Recognition: unknown
On the Footprints of Reviewer Bots Feedback on Agentic Pull Requests in OSS GitHub Repositories
Pith reviewed 2026-05-08 03:13 UTC · model grok-4.3
The pith
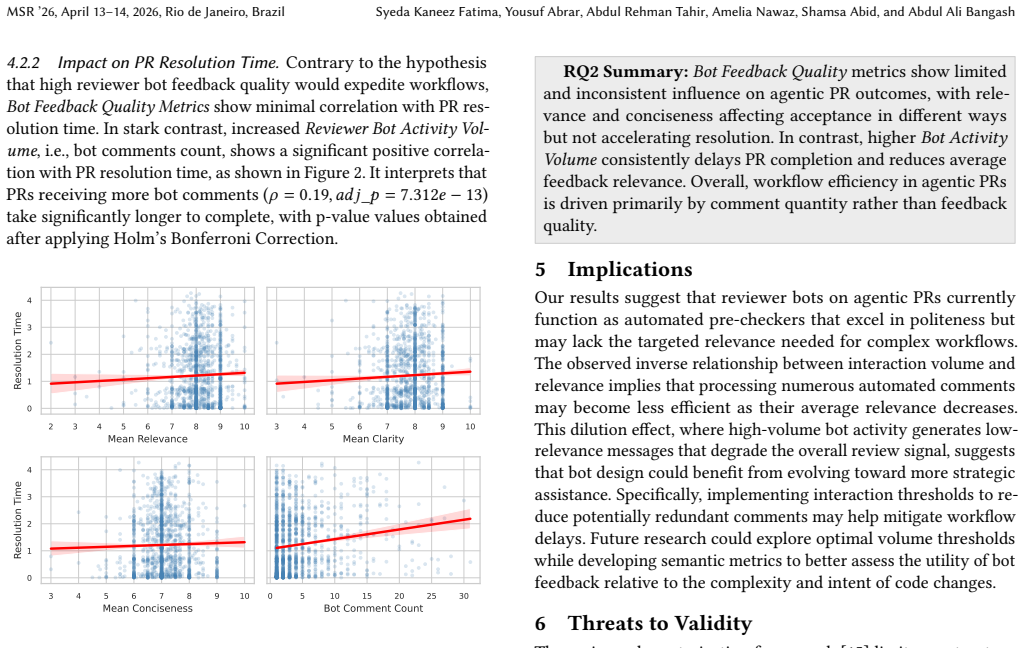
Reviewer bot comment volume in agentic pull requests links to longer resolution times without improving outcomes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Analysis of reviewer-bot comments on agentic pull requests shows that these comments focus primarily on bug fixes, testing, and documentation, maintain a civil and prescriptive tone, and deliver clear and concise language overall, though their semantic relevance to the underlying code changes remains moderate. Higher reviewer bot activity volume associates with longer PR resolution times and reduced average feedback quality, while reviewer bot feedback quality exhibits no meaningful association with PR acceptance or resolution time.
What carries the argument
Reviewer Bot Feedback Quality (relevance, clarity, conciseness) and Reviewer Bot Activity Volume (comment count) as factors associated with PR acceptance and resolution time.
If this is right
- Higher volumes of reviewer bot comments associate with longer PR resolution times.
- Greater comment volume tends to reduce the average relevance of the feedback provided.
- Reviewer bot feedback quality shows no substantial link to PR acceptance rates.
- Reviewer bot feedback quality shows no substantial link to PR resolution speed.
- Reviewer bots direct most attention to bug fixes, testing, and documentation.
Where Pith is reading between the lines
- Bots that generate reviewer comments could incorporate checks to cap volume once relevance thresholds are met.
- The pattern may extend to human reviewers working alongside agentic contributions, favoring depth over breadth.
- Different categories of code changes could be examined to see whether the volume-quality tradeoff holds uniformly.
- Acceptance decisions in these workflows may depend more on observable code properties than on review comment traits.
Load-bearing premise
The analysis assumes the collected set of agentic pull requests and reviewer comments forms a broad representative sample and that the defined metrics for quality and volume accurately reflect the intended constructs.
What would settle it
A replication on a fresh collection of agentic pull requests that uses alternate measures of comment relevance and finds a clear positive link between feedback quality and faster PR acceptance or resolution.
Figures


read the original abstract
Autonomous coding agents are reshaping software development by creating pull requests (PRs) on GitHub, referred to as agentic PRs. In parallel, the review process is also becoming autonomous, thereby making reviewer bots key actors in the assessment of these agentic PRs. However, their influence on PR acceptance and resolution remains unclear. This study empirically investigates the relationship between reviewer-bot feedback and PR outcomes by analyzing how Reviewer Bot Feedback Quality (relevance, clarity, conciseness) and Reviewer Bot Activity Volume (comment count) are associated with PR acceptance and resolution time. We analyze 7,416 reviewer-bot comments on 4,532 PRs from the AI_Dev dataset (a dataset that captured AI agents' PRs in GitHub projects). Our results show that reviewer-bot comments mainly focus on bug fixes, testing, and documentation, are civil in tone, and are prescriptive in nature. Reviewer bots generally produce clear and concise feedback, though the semantic relevance of comments to underlying code changes is moderate. We find that higher Reviewer Bot Activity volume is associated with longer PR resolution times and lower average feedback quality, showing that as bots generate more comments on a PR, the average pertinence of that feedback appears to degrade. At the same time, Reviewer Bot Feedback Quality shows no meaningful association with workflow outcomes. Our findings suggest that, in agentic PR workflows, reviewer bots should prioritize targeted high-relevance feedback over generating large numbers of comments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical analysis of reviewer bot feedback on 4,532 agentic pull requests (PRs) from the AI_Dev dataset, encompassing 7,416 comments. It examines associations between reviewer bot feedback quality (measured by relevance, clarity, and conciseness) and activity volume (comment count) with PR acceptance rates and resolution times. The study finds that bot comments focus on bug fixes, testing, and documentation; are generally civil, prescriptive, clear, and concise but only moderately relevant. Higher comment volume correlates with longer resolution times and reduced average feedback quality, while quality metrics show no association with acceptance or resolution outcomes. The authors conclude that reviewer bots should prioritize targeted, high-relevance feedback over high-volume commenting.
Significance. If the reported associations are robust to controls for PR complexity and other confounders, the findings could have practical implications for designing more effective reviewer bots in open-source software development involving autonomous agents. The use of a large, real-world dataset from GitHub provides a valuable empirical basis for understanding bot behaviors in agentic workflows, which is a growing area in software engineering.
major comments (3)
- [Results (empirical analysis of activity volume and outcomes)] The reported association between higher Reviewer Bot Activity Volume and longer PR resolution times does not account for potential confounding factors such as PR complexity (e.g., number of files changed, lines of code modified, or commit count). Without such controls, it is unclear whether increased comment volume causes delays or if more complex PRs naturally attract more comments and take longer to resolve. This undermines the prescriptive recommendation that bots should prioritize targeted feedback over volume.
- [Methods or Analysis section] The manuscript lacks details on the statistical methods used to evaluate the associations, including any regression models, controls, significance testing, or handling of potential selection biases in the AI_Dev dataset. This makes it difficult to assess the reliability and generalizability of the findings regarding feedback quality and outcomes.
- [Discussion or Conclusion] The suggestion that 'reviewer bots should prioritize targeted high-relevance feedback over generating large numbers of comments' implies a causal relationship that the observational data does not establish. The paper should either provide evidence for causality (e.g., via additional analyses) or reframe the conclusion as an association-based recommendation with explicit caveats about alternative explanations.
minor comments (2)
- [Abstract] The abstract could more clearly distinguish between observed associations and the suggested implications for bot design.
- [Throughout (methods and results)] Ensure that all metrics (relevance, clarity, conciseness) are precisely defined with examples or inter-rater reliability measures if manually annotated.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, acknowledging limitations where appropriate and outlining specific revisions to strengthen the manuscript's methodological transparency and interpretive caution.
read point-by-point responses
-
Referee: The reported association between higher Reviewer Bot Activity Volume and longer PR resolution times does not account for potential confounding factors such as PR complexity (e.g., number of files changed, lines of code modified, or commit count). Without such controls, it is unclear whether increased comment volume causes delays or if more complex PRs naturally attract more comments and take longer to resolve. This undermines the prescriptive recommendation that bots should prioritize targeted feedback over volume.
Authors: We agree this is a substantive limitation of the current analysis, which reports unadjusted associations. In the revision we will add multivariate regression models controlling for PR complexity using available GitHub metadata (files changed, lines modified, and commit count). Updated results will be presented with these controls, and we will qualify the discussion of activity volume accordingly. This directly addresses the concern and bolsters the robustness of the reported associations. revision: yes
-
Referee: The manuscript lacks details on the statistical methods used to evaluate the associations, including any regression models, controls, significance testing, or handling of potential selection biases in the AI_Dev dataset. This makes it difficult to assess the reliability and generalizability of the findings regarding feedback quality and outcomes.
Authors: We acknowledge the need for greater methodological transparency. The revised Methods section will explicitly describe the statistical procedures (including any correlation or regression techniques employed), variable definitions, significance testing approach, confidence intervals, and steps taken to mitigate selection effects in the AI_Dev dataset (e.g., inclusion criteria and robustness checks). These additions will enable readers to evaluate the analyses more fully. revision: yes
-
Referee: The suggestion that 'reviewer bots should prioritize targeted high-relevance feedback over generating large numbers of comments' implies a causal relationship that the observational data does not establish. The paper should either provide evidence for causality (e.g., via additional analyses) or reframe the conclusion as an association-based recommendation with explicit caveats about alternative explanations.
Authors: Our study is strictly observational and reports associations only; we do not claim or test causality. We will revise the Discussion and Conclusion to reframe all recommendations explicitly as association-based, add explicit caveats about alternative explanations (including PR complexity), and insert a dedicated limitations paragraph. No causal identification strategy is feasible with the current data, but the reframing will align the language precisely with the evidence presented. revision: yes
Circularity Check
No circularity: purely observational empirical analysis
full rationale
This paper contains no mathematical derivations, equations, fitted parameters, or predictive models that could reduce to inputs by construction. All findings are direct statistical associations computed from the external AI_Dev dataset of 7,416 comments on 4,532 PRs. The central suggestion that bots should prioritize targeted feedback follows from reported correlations between comment volume and resolution time/quality, without any self-definitional loops, self-citation load-bearing premises, or renaming of known results. The analysis is self-contained against external benchmarks and exhibits none of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The AI_Dev dataset accurately represents agentic PRs and associated reviewer bot feedback in OSS GitHub repositories.
Reference graph
Works this paper leans on
-
[1]
Amiangshu Bosu, Michaela Greiler, and Christian Bird. 2015. Characteristics of Useful Code Reviews: An Empirical Study at Microsoft. In2015 IEEE/ACM 12th Working Conference on Mining Software Repositories. 146–156. doi:10.1109/MSR. 2015.21
work page doi:10.1109/msr 2015
- [2]
-
[3]
Jacob Cohen. 1960. A Coefficient of Agreement for Nominal Scales.Ed- ucational and Psychological Measurement20, 1 (1960), 37–46. doi:10.1177/ 001316446002000104
1960
- [4]
- [5]
-
[6]
doi: 10.1007/978-1-4419-9863-7_1214
Winston Haynes. 2013.Holm’s Method. Springer New York, New York, NY, 902–902. doi:10.1007/978-1-4419-9863-7_1214
-
[7]
SayedHassan Khatoonabadi, Ahmad Abdellatif, Diego Elias Costa, and Emad Shihab. 2024. Predicting the First Response Latency of Maintainers and Contrib- utors in Pull Requests.IEEE Transactions on Software Engineering50, 10 (2024), 2529–2543. doi:10.1109/TSE.2024.3443741
-
[8]
Klaus Krippendorff. 1970. Estimating the Reliability, Systematic Error and Ran- dom Error of Interval Data.Educational and Psychological Measurement30, 1 (1970), 61–70. doi:10.1177/001316447003000105
-
[9]
J Richard Landis and Gary G. Koch. 1977. The measurement of observer agreement for categorical data.Biometrics33 1 (1977), 159–74. https://api.semanticscholar. org/CorpusID:11077516
1977
-
[10]
Hao Li, Haoxiang Zhang, and Ahmed E. Hassan. 2025. The Rise of AI Teammates in Software Engineering (SE) 3.0: How Autonomous Coding Agents Are Reshap- ing Software Engineering. arXiv:2507.15003 [cs.SE] https://arxiv.org/abs/2507. 15003
work page internal anchor Pith review arXiv 2025
-
[11]
Zhiyu Li, Shuai Lu, Daya Guo, Nan Duan, Shailesh Jannu, Grant Jenks, Deep Majumder, Jared Green, Alexey Svyatkovskiy, Shengyu Fu, and Neel Sundare- san. 2022. Automating Code Review Activities by Large-Scale Pre-training. arXiv:2203.09095 [cs.SE] https://arxiv.org/abs/2203.09095
-
[12]
Mann and Douglas R
Henry B. Mann and Douglas R. Whitney. 1947. On a Test of Whether one of Two Random Variables is Stochastically Larger than the Other.Annals of Mathematical Statistics18 (1947), 50–60. https://api.semanticscholar.org/CorpusID:14328772
1947
- [13]
- [14]
-
[15]
Oussama Ben Sghaier, Martin Weyssow, and Houari Sahraoui. 2025. Harnessing Large Language Models for Curated Code Reviews. In2025 IEEE/ACM 22nd International Conference on Mining Software Repositories (MSR). IEEE, 187–198
2025
-
[16]
C Spearman. 2010. The proof and measurement of association between two things.International Journal of Epidemiology39, 5 (10 2010), 1137–1150. arXiv:https://academic.oup.com/ije/article-pdf/39/5/1137/18481215/dyq191.pdf doi:10.1093/ije/dyq191
-
[17]
Kexin Sun, Hongyu Kuang, Sebastian Baltes, Xin Zhou, He Zhang, Xiaoxing Ma, Guoping Rong, Dong Shao, and Christoph Treude. 2025. Does AI Code Review Lead to Code Changes? A Case Study of GitHub Actions.arXiv preprint arXiv:2508.18771(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Abdul Rehman Tahir and Syeda Kaneez Fatima. 2025. On the Footprints of Reviewer Bots Feedback on Agentic Pull Requests in OSS GitHub Repositories. doi:10.5281/zenodo.17866386
-
[19]
Rosalia Tufano, Ozren Dabić, Antonio Mastropaolo, Matteo Ciniselli, and Gabriele Bavota. 2024. Code Review Automation: Strengths and Weaknesses of the State of the Art.IEEE Transactions on Software Engineering50, 2 (2024), 338–353. doi:10.1109/TSE.2023.3348172
- [20]
-
[21]
Mairieli Wessel, Alexander Serebrenik, Igor Wiese, Igor Steinmacher, and Marco A. Gerosa. 2020. Effects of Adopting Code Review Bots on Pull Requests to OSS Projects. In2020 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 1–11. doi:10.1109/ICSME46990.2020.00011
-
[22]
Mairieli Wessel, Alexander Serebrenik, Igor Wiese, Igor Steinmacher, and Marco A. Gerosa. 2020. What to Expect from Code Review Bots on GitHub? A Survey with OSS Maintainers. InProceedings of the XXXIV Brazilian Symposium on Software Engineering(Natal, Brazil)(SBES ’20). Association for Computing Machinery, New York, NY, USA, 457–462. doi:10.1145/3422392.3422459
-
[23]
Mairieli Wessel, Alexander Serebrenik, Igor Wiese, Igor Steinmacher, and Marco A. Gerosa. 2022. Quality gatekeepers: investigating the effects of code re- view bots on pull request activities. 27, 5 (2022). doi:10.1007/s10664-022-10130-9
-
[24]
Ratnadira Widyasari, Ting Zhang, Abir Bouraffa, Walid Maalej, and David Lo
-
[25]
https://arxiv.org/abs/2311.09020
Explaining Explanations: An Empirical Study of Explanations in Code Reviews.arXiv preprint arXiv:2311.09020(2024). https://arxiv.org/abs/2311.09020
-
[26]
Antonia Zapf, Stefanie Castell, Lars Morawietz, and André Karch. 2016. Measur- ing inter-rater reliability for nominal data - Which coefficients and confidence intervals are appropriate?BMC Medical Research Methodology16 (08 2016). doi:10.1186/s12874-016-0200-9
- [27]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.