Recognition: unknown
RACANet: Reliability-Aware Crowd Anchor Network for RGB-T Crowd Counting
Pith reviewed 2026-05-08 04:37 UTC · model grok-4.3
The pith
RACANet improves RGB-T crowd counting with explicit pretraining for cross-modal anchors and local reliability fusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
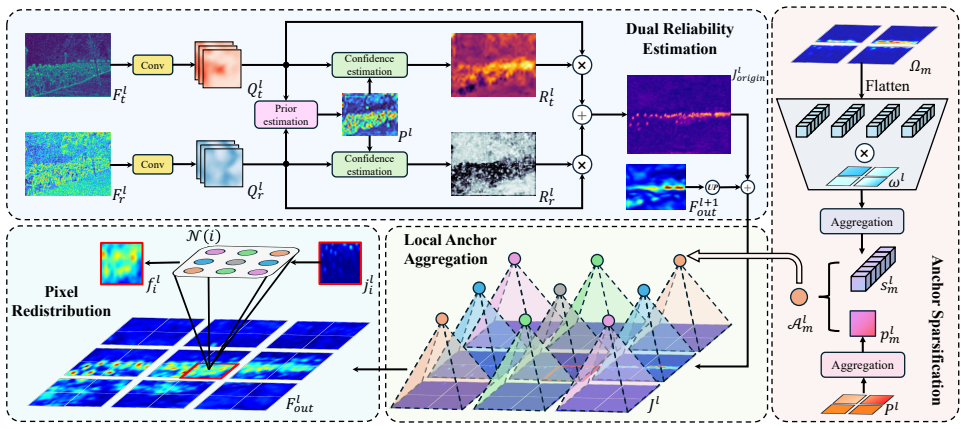
RACANet is a Reliability-Aware Crowd Anchor Network for RGB-T crowd counting. It first runs a lightweight cross-modal alignment pretraining stage that learns semantic correspondences via crowd-prior supervision and local bidirectional soft matching. These priors then drive the Local Anchor Fusion Module during formal training, which generates local semantic anchors by aggregating features from highly reliable regions and performs adaptive pixel-level feature redistribution with a local attention mechanism. A discrepancy-aware consistency constraint coordinates reliability in regions where the two modalities produce consistent representations.
What carries the argument
The Local Anchor Fusion Module (LAFM), which aggregates features from highly reliable regions into local semantic anchors and applies local attention to redistribute cross-modal information at the pixel level, guided by pretraining priors.
If this is right
- Explicit positional reliability modeling reduces errors from local spatial discrepancies between visible and thermal views.
- Pretraining priors enable adaptive feature redistribution that improves counting precision in complex lighting.
- The discrepancy-aware consistency constraint stabilizes fusion in regions where modalities agree.
- The full pipeline outperforms existing RGB-T crowd counting methods on the RGBT-CC and Drone-RGBT benchmarks.
Where Pith is reading between the lines
- The lightweight pretraining design could extend to other multi-modal fusion tasks such as RGB-D depth estimation or infrared-visible object detection.
- Positional reliability anchors may help address domain shifts when thermal cameras are deployed in new environments.
- The two-stage structure separates alignment learning from density estimation, which could simplify fine-tuning on small target datasets.
Load-bearing premise
The cross-modal alignment pretraining learns transferable semantic correspondences that improve the Local Anchor Fusion Module without introducing domain shift or overfitting.
What would settle it
Ablating the pretraining stage or the Local Anchor Fusion Module on the RGBT-CC dataset and observing no accuracy gain over standard implicit fusion baselines would falsify the claimed benefit of explicit reliability modeling.
Figures


read the original abstract
RGB-Thermal (T) crowd counting aims to integrate visible-spectrum and thermal infrared information to improve the robustness of crowd density estimation in complex scenes. Although existing studies generally improve counting accuracy through cross-modal feature fusion, most current methods rely on implicit cross-modal fusion strategies and lack explicit modeling of local spatial discrepancies as well as fine-grained characterization of modality reliability at the positional level, thereby limiting the accuracy and interpretability of the fusion process. To address these issues, this paper proposes a two-stage fusion framework, RACANet, a Reliability-Aware Crowd Anchor Network for RGB-T crowd counting. First, we introduce a lightweight cross-modal alignment pretraining stage, which explicitly learns cross-modal semantic correspondences through crowd-prior supervision and local bidirectional soft matching. Then, based on the priors learned during pretraining, a Local Anchor Fusion Module (LAFM) is introduced in the formal training stage. This module generates local semantic anchors by aggregating features from highly reliable regions and further enables adaptive pixel-level feature redistribution with a local attention mechanism. In addition, we propose a discrepancy-aware consistency constraint to dynamically coordinate the reliability of regions where modal representations are consistent. Experiments conducted on two widely used benchmark datasets, RGBT-CC and Drone-RGBT, demonstrate that RACANet outperforms existing methods. The anonymous code is available at https://anonymous.4open.science/r/RACANet-9985.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RACANet, a two-stage Reliability-Aware Crowd Anchor Network for RGB-T crowd counting. Stage one performs lightweight cross-modal alignment pretraining via crowd-prior supervision and local bidirectional soft matching to learn semantic correspondences. Stage two deploys a Local Anchor Fusion Module (LAFM) that aggregates features from reliable regions into local semantic anchors and applies local attention for adaptive pixel-level redistribution, together with a discrepancy-aware consistency constraint that penalizes unreliable regions. Experiments on the RGBT-CC and Drone-RGBT benchmarks report quantitative gains over prior RGB-T methods, supported by ablations, alignment visualizations, and controls.
Significance. If the reported gains hold under the stated controls, the work supplies a concrete advance over implicit cross-modal fusion by making positional reliability and local discrepancy explicit and interpretable. The two-stage design with explicit crowd-prior supervision, the availability of anonymous code, and the inclusion of ablations plus visualizations constitute reproducible strengths that could be adopted in related multimodal counting tasks.
minor comments (2)
- The abstract asserts outperformance on RGBT-CC and Drone-RGBT but supplies no numerical deltas, error bars, or table references; adding one or two headline numbers would strengthen the opening claim without lengthening the abstract.
- §4.3 (or equivalent ablation section): the consistency-constraint weight is described as 'dynamically coordinated' yet the exact scheduling or hyper-parameter range used in the reported runs is not stated; a short table or sentence would remove ambiguity.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. We are pleased that the explicit reliability modeling, two-stage design, cross-modal pretraining, and reproducibility elements (code, ablations, visualizations) were recognized as strengths.
Circularity Check
No significant circularity detected
full rationale
The RACANet framework is presented as a two-stage architectural proposal: a lightweight cross-modal alignment pretraining stage using crowd-prior supervision and bidirectional soft matching, followed by a Local Anchor Fusion Module (LAFM) with local attention and a discrepancy-aware consistency constraint. No equations, predictions, or central claims reduce by construction to fitted parameters from the same data or to self-citations. The method relies on explicit, independent design choices whose internal logic is self-contained and externally evaluated on RGBT-CC and Drone-RGBT benchmarks. No load-bearing step matches any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Local Anchor Fusion Module (LAFM)
no independent evidence
-
discrepancy-aware consistency constraint
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. 2019. ArcFace: Additive Angular Margin Loss for Deep Face Recognition. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 4690–4699. doi:10.1109/CVPR. 2019.00482
-
[2]
Shuai Dong, Shaoguang Huang, Jinhan Zhang, and Hongyan Zhang. 2024. A Novel Multi-scale Feature Fusion Based Network for Hyperspectral and Multi- spectral Image Fusion. InChinese Conference on Pattern Recognition and Computer Vision (PRCV). Springer, 530–544
2024
- [3]
-
[4]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. InInternational Conference on Learning Representations (ICLR)
2021
-
[5]
Xiao-Meng Duan, Hong-Mei Sun, Zeng-Min Zhang, Ling-Xiao Qin, and Rui- Sheng Jia. 2025. CMFX: Cross-modal fusion network for RGB-X crowd counting. Neural Networks184 (2025), 107070
2025
-
[6]
Qiang Guo, Pengcheng Yuan, Xiangming Huang, and Yangdong Ye. 2024. Consistency-Constrained RGB-T Crowd Counting via Mutual Information Maxi- mization.Complex & Intelligent Systems10, 4 (2024), 5049–5070
2024
-
[7]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition. 770–778
2016
-
[8]
Weihang Kong, Jiayu Liu, Yao Hong, He Li, and Jienan Shen. 2024. Cross-Modal Collaborative Feature Representation via Transformer-Based Multimodal Mixers for RGB-T Crowd Counting.Expert Systems with Applications255 (2024), 124483. doi:10.1016/j.eswa.2024.124483
-
[9]
Weihang Kong, Zepeng Yu, He Li, Liangang Tong, Fengda Zhao, and Yang Li. 2024. CrowdAlign: Shared-Weight Dual-Level Alignment Fusion for RGB-T Crowd Counting.Image and Vision Computing148 (2024), 105152
2024
-
[10]
Weihang Kong, Zepeng Yu, He Li, and Junge Zhang. 2024. Cross-modal misalignment-robust feature fusion for crowd counting.Engineering Applications of Artificial Intelligence136 (2024), 108898
2024
- [11]
-
[12]
Mengqi Lei, Haochen Wu, Xinhua Lv, and Liangxiao Jiang. 2024. Ddranet: A dy- namic density-region-aware network for crowd counting.IEEE Signal Processing Letters31 (2024), 2165–2169
2024
-
[13]
Mengqi Lei, Yihong Wu, Siqi Li, Xinhu Zheng, Juan Wang, Shaoyi Du, and Yue Gao. 2025. Softhgnn: Soft hypergraph neural networks for general visual recognition.arXiv preprint arXiv:2505.15325(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Chengyang Li, Dan Song, Ruofeng Tong, and Min Tang. 2019. Illumination-Aware Faster R-CNN for Robust Multispectral Pedestrian Detection.Pattern Recognition 85 (2019), 161–171
2019
-
[15]
He Li, Junge Zhang, Weihang Kong, Jienan Shen, and Yuguang Shao. 2023. CSA- Net: Cross-Modal Scale-Aware Attention-Aggregated Network for RGB-T Crowd Counting.Expert Systems with Applications213 (2023), 119038
2023
-
[16]
Mingjian Liang, Junjie Hu, Chenyu Bao, Hua Feng, Fuqin Deng, and Tin Lun Lam. 2023. Explicit attention-enhanced fusion for RGB-thermal perception tasks. IEEE Robotics and Automation Letters8, 7 (2023), 4060–4067
2023
- [17]
-
[18]
Lingbo Liu, Jiaqi Chen, Hefeng Wu, Guanbin Li, Chenglong Li, and Liang Lin
-
[19]
InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Cross-Modal Collaborative Representation Learning and a Large-Scale RGBT Benchmark for Crowd Counting. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 4823–4833
-
[20]
Lei Liu, Chenglong Li, Yun Xiao, and Jin Tang. 2023. Quality-Aware RGBT Tracking via Supervised Reliability Learning and Weighted Residual Guidance. InACM Multimedia. 3129–3137
2023
-
[21]
Yanbo Liu, Guo Cao, Boshan Shi, and Yingxiang Hu. 2023. CCANet: A collabora- tive cross-modal attention network for RGB-D crowd counting.IEEE Transactions on Multimedia26 (2023), 154–165
2023
-
[22]
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. 2021. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 10012–10022
2021
-
[23]
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. 2022. A ConvNet for the 2020s. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 11976–11986
2022
-
[24]
Haoliang Meng, Xiaopeng Hong, Chenhao Wang, Miao Shang, and Wangmeng Zuo. 2024. Multi-Modal Crowd Counting via a Broker Modality. InEuropean Conference on Computer Vision (ECCV). 231–250
2024
-
[25]
Baoyang Mu, Feng Shao, Zhengxuan Xie, Hangwei Chen, Zhongjie Zhu, and Qiuping Jiang. 2025. MISF-Net: Modality-Invariant and -Specific Fusion Network for RGB-T Crowd Counting.IEEE Transactions on Multimedia27 (2025), 2593– 2607
2025
-
[26]
Yi Pan, Wujie Zhou, Meixin Fang, and Fangfang Qiang. 2024. Graph Enhancement and Transformer Aggregation Network for RGB-Thermal Crowd Counting.IEEE Geoscience and Remote Sensing Letters21 (2024), 1–5. doi:10.1109/LGRS.2024. 3362820
-
[27]
Yi Pan, Wujie Zhou, Xiaohong Qian, Shanshan Mao, Rongwang Yang, and Lu Yu. 2023. CGINet: Cross-Modality Grade Interaction Network for RGB-T Crowd Counting.Engineering Applications of Artificial Intelligence126 (2023), 106885
2023
-
[28]
Tao Peng, Qing Li, and Pengfei Zhu. 2020. RGB-T Crowd Counting from Drone: A Benchmark and MMCCN Network. InAsian Conference on Computer Vision (ACCV). 497–513
2020
- [29]
-
[30]
Karen Simonyan and Andrew Zisserman. 2014. Very Deep Convolutional Net- works for Large-Scale Image Recognition.arXiv preprint arXiv:1409.1556(2014)
work page internal anchor Pith review arXiv 2014
-
[31]
Sindagi and Vishal M
Vishwanath A. Sindagi and Vishal M. Patel. 2018. A Survey of Recent Advances in CNN-based Single Image Crowd Counting and Density Estimation.Pattern Recognition Letters107 (2018), 3–16
2018
-
[32]
Zhengzheng Tu, Zhun Li, Chenglong Li, and Jin Tang. 2022. Weakly Alignment- Free RGBT Salient Object Detection With Deep Correlation Network.IEEE Transactions on Image Processing31 (2022), 3752–3764
2022
-
[33]
Kunpeng Wang, Danying Lin, Chenglong Li, Zhengzheng Tu, and Bin Luo. 2024. Alignment-Free RGBT Salient Object Detection: Semantics-Guided Asymmetric Correlation Network and a Unified Benchmark.IEEE Transactions on Multimedia 26 (2024), 10692–10707
2024
-
[34]
Shuyu Wang, Weiwei Wu, Yinglin Li, Yuhang Xu, and Yan Lyu. 2025. MIANet: Bridging the Gap in Crowd Density Estimation With Thermal and RGB Interac- tion.IEEE Transactions on Intelligent Transportation Systems26, 1 (2025), 254–267. doi:10.1109/TITS.2024.3478292
-
[35]
Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. 2021. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction Without Convolutions. InIEEE/CVF International Conference on Computer Vision (ICCV). 568–578
2021
-
[36]
Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. 2022. PVT v2: Improved Baselines with Pyramid Vision Transformer.Computational Visual Media8, 3 (2022), 415–424
2022
-
[37]
Alvarez, and Ping Luo
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, and Ping Luo. 2021. SegFormer: Simple and Efficient Design for Semantic Segmenta- tion with Transformers. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 34. 12077–12090
2021
-
[38]
Zhengxuan Xie, Feng Shao, Baoyang Mu, Hangwei Chen, Qiuping Jiang, Chenyang Lu, and Yo-Sung Ho. 2024. BGDFNet: Bidirectional Gated and Dy- namic Fusion Network for RGB-T Crowd Counting in Smart City System.IEEE Transactions on Instrumentation and Measurement73 (2024), 1–16
2024
-
[39]
Weihao Yu, Mi Luo, Pan Zhou, Chenyang Si, Yichen Zhou, Xinchao Wang, Jiashi Feng, and Shuicheng Yan. 2022. MetaFormer Is Actually What You Need for Vision. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 10819–10829
2022
-
[40]
Heng Zhang, Élisa Fromont, Sébastien Lefèvre, and Bruno Avignon. 2021. Guided Attentive Feature Fusion for Multispectral Pedestrian Detection. InIEEE Winter Conference on Applications of Computer Vision (W ACV). 72–80
2021
-
[41]
Youjia Zhang, Soyun Choi, and Sungeun Hong. 2025. Memory-efficient cross- modal attention for RGB-X segmentation and crowd counting.Pattern Recognition 162 (2025), 111376
2025
-
[42]
Wujie Zhou, Yi Pan, Jingsheng Lei, Lv Ye, and Lu Yu. 2022. DEFNet: Dual- Branch Enhanced Feature Fusion Network for RGB-T Crowd Counting.IEEE Transactions on Intelligent Transportation Systems23, 12 (2022), 24540–24549. doi:10.1109/TITS.2022.3203385
-
[43]
Wujie Zhou, Xun Yang, Jingsheng Lei, Weiqing Yan, and Lu Yu. 2023. MC 3 Net: Multimodality cross-guided compensation coordination network for RGB-T crowd counting.IEEE Transactions on Intelligent Transportation Systems25, 5 (2023), 4156–4165. 9
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.