Recognition: unknown
Mono2Sls: Automated Monolith-to-Serverless Migration via Multi-Stage Pipeline with Static Analysis
Pith reviewed 2026-05-08 02:52 UTC · model grok-4.3
The pith
A pipeline combining static analysis with four LLM agents automates migration of monolithic web backends to AWS serverless applications.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
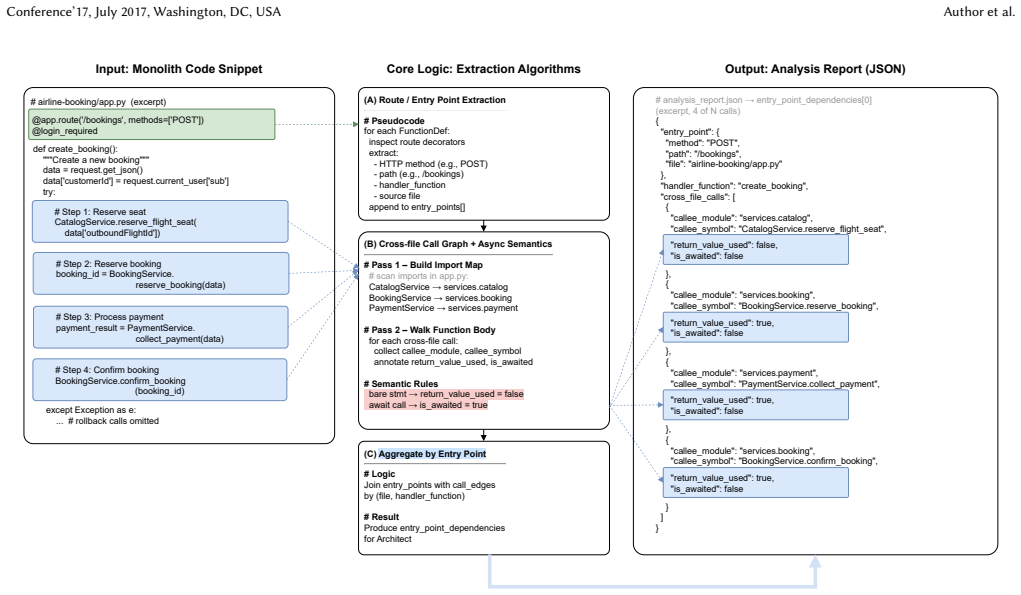
Mono2Sls converts monolithic web backends into AWS SAM serverless applications through a multi-stage pipeline that begins with static analysis of entry points, call graphs, and asynchronous behavior. Four tool-using LLM agents then operate in sequence: the Architect produces a high-level plan, the Code Developer rewrites the source, the SAM Engineer generates infrastructure definitions, and the Consistency Validator verifies the result. The agents communicate exclusively through explicit intermediate artifacts and reference a SAM knowledge base. On six benchmark applications containing more than 10K lines of code and 76 business endpoints, the pipeline produces 100% deployment success with 0
What carries the argument
The multi-stage pipeline that sequences lightweight static analysis with four sequential tool-using LLM agents (Architect, Code Developer, SAM Engineer, Consistency Validator) communicating through explicit artifacts and guided by a curated SAM knowledge base.
Load-bearing premise
The static analysis and four LLM agents will correctly manage architecture planning, code changes, and consistency verification for arbitrary real-world monolithic backends beyond the six selected benchmarks.
What would settle it
Applying the pipeline to a fresh collection of monolithic applications with greater size, more complex dependencies, or different languages and checking whether deployment succeeds without manual fixes while maintaining comparable correctness and API coverage.
Figures


read the original abstract
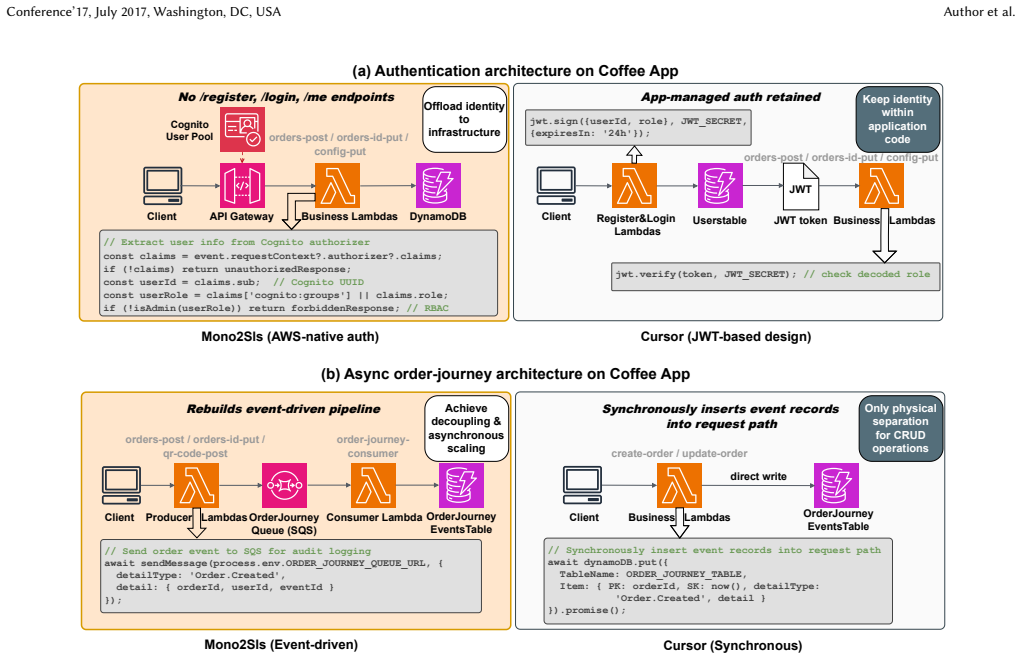
Cloud computing platforms offer elastic scaling, managed infrastructure, and pay-per-use pricing, but moving existing monolithic backends to them remains a difficult software engineering task. In practice, the migration requires coordinated changes to program structure, source code, infrastructure configuration, and cloud-specific design decisions, and these changes are still largely carried out by hand. In this paper, we present Mono2Sls, an automated pipeline that converts monolithic web backends into deployable AWS SAM applications. The pipeline combines lightweight static analysis of entry points, call graphs, and asynchronous behavior with four sequential tool-using LLM agents: Architect, Code Developer, SAM Engineer, and Consistency Validator. These agents communicate through explicit intermediate artifacts and consult a curated SAM knowledge base. Evaluated on six benchmark applications totaling more than 10K lines of code and 76 business endpoints, Mono2Sls achieves 100% deployment success without manual fixes. It also reaches 66.1% end-to-end correctness and 98.7% API-coverage F1, whereas the commercial baselines achieve 53.7--61.2% and 88.4%, respectively. The migrated systems show more consistent use of AWS-native authentication and asynchronous patterns, and an ablation study indicates that static-analysis-guided architecture planning contributes 23.4 percentage points to end-to-end correctness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to present Mono2Sls, an automated pipeline for converting monolithic web backends into deployable AWS SAM serverless applications. The pipeline uses lightweight static analysis of entry points, call graphs, and asynchronous behavior, combined with four tool-using LLM agents (Architect, Code Developer, SAM Engineer, and Consistency Validator) that interact via explicit intermediate artifacts and a curated SAM knowledge base. On six benchmark applications totaling more than 10K lines of code and 76 business endpoints, it achieves 100% deployment success without manual fixes, 66.1% end-to-end correctness, and 98.7% API-coverage F1, outperforming commercial baselines at 53.7--61.2% correctness and 88.4% F1. An ablation study shows static-analysis guidance contributes 23.4 percentage points to correctness.
Significance. If the results hold, this work would be significant for the field of automated software migration and refactoring. It provides a concrete, multi-agent LLM-based system that achieves high deployment success and improved correctness over baselines on a non-trivial set of applications. The emphasis on static analysis to guide architecture planning and the use of intermediate artifacts for agent communication are notable design choices that could be adopted more broadly. The ablation study adds value by quantifying the contribution of the static analysis component.
major comments (2)
- The evaluation is central to the paper's claims of superior performance. However, the manuscript does not provide details on the methodology for measuring end-to-end correctness across the 76 endpoints, the specific commercial baselines employed, or the selection process and characteristics of the six benchmark applications. This omission makes it challenging to evaluate the validity of the 66.1% correctness figure and the generalization to arbitrary real-world monoliths with features like reflection or complex dependency injection.
- In the ablation study, static analysis is credited with a 23.4 percentage point improvement in end-to-end correctness. Yet the paper lacks a direct evaluation of the static analysis itself, such as its coverage or accuracy in identifying entry points, call graphs, and async patterns on the benchmarks. This is important because the central assumption is that the combination of this analysis with the LLM agents will work for arbitrary monoliths.
minor comments (1)
- The abstract mentions improved consistency in AWS-native authentication and asynchronous patterns but does not quantify this; including a metric or comparison table in the results would improve clarity and presentation.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We appreciate the positive assessment of the work's significance and agree that the evaluation section would benefit from greater methodological transparency. We address each major comment below and will incorporate the requested details through major revisions to the manuscript.
read point-by-point responses
-
Referee: The evaluation is central to the paper's claims of superior performance. However, the manuscript does not provide details on the methodology for measuring end-to-end correctness across the 76 endpoints, the specific commercial baselines employed, or the selection process and characteristics of the six benchmark applications. This omission makes it challenging to evaluate the validity of the 66.1% correctness figure and the generalization to arbitrary real-world monoliths with features like reflection or complex dependency injection.
Authors: We agree that these details are essential for assessing the results. In the revised manuscript we will add a new subsection (5.1) titled 'Benchmark Selection and Evaluation Methodology'. It will describe: (1) the selection process and characteristics of the six benchmarks, including their open-source origins, programming frameworks, total lines of code, endpoint counts, and coverage of asynchronous patterns; (2) the specific commercial baselines and their configurations; and (3) the end-to-end correctness protocol, which executes identical test suites against original and migrated applications and scores functional equivalence via response matching and behavioral invariants. We will also add a threats-to-validity paragraph that explicitly discusses generalization limits, noting that the benchmarks contain representative but not exhaustive instances of reflection and dependency injection, and that results should not be extrapolated to arbitrary monoliths without further study. These additions will directly support the reported 66.1% correctness and 98.7% F1 figures. revision: yes
-
Referee: In the ablation study, static analysis is credited with a 23.4 percentage point improvement in end-to-end correctness. Yet the paper lacks a direct evaluation of the static analysis itself, such as its coverage or accuracy in identifying entry points, call graphs, and async patterns on the benchmarks. This is important because the central assumption is that the combination of this analysis with the LLM agents will work for arbitrary monoliths.
Authors: We accept that direct metrics on the static analysis would strengthen the ablation. The revised manuscript will extend Section 5.3 with a new table reporting precision/recall for entry-point identification, call-graph accuracy (compared against manually verified ground truth on all benchmarks), and detection coverage for asynchronous constructs. These metrics will be computed on the same six applications used throughout the evaluation. While the existing ablation already isolates the 23.4 pp contribution to end-to-end correctness, the added numbers will provide independent evidence of analysis quality. We will also revise the discussion to clarify that the approach relies on the static analysis being sufficiently accurate for the evaluated benchmarks and does not claim robustness for arbitrary monoliths containing heavy reflection or complex dynamic features. revision: yes
Circularity Check
No significant circularity in empirical system evaluation
full rationale
The paper presents an empirical description of the Mono2Sls pipeline (static analysis plus four LLM agents) and reports direct measurements of deployment success, end-to-end correctness, and API-coverage F1 on six chosen benchmarks totaling >10k LOC. No equations, fitted parameters, first-principles derivations, or predictions appear in the abstract or described content. Results are not obtained by renaming inputs or by self-citation chains; they are explicit experimental outcomes on the evaluated applications. The work is therefore self-contained as a software-engineering system paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents guided by static analysis and a SAM knowledge base can produce correct architecture plans, code transformations, and infrastructure configurations for monolithic web backends.
Reference graph
Works this paper leans on
-
[1]
Amazon Web Services. 2024. Amazon Cognito Developer Guide. https://docs. aws.amazon.com/cognito/latest/developerguide/what-is-amazon-cognito.html
2024
-
[2]
Amazon Web Services. 2024. Amazon EventBridge User Guide. https://docs.aws. amazon.com/eventbridge/latest/userguide/eb-what-is.html
2024
-
[3]
Amazon Web Services. 2024. Amazon Simple Queue Service Devel- oper Guide. https://docs.aws.amazon.com/AWSSimpleQueueService/latest/ SQSDeveloperGuide/welcome.html
2024
-
[4]
Amazon Web Services. 2024. AWS Lambda — Serverless Compute. https://aws. amazon.com/lambda/
2024
-
[5]
Amazon Web Services. 2024. aws-samples: AWS Sample Applications and Refer- ence Architectures. https://github.com/aws-samples
2024
-
[6]
Amazon Web Services. 2024. AWS Serverless Application Model (SAM) Devel- oper Guide. https://docs.aws.amazon.com/serverless-application-model/latest/ developerguide/what-is-sam.html
2024
-
[7]
Amazon Web Services. 2024. cfn-lint: CloudFormation Linter. https://github. com/aws-cloudformation/cfn-lint
2024
-
[8]
Amazon Web Services. 2024. Deploy Node.js Lambda Functions with .zip File Archives. https://docs.aws.amazon.com/lambda/latest/dg/nodejs-package.html
2024
-
[9]
Amazon Web Services. 2024. Understanding the Lambda Execution Environ- ment Lifecycle. https://docs.aws.amazon.com/lambda/latest/dg/lambda-runtime- environment.html
2024
-
[10]
Amazon Web Services. 2024. Working with Lambda Layers — Packaging Layer Content. https://docs.aws.amazon.com/lambda/latest/dg/packaging-layers.html
2024
-
[11]
Shrikara Arun, Meghana Tedla, and Karthik Vaidhyanathan. 2025. LLMs for Generation of Architectural Components: An Exploratory Empirical Study in the Serverless World. InProceedings of the 22nd IEEE International Conference on Software Architecture (ICSA). IEEE
2025
-
[12]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. 2021. Program Synthesis with Large Language Models. arXiv:2108.07732 https://arxiv.org/abs/2108.07732
work page internal anchor Pith review arXiv 2021
-
[13]
Calyo Consulting. 2026. Serverless Computing in Enterprise 2026: What You Need to Know. https://www.calyo-consulting.fr/en/resources/10-serverless- computing-enterprise-2026
2026
-
[14]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
-
[15]
Evaluating Large Language Models Trained on Code
Evaluating Large Language Models Trained on Code. arXiv:2107.03374 https://arxiv.org/abs/2107.03374
work page internal anchor Pith review arXiv
-
[16]
Leonardo Rebôuças de Carvalho and Eduardo Araujo Oliveira. 2023. FaaS- Oriented Node.js Applications in an RPC Approach Using the Node2FaaS Frame- work.IEEE Access11 (2023)
2023
-
[17]
Abad, and Alexandru Iosup
Simon Eismann, Joel Scheuner, Erwin van Eyk, Maximilian Schwinger, Johannes Grohmann, Nikolas Herbst, Cristina L. Abad, and Alexandru Iosup. 2022. The State of Serverless Applications: Collection, Characterization, and Community Consensus.IEEE Transactions on Software Engineering48, 10 (2022), 4066–4086
2022
-
[18]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. 2020. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. InFindings of the Association for Computational Linguistics: EMNLP 2020. Association for Computa- tional Linguistics
2020
-
[19]
GlobeNewsWire. 2026. Serverless Computing Market Surges to $44.7 Billion by 2029, CAGR 15.3%. https://globenewswire.com/news- release/2026/02/10/3235443/0/en/Serverless-Computing-Market-Surges-to-44- 7-billion-by-2029-CAGR-15-3.html
2026
- [20]
-
[21]
Hellerstein, Jose Faleiro, Joseph E
Joseph M. Hellerstein, Jose Faleiro, Joseph E. Gonzalez, Johann Schleier-Smith, Vikram Sreekanti, Alexey Tumanov, and Chenggang Wu. 2019. Serverless Com- puting: One Step Forward, Two Steps Back. InProceedings of the 9th Biennial Conference on Innovative Data Systems Research (CIDR)
2019
-
[22]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large Language Models for Software Engineering: A Systematic Literature Review.ACM Transactions on Software Engineering and Methodology(2024). Conference’17, July 2017, Washington, DC, USA Author et al
2024
-
[23]
Ali Reza Ibrahimzada, Kaiyao Ke, Mrigank Pawagi, Muhammad Salman Abid, Rangeet Pan, Saurabh Sinha, and Reyhaneh Jabbarvand. 2025. AlphaTrans: A Neuro-Symbolic Compositional Approach for Repository-Level Code Translation and Validation.Proceedings of the ACM on Software Engineering2, FSE (2025)
2025
- [24]
-
[25]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2024. A Survey on Large Language Models for Code Generation. arXiv:2406.00515 https: //arxiv.org/abs/2406.00515
work page internal anchor Pith review arXiv 2024
-
[26]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-World GitHub Issues?. InProceedings of the 12th International Conference on Learning Representations (ICLR). OpenReview.net. https://arxiv.org/abs/2310. 06770
2024
-
[27]
Kalia, Jin Xiao, Saurabh Sinha, Maja Vukovic, and Debasish Banerjee
Anup K. Kalia, Jin Xiao, Saurabh Sinha, Maja Vukovic, and Debasish Banerjee
-
[28]
InProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE)
Mono2Micro: An AI-Based Toolchain for Evolving Monolithic Enterprise Applications to a Microservice Architecture. InProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). ACM
-
[29]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 33. Curran Associates, Inc....
2020
- [30]
-
[31]
Zhiyuan Peng, Xin Yin, Pu Zhao, Fangkai Yang, Lu Wang, Ran Jia, Xu Chen, Qingwei Lin, Saravan Rajmohan, and Dongmei Zhang. 2026. RepoGenesis: Benchmarking End-to-End Microservice Generation from Readme to Repository. arXiv:2601.13943 https://arxiv.org/abs/2601.13943
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Protiviti. 2023. Technical Debt Remains a Major Burden. https://www.protiviti. com/de-de/global-technology-executive-survey-tech-debt-major-burden
2023
-
[33]
Yamina Romani, Okba Tibermacine, and Chouki Tibermacine. 2022. Towards Migrating Legacy Software Systems to Microservice-based Architectures: A Data- Centric Process for Microservice Identification. InProceedings of the 19th IEEE International Conference on Software Architecture Companion (ICSA-C). IEEE
2022
- [34]
-
[35]
Yingying Wang, Sarah Bornais, and Julia Rubin. 2024. Microservice Decomposi- tion Techniques: An Independent Tool Comparison. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (ASE). ACM
2024
-
[36]
Jinfeng Wen, Zhenpeng Chen, Xin Jin, and Xuanzhe Liu. 2023. Rise of the Planet of Serverless Computing: A Systematic Review.ACM Transactions on Software Engineering and Methodology32, 5 (2023)
2023
-
[37]
Jinfeng Wen, Zhenpeng Chen, Yi Liu, Yiling Lou, Yun Ma, Gang Huang, Xin Jin, and Xuanzhe Liu. 2021. An Empirical Study on Challenges of Application Development in Serverless Computing. InProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). ACM, 416–428
2021
-
[38]
Jinfeng Wen, Zhenpeng Chen, Federica Sarro, Zixi Zhu, Yi Liu, Haodi Ping, and Shangguang Wang. 2024. LLM-Based Misconfiguration Detection for AWS Server- less Computing. InACM Transactions on Software Engineering and Methodology
2024
-
[39]
Kechi Zhang, Jia Li, Ge Li, Xianjie Shi, and Zhi Jin. 2024. CodeAgent: Enhancing Code Generation with Tool-Integrated Agent Systems for Real-World Repo-Level Coding Challenges. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL). Association for Computational Linguistics
2024
-
[40]
Lulai Zhu, Damian Andrew Tamburri, and Giuliano Casale. 2023. RADF: Archi- tecture Decomposition for Function as a Service.Software: Practice and Experience (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.