Recognition: unknown
Can You Make It Sound Like You? Post-Editing LLM-Generated Text for Personal Style
Pith reviewed 2026-05-08 03:49 UTC · model grok-4.3
The pith
Post-editing LLM-generated drafts raises stylistic similarity to a writer's own unassisted text while lowering similarity to pure model output.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the study, post-editing increased stylistic similarity to participants' unassisted writing and reduced similarity to fully LLM-generated output, yet post-edited text remained closer in style to LLM text than to the unassisted control text and exhibited reduced stylistic diversity compared with unassisted human text.
What carries the argument
Embedding-based style similarity metrics that quantify how much post-edited text aligns with a participant's own unassisted writing versus untouched LLM output.
If this is right
- Post-editing shifts output toward a writer's style but does not fully eliminate LLM stylistic patterns.
- Edited text shows lower stylistic diversity than writing produced without LLM assistance.
- Writers may perceive post-edited text as authentic even when objective metrics detect model influence.
- Pure generation and post-editing produce different degrees of stylistic personalization.
Where Pith is reading between the lines
- Tools that help users rewrite LLM drafts could focus on increasing output diversity to close the remaining gap.
- For tasks where exact personal voice is required, users may still need to write from scratch rather than edit.
- The observed perception gap suggests that current similarity metrics may not fully align with reader judgments of authenticity.
Load-bearing premise
Embedding-based metrics capture what counts as personal style in a way that matches human perception and practical importance.
What would settle it
A controlled experiment in which independent human readers rate post-edited text as stylistically indistinguishable from unassisted human writing at rates equal to or higher than LLM text would falsify the claim that detectable LLM traces remain.
Figures

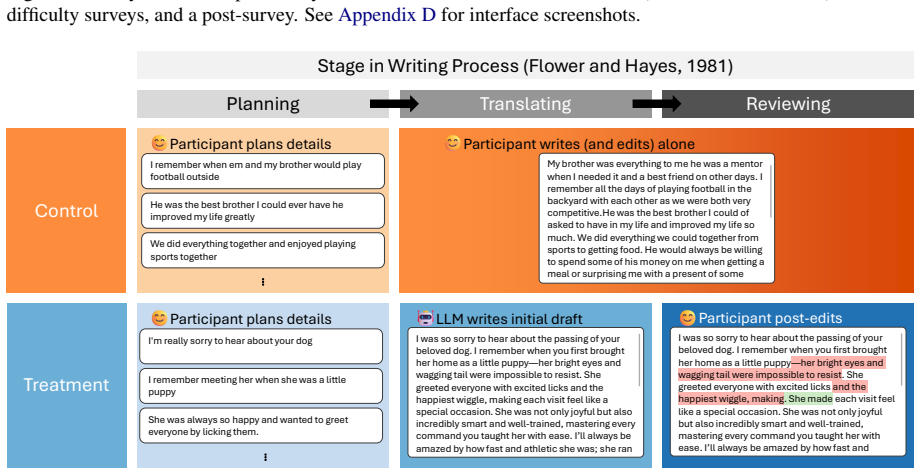

















read the original abstract
Despite the growing use of large language models (LLMs) for writing tasks, users may hesitate to rely on LLMs when personal style is important. Post-editing LLM-generated drafts or translations is a common collaborative writing strategy, but it remains unclear whether users can effectively reshape LLM-generated text to reflect their personal style. We conduct a pre-registered online study ($n=81$) in which participants post-edit LLM-generated drafts for writing tasks where personal style matters to them. Using embedding-based style similarity metrics, we find that post-editing increases stylistic similarity to participants' unassisted writing and reduces similarity to fully LLM-generated output. However, post-edited text still remains stylistically closer in style to LLM text than to participants' unassisted control text, and it exhibits reduced stylistic diversity compared to unassisted human text. We find a gap between perceived stylistic authenticity and model-measured stylistic similarity, with post-edited text often perceived as representative of participants' personal style despite remaining detectable LLM stylistic traces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports results from a pre-registered online study (n=81) in which participants post-edit LLM-generated drafts on writing tasks where personal style is salient. Using standard sentence-embedding cosine similarities, the authors conclude that post-editing increases stylistic similarity to participants' unassisted writing and decreases similarity to fully LLM-generated text, yet post-edited output remains closer to LLM style than to human control text and shows lower stylistic diversity; they additionally document a gap between participants' perceptions of authenticity and the embedding-based measurements.
Significance. If the embedding metrics are shown to track human-perceived personal style, the work supplies useful empirical bounds on what post-editing can achieve in stylistically sensitive domains and highlights a persistent LLM trace that users may not notice. The pre-registered design with explicit human controls is a clear methodological strength that supports reproducibility and direct comparison.
major comments (1)
- [§5] §5 (Results) and the embedding analysis: the central quantitative claims—that post-edited text is still closer to LLM output than to unassisted human text and exhibits reduced diversity—rest entirely on cosine similarities in sentence embeddings. No correlation is reported between these distances and human pairwise style-similarity ratings collected on the same texts, leaving open the possibility that the metric is sensitive to topic, length, or fluency confounds rather than the intended personal stylistic features.
minor comments (2)
- [Abstract and §5] The abstract and §5 could report the exact statistical tests, effect sizes, and p-values supporting the similarity and diversity comparisons rather than qualitative descriptions alone.
- [Figures] Figure captions and axis labels for the embedding similarity plots should explicitly state the embedding model and preprocessing steps used to compute the reported cosines.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for recognizing the strengths of our pre-registered design with human controls. We address the single major comment below regarding validation of the embedding metrics.
read point-by-point responses
-
Referee: [§5] §5 (Results) and the embedding analysis: the central quantitative claims—that post-edited text is still closer to LLM output than to unassisted human text and exhibits reduced diversity—rest entirely on cosine similarities in sentence embeddings. No correlation is reported between these distances and human pairwise style-similarity ratings collected on the same texts, leaving open the possibility that the metric is sensitive to topic, length, or fluency confounds rather than the intended personal stylistic features.
Authors: We appreciate this observation on metric validation. Our study collected participants' self-reported ratings of perceived stylistic authenticity for the post-edited outputs (as noted in the abstract and §5), but we did not collect pairwise human style-similarity judgments between texts. Consequently, we cannot compute or report a correlation between embedding distances and such pairwise ratings. We selected sentence embeddings (Sentence-BERT) as they are standard in the field for isolating stylistic features while being relatively robust to topical content; our task prompts were designed to hold topic roughly constant while emphasizing personal voice, and post-editing naturally affects fluency and length in ways that we report descriptively. We acknowledge that residual confounds remain possible without direct human correlation data. In revision we will expand the Discussion to (a) cite prior validation studies of embeddings for style, (b) explicitly note the absence of pairwise human ratings as a limitation, and (c) highlight the observed divergence between authenticity perceptions and embedding distances as evidence that the metric is capturing LLM traces not fully aligned with human self-perception. These additions will be made to §5 and the Discussion without new data collection. revision: partial
- We cannot report a correlation between embedding distances and human pairwise style-similarity ratings because such pairwise ratings were not collected in the study.
Circularity Check
No significant circularity: purely empirical measurement study
full rationale
The paper reports results from a pre-registered online study (n=81) that directly measures stylistic similarity via embedding-based metrics on post-edited, LLM-generated, and unassisted human texts. No derivations, equations, fitted parameters, or self-citation chains are invoked to support the central claims; the findings are straightforward empirical comparisons of cosine similarities and diversity statistics computed on the collected data. The analysis is self-contained against external benchmarks (participant texts) without any reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Embedding-based similarity metrics capture meaningful aspects of personal writing style
- domain assumption The writing tasks chosen elicit stable personal style that can be compared across conditions
Forward citations
Cited by 1 Pith paper
-
Beating the Style Detector: Three Hours of Agentic Research on the AI-Text Arms Race
Agentic reproduction of an NLP study recovers original findings and demonstrates that GPT-5.5 and Claude Opus can reduce their AI-detection probability by shrinking detector margins through 20 feedback iterations.
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 34855–34880, Suzhou, China
Leveraging multilingual training for author- ship representation: Enhancing generalization across languages and domains. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 34855–34880, Suzhou, China. Association for Computational Linguistics. Kevin Knight and Ishwar Chander. 1994. Automated postediting of docum...
2025
-
[2]
John Morris, Eli Lifland, Jin Yong Yoo, Jake Grigsby, Di Jin, and Yanjun Qi
The widespread adoption of large language model-assisted writing across society.Patterns, 6(12):101366. John Morris, Eli Lifland, Jin Yong Yoo, Jake Grigsby, Di Jin, and Yanjun Qi. 2020. TextAttack: A frame- work for adversarial attacks, data augmentation, and adversarial training in NLP. InProceedings of the 2020 Conference on Empirical Methods in Natu- ...
-
[3]
InProceedings of the 63rd Annual Meeting of the Association for Computational Lin- guistics (V olume 1: Long Papers), pages 5342–5373, Vienna, Austria
People who frequently use ChatGPT for writ- ing tasks are accurate and robust detectors of AI- generated text. InProceedings of the 63rd Annual Meeting of the Association for Computational Lin- guistics (V olume 1: Long Papers), pages 5342–5373, Vienna, Austria. Association for Computational Lin- guistics. Chantal Shaib, Yanai Elazar, Junyi Jessy Li, and ...
2024
-
[4]
Style transfer for texts: Retrain, report er- rors, compare with rewrites. InProceedings of the 2019 Conference on Empirical Methods in Natu- ral Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3936–3945, Hong Kong, China. Association for Computational Linguistics. Alex Warstadt, Amanpree...
-
[5]
generic” or “default
Same author or just same topic? towards content-independent style representations. InPro- ceedings of the 7th Workshop on Representation Learning for NLP, pages 249–268, Dublin, Ireland. Association for Computational Linguistics. Jiaxin Wen, Ruiqi Zhong, Akbir Khan, Ethan Perez, Jacob Steinhardt, Minlie Huang, Samuel R. Bowman, He He, and Shi Feng. 2025. ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.