Recognition: unknown
A Functorial Formulation of Neighborhood Aggregating Deep Learning
Pith reviewed 2026-05-08 04:13 UTC · model grok-4.3
The pith
Neighborhood aggregation in CNNs and message-passing networks admits a presheaf interpretation whose obstructions to being sheaves explain observed empirical limitations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
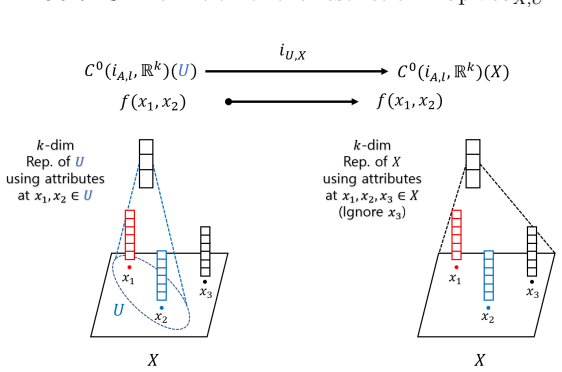
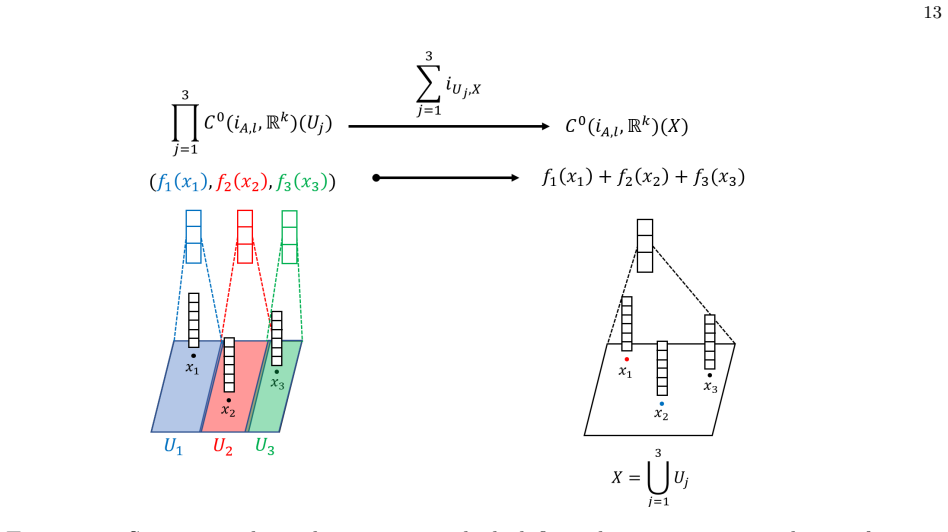
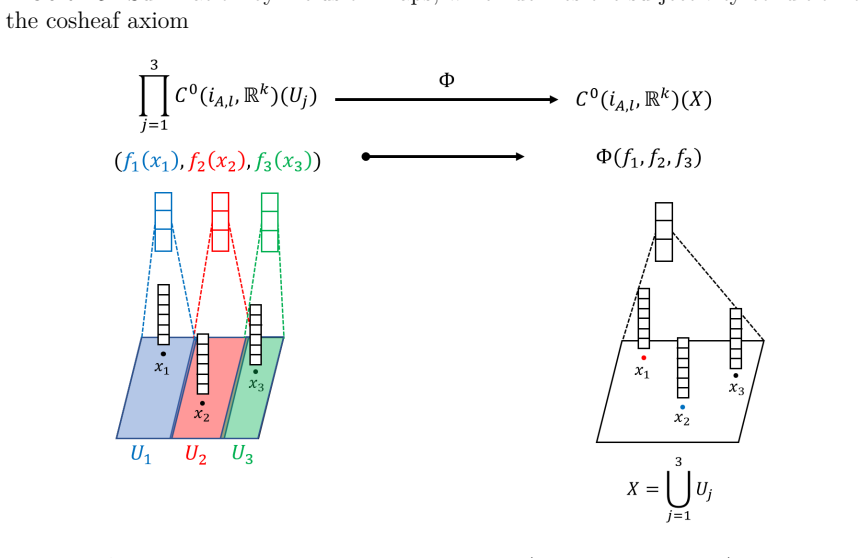
We provide a mathematical interpretation of convolutional (or message passing) neural networks by using presheaves and copresheaves of the set of continuous functions over a topological space. Based on this interpretation, we formulate a theoretical heuristic which elaborates a number of empirical limitations of these neural networks by using obstructions on such sets of continuous functions over a topological space to be sheaves or copresheaves.
What carries the argument
Presheaves and copresheaves of continuous functions on topological spaces that model neighborhood aggregation, with obstructions to sheaf or copresheaf conditions as the explanatory device.
If this is right
- Empirical shortcomings of these networks can be classified according to which sheaf axioms are violated by their aggregation rules.
- The same presheaf framework applies uniformly to both convolutional and graph-based neighborhood operations.
- Obstructions arising from local-to-global inconsistency provide a systematic way to predict when aggregation will lose information or produce artifacts.
Where Pith is reading between the lines
- If the correspondence is tight, one could design aggregation operators that explicitly enforce selected sheaf conditions to reduce the identified limitations.
- The approach suggests checking whether other aggregation-based models outside CNNs and GNNs exhibit analogous obstructions when cast in the same presheaf language.
- Explicit computation of sheaf cohomology on small example graphs or grids could quantify the size of the obstructions and correlate them with measured performance gaps.
Load-bearing premise
The presheaf or copresheaf model of neighborhood aggregation is faithful enough that its sheaf-theoretic obstructions actually correspond to the empirical limitations of the networks.
What would settle it
A concrete counterexample in which a CNN or message-passing network violates a specific sheaf gluing condition yet does not exhibit the corresponding empirical limitation, or vice versa.
Figures








read the original abstract
We provide a mathematical interpretation of convolutional (or message passing) neural networks by using presheaves and copresheaves of the set of continuous functions over a topological space. Based on this interpretation, we formulate a theoretical heuristic which elaborates a number of empirical limitations of these neural networks by using obstructions on such sets of continuous functions over a topological space to be sheaves or copresheaves.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to provide a mathematical interpretation of convolutional and message-passing neural networks via presheaves and copresheaves on the set of continuous functions over a topological space, then formulates a heuristic that attributes empirical limitations of these networks (such as over-smoothing or restricted receptive fields) to obstructions preventing the structures from satisfying the sheaf or copresheaf axioms.
Significance. If the proposed presheaf/copresheaf interpretation can be equipped with explicit functors and shown to predict specific documented failures, the work would supply a categorical lens on neighborhood aggregation that could guide architecture design; the attempt to connect sheaf obstructions to learning limitations is a potentially useful direction, though currently unrealized.
major comments (2)
- [Abstract] Abstract: the central claim asserts that neighborhood aggregation in CNNs and message-passing networks can be modeled as (co)presheaves such that failures of the locality or gluing axioms directly reproduce cited empirical limitations, yet supplies neither an explicit functor from network layers to presheaf data nor a concrete example (e.g., how a graph convolution operator violates the gluing condition and thereby produces over-smoothing).
- [Main text] Main text (heuristic formulation): the obstructions are defined in terms of the same presheaf/copresheaf structures used to interpret the networks, creating a risk that the heuristic restates known limitations rather than deriving new, independently verifiable predictions; no independent test or counter-example is supplied to break the potential circularity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recognition of the potential value in a categorical perspective on neighborhood aggregation. We respond point-by-point to the major comments below, indicating revisions where appropriate to strengthen the explicitness of the functorial construction and the heuristic.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim asserts that neighborhood aggregation in CNNs and message-passing networks can be modeled as (co)presheaves such that failures of the locality or gluing axioms directly reproduce cited empirical limitations, yet supplies neither an explicit functor from network layers to presheaf data nor a concrete example (e.g., how a graph convolution operator violates the gluing condition and thereby produces over-smoothing).
Authors: We agree that greater explicitness would improve the presentation. The manuscript defines the presheaf of continuous functions on the underlying topological space, with neighborhood aggregation corresponding to the restriction morphisms of the (co)presheaf; this supplies the functorial mapping from layers to the categorical data. To address the request directly, the revised manuscript will include an explicit functor definition from a general neighborhood-aggregating operator to the associated presheaf/copresheaf and a concrete worked example (a graph convolution on a simple cycle graph) that isolates the gluing obstruction and links it to over-smoothing. revision: yes
-
Referee: [Main text] Main text (heuristic formulation): the obstructions are defined in terms of the same presheaf/copresheaf structures used to interpret the networks, creating a risk that the heuristic restates known limitations rather than deriving new, independently verifiable predictions; no independent test or counter-example is supplied to break the potential circularity.
Authors: The heuristic is not circular: the (co)presheaf model is fixed first as the mathematical interpretation of aggregation, after which the obstructions are derived strictly from the failure of the sheaf axioms (locality and gluing). These axiom failures are independent of any neural-network performance metric and are then connected heuristically to documented empirical behaviors. We acknowledge, however, that an independent verification would strengthen the claim. The revised version will therefore add a short section proposing a concrete, testable prediction (an architecture modification that enforces the gluing condition via auxiliary regularization) together with the expected effect on over-smoothing benchmarks. revision: partial
Circularity Check
No load-bearing circularity; interpretation and heuristic remain modeling choices without reduction to inputs by construction.
full rationale
The abstract states that the authors provide a presheaf/copresheaf interpretation of neighborhood aggregation and then formulate a heuristic that uses obstructions to sheaf/copresheaf axioms to elaborate empirical limitations. No equations, self-citations, or fitted parameters are quoted that would make any claimed prediction or obstruction equivalent to the input interpretation by definition. The correspondence between sheaf obstructions and limitations is presented as a heuristic rather than a derived equality or statistically forced output. The derivation chain is therefore self-contained as an act of mathematical modeling; no step reduces to renaming or fitting the same structure it claims to explain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Presheaves and copresheaves of continuous functions on a topological space can serve as a faithful model for neighborhood aggregation in convolutional and message-passing networks.
- ad hoc to paper Obstructions to the presheaf data forming a sheaf or copresheaf correspond to empirical limitations of the networks.
Reference graph
Works this paper leans on
-
[1]
Approximation theory of the MLP model in neural networks
Allan Pinkus “Approximation theory of the MLP model in neural networks”. Acta Numerica. vol.8 pp.143–195 (1999)
1999
-
[2]
A Topological characterisation of Weisfeiler-Leman equivalence classes
Jacob Bamberger. “A Topological characterisation of Weisfeiler-Leman equivalence classes”. ICML Workshop: Topology, Algebra, and Geometry in Machine Learning. (2022)
2022
-
[3]
Sheaf Neural Networks with Connection Laplacians
Federico Barbero, Cristian Bodnar, Haitz Sáez de Ocáriz Borde, Michael Bronstein, Petar Veličković, and Pietro Liò. “Sheaf Neural Networks with Connection Laplacians”. ICML 2022 Workshop on Topology, Algebra, and Geometry in Machine Learning. (2022)
2022
-
[4]
Sheaf attention networks
Federico Barbero, Christian Bodnar, Haitz Sáez de Ocáriz Borde, and Pietro Liò. “Sheaf attention networks”. NeurIPS’22 Workshop on Symmetry and Geometry in Neural Representations (2022)
2022
-
[5]
Heterogeneous Sheaf Neural Networks
Luke Braithwaite, Alessio Borgi, Gabriele Onorato, Kristjan Tarantelli, Iulia Duta, Francesco Restuccia, Fabrizio Silvestri, and Pietro Liò. “Heterogeneous Sheaf Neural Networks”. Arxiv preprint (2024)
2024
-
[6]
Neural Sheaf Diffusion: A Topological Perspective on Heterophily and Oversmoothing in GNNs
Cristian Bodnar, Francesco Di Giovanni, Benjamin Paul Chamberlain, Pietro Lio, and Michael M. Bronstein. “Neural Sheaf Diffusion: A Topological Perspective on Heterophily and Oversmoothing in GNNs”. NeurIPS’22: Proceedings of the 36th International Conference on Neural Information Processing Systems. (2022)
2022
-
[7]
Polynomial Neural Sheaf Diffusion: A Spectral Filtering Approach on Cellular Sheaves
Alessio Borgi, Fabrizio Silvestri, and Pietro Liò. “Polynomial Neural Sheaf Diffusion: A Spectral Filtering Approach on Cellular Sheaves”. Arxiv Preprint. (2025)
2025
-
[8]
Sheaf Theory
Glen E. Bredon. “Sheaf Theory”. Graduate Texts in Mathematics, Springer. 279–448 (1997)
1997
-
[9]
Perslay: a neural network layer for persistence diagrams and new graph topological signatures
Mathieu Carriere, Frederic Chazal, Yuichi Ike, Theo Lacombe, Martin Royer, Yuhei Umeda. “Perslay: a neural network layer for persistence diagrams and new graph topological signatures”. Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics (2020)
2020
-
[10]
Neural Ordinary Differential Equations
Ricky T.Q.Chen, Yulia Rubanova, Jesse Bettencourt, and David Duvenaud. “Neural Ordinary Differential Equations”. Advances in Neural Information Processing Systems. Vol. 31. (2019)
2019
-
[11]
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Kyunghyun Cho, Bart van Merrienboer, Caglar Culcehre, Dzmitry Bahdanau Fethi Bougares, Holger Schwenk, Yoshua Bengio. “Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation”. Empirical Methods in Natural Language Processing (EMNLP). pp.1724-1734. (2014)
2014
-
[12]
Cycle to Clique (Cy2C) Graph Neural Network: A Sight to See beyond Neighborhood Aggregation
Yunyoung Choi, Sun Woo Park, U Jin Choi, and Youngho Woo. “Cycle to Clique (Cy2C) Graph Neural Network: A Sight to See beyond Neighborhood Aggregation”. Preprint, Submitted. (2022)
2022
-
[13]
Equivariant Convolutional Networks
Taco Cohen. “Equivariant Convolutional Networks”. Ph.D. Thesis. Available at https://pure.uva.nl/ws/files/60770359/Thesis.pdf (2021)
-
[14]
Spherical CNNs
Taco Cohen, Mario Geiger, Jonas Kohler, and Max Welling. “Spherical CNNs”. Proceedings of the International Conference on Learning Representations (2018)
2018
-
[15]
Sheaves, Cosheaves, and Applications
Justin Curry. “Sheaves, Cosheaves, and Applications”. Ph.D. Thesis. Arxiv Preprint (2013)
2013
-
[16]
Approximation by superpositions of a sigmoidal function
George Cybenko “Approximation by superpositions of a sigmoidal function”. Mathematics of Control, Signals, and Systems. 2 (4): 303–314 (1989)
1989
-
[17]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai et al. “An image is worth 16x16 words: Transformers for image recognition at scale”. Proceedings of the International Conference on Learning Representations (2021)
2021
-
[18]
Adversarial Robustness of Graph Transformers
Philipp Foth, Lukas Gosch, Simon Geisler, Leo Schwinn, and Stephan Günnemann. “Adversarial Robustness of Graph Transformers”. Transactions on Machine Learning Research (2025)
2025
-
[19]
On the approximate realization of continuous mappings by neural networks
Ken-Ichi Funahashi “On the approximate realization of continuous mappings by neural networks”. Neural Networks. 2 (3): 183–192 (1989)
1989
-
[20]
Explaining and harnessing adversarial examples
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy “Explaining and harnessing adversarial examples”. Proceedings of the International Conference on Learning Representations (2015)
2015
-
[21]
Theoretical Limitations of Self-Attention in Neural Sequence Models
Michael Hahn. “Theoretical Limitations of Self-Attention in Neural Sequence Models”. Transactions of the Association for Computational Linguistics. Vol. 8 pp.156–171. (2020)
2020
-
[22]
Sheaf Neural Networks
Jakob Hansen and Thomas Gebhart. “Sheaf Neural Networks”. NeurIPS’20 Workshop on TDA and Beyond. (2020)
2020
-
[23]
Copresheaf Topological Neural Networks: A Generalized Deep Learning Framework
Mustafa Hajij, Lennart Bastian, Sarah Osentoski, Hardik Kabaria, John Davenport, Dawood, Balaji Cherukuri, Joseph Kocheemoolayil, Nastaran Shahmansouri, Adrian Lew, Theodore Papamarkou, and Tolga Birdal.“Copresheaf Topological Neural Networks: A Generalized Deep Learning Framework”. NeurIPS’25. Proceedings of the 39th International Conference on Neural In...
2025
-
[24]
Algebraic Geometry
Robin Hartshorne. “Algebraic Geometry”. Graduate Texts in Mathematics, Springer. 60–69 (1977)
1977
-
[25]
Algebraic Topology
Allen Hatcher. “Algebraic Topology”. Cambridge University PRess. (2002) 31
2002
-
[26]
Sheaf-based Positional Encodings for Graph Neural Networks
Yu He, Cristian Bodnar, and Pietro Liò. “Sheaf-based Positional Encodings for Graph Neural Networks”. Proceedings of the 2nd NeurIPS Workshop on Symmetry and Geometry in Neural Representations, PMLR 228:1-18. (2024)
2024
-
[27]
Long short-term meory
S. Hochreiter and J. Schmidhuber. “Long short-term meory”. Neural Computation. Vol. 9 No. 8, pp.1700-1709 (1997)
1997
-
[28]
Multilayer feedforward networks are universal approxi- mators
Kurt Hornik, Maxwell Stinchcombe, and Halbert White “Multilayer feedforward networks are universal approxi- mators”. Neural Networks. 2 (5): 359–366. (1989)
1989
-
[29]
On the Robustness of Self-attentive models
Yu-Lun Hsieh, Minhao Cheng, Da-Cheng Juan, wei Wei, Wen-Lian Hsu, and Cho-Jui Hsieh. “On the Robustness of Self-attentive models”. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. pp. 1502-001529. (2019)
2019
-
[30]
Generalization or Hallucination? Understanding Out-of-Context Reasoning in Transformers
Yixiao Huang, Hanlin Zhu, Tianyu Guo, Jiantao Jiao, Somayeh Sojoudi, Michael Jordan, Stuart J Russell, and Song Mei. “Generalization or Hallucination? Understanding Out-of-Context Reasoning in Transformers”. NeurIPS’25. Proceedings of the 39th International Conference on Neural Information Processing Systems. (2025)
2025
-
[31]
Fuchsian Groups
Svetlana Katok. “Fuchsian Groups”. University of Chicago Press. pp. 63–77 (1992)
1992
-
[32]
Universal Cover of a Surface (with Boundary)
Moishe Kohan “Universal Cover of a Surface (with Boundary)”. Mathematics Stack Exchange, https://math.stackexchange.com/questions/673187/universal-cover-of-a-surface-with-boundary (version: February 12th, 2014)
2014
-
[33]
Universal Approximation with Deep Narrow Networks
Patrick Kidger and Terry Lyons. “Universal Approximation with Deep Narrow Networks”. Conference on Learning Theory. (2020)
2020
-
[34]
Semi-supervised classification with graph convolutional networks
Thomas Kipf, Max Welling “Semi-supervised classification with graph convolutional networks”. ICLR (2017)
2017
-
[35]
Does there exist a continuous, open, and surjective map fromf : Rn→Rm form > n?
Moishe Kohan. (https://math.stackexchange.com/questions/3130389/does-there-exist-a-continuous-open-and- surjective-map-from-f-colon-mathbbr). “Does there exist a continuous, open, and surjective map fromf : Rn→Rm form > n?”. Mathematics Stack Exchange. Answer provided on March 4th, 2019
-
[36]
Universal covers, color refinement, and two-variable counting logic: Lower bounds for the depth
Andreas Krebs and Oleg Verbitsky. “Universal covers, color refinement, and two-variable counting logic: Lower bounds for the depth". 2015 30th Annual ACM/IEEE Symposium on Logic in Computer Science. 15345831 (2015)
2015
-
[37]
The Expressive Power of Neural Networks: A View from the Width
Zhou Lu, Hongming Pu, Feicheng Wang, Zhiqiang Hu, and Liwei Wang. “The Expressive Power of Neural Networks: A View from the Width”. Advances in Neural Information Processing Systems. Vol. 30. (2017)
2017
-
[38]
On the robustness of vision transformers to adversarial examples
Kaleel Mahmood, Rigel Mahmood, and Marten van Dijk. “On the robustness of vision transformers to adversarial examples”. IEEE/CVF International Conference on Computer Vision (ICCV). (2021)
2021
-
[39]
On the Vulnerability of Capsule Networks to Adversarial Attacks
Felix Michels, Tobian Uelwer, Eric Upschulte, and Stefan Harmeling “On the Vulnerability of Capsule Networks to Adversarial Attacks”. International Conference on deep learning 2019, Workshop on Security and Privacy of deep learning (2019)
2019
-
[40]
Crafting Adversarial Input Sequences for Recurrent Neural Networks
Nicolas Papernot, Patrick McDaniel, Ananthram Swami, and Richard Harang. “Crafting Adversarial Input Sequences for Recurrent Neural Networks”. IEEE Military Communications Conference (2016)
2016
-
[41]
Minimum Width for Universal Approximation
Sejun Park, Chulhee Yun, Jaeho Lee, and Jinwoo Shin. “Minimum Width for Universal Approximation”. Proceedings of the International Conference on Learning Representations (2021)
2021
-
[42]
A persistent Weisfeiler-Lehman procedure for graph classification
Bastian Rieck, Christian Bock, Karsten Borgwardt. “A persistent Weisfeiler-Lehman procedure for graph classification”, Proceedings of the 36th International Conference on deep learning, PMLR 97:5448-5458 (2019)
2019
-
[43]
Dynamic Routing between Capsules
Sara Sabour, Nicholas Frosst, and Geoffrey E Hinton. “Dynamic Routing between Capsules”. Advances in Neural Information Processing Systems. vol.30 (2017)
2017
-
[44]
Mitigating adversarial attacks on transformer models in credit scoring
Brandon Schwab and Johannes Kriebel. “Mitigating adversarial attacks on transformer models in credit scoring”. European Journal of Operational Research 328 (1) pp. 309-323 (2026)
2026
-
[45]
Weisfeiler- Lehman Graph Kernels
Nino Shervashidze, Pascal Schweitzer, Erik Jan van Leeuwen, Kurt Mehlhorn, Karsten M. Borgwardt. “Weisfeiler- Lehman Graph Kernels”, Journal of deep learning Research no.12 (2011) 2539-2561
2011
-
[46]
Cohomology of Sheaves
Stacks Project. “Cohomology of Sheaves”. url: https://stacks.math.columbia.edu/tag/01DZ
-
[47]
From Noise to Narrative: Tracing the Origins of Hallucinations in Transformers
Praneet Suresh, Jack Stanley, Sonia Joseph, Luca Scimeca, and Danilo Bzdok. “From Noise to Narrative: Tracing the Origins of Hallucinations in Transformers”. NeurIPS’25. Proceedings of the 39th International Conference on Neural Information Processing Systems. (2025)
2025
-
[48]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. “Attention is all you need”. Advances in Neural Information Processing Systems. Vol. 30. (2017)
2017
-
[49]
On the limitations of representing functions on sets
Edward Wagstaff, Fabian B. Fuchs, Martin Engelcke, Ingmar Posner, and Michael Osborne. “On the limitations of representing functions on sets”. Proceedings of the 36th International Conference on Machine Learning. (2019)
2019
-
[50]
Monotone and open mappings on manifolds. I
John Walsh. “Monotone and open mappings on manifolds. I”. Transactions of the American Mathematical Society. Vol. 209 (1975)
1975
-
[51]
How Powerful are Graph Neural Networks?
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. “How Powerful are Graph Neural Networks?”. International Conference on Learning Representations (2019). 32
2019
-
[52]
Deep Sets
Manzil Zaheer, Satwik Kottur, Siamak Ravanbhakhsh, Barnabas Poczos, Ruslan Salakhutdinov, and Alexander J Smola. “Deep Sets”. 31st Conference on Neural Information Processing Systems. (2017)
2017
-
[53]
Adversarial attacks on deep learning models in natural language processing: A survey
Wei Emma Zhang, Quan Z. Sheng, Ahoud Alhazmi, and Chenliang Li. “Adversarial attacks on deep learning models in natural language processing: A survey”. ACM Transactions on Intelligent Systems and Technology. Vol.11 No.3 pp.1-41. (2020)
2020
-
[54]
Graph neural networks: A review of methods and applications
Jie Zhou, Ganqu Cui, Shengding Hu, Zhengyan Zhang, Cheng Yang, Zhiyuan Liu, Lifeng Wang, Changcheng Li, and Maosong Sun.“Graph neural networks: A review of methods and applications”. AI Open I. 57–81 (2020)
2020
-
[55]
Adversarial Attacks on Graph Neural Networks via Meta Learning
Daniel Zugner and Stephan Gunnemann “Adversarial Attacks on Graph Neural Networks via Meta Learning”. Proceedings of the International Conference on Learning Representations (2019) Max Planck Institute for Mathematics, Vivatsgasse 7, 53111 Bonn, Germany Email address:s.park@mpim-bonn.mpg.de SolverX, Gangseo-gu, Seoul 07801, Republic of Korea Email address...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.