Recognition: unknown
Incisor: Ex Ante Cloud Instance Selection for HPC Jobs
Pith reviewed 2026-05-07 17:54 UTC · model grok-4.3
The pith
Incisor uses program analysis and frontier LLMs to select working AWS EC2 instances ex ante for 100% of first-time HPC runs of C/C++/Fortran and Python codes, cutting runtime 54% and costs 44% versus an expert-constrained SkyPilot baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using submission artifacts alone, Incisor atop frontier coding LLMs selects working AWS EC2 instances ex ante for 100% of first-time runs of source-compiled (C, C++, Fortran) and Python applications. Against a strong baseline combining expert-derived constraints with SkyPilot's instance selection, Incisor cuts job runtime by 54% and instance costs by 44%.
Load-bearing premise
That LLM-guided reasoning over program-analysis outputs can reliably infer hardware constraints and produce instance selections that are both correct and cost-effective without any runtime profiling or additional user-provided hints.
Figures




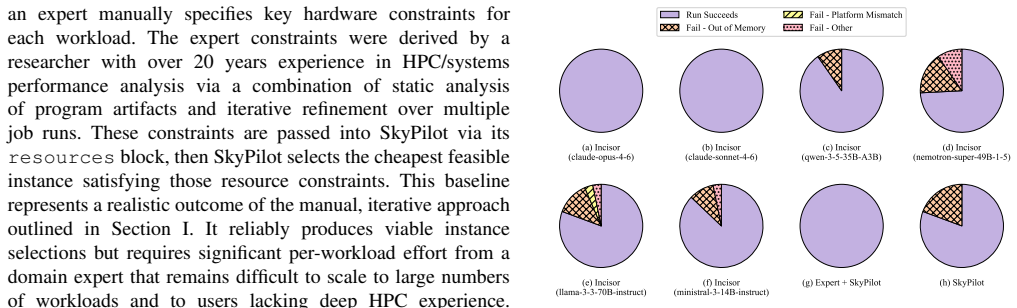


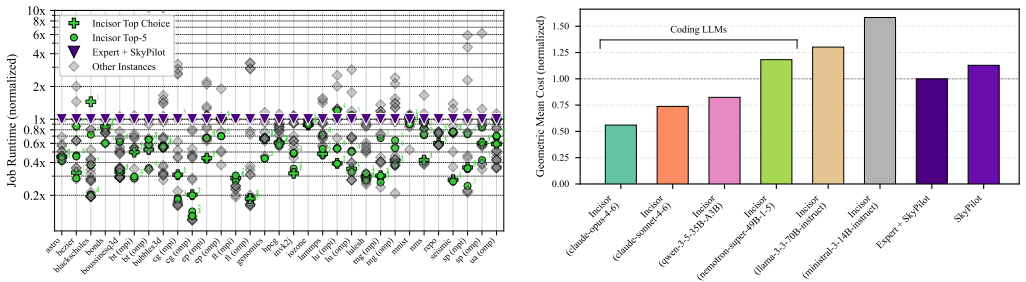
read the original abstract
We present Incisor, a cloud HPC job submission system for the ex ante instance selection problem: choosing suitable hardware in the challenging but common setting where only the executable, inputs, and invocation commands are available at submission time. In practice, this task is manual and expertise-intensive, requiring users to combine incomplete knowledge of rapidly evolving cloud offerings with workload-specific intuition, static analysis, and systems reasoning to infer hardware constraints and select an instance type for each job. Incisor automates this process by pairing widely available program analysis tools with LLM-guided reasoning to infer hardware requirements and choose cloud instances. Using submission artifacts alone, Incisor atop frontier coding LLMs selects working AWS EC2 instances ex ante for 100% of first-time runs of source-compiled (C, C++, Fortran) and Python applications. Against a strong baseline combining expert-derived constraints with SkyPilot's instance selection, Incisor cuts job runtime by 54% and instance costs by 44%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. Incisor is a system for ex ante cloud instance selection in HPC that pairs program analysis tools with LLM-guided reasoning to infer hardware requirements from only the executable, inputs, and invocation commands. The paper claims that Incisor atop frontier coding LLMs achieves 100% success in selecting working AWS EC2 instances for first-time runs of C/C++/Fortran and Python applications, while cutting runtime by 54% and costs by 44% versus a baseline of expert-derived constraints plus SkyPilot.
Significance. If the empirical results hold under rigorous validation, the work could meaningfully lower the expertise barrier for cloud HPC by automating instance selection. The combination of static analysis with LLM reasoning is a timely approach for systems that must operate without profiling or user hints. The reported gains indicate practical efficiency potential, but the current presentation leaves the robustness of the 100% success rate and percentage improvements difficult to assess.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation section: the headline claims of 100% success, 54% runtime reduction, and 44% cost reduction are presented without any description of the number of jobs, workload diversity, statistical significance testing, controls for instance availability, or LLM variability. This information is load-bearing for the central empirical contribution and must be supplied to allow readers to evaluate generalizability.
- [System Design] System design and assumption discussion: the approach rests on LLM reasoning over static program-analysis outputs being sufficient to deduce dynamic constraints such as peak memory, core scaling, or communication volume. The manuscript does not provide evidence or ablation that this inference step succeeds for input-dependent behaviors, which directly supports the 100% success claim and the reported gains over the SkyPilot baseline.
minor comments (1)
- [Abstract] The abstract would be strengthened by a single sentence stating the scale of the evaluation (e.g., number of distinct applications or total job runs) to give immediate context for the quantitative results.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We have revised the paper to address the concerns about the presentation of empirical claims and the discussion of key assumptions in the system design. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: the headline claims of 100% success, 54% runtime reduction, and 44% cost reduction are presented without any description of the number of jobs, workload diversity, statistical significance testing, controls for instance availability, or LLM variability. This information is load-bearing for the central empirical contribution and must be supplied to allow readers to evaluate generalizability.
Authors: We agree that these details are necessary for readers to properly evaluate the generalizability of our results. The original Evaluation section describes the individual applications and reports aggregate metrics but does not consolidate the requested information or include statistical tests. In the revised manuscript we have added a new 'Experimental Setup' subsection that supplies the number of jobs evaluated, workload diversity (including application domains and input variations), statistical significance testing for the reported runtime and cost improvements, controls for instance availability on AWS, and steps taken to account for LLM variability. We have also updated the abstract to briefly reference the scale of the evaluation. These changes directly respond to the comment. revision: yes
-
Referee: [System Design] System design and assumption discussion: the approach rests on LLM reasoning over static program-analysis outputs being sufficient to deduce dynamic constraints such as peak memory, core scaling, or communication volume. The manuscript does not provide evidence or ablation that this inference step succeeds for input-dependent behaviors, which directly supports the 100% success claim and the reported gains over the SkyPilot baseline.
Authors: We appreciate the referee highlighting this core assumption. Section 4 of the manuscript describes how the LLM is prompted with static-analysis outputs to reason about likely dynamic behaviors, including input-dependent ones, by leveraging common HPC code patterns. The 100% success rate is measured on workloads that include input variation, providing indirect support. We acknowledge the absence of a dedicated ablation isolating the LLM's contribution to input-dependent inference. In the revision we have expanded the System Design section with additional discussion and qualitative examples from our case studies showing how the LLM infers scaling from code structure. We note that a quantitative ablation would strengthen the claim further and list this as future work, but the current evidence from end-to-end results demonstrates the practical utility of the combined static-analysis plus LLM approach. revision: partial
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frontier coding LLMs can accurately translate program-analysis facts into hardware constraints and instance-type recommendations without runtime data.
Reference graph
Works this paper leans on
-
[1]
Predictive performance and scalabil- ity modeling of a large-scale application,
D. J. Kerbyson, H. J. Alme, A. Hoisie, F. Petrini, H. J. Wasserman, and M. Gittings, “Predictive performance and scalabil- ity modeling of a large-scale application,” inProceedings of the 2001 ACM/IEEE conference on Supercomputing, 2001, pp. 37–37, https://doi.org/10.1145/582034.582071
-
[2]
A framework for performance modeling and prediction,
A. Snavely, L. Carrington, N. Wolter, J. Labarta, R. Badia, and A. Purkayastha, “A framework for performance modeling and prediction,” inSC’02: Proceedings of the 2002 ACM/IEEE Conference on Supercomputing. IEEE, 2002, pp. 21–21, https://doi.org/10.1109/sc.2002.10004
-
[3]
An ap- proach to performance prediction for parallel applications,
E. Ipek, B. R. De Supinski, M. Schulz, and S. A. McKee, “An ap- proach to performance prediction for parallel applications,” inEuropean Conference on Parallel Processing. Springer, 2005, pp. 196–205, https://doi.org/10.1007/11549468 24
-
[4]
Roofline: an in- sightful visual performance model for multicore architectures,
S. Williams, A. Waterman, and D. Patterson, “Roofline: an in- sightful visual performance model for multicore architectures,”Com- munications of the ACM, vol. 52, no. 4, pp. 65–76, 2009, https://doi.org/10.1145/1498765.1498785
-
[5]
Using automated performance modeling to find scalability bugs in complex codes,
A. Calotoiu, T. Hoefler, M. Poke, and F. Wolf, “Using automated performance modeling to find scalability bugs in complex codes,” inProceedings of the International Conference on High Perfor- mance Computing, Networking, Storage and Analysis, 2013, pp. 1–12, https://doi.org/10.1145/2503210.2503277
-
[6]
Palm: Easing the burden of an- alytical performance modeling,
N. R. Tallent and A. Hoisie, “Palm: Easing the burden of an- alytical performance modeling,” inProceedings of the 28th ACM international conference on Supercomputing, 2014, pp. 221–230, https://doi.org/10.1145/2597652.2597683
-
[7]
Ernest: Efficient performance prediction for Large-Scale advanced analytics,
S. Venkataraman, Z. Yang, M. Franklin, B. Recht, and I. Stoica, “Ernest: Efficient performance prediction for Large-Scale advanced analytics,” in13th USENIX Symposium on Networked Systems Design and Im- plementation (NSDI 16). USENIX Association, 2016, pp. 363–378, https://dl.acm.org/doi/10.5555/2930611.2930635
-
[8]
Predicting workflow task execution time in the cloud using a two-stage machine learning approach,
T.-P. Pham, J. J. Durillo, and T. Fahringer, “Predicting workflow task execution time in the cloud using a two-stage machine learning approach,”IEEE Transactions on Cloud Computing, vol. 8, no. 1, pp. 256–268, 2017, https://doi.org/10.1109/TCC.2017.2732344
-
[9]
CherryPick: Adaptively unearthing the best cloud configura- tions for big data analytics,
O. Alipourfard, H. H. Liu, J. Chen, S. Venkataraman, M. Yu, and M. Zhang, “CherryPick: Adaptively unearthing the best cloud configura- tions for big data analytics,” in14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17). USENIX Association, 2017, pp. 469–482, https://dl.acm.org/doi/10.5555/3154630.3154669
-
[10]
Towards col- laborative continuous benchmarking for hpc,
O. Pearce, A. Scott, G. Becker, R. Haque, N. Hanford, S. Brink, D. Jacobsen, H. Poxon, J. Domke, and T. Gamblin, “Towards col- laborative continuous benchmarking for hpc,” inProceedings of the SC’23 Workshops of The International Conference on High Perfor- mance Computing, Network, Storage, and Analysis, 2023, pp. 627–635, https://doi.org/10.1145/3624062.3624135
-
[11]
Adviser: An intuitive multi-cloud platform for scientific and ml workflows,
S. Cheng, M. A. Laurenzano, B. Strauch, T. A. Ellis, K. Wadhwani, and D. A. B. Hyde, “Adviser: An intuitive multi-cloud platform for scientific and ml workflows,”arXiv preprint arXiv:2603.20941, 2026, https://doi.org/10.48550/arXiv.2603.20941
-
[12]
SkyPilot: An intercloud broker for sky computing,
Z. Yang, Z. Wu, M. Luo, W.-L. Chiang, R. Bhardwaj, W. Kwon, S. Zhuang, F. S. Luan, G. Mittal, S. Shenkeret al., “SkyPilot: An intercloud broker for sky computing,” in20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23). USENIX Association, 2023, pp. 437–455, https://www.usenix.org/conference/nsdi23/presentation/yang-zongheng
2023
-
[13]
The nas parallel bench- marks—summary and preliminary results,
D. H. Bailey, E. Barszcz, J. T. Barton, D. S. Browning, R. L. Carter, L. Dagum, R. A. Fatoohi, P. O. Frederickson, T. A. Lasinski, R. S. Schreiberet al., “The nas parallel bench- marks—summary and preliminary results,” inProceedings of the 1991 ACM/IEEE Conference on Supercomputing, 1991, pp. 158–165, https://doi.org/10.1145/125826.125925
-
[14]
Assisting static analysis with large language models: A chatgpt experiment,
H. Li, Y . Hao, Y . Zhai, and Z. Qian, “Assisting static analysis with large language models: A chatgpt experiment,” inProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 2023, pp. 2107–2111, https://doi.org/10.1145/3611643.3613078
-
[15]
The emergence of large language models in static anal- ysis: A first look through micro-benchmarks,
A. P. S. Venkatesh, S. Sabu, A. M. Mir, S. Reis, and E. Bod- den, “The emergence of large language models in static anal- ysis: A first look through micro-benchmarks,” inProceedings of the 2024 IEEE/ACM First International Conference on AI Foundation Models and Software Engineering, 2024, pp. 35–39, https://doi.org/10.1145/3650105.3652288
-
[16]
Interleaving static analysis and llm prompting,
P. J. Chapman, C. Rubio-Gonz ´alez, and A. V . Thakur, “Interleaving static analysis and llm prompting,” inProceedings of the 13th ACM SIGPLAN International Workshop on the State Of the Art in Program Analysis, 2024, pp. 9–17, https://doi.org/10.1145/3652588.3663317
-
[17]
Llmdfa: analyzing dataflow in code with large language models,
C. Wang, W. Zhang, Z. Su, X. Xu, X. Xie, and X. Zhang, “Llmdfa: analyzing dataflow in code with large language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 131 545–131 574, 2024, https://doi.org/10.52202/079017-4181
-
[18]
A contemporary sur- vey of large language model assisted program analysis,
J. Wang, T. Ni, W.-B. Lee, and Q. Zhao, “A contemporary sur- vey of large language model assisted program analysis,”Transac- tions on Artificial Intelligence, vol. 1, no. 1, pp. 105–129, 2025, https://doi.org/10.53941/tai.2025.100006
-
[19]
Can large language models predict parallel code performance?
G. Bolet, G. Georgakoudis, H. Menon, K. Parasyris, N. Hasabnis, H. Estes, K. Cameron, and G. Oren, “Can large language models predict parallel code performance?” inProceedings of the 34th International Symposium on High-Performance Parallel and Distributed Computing, 2025, pp. 1–6, https://doi.org/10.1145/3731545.3743645
-
[20]
Hpc-coder: Modeling parallel programs using large language mod- els,
D. Nichols, A. Marathe, H. Menon, T. Gamblin, and A. Bhatele, “Hpc-coder: Modeling parallel programs using large language mod- els,” inISC High Performance 2024 Research Paper Proceedings (39th International Conference). Prometeus GmbH, 2024, pp. 1–12, https://doi.org/10.23919/isc.2024.10528929
-
[21]
Do large language models understand performance optimization?
B. Cui, T. Ramesh, O. Hernandez, and K. Zhou, “Do large lan- guage models understand performance optimization?”arXiv preprint arXiv:2503.13772, 2025, https://doi.org/10.48550/arXiv.2503.13772
-
[22]
Llmperf: Gpu performance modeling meets large language models,
M.-K. Nguyen-Nhat, H. D. N. Do, H. T. Le, and T. T. Dao, “Llmperf: Gpu performance modeling meets large language models,” in2024 32nd International Conference on Modeling, Analysis and Simulation of Computer and Telecommunication Systems (MASCOTS). IEEE, 2024, pp. 1–8, https://doi.org/10.1109/mascots64422.2024.10786558
-
[23]
Llm-based cost-aware task scheduling for cloud computing sys- tems,
H. Pei, Y . Gu, Y . Sun, Q. Wang, C. Liu, X. Chen, and L. Cheng, “Llm-based cost-aware task scheduling for cloud computing sys- tems,”Journal of Cloud Computing, vol. 14, no. 1, p. 81, 2025, https://doi.org/10.1186/s13677-025-00822-0
-
[24]
Exploring cloud instance options for optimal performance-cost efficiency,
W. Maas and A. Lorenzon, “Exploring cloud instance options for optimal performance-cost efficiency,”Cluster Computing, vol. 28, no. 15, p. 984, 2025, https://doi.org/10.1007/s10586-025-05702-5
-
[25]
Investigating cloud instances to achieve optimal trade-offs between performance-cost efficiency,
W. Maas, F. Rossi, M. Caggiani, P. Navaux, and A. Lorenzon, “Investigating cloud instances to achieve optimal trade-offs between performance-cost efficiency,”Computing, vol. 107, no. 3, p. 82, 2025, https://doi.org/10.1007/s00607-025-01444-9
-
[26]
M. Kumar, G. Kaur, and P. S. Rana, “Robust evaluation of gpu compute instances for hpc and ai in the cloud: a topsis approach with sensitivity, bootstrapping, and non-parametric analysis,”Computing, vol. 106, no. 12, pp. 3987–4014, 2024, https://doi.org/10.1007/s00607-024- 01342-6
-
[27]
Evaluating hpc-style cpu performance and cost in virtualized cloud infras- tructures,
J. Tharwani, S. Aggarwal, and A. A. Purkayastha, “Evaluating hpc-style cpu performance and cost in virtualized cloud infras- tructures,” inSoutheastCon 2025. IEEE, 2025, pp. 1239–1244, https://doi.org/10.1109/southeastcon56624.2025.10971705
-
[28]
Adap- tive computing on the grid using apples,
F. Berman, R. Wolski, H. Casanova, W. Cirne, H. Dail, M. Faer- man, S. Figueira, J. Hayes, G. Obertelli, J. Schopfet al., “Adap- tive computing on the grid using apples,”IEEE transactions on Par- allel and Distributed Systems, vol. 14, no. 4, pp. 369–382, 2003, https://doi.org/10.1109/tpds.2003.1195409
-
[29]
B. Bethwaite, D. Abramson, F. Bohnert, S. Garic, C. Enticott, and T. Peachey, “Mixing grids and clouds: high-throughput science using the nimrod tool family,” inCloud computing: principles, systems and applications. Springer, 2010, pp. 219–237, https://doi.org/10.1007/978- 1-84996-241-4 13
-
[30]
A taxonomy and sur- vey of grid resource management systems for distributed computing,
K. Krauter, R. Buyya, and M. Maheswaran, “A taxonomy and sur- vey of grid resource management systems for distributed computing,” Software: Practice and Experience, vol. 32, no. 2, pp. 135–164, 2002, https://doi.org/10.1002/spe.432
-
[31]
The evolution of the pegasus workflow management software,
E. Deelman, K. Vahi, M. Rynge, R. Mayani, R. Ferreira da Silva, and G. Papadimitriou, “The evolution of the pegasus workflow management software,”Computing in Science & Engineering, vol. 21, no. 4, pp. 22– 36, 2019, https://doi.org/10.1109/MCSE.2019.2919690
-
[32]
Scientific workflows and clouds,
G. Juve and E. Deelman, “Scientific workflows and clouds,”XRDS: Crossroads, The ACM Magazine for Students, vol. 16, no. 3, pp. 14–18, 2010, https://doi.org/10.1145/1734160.1734166
-
[33]
Deadline based resource provisioning and scheduling algorithm for scientific workflows on clouds,
M. A. Rodriguez and R. Buyya, “Deadline based resource provisioning and scheduling algorithm for scientific workflows on clouds,”IEEE Transactions on Cloud Computing, vol. 2, no. 2, pp. 222–235, 2014, https://doi.org/10.1109/tcc.2014.2314655
-
[34]
arXiv preprint arXiv:2310.10634 , year=
T. Xie, F. Zhou, Z. Cheng, P. Shi, L. Weng, Y . Liu, T. J. Hua, J. Zhao, Q. Liu, C. Liuet al., “Openagents: An open platform for language agents in the wild,”arXiv preprint arXiv:2310.10634, 2023, https://doi.org/10.48550/arXiv.2310.10634
-
[35]
H. Yang, S. Yue, and Y . He, “Auto-gpt for online decision making: Benchmarks and additional opinions,”arXiv preprint arXiv:2306.02224, 2023, https://doi.org/10.48550/arXiv.2306.02224
-
[36]
Autoagents: A framework for automatic agent generation
G. Chen, S. Dong, Y . Shu, G. Zhang, J. Sesay, B. F. Karls- son, J. Fu, and Y . Shi, “Autoagents: A framework for auto- matic agent generation,”arXiv preprint arXiv:2309.17288, 2023, https://doi.org/10.48550/arXiv.2309.17288
-
[37]
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
P. Sahoo, A. K. Singh, S. Saha, V . Jain, S. Mondal, and A. Chadha, “A systematic survey of prompt engineering in large language models: Techniques and applications,”arXiv preprint arXiv:2402.07927, vol. 1, 2024, https://doi.org/10.48550/arXiv.2402.07927
work page internal anchor Pith review doi:10.48550/arxiv.2402.07927 2024
-
[38]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liuet al., “Autogen: Enabling next-gen llm applications via multi-agent conversations,” inFirst conference on language modeling, 2024, https://doi.org/10.48550/arXiv.2308.08155
-
[39]
G. W ¨olflein, D. Ferber, D. Truhn, O. Arandjelovic, and J. N. Kather, “Llm agents making agent tools,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 26 092–26 130, https://doi.org/10.18653/v1/2025.acl-long.1266
-
[40]
Evaluation and benchmark- ing of llm agents: A survey
M. Mohammadi, Y . Li, J. Lo, and W. Yip, “Evaluation and benchmarking of llm agents: A survey,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, 2025, pp. 6129–6139, https://doi.org/10.1145/3711896.3736570
-
[41]
Agent development kit (ADK),
Google, “Agent development kit (ADK),” 2025, framework for building, evaluating, and deploying AI agents. [Online]. Available: https://github.com/google/adk-python
2025
-
[42]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
D. Zhou, N. Sch ¨arli, L. Hou, J. Wei, N. Scales, X. Wang, D. Schuurmans, C. Cui, O. Bousquet, Q. Le, and E. Chi, “Least-to-most prompting enables complex reasoning in large language models,”arXiv preprint arXiv:2205.10625, 2022, https://doi.org/10.48550/arXiv.2205.10625
work page internal anchor Pith review doi:10.48550/arxiv.2205.10625 2022
-
[43]
ReAct: Synergizing Reasoning and Acting in Language Models
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” inThe eleventh international conference on learning representations, 2022, https://doi.org/10.48550/arXiv.2210.03629
work page internal anchor Pith review doi:10.48550/arxiv.2210.03629 2022
-
[44]
Angr-the next generation of binary analysis,
F. Wang and Y . Shoshitaishvili, “Angr-the next generation of binary analysis,” in2017 IEEE Cybersecurity Development (SecDev). IEEE, 2017, pp. 8–9, https://doi.org/10.1109/secdev.2017.14
-
[45]
Eagle and K
C. Eagle and K. Nance,The Ghidra Book: The Definitive Guide. no starch press, 2020, ISBN-13 978-1718501027
2020
-
[46]
Pycg: Practical call graph generation in python,
V . Salis, T. Sotiropoulos, P. Louridas, D. Spinellis, and D. Mitropoulos, “Pycg: Practical call graph generation in python,” in2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). IEEE, 2021, pp. 1646–1657, https://doi.org/10.1109/icse43902.2021.00146
-
[47]
Weisfeiler-lehman graph kernels,
N. Shervashidze, P. Schweitzer, E. J. Van Leeuwen, K. Mehlhorn, and K. M. Borgwardt, “Weisfeiler-lehman graph kernels,”Journal of Machine Learning Research, vol. 12, no. 77, pp. 2539–2561, 2011, https://dl.acm.org/doi/10.5555/1953048.2078187
-
[48]
Turnbull,Monitoring with Prometheus
J. Turnbull,Monitoring with Prometheus. Turnbull Press, 2018, ISBN- 13 978-0988820289
2018
-
[49]
Node exporter,
“Node exporter,” 2017, prometheus exporter for hardware and OS metrics exposed by *NIX kernels. [Online]. Available: https://github.com/prometheus/node exporter
2017
-
[50]
Nvidia gpu exporter,
“Nvidia gpu exporter,” 2021, nvidia GPU exporter for Prometheus. [On- line]. Available: https://github.com/utkuozdemir/nvidia gpu exporter
2021
-
[51]
InProceedings of the 29th Symposium on Operating Systems Principles (SOSP ’23)
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023, pp. 611–626, https://doi.org/10.1145/3600006.3613165
-
[52]
Hpcg benchmark technical specification,
M. A. Heroux, J. Dongarra, and P. Luszczek, “Hpcg benchmark technical specification,” Sandia National Laboratories (SNL-NM), Albuquerque, NM (United States), Tech. Rep., 2013, https://doi.org/10.2172/1113870
-
[53]
IOzone filesystem benchmark,
W. D. Norcott, “IOzone filesystem benchmark,” 2003, https://www.iozone.org/
2003
-
[54]
A benchmark suite for improving per- formance portability of the sycl programming model,
Z. Jin and J. S. Vetter, “A benchmark suite for improving per- formance portability of the sycl programming model,” in2023 IEEE International Symposium on Performance Analysis of Sys- tems and Software (ISPASS). IEEE, 2023, pp. 325–327, https://doi.org/10.1109/ISPASS57527.2023.00041
-
[55]
A. P. Thompson, H. M. Aktulga, R. Berger, D. S. Bolintineanu, W. M. Brown, P. S. Crozier, P. J. In’t Veld, A. Kohlmeyer, S. G. Moore, T. D. Nguyenet al., “Lammps-a flexible simulation tool for particle-based materials modeling at the atomic, meso, and continuum scales,”Computer physics communications, vol. 271, p. 108171, 2022, https://doi.org/10.1016/j.c...
-
[56]
Available: https://doi.org/10.2172/1090032
I. Karlin, J. Keasler, and J. R. Neely, “Lulesh 2.0 updates and changes,” Lawrence Livermore National Laboratory (LLNL), Livermore, CA (United States), Tech. Rep., 2013, https://doi.org/10.2172/1090032
-
[57]
Palabos: parallel lattice boltzmann solver,
J. Latt, O. Malaspinas, D. Kontaxakis, A. Parmigiani, D. La- grava, F. Brogi, M. B. Belgacem, Y . Thorimbert, S. Leclaire, S. Liet al., “Palabos: parallel lattice boltzmann solver,”Comput- ers & Mathematics with Applications, vol. 81, pp. 334–350, 2021, https://doi.org/10.1016/j.camwa.2020.03.022
-
[58]
Accelerating financial applications on the gpu,
S. Grauer-Gray, W. Killian, R. Searles, and J. Cavazos, “Accelerating financial applications on the gpu,” inProceedings of the 6th Workshop on General Purpose Processor Using Graphics Processing Units, 2013, pp. 127–136, https://dx.doi.org/10.1145/2458523.2458536
-
[59]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
N. Jain, K. Han, A. Gu, W.-D. Li, F. Yan, T. Zhang, S. Wang, A. Solar-Lezama, K. Sen, and I. Stoica, “Livecodebench: Holistic and contamination free evaluation of large language models for code,” in The Thirteenth International Conference on Learning Representations, 2025, https://doi.org/10.48550/arXiv.2403.07974
work page internal anchor Pith review doi:10.48550/arxiv.2403.07974 2025
-
[60]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
T. Y . Zhuo, M. C. Vu, J. Chim, H. Hu, W. Yu, R. Widyasari, I. N. B. Yusuf, H. Zhan, J. He, I. Paul, S. Brunner, C. Gong, J. Hoang, A. R. Zebaze, X. Hong, W.-D. Li, J. Kaddour, M. Xu, Z. Zhang, P. Yadav, N. Jain, A. Guet al., “Bigcodebench: Benchmarking code generation with diverse function calls and complex instructions,” inThe Thirteenth International C...
work page internal anchor Pith review doi:10.48550/arxiv.2406.15877 2025
-
[61]
How efficient is llm-generated code? a rigorous & high-standard benchmark,
R. Qiu, W. Zeng, J. Ezick, C. Lott, and H. Tong, “How efficient is llm-generated code? a rigorous & high-standard benchmark,” inThe Thirteenth International Conference on Learning Representations, 2025, https://doi.org/10.48550/arXiv.2406.06647
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.