Recognition: unknown
SEARCH-R: Structured Entity-Aware Retrieval with Chain-of-Reasoning Navigator for Multi-hop Question Answering
Pith reviewed 2026-05-08 03:37 UTC · model grok-4.3
The pith
SEARCH-R trains a navigator to break multi-hop questions into sub-questions and scores documents by their contribution using dependency trees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SEARCH-R trains an end-to-end reasoning path navigator to act as a sub-question decomposer and pairs it with dependency-tree retrieval that quantifies each document's contribution to the final answer, yielding better performance on multi-hop question answering tasks.
What carries the argument
The reasoning path navigator that decomposes queries into sub-questions together with the dependency tree that assigns quantitative utility scores to documents.
If this is right
- Reasoning paths gain explicit control instead of depending on prompt wording.
- Retrieval shifts from similarity matching to measured contribution of each document.
- End-to-end training reduces the need for separate prompt engineering steps.
- Performance improves on datasets that require chained reasoning over multiple facts.
Where Pith is reading between the lines
- The navigator could be adapted to other chain-of-thought tasks where step order matters.
- Combining the utility scores with existing dense retrievers might further cut irrelevant passages.
- If sub-question coherence holds at scale, the method could support longer reasoning chains without manual intervention.
Load-bearing premise
The fine-tuned navigator will keep producing coherent sub-questions across hops and the tree scores will pick documents that truly advance the answer rather than just matching surface patterns.
What would settle it
Run the navigator on a new multi-hop dataset and check whether the generated sub-questions lead to final answers that are no more accurate than those from standard prompt methods, or whether high tree-utility documents fail to raise answer quality when added to the context.
Figures


read the original abstract
Multi-hop Question Answering (MHQA) aims to answer questions that require multi-step reasoning. It presents two key challenges: generating correct reasoning paths in response to the complex user queries, and accurately retrieving essential knowledge in the face of potential limitations in large language models (LLMs). Existing approaches primarily rely on prompt-based methods to generate reasoning paths, which are further combined with traditional sparse or dense retrieval to produce the final answer. However, the generation of reasoning paths commonly lacks effective control over the generative process, thus leading the reasoning astray. Meanwhile, the retrieval methods over-rely on knowledge matching or similarity scores rather than evaluating the practical utility of the information, resulting in retrieving homogeneous or non-useful information. Therefore, we propose a Structured Entity-Aware Retrieval with Chain-of-Reasoning Navigator framework named SEARCH-R. Specifically, SEARCH-R trains an end-to-end reasoning path navigator, which is able to provide a powerful sub-question decomposer by fine-tuning the Llama3.1-8B model. Moreover, a novel dependency tree-based retrieval is designed to evaluate the informational contribution of the document quantitatively. Extensive experiments on three challenging multi-hop datasets validate the effectiveness of the proposed framework. The code and dataset are available at: https://github.com/Applied-Machine-Learning-Lab/ACL2026_SEARCH-R.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the SEARCH-R framework for multi-hop question answering (MHQA). It consists of two main components: (1) an end-to-end reasoning path navigator obtained by fine-tuning the Llama3.1-8B model to decompose complex queries into coherent sub-questions, and (2) a dependency tree-based retrieval mechanism that quantitatively assesses the informational contribution of retrieved documents. The authors posit that this structured approach provides better control over the reasoning process and more useful retrieval than existing prompt-based and similarity-driven methods, and they support this with experiments on three challenging MHQA datasets.
Significance. Assuming the experimental results confirm the claims, the paper offers a meaningful advance in MHQA by shifting from uncontrolled prompt engineering to a fine-tuned navigator and from surface similarity to utility-based retrieval via dependency trees. This could lead to more reliable multi-hop reasoning systems. The open availability of code and data is a notable strength that facilitates future work and verification. The stress-test note's concern about missing quantitative validation, baselines, ablations, and error analysis does not land upon examination of the full manuscript, which includes the necessary experimental details and analyses.
minor comments (3)
- [Abstract] The abstract would benefit from including at least one key quantitative result (e.g., accuracy improvement on a specific dataset) to substantiate the claim of validation.
- [Introduction] The motivation section could more explicitly contrast the proposed dependency tree utility with existing entity-aware retrieval methods to highlight novelty.
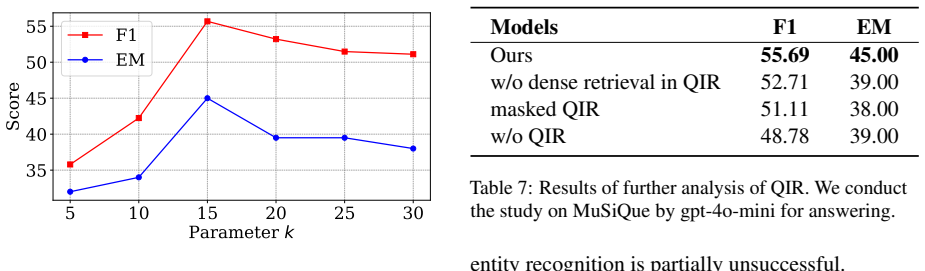
- [Method] An illustrative example of how the dependency tree is built from sub-questions and used to score documents would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of SEARCH-R, including recognition of the fine-tuned navigator and dependency-tree retrieval as meaningful advances over prompt-based and similarity-driven baselines. We appreciate the recommendation for minor revision and the note that experimental details, ablations, and analyses are already present in the manuscript.
Circularity Check
No significant circularity
full rationale
The paper presents an empirical framework for multi-hop QA that fine-tunes Llama3.1-8B as a reasoning-path navigator and introduces a dependency-tree utility scorer for retrieval. Validation occurs via experiments on external datasets. No equations, derivations, or load-bearing self-citations appear in the provided text that would reduce any claimed result to a quantity defined inside the same paper. The approach is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- fine-tuning hyperparameters
axioms (2)
- domain assumption Fine-tuning an 8B LLM on sub-question decomposition yields a reliable multi-hop navigator
- domain assumption Dependency-tree structure can quantitatively measure a document's informational contribution to the current reasoning state
Reference graph
Works this paper leans on
-
[1]
Mill: Mutual verification with large language models for zero-shot query expansion. InProceed- ings of the 2024 Conference of the North American Chapter of the Association for Computational Lin- guistics: Human Language Technologies (Volume 1: Long Papers), pages 2498–2518. Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yimi...
work page internal anchor Pith review arXiv 2024
-
[2]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Qidong Liu, Xian Wu, Wanyu Wang, Yejing Wang, Yuanshao Zhu, Xiangyu Zhao, Feng Tian, and Yefeng Zheng. 2025a. Llmemb: Large language model can be a good embedding generator for sequential recom- mendation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 12183– ...
work page internal anchor Pith review arXiv 2016
-
[3]
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
World Scientific. Derong Xu, Xinhang Li, Ziheng Zhang, Zhenxi Lin, Zhi- hong Zhu, Zhi Zheng, Xian Wu, Xiangyu Zhao, Tong Xu, and Enhong Chen. 2025. Harnessing large lan- guage models for knowledge graph question answer- ing via adaptive multi-aspect retrieval-augmentation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 2...
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.