Recognition: unknown
SpotVista: Availability-Aware Recommendation System for Reliable and Cost-Efficient Multi-Node Spot Instances
Pith reviewed 2026-05-08 01:38 UTC · model grok-4.3
The pith
SpotVista recommends pools of multi-node spot instances that deliver substantially higher availability and lower costs than previous methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SpotVista establishes a methodology for recommending cost-efficient and reliable multi-node spot instance configurations by collecting and analyzing a large-scale multi-node availability dataset. Through real-world interruption experiments, it shows this approach outperforms SpotVerse by achieving 81.28% greater availability and 2.84% more cost savings in multi-region setups, and surpasses AWS SpotFleet with 21.6% higher stability and 26.3% greater cost savings.
What carries the argument
The SpotVista recommendation methodology, which uses collected multi-node availability datasets to identify stable and low-cost instance pools.
Load-bearing premise
The large-scale multi-node availability dataset collected is representative of real-world behaviors across workloads, regions, and cloud providers, allowing the methodology to generalize.
What would settle it
A replication experiment on a different cloud provider or with a different workload type that shows no improvement or worse performance than SpotVerse or SpotFleet would falsify the claim of general superiority.
Figures



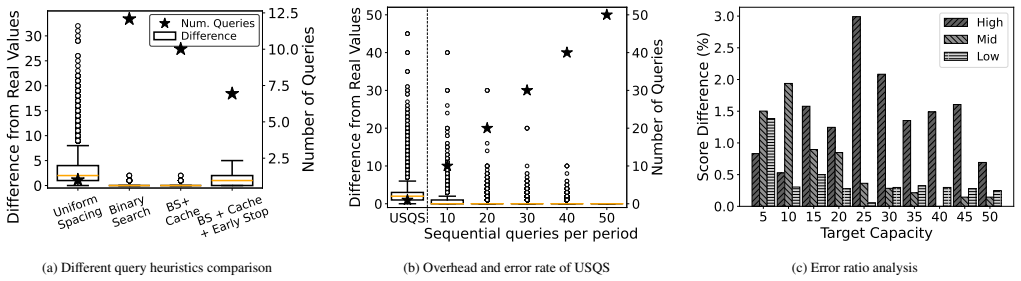
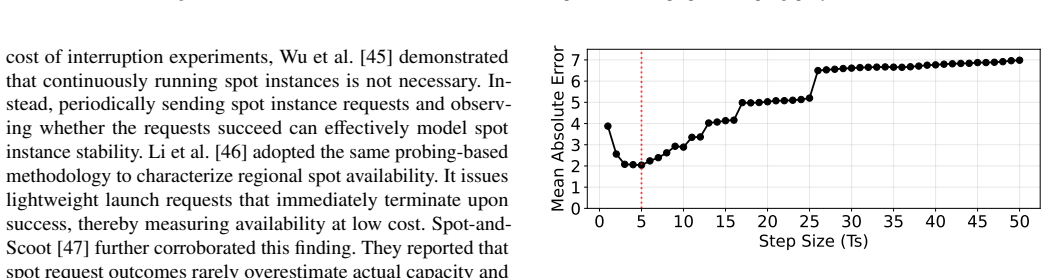









read the original abstract
Cloud vendors offer discounted spot instances to maximize surplus resource utilization, but these instances are subject to the risk of sudden interruption. Traditional pricing datasets have been employed to predict this risk, yet recent policy changes by cloud vendors have diminished their effectiveness. To promote spot instance usage, public cloud vendors provide instant availability datasets to help users mitigate interruption risks. While existing research utilizing this data has proposed methods to reduce interruptions, these studies have primarily focused on single-node instances, overlooking the stability of multi-node environments widely adopted for modern cloud workloads. This paper proposes SpotVista, a system that recommends a resource pool of reliable and cost-efficient multi-node spot instances by leveraging various publicly available datasets. To achieve this, SpotVista collects a large-scale multi-node availability dataset while overcoming significant query limitations. Through a thorough analysis of multi-node spot instance availability behavior, SpotVista establishes a methodology for recommending cost-efficient and reliable multi-node configurations. To evaluate how effectively the proposed methodology reflects multi-node availability and cost efficiency, extensive real-world interruption experiments were conducted. The results demonstrate that SpotVista outperforms the state-of-the-art work, SpotVerse, achieving 81.28% greater availability and 2.84\% more cost savings in a multi-region setup. When compared to a publicly available service, AWS SpotFleet, SpotVista provides 21.6\% higher stability and 26.3% greater cost savings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SpotVista, a recommendation system for selecting reliable and cost-efficient multi-node spot instance pools. It collects a large-scale multi-node availability dataset despite query limitations, performs an analysis of joint availability behavior across nodes, derives a recommendation methodology, and validates it via real-world interruption experiments. The abstract reports that SpotVista achieves 81.28% greater availability and 2.84% more cost savings than SpotVerse in multi-region setups, and 21.6% higher stability plus 26.3% greater cost savings than AWS SpotFleet.
Significance. If the dataset proves representative and the experimental results hold under scrutiny, the work would address a genuine gap: existing spot-instance research has focused on single-node cases while modern workloads are multi-node. A validated methodology could improve practical adoption of spot instances by providing concrete, availability-aware configuration advice that balances reliability and cost.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: the headline claims (81.28% availability gain vs. SpotVerse, 21.6% stability gain vs. SpotFleet) rest on real-world interruption experiments, yet the manuscript supplies no description of experimental design, statistical methods, data-exclusion rules, how availability was measured, or the number of trials. Without these details the quantitative results cannot be assessed for robustness or reproducibility.
- [Data Collection / Methodology] Data-collection and methodology sections: the paper states that a large-scale multi-node availability dataset was gathered “while overcoming significant query limitations,” but provides no sampling strategy, bias-mitigation steps, coverage across regions/workloads/providers, or validation against independent traces. Because all subsequent recommendation rules and performance claims derive from this dataset, its representativeness is load-bearing and must be demonstrated.
minor comments (2)
- [Abstract] Abstract: the percentage “2.84%” appears with an escaped backslash (“2.84%”); this is a minor typesetting artifact.
- [Discussion / Conclusion] The manuscript would benefit from an explicit limitations subsection that discusses the scope of the collected dataset and the conditions under which the recommendation rules may not generalize.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for improving transparency in our work. We address each major comment below and will incorporate the suggested details into the revised manuscript to strengthen the presentation of our experimental results and data collection process.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the headline claims (81.28% availability gain vs. SpotVerse, 21.6% stability gain vs. SpotFleet) rest on real-world interruption experiments, yet the manuscript supplies no description of experimental design, statistical methods, data-exclusion rules, how availability was measured, or the number of trials. Without these details the quantitative results cannot be assessed for robustness or reproducibility.
Authors: We acknowledge that the current manuscript does not provide sufficient detail on the experimental design supporting the headline claims. Although the Evaluation section notes that real-world interruption experiments were conducted, it lacks explicit descriptions of the setup. In the revised version, we will add a dedicated subsection in the Evaluation section that specifies the experimental design, including the number of trials performed, the precise method for measuring availability (monitoring instance uptime and interruptions over defined periods), the statistical methods applied (e.g., computation of means, standard deviations, and confidence intervals), and any data-exclusion rules (such as filtering transient network-related events). These additions will improve reproducibility and allow readers to assess the robustness of the reported gains versus SpotVerse and AWS SpotFleet. revision: yes
-
Referee: [Data Collection / Methodology] Data-collection and methodology sections: the paper states that a large-scale multi-node availability dataset was gathered “while overcoming significant query limitations,” but provides no sampling strategy, bias-mitigation steps, coverage across regions/workloads/providers, or validation against independent traces. Because all subsequent recommendation rules and performance claims derive from this dataset, its representativeness is load-bearing and must be demonstrated.
Authors: We agree that the representativeness of the multi-node availability dataset is critical, given that it forms the basis for our analysis and recommendations. The manuscript currently mentions overcoming query limitations but omits the supporting methodological details. We will expand the Data Collection section to describe the sampling strategy (periodic, systematic queries across instance types and regions to capture temporal patterns), bias-mitigation steps (use of multiple accounts and varied query schedules to reduce rate-limiting effects), coverage (specific regions, instance families, and time span), and validation steps (comparisons with available single-node public traces where feasible). These revisions will better demonstrate the dataset's suitability for deriving the joint-availability methodology. revision: yes
Circularity Check
No significant circularity; derivation relies on independent data collection and external experiments
full rationale
The paper's chain proceeds from public availability datasets (explicitly external) to collection of a multi-node trace, analysis to form a recommendation methodology, and validation via separate real-world interruption experiments. No equations or steps reduce a prediction to a fitted input by construction, no self-definitional loops appear, and no load-bearing uniqueness or ansatz is imported via self-citation. Performance deltas (81.28% availability, 26.3% cost savings) are reported from those independent experiments rather than being statistically forced by the input data itself. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
O. Agmon Ben-Yehuda, M. Ben-Yehuda, A. Schuster, D. Tsafrir, Decon- structing amazon ec2 spot instance pricing, ACM Trans. Econ. Comput. 1 (3) (sep 2013).doi:10.1145/2509413.2509416. 14
-
[2]
D. Movsowitz Davidow, O. Agmon Ben-Yehuda, O. Dunkelman, Decon- structing alibaba cloud’s preemptible instance pricing, in: Proceedings of the 32nd International Symposium on High-Performance Parallel and Distributed Computing, HPDC ’23, Association for Computing Machinery, New York, NY , USA, 2023, p. 253–265.doi:10.1145/3588195.3593 001
-
[3]
Characterizing spot price dynamics in public cloud environments
B. Javadi, R. K. Thulasiram, R. Buyya, Characterizing spot price dynamics in public cloud environments, Future Generation Computer Systems 29 (4) (2013) 988–999, special Section: Utility and Cloud Computing. doi: https://doi.org/10.1016/j.future.2012.06.012
-
[4]
C. Wang, Q. Liang, B. Urgaonkar, An empirical analysis of amazon ec2 spot instance features affecting cost-effective resource procurement, in: Proceedings of the 8th ACM/SPEC on International Conference on Perfor- mance Engineering, ICPE ’17, Association for Computing Machinery, New York, NY , USA, 2017, p. 63–74.doi:10.1145/3030207.3030210
-
[5]
N. Ekwe-Ekwe, A. Barker, Location, location, location: Exploring ama- zon ec2 spot instance pricing across geographical regions, in: 2018 18th IEEE/ACM International Symposium on Cluster, Cloud and Grid Comput- ing (CCGRID), 2018, pp. 370–373. doi:10.1109/CCGRID.2018.0005 9
-
[6]
K. Lee, M. Son, Deepspotcloud: Leveraging cross-region gpu spot in- stances for deep learning, in: 2017 IEEE 10th International Conference on Cloud Computing (CLOUD), 2017, pp. 98–105. doi:10.1109/CLOUD. 2017.21
-
[7]
Chohan, C
N. Chohan, C. Castillo, M. Spreitzer, M. Steinder, A. Tantawi, C. Krintz, See spot run: Using spot instances for MapReduce workflows, in: 2nd USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 10), USENIX Association, Boston, MA, 2010. URL https://www.usenix.org/conference/hotcloud-10/see-spot-run-usi ng-spot-instances-mapreduce-workflows
2010
-
[8]
P. Sharma, T. Guo, X. He, D. Irwin, P. Shenoy, Flint: Batch-interactive data- intensive processing on transient servers, in: Proceedings of the Eleventh European Conference on Computer Systems, EuroSys ’16, Association for Computing Machinery, New York, NY , USA, 2016.doi:10.1145/2901 318.2901319
-
[9]
A. Ali-Eldin, J. Westin, B. Wang, P. Sharma, P. Shenoy, Spotweb: Running latency-sensitive distributed web services on transient cloud servers, in: Proceedings of the 28th International Symposium on High- Performance Parallel and Distributed Computing, HPDC ’19, Associ- ation for Computing Machinery, New York, NY , USA, 2019, p. 1–12. doi:10.1145/3307681.3325397
-
[10]
X. He, P. Shenoy, R. Sitaraman, D. Irwin, Cutting the cost of hosting online services using cloud spot markets, in: Proceedings of the 24th International Symposium on High-Performance Parallel and Distributed Computing, HPDC ’15, Association for Computing Machinery, New York, NY , USA, 2015, p. 207–218.doi:10.1145/2749246.2749275
-
[11]
Menache, O
I. Menache, O. Shamir, N. Jain, On-demand, spot, or both: Dynamic resource allocation for executing batch jobs in the cloud, in: 11th In- ternational Conference on Autonomic Computing (ICAC 14), USENIX Association, Philadelphia, PA, 2014, pp. 177–187. URL https://www.usenix.org/conference/icac14/technical-sessions/pres entation/menache
2014
-
[12]
61-70).https://doi.org/10.1145/28 08194.2809457
S. Subramanya, T. Guo, P. Sharma, D. Irwin, P. Shenoy, Spoton: A batch computing service for the spot market, in: Proceedings of the Sixth ACM Symposium on Cloud Computing, SoCC ’15, Association for Computing Machinery, New York, NY , USA, 2015, p. 329–341.doi:10.1145/28 06777.2806851
work page doi:10.1145/28 2015
-
[13]
P. Varshney, Y . Simmhan, Autobot: Resilient and cost-effective scheduling of a bag of tasks on spot vms, IEEE Transactions on Parallel & Distributed Systems 30 (07) (2019) 1512–1527. doi:10.1109/TPDS.2018.2889 851
-
[14]
Inside the social network’s (datacenter) network,
L. Zheng, C. Joe-Wong, C. W. Tan, M. Chiang, X. Wang, How to bid the cloud, in: Proceedings of the 2015 ACM Conference on Spe- cial Interest Group on Data Communication, SIGCOMM ’15, Associa- tion for Computing Machinery, New York, NY , USA, 2015, p. 71–84. doi:10.1145/2785956.2787473
-
[15]
Sharma, D
P. Sharma, D. Irwin, P. Shenoy, How not to bid the cloud, in: 8th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 16), USENIX Association, Denver, CO, 2016. URL https://www.usenix.org/conference/hotcloud16/workshop-program /presentation/sharma
2016
-
[16]
Alkharif, K
S. Alkharif, K. Lee, H. Kim, Time-series analysis for price prediction of opportunistic cloud computing resources, in: W. Lee, W. Choi, S. Jung, M. Song (Eds.), Proceedings of the 7th International Conference on Emerg- ing Databases, Springer Singapore, Singapore, 2018, pp. 221–229
2018
-
[17]
V . Khandelwal, A. Chaturvedi, C. P. Gupta, Amazon ec2 spot price pre- diction using regression random forests, IEEE Transactions on Cloud Computing (2017) 1–1doi:10.1109/TCC.2017.2780159
-
[18]
M. Khodak, L. Zheng, A. S. Lan, C. Joe-Wong, M. Chiang, Learning cloud dynamics to optimize spot instance bidding strategies, in: IEEE INFOCOM 2018 - IEEE Conference on Computer Communications, 2018, pp. 2762–2770.doi:10.1109/INFOCOM.2018.8486291
-
[19]
Fabra, J
J. Fabra, J. Ezpeleta, P. ´Alvarez, Reducing the price of resource provision- ing using ec2 spot instances with prediction models, Future Generation Computer Systems 96 (2019) 348–367. doi:https://doi.org/10.1 016/j.future.2019.01.025
2019
-
[20]
M. Baughman, S. Caton, C. Haas, R. Chard, R. Wolski, I. Foster, K. Chard, Deconstructing the 2017 changes to aws spot market pricing, in: Proceed- ings of the 10th Workshop on Scientific Cloud Computing, ScienceCloud ’19, Association for Computing Machinery, New York, NY , USA, 2019, p. 19–26.doi:10.1145/3322795.3331465
-
[21]
D. Irwin, P. Shenoy, P. Ambati, P. Sharma, S. Shastri, A. Ali-Eldin, The price is (not) right: Reflections on pricing for transient cloud servers, in: 2019 28th International Conference on Computer Communication and Networks (ICCCN), 2019, pp. 1–9. doi:10.1109/ICCCN.2019.88469 33
-
[22]
A. W. is New, Introducing amazon ec2 spot placement score (2021). URL https://aws.amazon.com/about-aws/whats-new/2021/10/amazon-e c2-spot-placement-score/
2021
-
[23]
URL https://learn.microsoft.com/en-us/azure/virtual-machine-scale-set s/spot-placement-score
Azure, Spot placement score (2025). URL https://learn.microsoft.com/en-us/azure/virtual-machine-scale-set s/spot-placement-score
2025
-
[24]
S. Lee, J. Hwang, K. Lee, Spotlake: Diverse spot instance dataset archive service, in: 2022 IEEE International Symposium on Workload Characteri- zation (IISWC), IEEE Computer Society, Los Alamitos, CA, USA, 2022, pp. 242–255.doi:10.1109/IISWC55918.2022.00029
-
[25]
K. Kim, S. Park, J. Hwang, H. Lee, S. Kang, K. Lee, Public spot instance dataset archive service, in: Companion Proceedings of the ACM Web Conference 2023, WWW ’23 Companion, Association for Computing Machinery, New York, NY , USA, 2023, p. 69–72.doi:10.1145/3543 873.3587314
-
[26]
Cheon, K
S. Cheon, K. Kim, K. Kim, M. Song, K. Lee, Multi-node spot instances availability score collection system, in: Proceedings of the 34th Interna- tional Symposium on High-Performance Parallel and Distributed Comput- ing (HPDC ’25), ACM, 2025
2025
-
[27]
M. Son, G. G. Akbulut, M. T. Kandemir, Spotverse: Optimizing bioinfor- matics workflows with multi-region spot instances in galaxy and beyond, in: Proceedings of the 25th International Middleware Conference, Middle- ware ’24, Association for Computing Machinery, New York, NY , USA, 2024, p. 74–87.doi:10.1145/3652892.3700750
-
[28]
S. Tang, J. Yuan, X.-Y . Li, Towards optimal bidding strategy for amazon ec2 cloud spot instance, in: 2012 IEEE Fifth International Conference on Cloud Computing, 2012, pp. 91–98.doi:10.1109/CLOUD.2012.134
-
[29]
URL https://learn.microsoft.com/en-us/azure/virtual-machines/spot-vms/
azure cloud, azure spot virtual machines (2024). URL https://learn.microsoft.com/en-us/azure/virtual-machines/spot-vms/
2024
-
[30]
URL https://www.alibabacloud.com/help/en/ecs/user-guide/overview-4/
alibaba cloud, alibaba preemptible instance (2024). URL https://www.alibabacloud.com/help/en/ecs/user-guide/overview-4/
2024
-
[31]
R. Y . Aminabadi, S. Rajbhandari, A. A. Awan, C. Li, D. Li, E. Zheng, O. Ruwase, S. Smith, M. Zhang, J. Rasley, Y . He, Deepspeed-inference: enabling efficient inference of transformer models at unprecedented scale, in: Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, SC ’22, IEEE Press, 2022
2022
-
[32]
J. Samp´e, M. S´anchez-Artigas, G. Vernik, I. Yehekzel, P. Garc´ıa-L´opez, Outsourcing data processing jobs with lithops, IEEE Transactions on Cloud Computing 11 (1) (2023) 1026–1037. doi:10.1109/TCC.2021.31290 00
-
[33]
Thorpe, P
J. Thorpe, P. Zhao, J. Eyolfson, Y . Qiao, Z. Jia, M. Zhang, R. Netravali, G. H. Xu, Bamboo: Making preemptible instances resilient for affordable training of large DNNs, in: 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), USENIX Association, Boston, MA, 2023, pp. 497–513. URL https://www.usenix.org/conference/nsdi23/presen...
2023
-
[34]
J. Duan, Z. Song, X. Miao, X. Xi, D. Lin, H. Xu, M. Zhang, Z. Jia, Par- cae: Proactive, Liveput-Optimized DNN training on preemptible instances, in: 21st USENIX Symposium on Networked Systems Design and Imple- mentation (NSDI 24), USENIX Association, Santa Clara, CA, 2024, pp. 1121–1139. URL https://www.usenix.org/conference/nsdi24/presentation/duan
2024
-
[35]
Chohan, C
N. Chohan, C. Castillo, M. Spreitzer, M. Steinder, A. Tantawi, C. Krintz, See spot run: Using spot instances for {MapReduce} workflows, in: 2nd USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 10), 2010
2010
-
[36]
K. Kim, K. Lee, Making cloud spot instance interruption events visible, in: Proceedings of the ACM on Web Conference 2024, WWW ’24, Associa- tion for Computing Machinery, New York, NY , USA, 2024, p. 2998–3009. doi:10.1145/3589334.3645548
-
[37]
URL https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/spot-bes t-practices
AWS, Best practices for amazon ec2 spot (2026). URL https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/spot-bes t-practices
2026
-
[38]
R. M. Gray, Entropy and Information Theory, 2nd Edition, Springer Pub- lishing Company, Incorporated, 2011
2011
-
[39]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Pas- sos, D. Cournapeau, M. Brucher, M. Perrot, E. Duchesnay, Scikit-learn: Machine learning in Python - minmax scaling, Journal of Machine Learn- ing Research 12 (2011) 2825–2830
2011
-
[40]
Karaliˇc, I
A. Karaliˇc, I. Bratko, First order regression, Machine learning 26 (1997) 147–176
1997
-
[41]
R. M. Karp, Reducibility among combinatorial problems, in: R. E. Miller, J. W. Thatcher (Eds.), Complexity of computer computations, Plenum Press, New York, NY , USA, 1972, pp. 85–103
1972
-
[42]
J. M. Hellerstein, J. M. Faleiro, J. Gonzalez, J. Schleier-Smith, V . Sreekanti, A. Tumanov, C. Wu, Serverless computing: One step forward, two steps back, in: 9th Biennial Conference on Innovative Data Systems Research, CIDR 2019, Asilomar, CA, USA, January 13-16, 2019, Online Proceed- ings, www.cidrdb.org, 2019. URL http://cidrdb.org/cidr2019/papers/p11...
2019
-
[43]
J. Kadupitige, V . Jadhao, P. Sharma, Modeling the temporally constrained preemptions of transient cloud vms, in: Proceedings of the 29th Interna- tional Symposium on High-Performance Parallel and Distributed Comput- ing, HPDC ’20, Association for Computing Machinery, New York, NY , USA, 2020, p. 41–52.doi:10.1145/3369583.3392671
-
[44]
T.-P. Pham, S. Ristov, T. Fahringer, Performance and behavior charac- terization of amazon ec2 spot instances, in: 2018 IEEE 11th Interna- tional Conference on Cloud Computing (CLOUD), 2018, pp. 73–81. doi:10.1109/CLOUD.2018.00017
-
[45]
Wu, W.-L
Z. Wu, W.-L. Chiang, Z. Mao, Z. Yang, E. Friedman, S. Shenker, I. Stoica, Can’t be late: Optimizing spot instance savings under deadlines, in: 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24), USENIX Association, Santa Clara, CA, 2024, pp. 185–203. URL https://www.usenix.org/conference/nsdi24/presentation/wu-zhang hao
2024
- [46]
-
[47]
K. Kim, M. Song, T. Kim, K. Lee, Spot-and-scoot: Peeking into spot instance availability (Apr. 2026).doi:10.5281/zenodo.19590680. URL https://doi.org/10.5281/zenodo.19590680
-
[48]
Bandara, R
K. Bandara, R. J. Hyndman, C. Bergmeir, Mstl: A seasonal-trend de- composition algorithm for time series with multiple seasonal patterns, International Journal of Operational Research 52 (1) (2025) 79–98
2025
-
[49]
F. Yang, L. Wang, Z. Xu, J. Zhang, L. Li, B. Qiao, C. Couturier, C. Bansal, S. Ram, S. Qin, Z. Ma, I. n. Goiri, E. Cortez, T. Yang, V . R¨uhle, S. Ra- jmohan, Q. Lin, D. Zhang, Snape: Reliable and low-cost computing with mixture of spot and on-demand vms, in: Proceedings of the 28th ACM International Conference on Architectural Support for Programming Lan...
-
[50]
X. Wang, K. Smith, R. Hyndman, Characteristic-based clustering for time series data, Data Min. Knowl. Discov. 13 (3) (2006) 335–364. doi: 10.1007/s10618-005-0039-x
-
[51]
J. Bai, P. Perron, Estimating and testing linear models with multiple struc- tural changes, Econometrica (1998) 47–78
1998
-
[52]
E. L. Kaplan, P. Meier, Nonparametric estimation from incomplete obser- vations, Journal of the American Statistical Association 53 (282) (1958) 457–481.doi:10.1080/01621459.1958.10501452
-
[53]
D. R. Cox, Regression models and life-tables, Journal of the Royal Statis- tical Society: Series B (Methodological) 34 (2) (1972) 187–202
1972
-
[54]
D. A. Ali, A. M. Hussein, Analysis of cox proportional hazard model for dropout students in university: case study from simad university, Journal of Applied Research in Higher Education 16 (3) (2024) 820–830
2024
-
[55]
K. N. Chi, T. Kheoh, C. J. Ryan, A. Molina, J. Bellmunt, N. J. V ogelzang, D. E. Rathkopf, K. Fizazi, P. W. Kantoff, J. Li, et al., A prognostic index model for predicting overall survival in patients with metastatic castration- resistant prostate cancer treated with abiraterone acetate after docetaxel, Annals of Oncology 27 (3) (2016) 454–460
2016
-
[56]
Okuda-Arai, S
M. Okuda-Arai, S. Mori, F. Takano, K. Ueda, M. Sakamoto, Y . Yamada- Nakanishi, M. Nakamura, Impact of glaucoma medications on subsequent schlemm’s canal surgery outcome: Cox proportional hazard model and propensity score-matched analysis, Acta Ophthalmologica 102 (2) (2024) e178–e184
2024
-
[57]
Conniffe, Expected maximum log likelihood estimation, Journal of the Royal Statistical Society
D. Conniffe, Expected maximum log likelihood estimation, Journal of the Royal Statistical Society. Series D (The Statistician) 36 (4) (1987) 317–329. URL http://www.jstor.org/stable/2348828
-
[58]
Benesty, J
J. Benesty, J. Chen, Y . Huang, I. Cohen, Pearson correlation coefficient, in: Noise reduction in speech processing, Springer, 2009, pp. 1–4
2009
-
[59]
S. A. Mitchell, Pulp, https://github.com/coin-or/pulp (2003)
2003
-
[60]
URL https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/Fleets
AWS, Ec2 fleet and spot fleet (2024). URL https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/Fleets
2024
-
[61]
R. Wolski, J. Brevik, R. Chard, K. Chard, Probabilistic guarantees of execution duration for amazon spot instances, in: Proceedings of the In- ternational Conference for High Performance Computing, Networking, Storage and Analysis, SC ’17, Association for Computing Machinery, New York, NY , USA, 2017.doi:10.1145/3126908.3126953
-
[62]
Statistical analysis of Amazon EC2 cloud pricing models
G. Portella, G. N. Rodrigues, E. Nakano, A. C. Melo, Statistical analysis of amazon ec2 cloud pricing models, Concurrency and Computation: Practice and Experience 31 (18) (2019) e4451.doi:10.1002/cpe.4451
-
[63]
A. Marathe, R. Harris, D. Lowenthal, B. R. de Supinski, B. Rountree, M. Schulz, Exploiting redundancy for cost-effective, time-constrained execution of hpc applications on amazon ec2, in: Proceedings of the 23rd International Symposium on High-Performance Parallel and Distributed Computing, HPDC ’14, Association for Computing Machinery, New York, NY , USA...
-
[64]
A. S. Foundation, Apache hadoop (2004). URL http://hadoop.apache.org/
2004
-
[65]
Y . Yan, Y . Gao, Y . Chen, Z. Guo, B. Chen, T. Moscibroda, Tr-spark: Transient computing for big data analytics, in: Proceedings of the Sev- enth ACM Symposium on Cloud Computing, SoCC ’16, Association for Computing Machinery, New York, NY , USA, 2016, p. 484–496. doi:10.1145/2987550.2987576
-
[66]
Zaharia, M
M. Zaharia, M. Chowdhury, T. Das, A. Dave, J. Ma, M. McCauly, M. J. Franklin, S. Shenker, I. Stoica, Resilient distributed datasets: A Fault- Tolerant abstraction for In-Memory cluster computing, in: 9th USENIX Symposium on Networked Systems Design and Implementation (NSDI 12), USENIX Association, San Jose, CA, 2012, pp. 15–28. URL https://www.usenix.org/...
2012
-
[67]
F. Yang, B. Pang, J. Zhang, B. Qiao, L. Wang, C. Couturier, C. Bansal, S. Ram, S. Qin, Z. Ma, I. n. Goiri, E. Cortez, S. Baladhandayutham, V . R¨uhle, S. Rajmohan, Q. Lin, D. Zhang, Spot virtual machine eviction prediction in microsoft cloud, in: Companion Proceedings of the Web Conference 2022, WWW ’22, Association for Computing Machinery, New York, NY ,...
-
[68]
H. Haugerud, J. Kr¨uger Svensson, A. Yazidi, Autonomous provisioning of preemptive instances in google cloud for maximum performance per dollar, in: 2020 5th International Conference on Cloud Computing and Artificial Intelligence: Technologies and Applications (CloudTech), 2020, pp. 1–8.doi:10.1109/CloudTech49835.2020.9365879
-
[69]
J. Kadupitiya, V . Jadhao, P. Sharma, Scispot: Scientific computing on temporally constrained cloud preemptible vms, IEEE Transactions on Parallel and Distributed Systems 33 (12) (2022) 3575–3588. doi:10.1 16 109/TPDS.2022.3157272
-
[70]
Z. Yang, Z. Wu, M. Luo, W.-L. Chiang, R. Bhardwaj, W. Kwon, S. Zhuang, F. S. Luan, G. Mittal, S. Shenker, I. Stoica, SkyPilot: An intercloud broker for sky computing, in: 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), USENIX Association, Boston, MA, 2023, pp. 437–455. URL https://www.usenix.org/conference/nsdi23/presentati...
2023
-
[71]
I. Jang, Z. Yang, Z. Zhang, X. Jin, M. Chowdhury, Oobleck: Resilient distributed training of large models using pipeline templates, in: Proceed- ings of the 29th Symposium on Operating Systems Principles, SOSP ’23, Association for Computing Machinery, New York, NY , USA, 2023, p. 382–395.doi:10.1145/3600006.3613152
-
[72]
S. Athlur, N. Saran, M. Sivathanu, R. Ramjee, N. Kwatra, Varuna: scalable, low-cost training of massive deep learning models, in: Proceedings of the Seventeenth European Conference on Computer Systems, EuroSys ’22, Association for Computing Machinery, New York, NY , USA, 2022, p. 472–487.doi:10.1145/3492321.3519584
-
[73]
Y . Kim, K. Kim, Y . Cho, J. Kim, A. Khan, K.-D. Kang, B.-S. An, M.- H. Cha, H.-Y . Kim, Y . Kim, Deepvm: Integrating spot and on-demand vms for cost-efficient deep learning clusters in the cloud, in: 2024 IEEE 24th International Symposium on Cluster, Cloud and Internet Computing (CCGrid), 2024, pp. 227–235. doi:10.1109/CCGrid59990.2024.000 34
-
[74]
Z. Xu, C. Stewart, N. Deng, X. Wang, Blending on-demand and spot instances to lower costs for in-memory storage, in: IEEE INFOCOM 2016 - The 35th Annual IEEE International Conference on Computer Communications, 2016, pp. 1–9. doi:10.1109/INFOCOM.2016.75243 48
-
[75]
Sharma, D
P. Sharma, D. Irwin, P. Shenoy, Portfolio-driven resource management for transient cloud servers, Proceedings of the ACM on Measurement and Analysis of Computing Systems 1 (1) (2017) 1–23
2017
-
[76]
Harlap, A
A. Harlap, A. Chung, A. Tumanov, G. R. Ganger, P. B. Gibbons, Tributary: spot-dancing for elastic services with latency SLOs, in: 2018 USENIX Annual Technical Conference (USENIX ATC 18), USENIX Association, Boston, MA, 2018, pp. 1–14. URL https://www.usenix.org/conference/atc18/presentation/harlap 17
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.