Recognition: unknown
PhysNote: Self-Knowledge Notes for Evolvable Physical Reasoning in Vision-Language Model
Pith reviewed 2026-05-08 03:38 UTC · model grok-4.3
The pith
Vision-language models can consolidate self-generated knowledge notes to maintain object identities and causal chains across video frames for physical reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
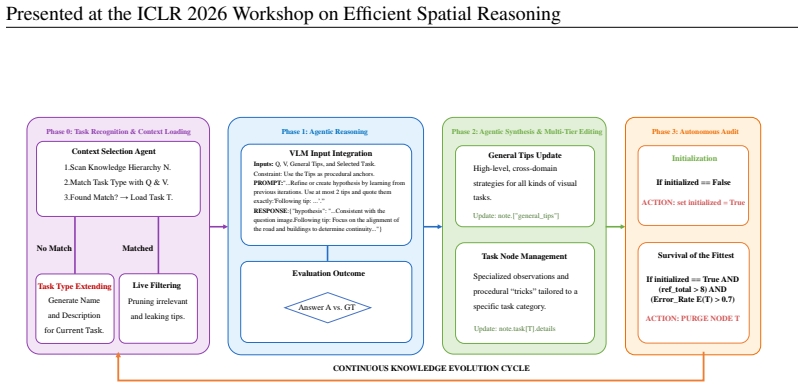
PhysNote is a framework that lets vision-language models externalize physical knowledge as self-generated Knowledge Notes, apply spatio-temporal canonicalization to preserve object identities across frames, organize insights in a hierarchical repository, and run an iterative loop that grounds new hypotheses in visual evidence before consolidation, leading to higher accuracy on multi-frame physical reasoning tasks.
What carries the argument
Knowledge Notes: self-generated, verified, and consolidated records of physical insights that the model reuses to stabilize perception and maintain causal reasoning over time.
If this is right
- Object identities remain consistent across successive frames instead of drifting and breaking causal chains.
- Correct physical insights produced during inference become stored for reuse rather than lost after each query.
- Iterative grounding in visual evidence reduces reliance on volatile single-pass reasoning.
- Accuracy gains appear across all tested physical reasoning domains rather than in isolated cases.
Where Pith is reading between the lines
- The same note-based consolidation could be tested on non-physical tasks such as multi-step planning where insights need to persist across steps.
- If notes can be shared or merged between models, the approach might support collective knowledge building in agent teams.
- Longer video sequences could expose whether the hierarchical repository scales before note conflicts arise.
Load-bearing premise
That the model can reliably verify and consolidate its own self-generated knowledge notes against visual evidence without introducing or propagating errors.
What would settle it
Disabling the verification and consolidation steps in the iterative loop and checking whether accuracy on PhysBench falls back to or below the multi-agent baseline levels.
Figures



read the original abstract
Vision-Language Models (VLMs) have demonstrated strong performance on textbook-style physics problems, yet they frequently fail when confronted with dynamic real-world scenarios that require temporal consistency and causal reasoning across frames. We identify two fundamental challenges underlying these failures: (1) spatio-temporal identity drift, where objects lose their physical identity across successive frames and break causal chains, and (2) volatility of inference-time insights, where a model may occasionally produce correct physical reasoning but never consolidates it for future reuse. To address these challenges, we propose PhysNote, an agentic framework that enables VLMs to externalize and refine physical knowledge through self-generated "Knowledge Notes." PhysNote stabilizes dynamic perception through spatio-temporal canonicalization, organizes self-generated insights into a hierarchical knowledge repository, and drives an iterative reasoning loop that grounds hypotheses in visual evidence before consolidating verified knowledge. Experiments on PhysBench demonstrate that PhysNote achieves 56.68% overall accuracy, a 4.96% improvement over the best multi-agent baseline, with consistent gains across all four physical reasoning domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PhysNote, an agentic framework for Vision-Language Models (VLMs) to address challenges in physical reasoning, specifically spatio-temporal identity drift and volatility of inference-time insights. It does so by enabling VLMs to generate self-knowledge notes, organize them hierarchically, and use an iterative loop to ground hypotheses in visual evidence before consolidation. The key empirical result is an overall accuracy of 56.68% on PhysBench, representing a 4.96% improvement over the best multi-agent baseline, with gains in all four physical reasoning domains.
Significance. Should the self-verification and consolidation process prove robust, PhysNote offers a promising direction for making VLMs' physical reasoning more evolvable and consistent over time by externalizing and reusing knowledge. This could have implications for applications requiring long-term physical understanding, such as robotics or video analysis. The identification of the two core challenges provides a useful framing for future work in the area.
major comments (2)
- Abstract: The reported 56.68% accuracy and 4.96% improvement over the multi-agent baseline are presented without ablations, error bars, statistical tests, or controls that isolate the contribution of the Knowledge Notes, spatio-temporal canonicalization, or iterative verification loop. This is load-bearing for the central claim, as the gains could arise from unstated implementation details rather than the proposed components.
- Method (iterative reasoning loop description): The self-verification step that grounds hypotheses in visual evidence and consolidates only 'verified' notes into the hierarchical repository lacks any independent check, human audit, or measured error rate on the notes themselves. Given that the same VLM is used for both generation and verification, this leaves open the possibility of error amplification in the spatio-temporal identity drift and causal reasoning cases highlighted in the abstract.
minor comments (2)
- Abstract: The phrase 'spatio-temporal canonicalization' is used without a concise definition or pointer to its implementation details, which reduces immediate clarity for readers.
- Overall: Adding a diagram of the hierarchical repository and the generate-ground-consolidate loop would aid comprehension of the agentic flow.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate the revisions we will incorporate to strengthen the empirical presentation and methodological transparency.
read point-by-point responses
-
Referee: Abstract: The reported 56.68% accuracy and 4.96% improvement over the multi-agent baseline are presented without ablations, error bars, statistical tests, or controls that isolate the contribution of the Knowledge Notes, spatio-temporal canonicalization, or iterative verification loop. This is load-bearing for the central claim, as the gains could arise from unstated implementation details rather than the proposed components.
Authors: The abstract is intentionally concise. The full manuscript provides component-wise ablations in Section 4 that isolate the contributions of Knowledge Notes, spatio-temporal canonicalization, and the iterative verification loop, including direct comparisons against variants without each element. We will revise the abstract to reference these controls and include error bars plus statistical significance tests on the reported accuracies in the revised version. revision: partial
-
Referee: Method (iterative reasoning loop description): The self-verification step that grounds hypotheses in visual evidence and consolidates only 'verified' notes into the hierarchical repository lacks any independent check, human audit, or measured error rate on the notes themselves. Given that the same VLM is used for both generation and verification, this leaves open the possibility of error amplification in the spatio-temporal identity drift and causal reasoning cases highlighted in the abstract.
Authors: The verification step requires explicit grounding against input frames before consolidation, providing an internal consistency mechanism tied to visual evidence. We acknowledge that no independent human audit or separate error-rate measurement on the notes was performed and that reuse of the same VLM raises a legitimate risk of error amplification. We will add an explicit limitations paragraph discussing this risk, along with suggestions for external verifiers in future extensions. revision: yes
Circularity Check
No circularity: empirical benchmark results independent of any derivation chain
full rationale
The paper presents an agentic framework (PhysNote) for VLMs and reports measured accuracy on the external PhysBench benchmark (56.68% overall, +4.96% over baseline). No equations, derivations, fitted parameters, or mathematical predictions appear in the abstract or method description. The central claim is an empirical outcome from running the system on a held-out dataset rather than a quantity constructed by definition, self-citation, or renaming of inputs. No self-definitional loops, uniqueness theorems, or ansatz smuggling are present. The result is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-generated knowledge notes can be verified against visual evidence and consolidated without error propagation
invented entities (1)
-
Knowledge Notes
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Ale- man, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review arXiv
-
[3]
URLhttps://arxiv.org/abs/2502.13923. Vahid Balazadeh, Mohammadmehdi Ataei, Hyunmin Cheong, Amir Hosein Khasahmadi, and Rahul G Krishnan. Physics context builders: A modular framework for physical reasoning in vision-language models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 7318–7328,
work page internal anchor Pith review arXiv
-
[4]
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, et al. How far are we to GPT-4v? closing the gap to commercial multimodal models with open-source suites.arXiv preprint arXiv:2404.16821,
work page internal anchor Pith review arXiv
-
[5]
Wei Chow, Jiageng Mao, Boyi Li, Daniel Seita, Vitor Campagnolo Guizilini, and Yue Wang. Phys- bench: Benchmarking and enhancing vision-language models for physical world understanding. InThe Thirteenth International Conference on Learning Representations. Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Ma...
work page internal anchor Pith review arXiv
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review arXiv
-
[7]
A path towards autonomous machine intelligence version 0.9
Yann LeCun. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27.Open Review, 62(1):1–62,
2022
-
[8]
Improved Baselines with Visual Instruction Tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning.arXiv preprint arXiv:2310.03744,
work page internal anchor Pith review arXiv
-
[9]
OpenAI. GPT-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review arXiv
-
[10]
Phybench: Holistic evaluation of physical perception and reasoning in large language models
10 Presented at the ICLR 2026 Workshop on Efficient Spatial Reasoning Shi Qiu, Shaoyang Guo, Zhuo-Yang Song, Yunbo Sun, Zeyu Cai, Jiashen Wei, Tianyu Luo, Yix- uan Yin, Haoxu Zhang, Yi Hu, et al. Phybench: Holistic evaluation of physical perception and reasoning in large language models.arXiv preprint arXiv:2504.16074,
-
[11]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Machel Reid, Nikolay Savinov, Denis Teplyashin, et al. Gemini 1.5: Unlocking multimodal under- standing across millions of tokens of context.arXiv preprint arXiv:2403.05530,
work page internal anchor Pith review arXiv
-
[12]
Cambrian-s: Towards spatial supersens- ing in video.arXiv preprint arXiv:2511.04670, 2025
Shusheng Yang, Jihan Yang, Pinzhi Huang, Ellis Brown, Zihao Yang, Yue Yu, Shengbang Tong, Zihan Zheng, Yifan Xu, Muhan Wang, et al. Cambrian-s: Towards spatial supersensing in video. arXiv preprint arXiv:2511.04670,
-
[13]
Xinyu Zhang, Yuxuan Dong, Yanrui Wu, Jiaxing Huang, Chengyou Jia, Basura Fernando, Mike Zheng Shou, Lingling Zhang, and Jun Liu. Physreason: A comprehensive benchmark towards physics-based reasoning.arXiv preprint arXiv:2502.12054,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.