Recognition: unknown
Heterogeneous-Horizon Exact-Weight Local SGD
Pith reviewed 2026-05-08 02:33 UTC · model grok-4.3
The pith
HEW-Local SGD selects nodewise server weights by minimizing an explicit one-round upper bound on the next objective value.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HEW-Local SGD is a corrected local-SGD method that chooses nodewise server weights by minimizing an explicit one-round upper bound on the next objective value. This yields an exact local-control formulation with a threshold simplex update, separable amplitude updates, and a one-step guarantee under arbitrary predictable participation. Two post-local variants are introduced: a corrected heterogeneous method and a simpler homogeneous specialization. One-step guarantees and global benchmark-style convergence results are established; in regimes where comparison is possible the theory matches the qualitative communication-efficient picture of recent LocalSGD/SCAFFOLD analyses while supplying the
What carries the argument
Weight selection obtained by minimizing an explicit one-round upper bound on the objective, which produces a threshold simplex update and separable amplitude updates that together give exact local control.
If this is right
- One-step decrease guarantees hold under arbitrary but predictable participation.
- Explicit convergence rates are obtained for heterogeneous local horizons, minibatch sizes, and gradient noise.
- The qualitative communication-efficiency picture of LocalSGD and SCAFFOLD is recovered in the homogeneous regime.
- Post-local corrected variants provide both a fully heterogeneous and a homogeneous specialization.
Where Pith is reading between the lines
- The local-control structure may allow each node to compute its own weight contribution with only a single extra scalar exchange per round.
- The same bounding technique could be tested in non-convex regimes if a suitable surrogate upper bound can be derived.
- Participation predictability could be relaxed by replacing the deterministic guarantee with a high-probability statement that absorbs occasional mispredictions.
Load-bearing premise
The one-round upper bound on the objective can be formed and minimized from local gradient information and noise statistics alone, and participation patterns remain predictable enough for the one-step guarantee to hold.
What would settle it
An experiment on a simple convex quadratic where the measured objective after one round exceeds the minimized upper bound despite using the prescribed weights and reported noise statistics.
Figures


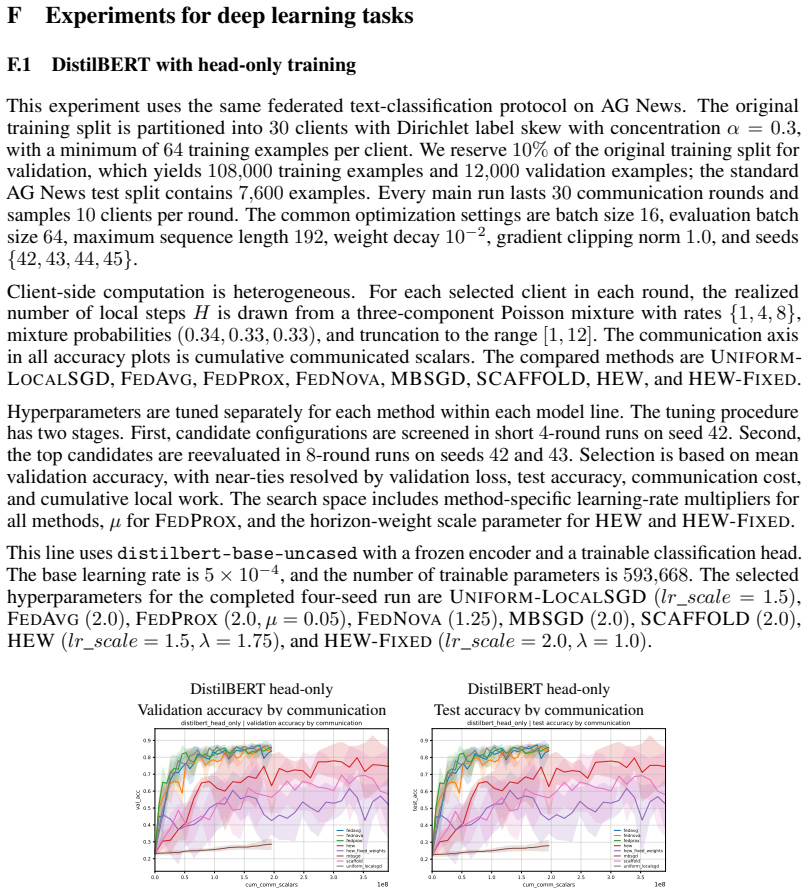

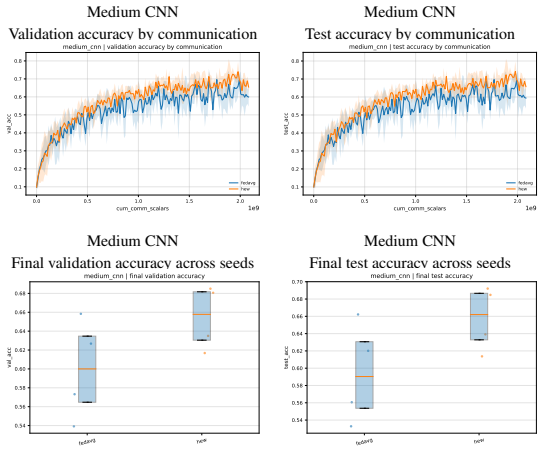
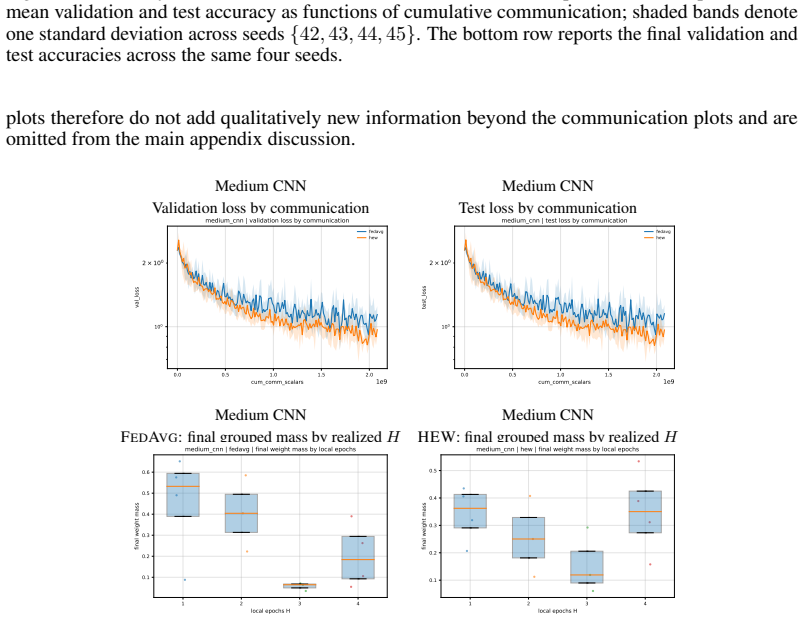
read the original abstract
We study adaptive aggregation for heterogeneous local SGD in convex finite-sum optimization, allowing heterogeneous local horizons, minibatch sizes, gradient noise, and participation. We introduce HEW-Local SGD, a corrected local-SGD method that chooses nodewise server weights by minimizing an explicit one-round upper bound on the next objective value. This yields an exact local-control formulation with a threshold simplex update, separable amplitude updates, and a one-step guarantee under arbitrary predictable participation. We also introduce two post-local variants: a corrected heterogeneous method and a simpler homogeneous specialization. We establish one-step guarantees and global benchmark-style convergence results. In the regimes where comparison is appropriate, the theory matches the qualitative communication-efficient picture of recent LocalSGD/SCAFFOLD analyses, while also giving explicit guarantees for unequal local horizons.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HEW-Local SGD for adaptive aggregation in heterogeneous local SGD applied to convex finite-sum optimization. Nodewise server weights are chosen by minimizing an explicit one-round upper bound on the subsequent objective value, producing a threshold simplex update for the weights together with separable amplitude updates. The method yields a one-step guarantee that holds under arbitrary but predictable participation patterns, heterogeneous local horizons, minibatch sizes, and gradient noise. Two post-local variants are also defined (a corrected heterogeneous version and a homogeneous specialization). One-step guarantees and global convergence rates are established; in regimes where comparison is possible, the rates recover the qualitative communication-efficiency picture of prior LocalSGD/SCAFFOLD analyses while supplying explicit bounds for unequal horizons.
Significance. If the derivations hold, the work supplies a principled, exact-weight mechanism for handling heterogeneity in local SGD that avoids post-hoc parameter fitting. The direct construction of the one-round upper bound, its minimization, and the resulting one-step guarantee constitute a clean theoretical contribution; the global rates follow by standard summation and accommodate heterogeneous horizons without circularity. This extends the existing literature by giving explicit, non-asymptotic guarantees under the stated participation and noise assumptions.
minor comments (3)
- [§3.2] §3.2, the statement of the threshold simplex update: the normalization step after the threshold operation is described only in prose; an explicit formula or pseudocode line would remove ambiguity about how the simplex constraint is enforced when some amplitudes are zeroed.
- [Theorem 5] Theorem 5 (global convergence): the dependence of the leading constant on the maximum local horizon H_max is stated but not compared numerically to the homogeneous case; a short remark or table entry illustrating the degradation for H_max ≫ H_min would help readers assess practical impact.
- [Assumption 2] The noise-variance assumption (Assumption 2) is used to form the one-round bound, yet the paper does not discuss how the variances are obtained or estimated from local data; a brief paragraph on this point would clarify the method’s implementability.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of our work on HEW-Local SGD, including its exact-weight adaptive aggregation, one-step guarantees under heterogeneous participation and horizons, and the resulting convergence rates. The recommendation for minor revision is noted; since no specific major comments were raised, we will incorporate any minor clarifications or presentation improvements in the revised version.
Circularity Check
No significant circularity; derivation self-contained
full rationale
The central construction minimizes an explicit one-round upper bound on the next objective value to select nodewise weights, directly yielding the threshold simplex update and separable amplitude updates. The one-step guarantee is obtained by substituting the minimized bound into the objective decrease inequality under the stated assumptions (known noise statistics, predictable participation). Global convergence follows by standard telescoping summation over heterogeneous horizons, without any reduction to fitted parameters, self-referential definitions, or load-bearing self-citations. No step equates a prediction to its own input by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The optimization problem is convex and finite-sum.
- domain assumption A one-round upper bound on the objective can be written explicitly in terms of local gradients, noise, and participation.
Reference graph
Works this paper leans on
-
[1]
Edwin F. Beckenbach and Richard Bellman.Inequalities, volume 30 ofErgebnisse der Mathematik und ihrer Grenzgebiete. Neue Folge. Springer-Verlag, Berlin, 1961. doi: 10.1007/978-3-642-64971-4
-
[2]
Blackard, Denis J
Jock A. Blackard, Denis J. Dean, and Charles W. Anderson. Covertype data set, 1998. URL https://archive.ics.uci.edu/ml/datasets/covertype
1998
-
[3]
Local sgd: Unified theory and new efficient methods
Eduard Gorbunov, Filip Hanzely, and Peter Richtarik. Local sgd: Unified theory and new efficient methods. In Arindam Banerjee and Kenji Fukumizu, editors,Proceedings of the 24th International Conference on Artificial Intelligence and Statistics, volume 130 ofProceedings of Machine Learning Research, pages 3556–3564. PMLR, 2021
2021
-
[4]
SCAFFOLD: Stochastic controlled averaging for federated learning
Sai Praneeth Karimireddy, Satyen Kale, Mehryar Mohri, Sashank Reddi, Sebastian Stich, and Ananda Theertha Suresh. SCAFFOLD: Stochastic controlled averaging for federated learning. In Hal Daumé III and Aarti Singh, editors,Proceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 5132...
2020
-
[5]
Mnist handwritten digit database.ATT Labs [Online]
Yann LeCun, Corinna Cortes, and CJ Burges. Mnist handwritten digit database.ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist, 2, 2010
2010
-
[6]
Federated optimization in heterogeneous networks
Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ameet Talwalkar, and Virginia Smith. Federated optimization in heterogeneous networks. In I. Dhillon, D. Papailiopoulos, and V . Sze, editors,Proceedings of Machine Learning and Systems, volume 2, pages 429–450, 2020
2020
-
[7]
Stich, Samuel Horváth, and Martin Taká ˇc
Ruichen Luo, Sebastian U. Stich, Samuel Horváth, and Martin Taká ˇc. Revisiting localsgd and scaffold: Improved rates and missing analysis. In Yingzhen Li, Stephan Mandt, Shipra Agrawal, and Emtiyaz Khan, editors,Proceedings of the 28th International Conference on Artificial Intelligence and Statistics, volume 258 ofProceedings of Machine Learning Researc...
2025
-
[8]
Scaffold with stochastic gradients: New analysis with linear speed-up, 2025
Paul Mangold, Alain Durmus, Aymeric Dieuleveut, and Eric Moulines. Scaffold with stochastic gradients: New analysis with linear speed-up, 2025
2025
-
[9]
Communication-efficient learning of deep networks from decentralized data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. In Aarti Singh and Jerry Zhu, editors,Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, volume 54 ofProceedings of Machine Learning Research, pages 1273–1...
2017
-
[10]
Vincent Poor
Jianyu Wang, Qinghua Liu, Hao Liang, Gauri Joshi, and H. Vincent Poor. Tackling the objective inconsistency problem in heterogeneous federated optimization. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin, editors, Advances in Neural Information Processing Systems 33, 2020
2020
-
[11]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms.CoRR, abs/1708.07747, 2017. URL http:// arxiv.org. 10 A Scalar lemmas and deterministic caps Lemma A.1(Gradient-gap inequalities and deterministic cap).Under Assumption B.1, ft ≤R∥∇F(x t)∥,∥∇F(x t)∥2 ≥ f2 t R2 .(35) Moreover, for...
work page internal anchor Pith review arXiv 2017
-
[12]
Assumption E.8(Generator).Letφ θ : [0,∞)→[0,∞)satisfy: 1.φ θ ∈C([0,∞))∩C 2((0,∞)); 2.φ θ(0) = 0; 3.φ θ(s)>0for everys >0; 4.φ θ is convex on[0,∞)
all maps introduced below are Borel in all variables and continuous in the control variable. Assumption E.8(Generator).Letφ θ : [0,∞)→[0,∞)satisfy: 1.φ θ ∈C([0,∞))∩C 2((0,∞)); 2.φ θ(0) = 0; 3.φ θ(s)>0for everys >0; 4.φ θ is convex on[0,∞). Definition E.9(Scalar flow).Under Assumption E.8, for each s≥0 let v(·;s) be the unique global solution of ˙v(τ) =−φθ...
-
[13]
every weight subproblem is a strictly convex quadratic program with the closed-form KKT threshold law of Proposition B.36
-
[14]
for fixed weights w, the amplitude subproblem is separable across the nodes and reduces to independent one-dimensional convex minimizations
-
[15]
exact block-coordinate descent produces a monotonically nonincreasing sequence of objective values
-
[16]
every limit point is a coordinatewise minimum. Proof. Item (1) is Proposition B.36. For item (2), the objective decomposes as a sum of scalar coordinate functions because each µi and κi depends only on θi. It remains to prove convexity of the scalar block. In all local objectives used in the paper, the only non-polynomial part is −si(u;θ i), where si(u;θ ...
-
[17]
node i computes exactly Hi minibatch gradients of size bi and performs O(Hid) vector opera- tions
-
[18]
for fixed amplitudes, the exact weight subproblem is solved in O(St logS t) time by sorting the KKT thresholds; 67
-
[19]
for fixed weights, the amplitude block decomposes into St independent one-dimensional convex minimizations
-
[20]
Assume broadcast is available
one alternating local-control sweep has optimization overhead O(St logS t), plus the scalar accuracy cost of the amplitude solves, and server-side vector arithmeticO(S td). Assume broadcast is available. Then the total communication at a round with active set sizeS t is CommRound(St, d) = 2d+ 2dS t +S t +ν t,(153) where νt is the number of additional scal...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.