
- The observed capability split suggests that different training regimes currently trade off grounding skill against captioning skill rather than building unified functional understanding.
- Extending the hierarchical parsing approach to live user sessions could expose whether benchmark tasks generalize to unscripted workflows.
- Until models handle uncommon logic reliably, deployed GUI agents will remain restricted to narrow, well-rehearsed interaction patterns.
Load-bearing premise
The VLM-human collaborative pipeline produces tasks that accurately represent real GUI functionality and transition logic without bias.
What would settle it
An independent test in which current models accurately predict state outcomes for a set of complex uncommon actions drawn from actual operating systems would falsify the claim that deep functional understanding remains a significant hurdle.
Figures









read the original abstract
Autonomous agents capable of navigating Graphical User Interfaces (GUIs) hold the potential to revolutionize digital productivity. However, achieving true digital autonomy extends beyond reactive element matching; it necessitates a predictive mental model of interface dynamics and the ability to foresee the "digital world state" resulting from interactions. Despite the perceptual capabilities of modern Vision-Language Models (VLMs), existing benchmarks remain bifurcated (focusing either on black-box task completion or static, shallow grounding), thereby failing to assess whether agents truly comprehend the implicit functionality and transition logic of GUIs. To bridge this gap, we introduce AutoGUI-v2, a comprehensive benchmark designed to evaluate deep GUI functionality understanding and interaction outcome prediction. We construct the benchmark using a novel VLM-human collaborative pipeline that recursively parses multi-platform screenshots into hierarchical functional regions to generate diverse evaluation tasks. Providing 2,753 tasks across six operating systems, AutoGUI-v2 rigorously tests agents on region and element-level semantics, grounding, and dynamic state prediction. Our evaluation reveals a striking dichotomy in VLMs: while open-source models fine-tuned on agent data (e.g., Qwen3-VL) excel at functional grounding, commercial models (e.g., Gemini-2.5-Pro-Thinking) dominate in functionality captioning. Crucially, all models struggle with complex interaction logic of uncommon actions, highlighting that deep functional understanding remains a significant hurdle. By systematically measuring these foundational capabilities, AutoGUI-v2 offers a new lens for advancing the next generation of GUI agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AutoGUI-v2, a benchmark with 2,753 tasks across six operating systems designed to evaluate Vision-Language Models on deep GUI functionality understanding. It focuses on region/element semantics, grounding, and dynamic state prediction using a novel VLM-human collaborative pipeline that recursively parses screenshots into hierarchical functional regions. Evaluations reveal that fine-tuned open-source models (e.g., Qwen3-VL) excel at functional grounding while commercial models (e.g., Gemini-2.5-Pro) lead in captioning, but all models struggle with complex interaction logic of uncommon actions, indicating that true predictive mental models of GUI dynamics remain a significant challenge.
Significance. If the generated tasks faithfully represent real GUI state transitions without systematic bias, AutoGUI-v2 would fill an important gap between black-box task-completion benchmarks and static grounding evaluations, offering a targeted lens for improving GUI agents' ability to foresee interaction outcomes. The reported dichotomy between model types and the specific weakness on uncommon actions could usefully guide future work on functional understanding.
major comments (2)
- [Benchmark Construction] Benchmark Construction section: The VLM-human collaborative pipeline is presented as the sole source of the 2,753 tasks and their ground-truth logic, yet the manuscript provides no quantitative validation metrics such as inter-annotator agreement, error rates on held-out screenshots, or comparison against real user-interaction logs. This is load-bearing for the central claim, because the pipeline relies on the same class of VLMs shown to fail on uncommon actions, creating a risk that the benchmark systematically excludes or simplifies the hardest cases.
- [Evaluation and Results] Evaluation and Results sections: The abstract and main text report performance gaps and the conclusion that 'all models struggle with complex interaction logic of uncommon actions,' but supply no details on task validation procedures, per-category statistics, or experimental controls. Without these, it is not possible to confirm that the observed failures reflect genuine limitations in functional understanding rather than artifacts of the generation process.
minor comments (1)
- The abstract would be clearer if it briefly stated the distribution of tasks across the six operating systems and the main task categories (region semantics, grounding, outcome prediction).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, clarifying our approach and committing to revisions where appropriate to strengthen the presentation of the benchmark construction and evaluation.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark Construction section: The VLM-human collaborative pipeline is presented as the sole source of the 2,753 tasks and their ground-truth logic, yet the manuscript provides no quantitative validation metrics such as inter-annotator agreement, error rates on held-out screenshots, or comparison against real user-interaction logs. This is load-bearing for the central claim, because the pipeline relies on the same class of VLMs shown to fail on uncommon actions, creating a risk that the benchmark systematically excludes or simplifies the hardest cases.
Authors: We agree that quantitative validation metrics would strengthen confidence in the pipeline. The manuscript describes the VLM-human collaborative process with human verification at each recursive parsing step to ensure functional accuracy, but we did not report inter-annotator agreement or held-out error rates. We will revise the Benchmark Construction section to include these metrics from our internal annotation process and add an analysis of potential biases. On the risk of excluding hard cases, human annotators were explicitly directed to incorporate uncommon actions and complex logic during task generation; we will expand the discussion to address how this mitigates VLM limitations. Direct comparison to real user-interaction logs is outside the scope of our screenshot-based construction method, but we will note alignment with observed GUI transitions. revision: yes
-
Referee: [Evaluation and Results] Evaluation and Results sections: The abstract and main text report performance gaps and the conclusion that 'all models struggle with complex interaction logic of uncommon actions,' but supply no details on task validation procedures, per-category statistics, or experimental controls. Without these, it is not possible to confirm that the observed failures reflect genuine limitations in functional understanding rather than artifacts of the generation process.
Authors: We acknowledge the need for greater transparency in the evaluation. The manuscript reports aggregate results and highlights failures on uncommon actions through qualitative examples, but lacks the requested breakdowns. We will revise the Evaluation and Results sections to include per-category statistics (e.g., by action rarity and complexity), explicit task validation procedures (human cross-checks of ground-truth logic), and experimental controls (such as standardized prompting and multiple runs). These additions will better isolate genuine model limitations from any generation artifacts and support the central conclusions. revision: yes
Circularity Check
No circularity: purely empirical benchmark with independent task construction and evaluation
full rationale
The paper introduces AutoGUI-v2 as an empirical benchmark for GUI functionality understanding, constructed via a described VLM-human collaborative pipeline that recursively parses screenshots into hierarchical regions and generates 2,753 tasks. No derivation chain, equations, fitted parameters, or predictions exist in the provided text. The central claims about model performance (e.g., struggles with uncommon actions) are evaluated directly on the generated tasks without any reduction of outputs to inputs by construction, self-definition, or load-bearing self-citation. The pipeline is presented as a methodological choice for data creation, not as a self-referential loop where task validity depends on the evaluated models' success. This is a standard empirical benchmark setup that remains self-contained against external validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hierarchical functional regions from screenshots accurately capture GUI functionality and interaction outcomes.
Reference graph
Works this paper leans on
-
[1]
Navigation world models
Amir Bar, Gaoyue Zhou, Danny Tran, Trevor Darrell, and Yann LeCun. Navigation world models. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 15791–15801, 2025. 2
2025
-
[2]
Windows agent arena: Evaluating multi-modal os agents at scale, 2024
Rogerio Bonatti, Dan Zhao, Francesco Bonacci, Dillon Dupont, Sara Abdali, Yinheng Li, Yadong Lu, Justin Wa- gle, Kazuhito Koishida, Arthur Bucker, Lawrence Jang, and Zack Hui. Windows agent arena: Evaluating multi-modal os agents at scale, 2024. 3
2024
-
[3]
Amex: Android multi-annotation expo dataset for mobile gui agents, 2024
Yuxiang Chai, Siyuan Huang, Yazhe Niu, Han Xiao, Liang Liu, Dingyu Zhang, Peng Gao, Shuai Ren, and Hongsheng Li. Amex: Android multi-annotation expo dataset for mobile gui agents, 2024. 4, 1
2024
-
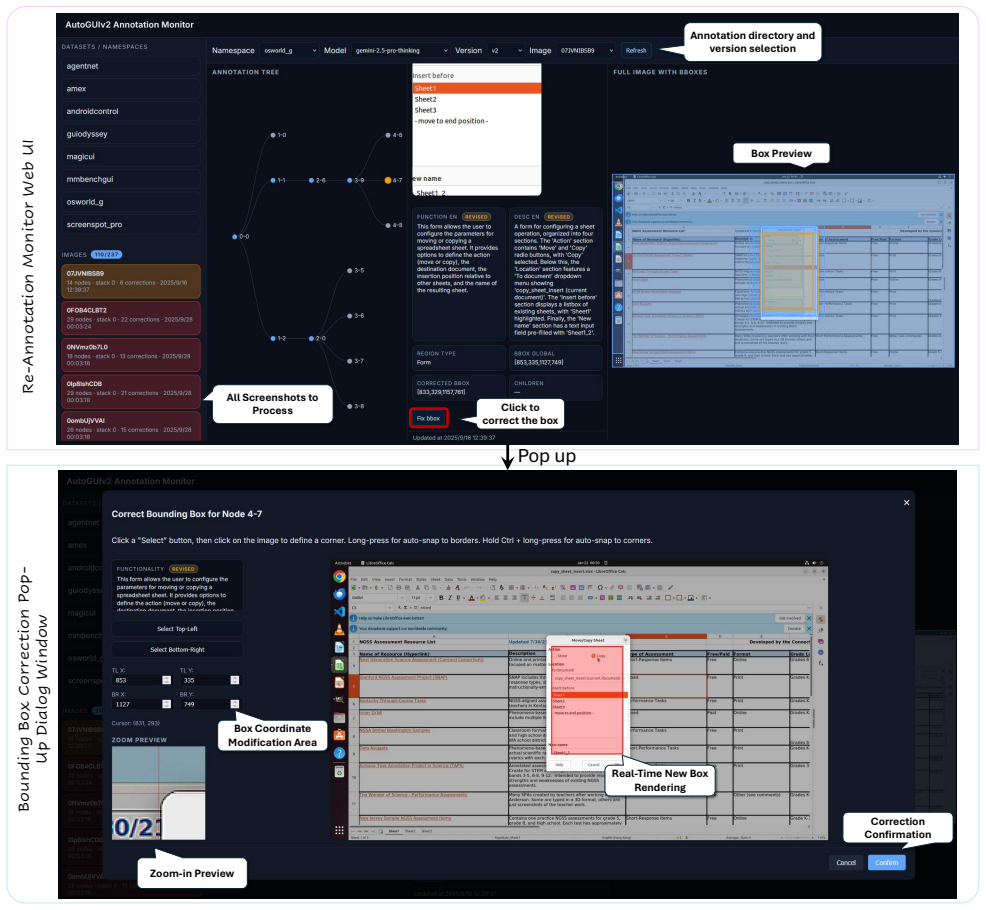
[4]
Guicourse: From general vision language models to versatile gui agents, 2024
Wentong Chen, Junbo Cui, Jinyi Hu, Yujia Qin, Junjie Fang, Yue Zhao, Chongyi Wang, Jun Liu, Guirong Chen, Yupeng Huo, Yuan Yao, Yankai Lin, Zhiyuan Liu, and Maosong Sun. Guicourse: From general vision language models to versatile gui agents, 2024. 3
2024
-
[5]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InCVPR, pages 24185– 24198, 2024. 2
2024
-
[6]
Seeclick: Har- nessing gui grounding for advanced visual gui agents
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Li YanTao, Jianbing Zhang, and Zhiyong Wu. Seeclick: Har- nessing gui grounding for advanced visual gui agents. InACL, pages 9313–9332, 2024. 2, 3, 5
2024
-
[7]
Holo2 - open foundation models for navigation and computer use agents, 2025
H Company. Holo2 - open foundation models for navigation and computer use agents, 2025. 6, 7
2025
-
[8]
Mind2web: Towards a generalist agent for the web.NIPS, 36, 2024
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web.NIPS, 36, 2024. 2, 3
2024
-
[9]
Italiano
Zvi Galil and Giuseppe F. Italiano. Data structures and algo- rithms for disjoint set union problems.ACM Comput. Surv., 23(3):319–344, 1991. 5
1991
-
[10]
Navigating the digital world as humans do: Universal visual grounding for GUI agents
Boyu Gou, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, and Yu Su. Navigating the digital world as humans do: Universal visual grounding for GUI agents. InICLR, 2025. 2, 3, 5, 6, 7
2025
-
[11]
Ui-venus technical report: Building high-performance ui agents with rft, 2025
Zhangxuan Gu, Zhengwen Zeng, Zhenyu Xu, et al. Ui-venus technical report: Building high-performance ui agents with rft, 2025. 6, 7
2025
-
[12]
Cogagent: A visual language model for gui agents
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wen- meng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, and Jie Tang. Cogagent: A visual language model for gui agents. InCVPR, pages 14281–14290, 2024. 2, 3
2024
-
[13]
Spiritsight agent: Advanced gui agent with one look
Zhiyuan Huang, Ziming Cheng, Junting Pan, Zhaohui Hou, and Mingjie Zhan. Spiritsight agent: Advanced gui agent with one look. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 29490–29500, 2025. 3
2025
-
[14]
Sheetcopilot: Bringing software produc- tivity to the next level through large language models
Hongxin Li, Jingran Su, Yuntao Chen, Qing Li, and ZHAO- XIANG ZHANG. Sheetcopilot: Bringing software produc- tivity to the next level through large language models. In Advances in Neural Information Processing Systems, pages 4952–4984. Curran Associates, Inc., 2023. 2, 3
2023
-
[15]
Autogui: Scaling gui grounding with automatic functionality annotations from llms
Hongxin Li, Jingfan Chen, Jingran Su, Yuntao Chen, Qing Li, and Zhaoxiang Zhang. Autogui: Scaling gui grounding with automatic functionality annotations from llms. InACL, 2025. 2, 3, 4, 5
2025
-
[16]
Uipro: Unleashing superior interaction capability for gui agents, 2025
Hongxin Li, Jingran Su, Jingfan Chen, Zheng Ju, Yuntao Chen, Qing Li, and Zhaoxiang Zhang. Uipro: Unleashing superior interaction capability for gui agents, 2025. 2, 1
2025
-
[17]
Screenspot-pro: GUI grounding for professional high- resolution computer use
Kaixin Li, Meng ziyang, Hongzhan Lin, Ziyang Luo, Yuchen Tian, Jing Ma, Zhiyong Huang, and Tat-Seng Chua. Screenspot-pro: GUI grounding for professional high- resolution computer use. InWorkshop on Reasoning and Planning for Large Language Models, 2025. 2, 3, 4, 1
2025
-
[18]
On the effects of data scale on ui control agents
Wei Li, William Bishop, Alice Li, Chris Rawles, Folawiyo Campbell-Ajala, Divya Tyamagundlu, and Oriana Riva. On the effects of data scale on ui control agents. InNIPS, pages 92130–92154. Curran Associates, Inc., 2024. 1
2024
-
[19]
Li, Gang Li, Luheng He, Jingjie Zheng, Hong Li, and Zhi- wei Guan
Y . Li, Gang Li, Luheng He, Jingjie Zheng, Hong Li, and Zhi- wei Guan. Widget captioning: Generating natural language description for mobile user interface elements. InEMNLP,
-
[20]
Showui: One vision-language-action model for gui visual agent
Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Shiwei Wu, Zechen Bai, Stan Weixian Lei, Lijuan Wang, and Mike Zheng Shou. Showui: One vision-language-action model for gui visual agent. InCVPR, pages 19498–19508,
-
[21]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InNIPS, pages 34892–34916. Curran Associates, Inc., 2023. 2
2023
-
[22]
Visualwebbench: How far have multimodal LLMs evolved in web page under- standing and grounding? InFirst Conference on Language Modeling, 2024
Junpeng Liu, Yifan Song, Bill Yuchen Lin, Wai Lam, Gra- ham Neubig, Yuanzhi Li, and Xiang Yue. Visualwebbench: How far have multimodal LLMs evolved in web page under- standing and grounding? InFirst Conference on Language Modeling, 2024. 2, 3
2024
-
[23]
Yuhang Liu, Zeyu Liu, Shuanghe Zhu, Pengxiang Li, Congkai Xie, Jiasheng Wang, Xueyu Hu, Xiaotian Han, Jianbo Yuan, Xinyao Wang, et al. Infigui-g1: Advancing gui grounding with adaptive exploration policy optimization.ArXiv preprint, abs/2508.05731, 2025. 3
-
[24]
Infigui-g1: Advancing gui grounding with adaptive exploration policy optimization.Proceedings of the AAAI Conference on Artificial Intelligence, 40(38):32267–32275,
Yuhang Liu, Zeyu Liu, Shuanghe Zhu, Pengxiang Li, Con- gkai Xie, Jiasheng Wang, Xueyu Hu, Xiaotian Han, Jianbo Yuan, Xinyao Wang, Shengyu Zhang, Hongxia Yang, and Fei Wu. Infigui-g1: Advancing gui grounding with adaptive exploration policy optimization.Proceedings of the AAAI Conference on Artificial Intelligence, 40(38):32267–32275,
-
[25]
Mathvista: Evaluating mathemati- cal reasoning of foundation models in visual contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathemati- cal reasoning of foundation models in visual contexts. InIn- ternational Conference on Learning Representations (ICLR),
-
[26]
Gui odyssey: A comprehensive dataset for cross-app gui navigation on mobile devices, 2024
Quanfeng Lu, Wenqi Shao, Zitao Liu, Fanqing Meng, Boxuan Li, Botong Chen, Siyuan Huang, Kaipeng Zhang, Yu Qiao, and Ping Luo. Gui odyssey: A comprehensive dataset for cross-app gui navigation on mobile devices, 2024. 2, 3
2024
-
[27]
Omniparser for pure vision based gui agent, 2024
Yadong Lu, Jianwei Yang, Yelong Shen, and Ahmed Awadal- lah. Omniparser for pure vision based gui agent, 2024. 2, 3, 5, 1
2024
-
[28]
Zhengxi Lu, Yuxiang Chai, Yaxuan Guo, Xi Yin, Liang Liu, Hao Wang, Han Xiao, Shuai Ren, Guanjing Xiong, and Hongsheng Li. Ui-r1: Enhancing efficient action predic- tion of gui agents by reinforcement learning.ArXiv preprint, abs/2503.21620, 2025. 3
-
[29]
arXiv preprint arXiv:2504.10458 , year=
Run Luo, Lu Wang, Wanwei He, and Xiaobo Xia. Gui-r1: A generalist r1-style vision-language action model for gui agents.arXiv preprint arXiv:2504.10458, 2025. 6, 7
-
[30]
Rodriguez, Montek Kalsi, Nicolas Chapados, M
Shravan Nayak, Xiangru Jian, Kevin Qinghong Lin, Juan A. Rodriguez, Montek Kalsi, Nicolas Chapados, M. Tamer Özsu, Aishwarya Agrawal, David Vazquez, Christopher Pal, Perouz Taslakian, Spandana Gella, and Sai Rajeswar. UI-vision: A desktop-centric GUI benchmark for visual perception and interaction. InForty-second International Conference on Machine Learni...
2025
-
[31]
Ui-tars: Pioneering automated gui interaction with native agents, 2025
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shi- jue Huang, Wanjun Zhong, Kuanye Li, Jiale Yang, Yu Miao, Woyu Lin, Longxiang Liu, Xu Jiang, Qianli Ma, Jingyu Li, Xi- aojun Xiao, Kai Cai, Chuang Li, Yaowei Zheng, Chaolin Jin, Chen Li, Xiao Zhou, Minchao Wang, Haoli Chen, Zhaojian Li, Haihu...
2025
-
[32]
Android in the wild: A large-scale dataset for android device control
Christopher Rawles, Alice Li, Daniel Rodriguez, Oriana Riva, and Timothy Lillicrap. Android in the wild: A large-scale dataset for android device control. InNIPS, pages 59708– 59728. Curran Associates, Inc., 2023. 2
2023
-
[33]
Androidworld: A dynamic bench- marking environment for autonomous agents, 2024
Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, Daniel Toyama, Robert Berry, Divya Tyamagundlu, Timothy Lill- icrap, and Oriana Riva. Androidworld: A dynamic bench- marking environment for autonomous agents, 2024. 2, 3
2024
-
[34]
General agents need world models
Jonathan Richens, Tom Everitt, and David Abel. General agents need world models. InForty-second International Conference on Machine Learning, 2025. 2, 3
2025
-
[35]
Gui knowledge bench: Revealing the knowledge gap behind vlm failures in gui tasks, 2025
Chenrui Shi, Zedong Yu, Zhi Gao, Ruining Feng, Enqi Liu, Yuwei Wu, Yunde Jia, Liuyu Xiang, Zhaofeng He, and Qing Li. Gui knowledge bench: Revealing the knowledge gap behind vlm failures in gui tasks, 2025. 2, 3
2025
-
[36]
Oriane Siméoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Tim- othée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Jul...
2025
-
[37]
Gui- xplore: Empowering generalizable gui agents with one explo- ration
Yuchen Sun, Shanhui Zhao, Tao Yu, Hao Wen, Samith Va, Mengwei Xu, Yuanchun Li, and Chongyang Zhang. Gui- xplore: Empowering generalizable gui agents with one explo- ration. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 19477–19486, 2025. 3
2025
-
[38]
Gui-g2: Gaussian reward modeling for gui grounding, 2025
Fei Tang, Zhangxuan Gu, Zhengxi Lu, Xuyang Liu, Shuheng Shen, Changhua Meng, Wen Wang, Wenqi Zhang, Yongliang Shen, Weiming Lu, Jun Xiao, and Yueting Zhuang. Gui-g2: Gaussian reward modeling for gui grounding, 2025. 3
2025
-
[39]
Gemini 2.5 pro, 2025
Google DeepMind Team. Gemini 2.5 pro, 2025. 2, 4, 5, 6, 7, 8
2025
-
[40]
/llama-3.2-11b-vision, 2024
Meta Llama Team. /llama-3.2-11b-vision, 2024. 2
2024
-
[41]
Introducing claude sonnet 4.5, 2025
OpenAI Team. Introducing claude sonnet 4.5, 2025. 5, 6, 7
2025
-
[42]
Gpt-5 is here, 2025
OpenAI Team. Gpt-5 is here, 2025. 5, 6, 7
2025
-
[43]
Introducing openai o3 and o4-mini, 2025
OpenAI Team. Introducing openai o3 and o4-mini, 2025. 5, 6, 7
2025
-
[44]
Qwen3-vl: Sharper vision, deeper thought, broader action, 2025
Qwen Team. Qwen3-vl: Sharper vision, deeper thought, broader action, 2025. 2, 5, 6, 7, 8
2025
-
[45]
Step-3 is large yet affordable: Model-system co-design for cost-effective decoding, 2025
StepFun Team. Step-3 is large yet affordable: Model-system co-design for cost-effective decoding, 2025. 5, 6, 7
2025
-
[46]
Glm-4.5v and glm-4.1v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning,
V Team, Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, Shuaiqi Duan, Weihan Wang, Yan Wang, Yean Cheng, Zehai He, Zhe Su, Zhen Yang, Ziyang Pan, Aohan Zeng, Baoxu Wang, Bin Chen, Boyan Shi, Changyu Pang, Chenhui Zhang, Da Yin, Fan Yang, Guoqing Chen, Jiazheng Xu, Jiale Zhu, Jiali Chen, J...
-
[47]
Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution, 2024
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution, 2024. 2, 5, 6, 7
2024
-
[48]
Mmbench-gui: Hierarchical multi-platform evaluation framework for gui agents, 2025
Xuehui Wang, Zhenyu Wu, JingJing Xie, Zichen Ding, Bowen Yang, Zehao Li, Zhaoyang Liu, Qingyun Li, Xuan Dong, Zhe Chen, Weiyun Wang, Xiangyu Zhao, Jixuan Chen, Haodong Duan, Tianbao Xie, Chenyu Yang, Shiqian Su, Yue Yu, Yuan Huang, Yiqian Liu, Xiao Zhang, Yanting Zhang, Xi- angyu Yue, Weijie Su, Xizhou Zhu, Wei Shen, Jifeng Dai, and Wenhai Wang. Mmbench-g...
2025
-
[49]
OpenCUA: Open foundations for computer-use agents
Xinyuan Wang, Bowen Wang, Dunjie Lu, Junlin Yang, Tian- bao Xie, Junli Wang, Jiaqi Deng, Xiaole Guo, Yiheng Xu, Chen Henry Wu, Zhennan Shen, Zhuokai Li, Ryan Li, Xi- aochuan Li, Junda Chen, Zheng Boyuan, LI PEIHANG, Fangyu Lei, Ruisheng Cao, Yeqiao Fu, Dongchan Shin, Mar- tin Shin, Hu Jiarui, Yuyan Wang, Jixuan Chen, Yuxiao Ye, Danyang Zhang, Yipu Wang, H...
-
[50]
Driving into the future: Multiview visual forecasting and planning with world model for au- tonomous driving
Yuqi Wang, Jiawei He, Lue Fan, Hongxin Li, Yuntao Chen, and Zhaoxiang Zhang. Driving into the future: Multiview visual forecasting and planning with world model for au- tonomous driving. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 14749–14759, 2024. 2
2024
-
[51]
Mp-gui: Modality perception with mllms for gui understanding
Ziwei Wang, Weizhi Chen, Leyang Yang, Sheng Zhou, Shengchu Zhao, Hanbei Zhan, Jiongchao Jin, Liangcheng Li, Zirui Shao, and Jiajun Bu. Mp-gui: Modality perception with mllms for gui understanding. InProceedings of the Com- puter Vision and Pattern Recognition Conference (CVPR), pages 29711–29721, 2025. 2
2025
-
[52]
OS-ATLAS: Foundation action model for generalist GUI agents
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, and Yu Qiao. OS-ATLAS: Foundation action model for generalist GUI agents. InICLR, 2025. 2, 3, 5, 6, 7, 8
2025
-
[53]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. InAd- vances in Neural Information...
2024
-
[55]
Scaling computer-use grounding via user interface decomposition and synthesis,
Tianbao Xie, Jiaqi Deng, Xiaochuan Li, Junlin Yang, Haoyuan Wu, Jixuan Chen, Wenjing Hu, Xinyuan Wang, Yuhui Xu, Zekun Wang, Yiheng Xu, Junli Wang, Doyen Sa- hoo, Tao Yu, and Caiming Xiong. Scaling computer-use grounding via user interface decomposition and synthesis,
-
[56]
AndroidLab: Training and systematic benchmarking of an- droid autonomous agents
Yifan Xu, Xiao Liu, Xueqiao Sun, Siyi Cheng, Hao Yu, Hanyu Lai, Shudan Zhang, Dan Zhang, Jie Tang, and Yuxiao Dong. AndroidLab: Training and systematic benchmarking of an- droid autonomous agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2144–2166, Vienna, Austria,
-
[57]
Association for Computational Linguistics. 3
-
[58]
Aguvis: Unified pure vision agents for autonomous GUI interaction
Yiheng Xu, Zekun Wang, Junli Wang, Dunjie Lu, Tianbao Xie, Amrita Saha, Doyen Sahoo, Tao Yu, and Caiming Xiong. Aguvis: Unified pure vision agents for autonomous GUI interaction. InICML, 2025. 2, 3
2025
-
[59]
macosworld: A multilingual interactive benchmark for gui agents, 2025
Pei Yang, Hai Ci, and Mike Zheng Shou. macosworld: A multilingual interactive benchmark for gui agents, 2025. 3
2025
-
[60]
Aria-ui: Visual grounding for gui instructions, 2024
Yuhao Yang, Yue Wang, Dongxu Li, Ziyang Luo, Bei Chen, Chao Huang, and Junnan Li. Aria-ui: Visual grounding for gui instructions, 2024. 2
2024
-
[61]
Mmmu: A massive multi-discipline multimodal understand- ing and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Ren- liang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. Mmmu: A massive multi-discipline multimodal understand- ing and reasoning benchmark for...
2024
-
[62]
Bofei Zhang, Zirui Shang, Zhi Gao, Wang Zhang, Rui Xie, Xi- aojian Ma, Tao Yuan, Xinxiao Wu, Song-Chun Zhu, and Qing Li. Tongui: Building generalized gui agents by learning from multimodal web tutorials.arXiv preprint arXiv:2504.12679,
-
[63]
AppAgent: Multimodal agents as smartphone users,
Chi Zhang, Zhao Yang, Jiaxuan Liu, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Yu. Appagent: Multimodal agents as smartphone users.arXiv preprint arXiv:2312.13771,
-
[64]
Android in the zoo: Chain-of-action-thought for GUI agents
Jiwen Zhang, Jihao Wu, Teng Yihua, Minghui Liao, Nuo Xu, Xiao Xiao, Zhongyu Wei, and Duyu Tang. Android in the zoo: Chain-of-action-thought for GUI agents. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 12016–12031, Miami, Florida, USA, 2024. Association for Computational Linguistics. 2
2024
-
[65]
Qwen3 em- bedding: Advancing text embedding and reranking through foundation models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 em- bedding: Advancing text embedding and reranking through foundation models. 2025. 4 AutoGUI-v2: A Comprehensive Multi-Modal GUI Functionality Understanding Benchmark Supplementary Material
2025
-
[66]
propose-verify- refine
Implementation Details of AutoGUI-v2 Datasets 6.1. GUI Data Sources The following GUI data sources are utilized by AutoGUI- v2 to generation functional regions along with functionality descriptions: AMEX, also named Android Multi-annotation EXpo [3], is a comprehensive, large-scale dataset designed for mobile GUI agents, providing 104K high-resolution scr...
-
[67]
It returns a score from 0-3, assessing if the region is fully visible and functionally coherent
Completeness (scomp i ):The checking model evaluates the cropped child region Ii within the context of its parent Iregion (which is marked with a red rectangle for refer- ence). It returns a score from 0-3, assessing if the region is fully visible and functionally coherent
-
[68]
accepted
Boundedness ( sbound i ):The model provides a binary (Yes/No) judgment on whether the bounding box Bi tightly frames the functional elements without excessive padding or cropping. A proposal is "accepted" if the average completeness score 1 K P scomp i meets our quality threshold (e.g., ≥2.5 ) AND the ratio of "bounded" children 1 K P 1(sbound i =Yes) mee...
-
[69]
Image List:A searchable list of all GUIs, with status indicators showing the percentage of nodes that have been corrected
-
[70]
Clicking a node in this tree loads its metadata in the details panel
Hierarchy Panel:A D3.js-based interactive tree visu- alization of the selected GUI’s full functional hierarchy. Clicking a node in this tree loads its metadata in the details panel
-
[71]
Fix BBox
Full Image Panel:A view of the entire root screenshot with all VLM-proposed bounding boxes rendered on an SVG overlay. 6.4.3. Convenient Bounding Box Correction Workflow The correction process is initiated when an annotator selects a node and opens the "Fix BBox" modal. This interface is equipped with advanced tools to make correction fast and precise: • ...
-
[72]
It searches for all human- corrected metadata files, which are identified by their _fix*.jsonor_meta_fix *.jsonsuffix
Correction Discovery:The re-annotating script recur- sively scans the cache directory. It searches for all human- corrected metadata files, which are identified by their _fix*.jsonor_meta_fix *.jsonsuffix
-
[73]
This object con- tains paths to the original root image, the node’s original metadata, and the human-corrected file
Task Queuing:For each corrected file found, the script generates a CorrectionTask object. This object con- tains paths to the original root image, the node’s original metadata, and the human-corrected file
-
[74]
UI/UX analyst
Parallel Execution:The script processes this queue in parallel using a multiprocessing.Pool. Each worker executes the core reannotate_node function for a given task. The core of this functionality re- annotation is a specialized VLM prompt (REANNOTATION_PROMPT_TEMPLATE shown in Tab. 11) that provides the model with a rich, multi-modal context to perform a...
-
[75]
En- tire GUI
Filtering:The script first filters out the root node ("En- tire GUI") and any nodes that do not meet minimal size criteria, as these are trivial or non-informative
-
[76]
Application Win- dow
Context-Aware Prompting:The VLM is presented with thecropped imageof the region. To ensure accuracy, the prompt ( build_classification_prompt) pro- vides the model with: • The full taxonomy list with definitions. • A set of few-shot examples demonstrating correct clas- sification (e.g., distinguishing an "Application Win- dow" containing a dialog from the...
-
[77]
The system includes robust regex-based fallback mecha- nisms to handle varied VLM output formats
Robust Parsing:The VLM’s response is parsed to ex- tract the type, subtype, and a confidence score. The system includes robust regex-based fallback mecha- nisms to handle varied VLM output formats
-
[78]
Nav- igation
Inheritance Logic:For regions that are not ex- plicitly classified (e.g., intermediate grouping nodes), the system implements a fallback inheritance logic (get_inherited_type), allowing them to adopt the classification of their parent or child nodes where appro- priate to maintain semantic continuity in the hierarchy. 6.5.3. Output Integration The classif...
1920
-
[79]
If an overlap is detected, one element (typically the one with the larger area) is removed, and the check is repeated until no overlaps remain
Overlap Resolution:We iteratively check for bounding box overlaps within each group. If an overlap is detected, one element (typically the one with the larger area) is removed, and the check is repeated until no overlaps remain
-
[80]
Minimum Size Check:Groups that have been reduced to fewer than 2 elements after verification or cleanup are immediately discarded
-
[81]
oversized
Oversized Group Detection:Groups containing more than 5 elements are flagged as “oversized.”
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.